Proxmox: Ceph vs. ZFS Replication — Escolhendo sem Fanatismo
ZFS é rápido mas assíncrono. Ceph é robusto mas exige hardware. Uma análise profunda sobre latência, consistência e custos para decidir seu storage HA.
Se você frequenta fóruns de homelab ou grupos de Sysadmins, já viu a guerra santa. De um lado, os puristas do ZFS gritando sobre integridade de dados e simplicidade. Do outro, os evangelistas do Ceph prometendo a terra prometida da escalabilidade infinita e do "self-healing".
A verdade, como sempre, está suja de graxa no meio do caminho.
O problema é que a maioria dos tutoriais vende o sonho do "Cluster de Alta Disponibilidade" (HA) sem explicar o custo físico e logístico disso. Armazenamento não é mágica; é física, latência e coerência de cache. Quando você escolhe entre ZFS Replication e Ceph no Proxmox, você não está escolhendo uma "feature". Você está escolhendo onde você aceita sofrer: na latência de rede ou na janela de perda de dados (RPO).
Vamos dissecar essas duas tecnologias, ignorar o marketing e olhar para o que acontece quando o cabo de rede é puxado.
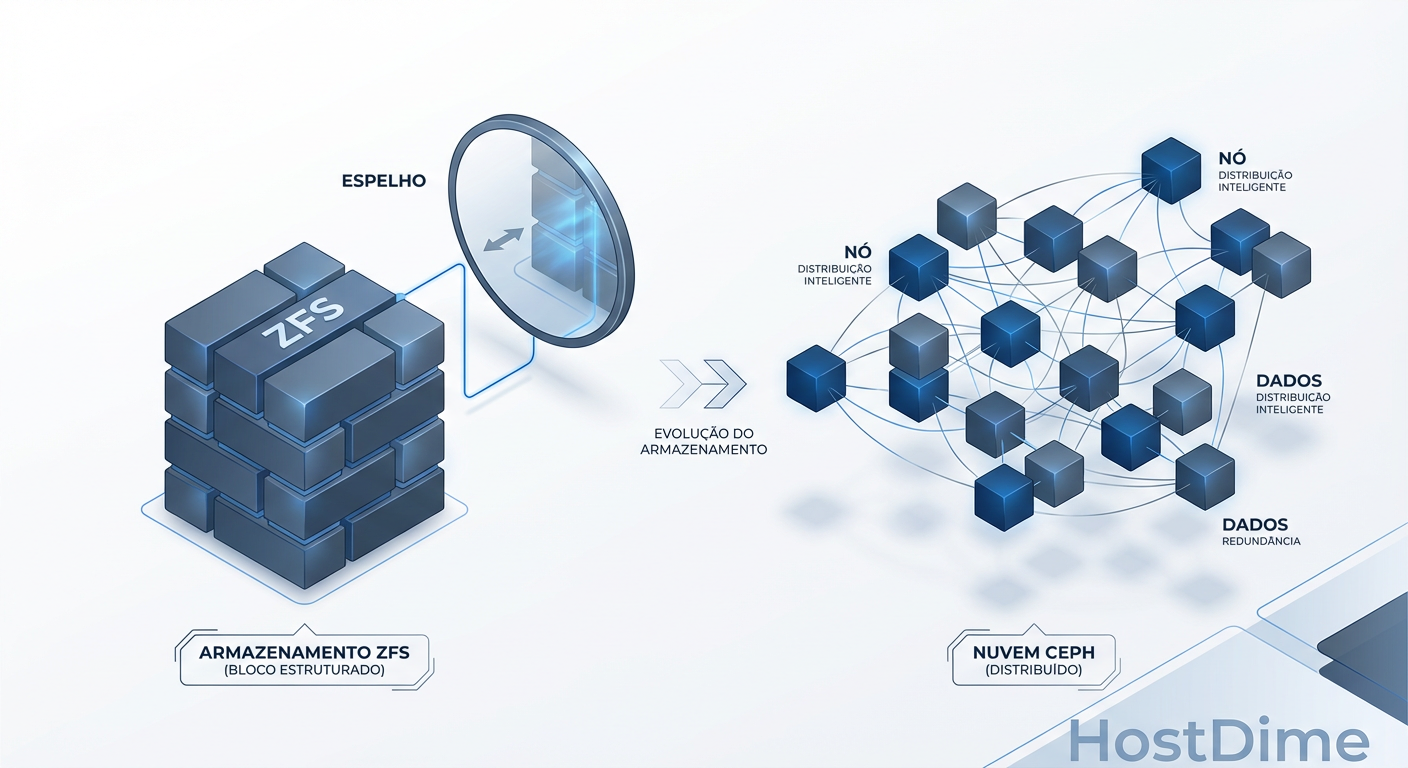
O Mito da Alta Disponibilidade Instantânea
A primeira coisa que precisamos desconstruir é o botão "Migrate" e o conceito de HA (High Availability). No Proxmox, HA significa que, se um nó morrer, a VM reinicia em outro. Mas como os dados chegam lá define se você terá um banco de dados corrompido ou uma operação suave.
ZFS Replication: O "Quase" Tempo Real
O ZFS Replication (padrão no Proxmox para setups sem armazenamento compartilhado real) é, por definição, assíncrono. Ele funciona tirando snapshots do seu volume e enviando a diferença (zfs send/recv) para o nó de destino via SSH.
Você configura isso para rodar a cada 15 minutos? A cada 1 minuto? Ótimo. Mas entenda a física: se o seu nó primário pegar fogo 59 segundos após a última replicação de 1 minuto, você perdeu 59 segundos de dados.
Para um servidor de arquivos estáticos, isso é irrelevante. Para um banco de dados transacional (SQL, Postgres) ou um sistema de filas, isso é catastrófico. O ZFS Replication oferece um RPO (Recovery Point Objective) maior que zero.
Ceph: O Compromisso da Coerência
O Ceph joga um jogo diferente. Ele é um armazenamento distribuído de objetos. Quando sua VM escreve um bloco de dados no disco virtual, o Ceph não diz "ok" para o sistema operacional até que esse dado tenha sido escrito no disco primário (OSD) E replicado para os OSDs secundários via rede.
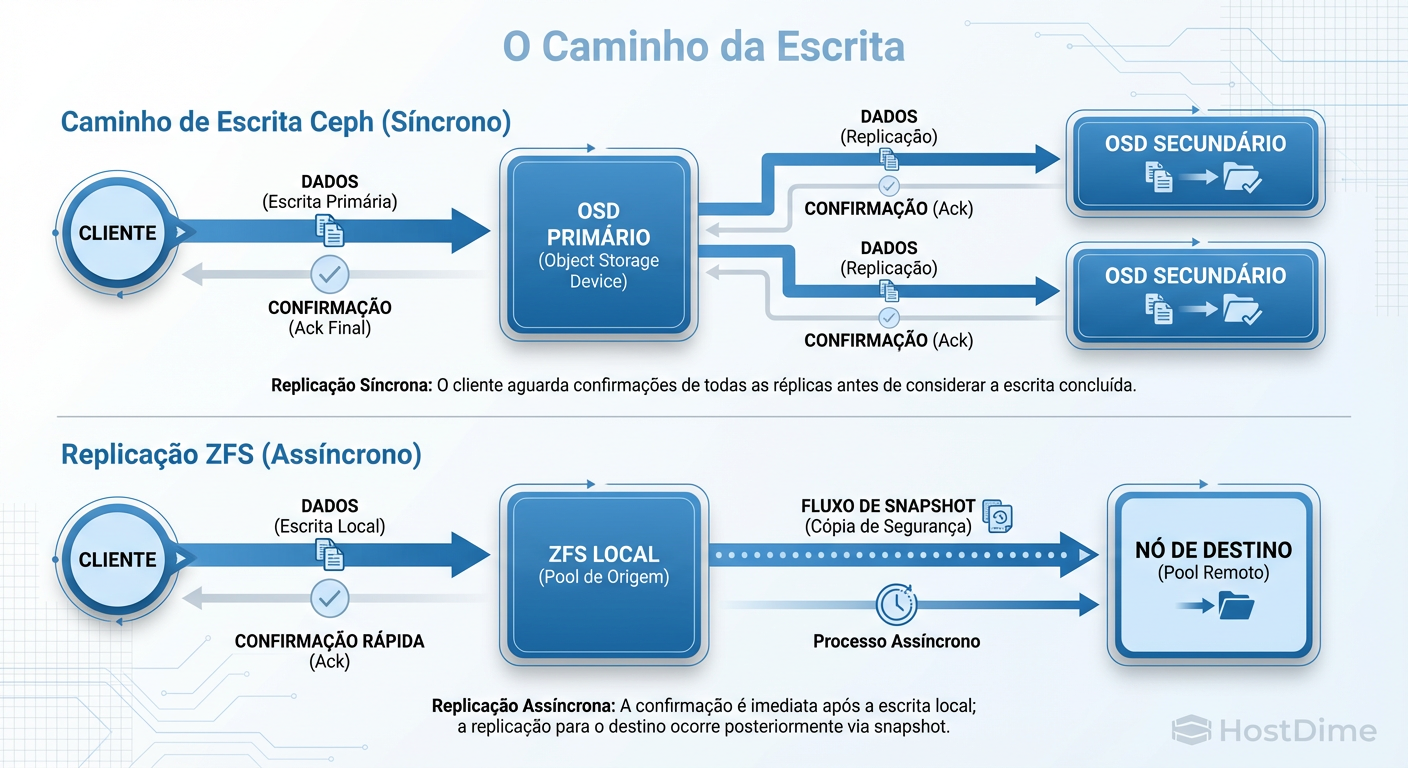 Figura: A Diferença Vital: Ceph garante que os dados estão em múltiplos lugares antes de confirmar. ZFS Replication (padrão no Proxmox) confirma localmente e envia depois, criando uma janela de perda de dados (RPO > 0).
Figura: A Diferença Vital: Ceph garante que os dados estão em múltiplos lugares antes de confirmar. ZFS Replication (padrão no Proxmox) confirma localmente e envia depois, criando uma janela de perda de dados (RPO > 0).
Isso garante RPO = 0 (ou muito próximo disso, salvo catástrofes nucleares). Se o nó 1 morrer no meio de uma transação, o nó 2 já tem o dado. Não há "gap" de replicação. Mas essa segurança tem um preço alto: latência.
O Imposto do Hardware: Por que sua rede de 1Gbps é insuficiente
Aqui é onde o sysadmin iniciante falha. O Ceph é "software-defined storage", o que significa que ele troca hardware proprietário caro (SANs) por ciclos de CPU e largura de banda de rede.
A Latência de Rede é o Novo Gargalo
No ZFS local, uma escrita é limitada pela velocidade do seu NVMe. É brutalmente rápido. No Ceph, uma escrita é:
VM envia dado.
Rede para o OSD Primário.
OSD Primário processa (CPU).
Rede para OSD Secundário.
OSD Secundário grava no disco (Latência de Disco).
Confirmação volta pela rede...
Se você tentar rodar Ceph em uma rede de 1Gbps, você vai chorar. A latência de cada operação de I/O dispara. O Ceph exige, no mínimo, uma rede de 10Gbps dedicada para o tráfego de cluster (backend) para ser utilizável em produção. Com 1Gbps, qualquer operação de rebalanceamento (recovery) vai derrubar a performance das suas VMs para níveis de disquete.
O Drama dos SSDs de Consumidor
O Ceph usa fsync agressivamente para garantir a integridade. SSDs de consumidor (Samsung EVO/QVO, Kingston baratos) mentem sobre sua velocidade de escrita usando caches SLC voláteis. Quando o Ceph força um flush para o disco real, a performance desses drives cai de 500MB/s para 10MB/s.
Regra de Ouro: Se for usar Ceph, você precisa de SSDs com PLP (Power Loss Protection). Sem isso, a latência de escrita (write latency) matará suas aplicações. O ZFS é mais indulgente com hardware barato porque usa a RAM (ARC) como um buffer massivo de leitura e agrupa escritas de forma mais eficiente (Transaction Groups), mascarando a lentidão do disco subjacente melhor que o Ceph.
Cenários de Falha: O Pesadelo Operacional
Todo sistema funciona bem quando as luzes estão acesas. Vamos ver o que acontece no escuro.
ZFS e o "Split-Brain"
O ZFS Replication brilha em clusters pequenos de 2 nós, mas é perigoso. Se a conexão entre os nós cai, ambos podem achar que são o "mestre". Se o HA do Proxmox tentar subir a VM no lado "errado" ou se houver uma divergência de dados, você terá duas versões da mesma VM rodando.
Para mitigar isso, você precisa de um terceiro voto (Quorum Device/QDevice), que pode ser um Raspberry Pi ou uma VM externa, para desempatar a decisão. Sem quórum, o cluster trava para evitar corrupção. A recuperação de um split-brain no ZFS replication muitas vezes é manual e dolorosa: você precisa decidir qual versão dos dados é a "verdadeira" e sobrescrever a outra.
Ceph e a Reconstrução Automática
O Ceph é projetado para falhar. Se um disco morre, o Ceph percebe e começa a copiar os dados das réplicas restantes para restaurar a redundância (rebalancing).
O problema? Esse processo consome muita CPU e I/O. Se o seu cluster já estava no limite, o processo de recuperação pode tornar o sistema inoperável. Além disso, o Ceph precisa de um número ímpar de monitores (Mons) para manter o quórum (paxos). Ele escala bem, mas a complexidade de gerenciamento inicial é um "degrau" alto.
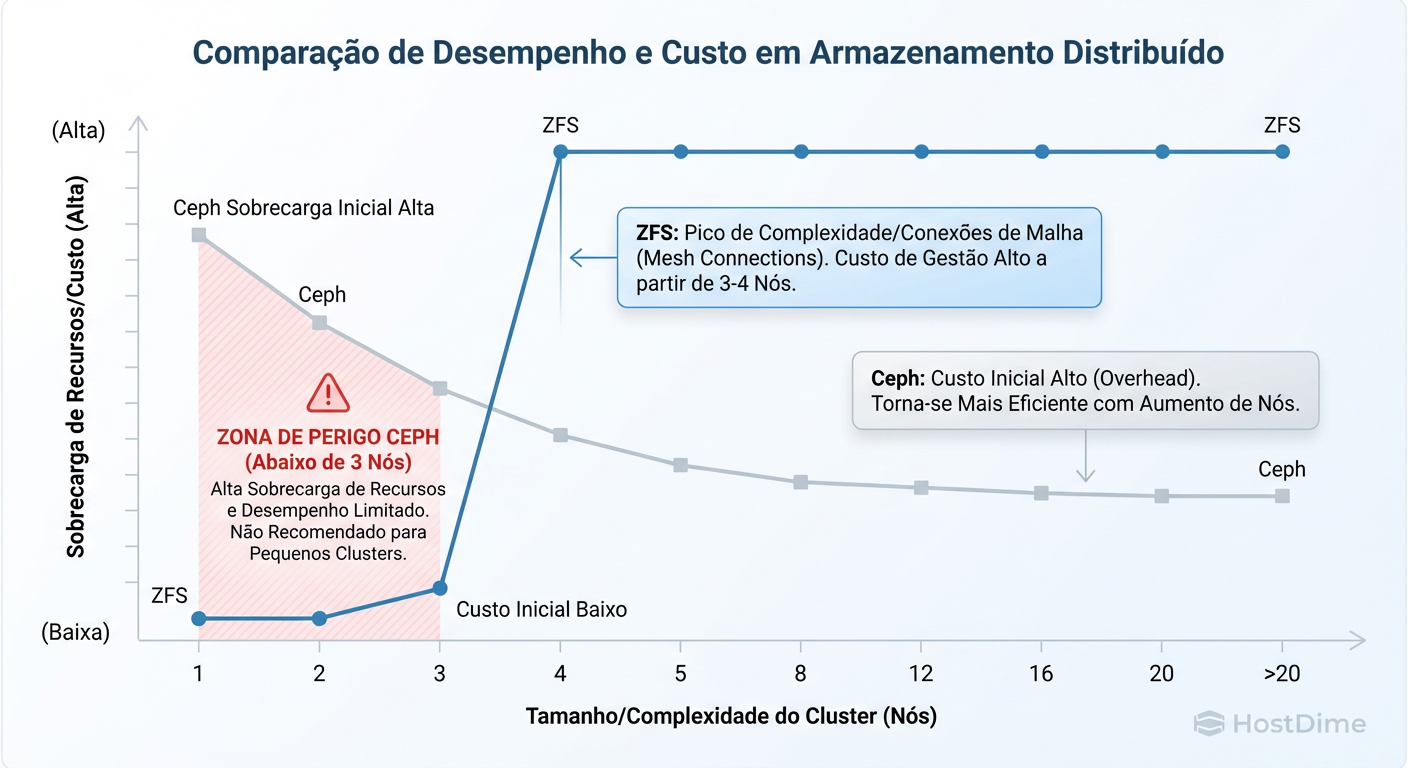 Figura: A Curva de Complexidade: ZFS brilha em setups pequenos (2-3 nós). Ceph exige um 'imposto' inicial alto de recursos, mas escala linearmente onde o ZFS se torna ingovernável.
Figura: A Curva de Complexidade: ZFS brilha em setups pequenos (2-3 nós). Ceph exige um 'imposto' inicial alto de recursos, mas escala linearmente onde o ZFS se torna ingovernável.
Como a imagem acima ilustra, o ZFS é linear. O Ceph tem um custo de entrada alto (hardware e complexidade), mas depois desse ponto, ele escala horizontalmente de forma que o ZFS não consegue acompanhar. Adicionar um novo nó no Ceph é trivial; no ZFS Replication, é apenas mais um ponto de falha para gerenciar scripts de sincronia.
Performance Real: Como medir e não se enganar
Não use dd para testar performance de disco em virtualização. dd é sequencial e enganoso. O mundo real é aleatório e concorrente.
Para saber se seu armazenamento aguenta a carga, você precisa testar IOPS de escrita síncrona (Sync Write) e latência.
Aqui está um teste honesto usando fio que simula um banco de dados (o pior cenário para Ceph e ZFS):
# Instale o fio: apt install fio
# Teste de Latência de Escrita Aleatória 4k (O "Killer" de performance)
fio --name=random-write --ioengine=libaio --rw=randwrite --bs=4k --numjobs=1 \
--size=1g --iodepth=1 --runtime=60 --time_based --end_fsync=1 \
--filename=teste_fio_temp
O que observar:
ZFS Local (NVMe): Você deve ver latências na casa de microsegundos (us) e IOPS altos.
Ceph (Rede 10G + SSD Enterprise): Latência aceitável (1-2ms).
Ceph (Rede 1G ou SSD Consumidor): Latência na casa de 10ms a 100ms. Isso é inaceitável para produção.
Se o flat (latência) no resultado for alto, seus usuários vão reclamar que "o sistema está travando", mesmo que a taxa de transferência (MB/s) pareça alta.
Veredito Pragmático: A Matriz de Decisão
Não existe "o melhor". Existe o que paga as contas com menos dor de cabeça para o seu cenário.
Use ZFS Replication se:
Você tem 2 ou 3 nós: O overhead do Ceph não vale a pena aqui.
Seu orçamento é limitado: Você não pode comprar switches 10Gbps ou SSDs Enterprise com PLP.
Performance local é crítica: Você precisa da velocidade bruta do NVMe local para um banco de dados pesado.
RPO de 1 a 15 minutos é aceitável: Se perder 5 minutos de trabalho não falir a empresa.
Use Ceph se:
Você tem 4+ nós (idealmente 5+): O Ceph precisa de espaço para manobrar dados.
Alta Disponibilidade Real é mandatória: RPO=0. Se um nó cair, a VM reinicia em outro sem perda de dados.
Você tem infraestrutura de rede robusta: 10Gbps+ e Jumbo Frames configurados.
Você quer "Storage Unificado": Um pool gigante onde você pode jogar VMs sem se preocupar em qual disco local elas estão.
O Resumo do Veterano
O ZFS Replication é a ferramenta do "Homelabber Avançado" e das PMEs que precisam de resiliência com custo baixo. É rápido, simples, mas exige cuidado com a janela de dados.
O Ceph é a ferramenta do "Data Center". Ele transforma seu hardware em uma nuvem privada real. Mas, como qualquer nuvem, exige engenharia de rede e hardware adequado. Tentar rodar Ceph no "barato" é a receita mais rápida para passar o fim de semana debugando logs de latência em vez de descansar.
Escolha sua dor. Configure. Meça. E nunca confie no padrão de fábrica.

Elena Kovacs
Arquiteta de Cloud Infrastructure
Focada em NVMe-oF e storage definido por software. Projeta clusters de petabytes para grandes provedores de nuvem.