Proxmox Disk Cache: A Verdade sobre Writeback, None e a Integridade dos Dados

Pare de chutar configurações. Entenda o fluxo de I/O no KVM, o impacto do ZFS ARC vs Host Page Cache e quando o Writeback destrói seus dados.
Você recebe o chamado às 3 da manhã. O banco de dados da VM crítica corrompeu após uma queda abrupta de energia no Host, mesmo com o UPS segurando por alguns minutos. O sistema de arquivos diz que gravou os dados. O Proxmox diz que o disco está saudável. Mas os logs do PostgreSQL mostram transações perdidas que deveriam estar lá.
Como investigador forense de sistemas, eu não procuro culpados, procuro a causa raiz. E em 90% dos casos de corrupção de dados em virtualização, o culpado é uma mentira contada entre o Guest (a VM) e o Storage físico.
Essa mentira se chama Cache de Disco.
No Proxmox (KVM/QEMU), a configuração de cache não é um botão de "Turbo". É uma definição de quem segura a batata quente (os dados) e quem mente para quem sobre se ela já esfriou (foi gravada no disco). Vamos dissecar a anatomia desse crime potencial antes que ele aconteça no seu ambiente.
Anatomia do I/O: O Caminho da Escrita
Para entender por que seus dados corrompem ou por que sua performance flutua, precisamos traçar a rota de um bloco de dados desde o momento em que a aplicação diz "Salvar" até o elétron mudar de estado na célula NAND do seu SSD.
Quando uma VM grava um dado, ele passa por quatro barreiras principais:
Page Cache do Guest: A RAM da própria VM.
VirtIO Driver: O entregador que passa o pacote da VM para o Hypervisor (QEMU).
Page Cache do Host: A RAM do Proxmox (Linux).
Storage Controller/Disk: O hardware físico (ou a camada ZFS/Ceph).
O problema surge quando uma dessas camadas diz "OK, gravei!" (o Ack ou Acknowledge), mas na verdade apenas guardou o dado na RAM para gravar depois. Se a energia cair nesse milissegundo, o dado desaparece, mas a aplicação acha que ele está salvo.
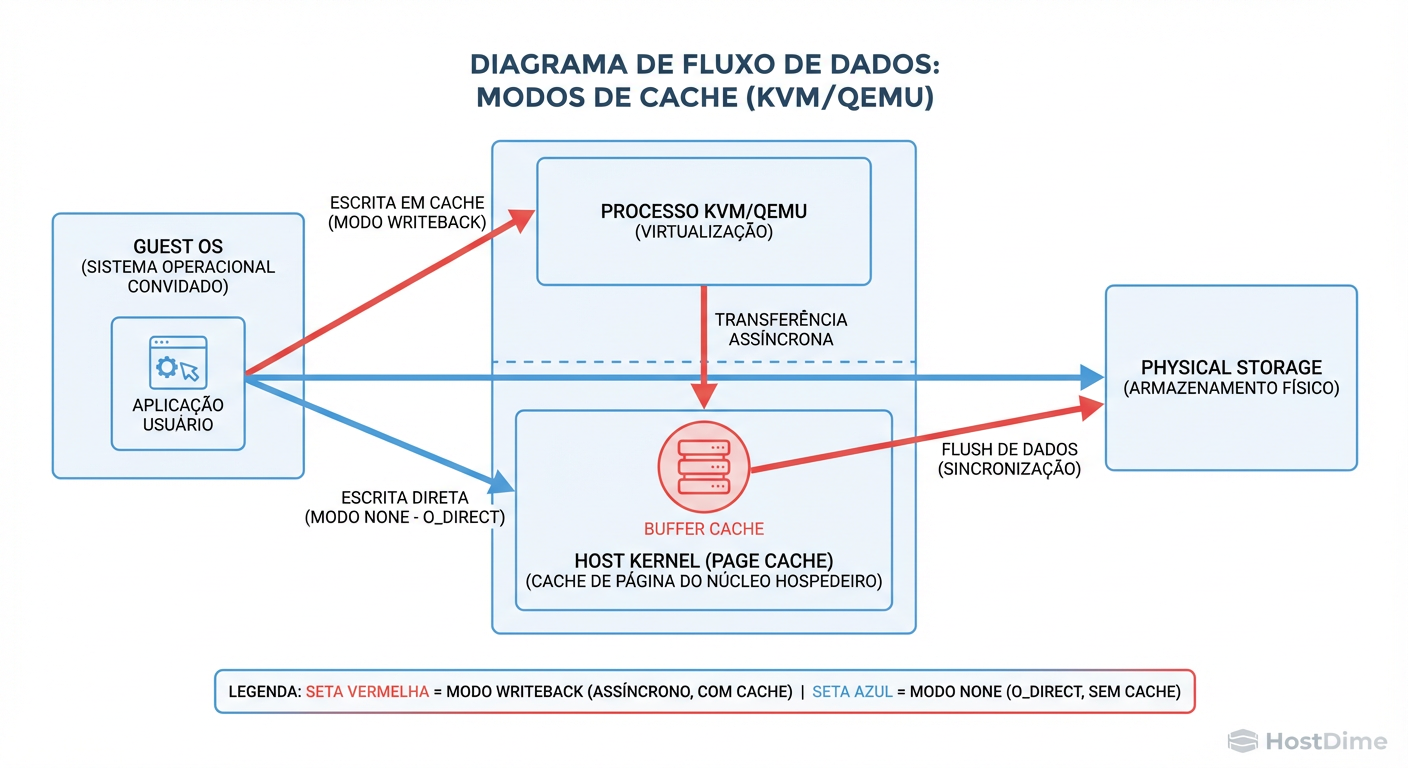 Figura: O Fluxo da Verdade: Note como o modo 'None' (O_DIRECT) contorna completamente o Page Cache do Host, entregando o controle de volta ao Storage Controller ou ZFS.
Figura: O Fluxo da Verdade: Note como o modo 'None' (O_DIRECT) contorna completamente o Page Cache do Host, entregando o controle de volta ao Storage Controller ou ZFS.
A imagem acima ilustra o cenário ideal moderno. Mas a maioria das instalações padrão não opera assim. Vamos analisar os modos de cache e onde o perigo reside.
A Ilusão do Cache: Writeback
O modo Writeback é o padrão em muitos tutoriais antigos porque ele oferece uma performance "sedutora".
Neste modo, o Proxmox (Host) intercepta a escrita da VM e diz imediatamente: "Gravei!". A VM fica feliz e continua o processo. Mas o dado ainda está na RAM do Host (Page Cache). O Host vai descarregar isso para o disco físico quando tiver tempo.
O Risco Forense
Se o Host travar ou perder energia antes de esvaziar esse buffer, os dados somem.
"Mas o Linux não manda um comando de flush?"
Sim. O Guest OS envia instruções de barreira de escrita (frequentemente chamadas de fsync ou fdatasync). No modo Writeback padrão, o QEMU respeita essas instruções e força o Host a gravar no disco.
Isso cria um perfil de performance "dente de serra". A escrita é rápida na RAM, mas quando o Guest pede um fsync (commit), a latência dispara porque o Host precisa parar de mentir e trabalhar de verdade.
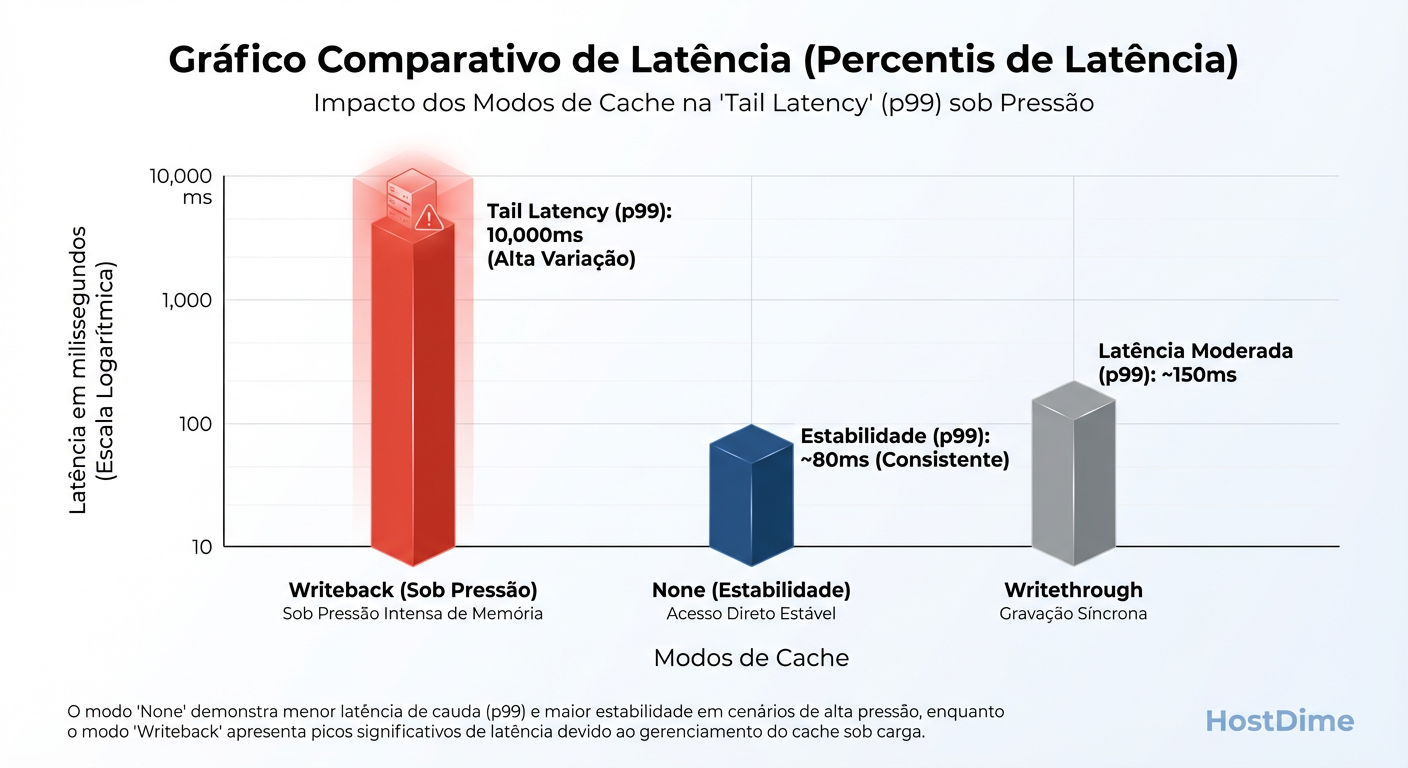 Figura: A Mentira da Média: O Writeback parece rápido na média, mas observe os picos de latência (p99) quando o Host precisa despejar dados para o disco sob pressão.
Figura: A Mentira da Média: O Writeback parece rápido na média, mas observe os picos de latência (p99) quando o Host precisa despejar dados para o disco sob pressão.
Writeback (Unsafe): A Roleta Russa
Existe uma variação chamada Writeback (Unsafe). Aqui, o QEMU ignora os comandos de fsync do Guest. Ele diz "Sim, eu sincronizei com o disco", mas continua mantendo tudo na RAM.
Veredito: Nunca use Unsafe em produção. É útil apenas para instalações temporárias de VMs onde, se quebrar, você apaga e começa de novo. Se você usa isso em um banco de dados, a corrupção não é uma possibilidade; é uma certeza matemática em caso de falha.
Cache=None (O_DIRECT): A Escolha Moderna
O nome "None" confunde muita gente. Parece que você está desligando toda a aceleração e que tudo ficará lento.
Na realidade, Cache=None significa Direct I/O (O_DIRECT). O QEMU ignora o Page Cache do Host (RAM do Proxmox) e fala diretamente com o sistema de armazenamento subjacente.
Por que isso é, paradoxalmente, melhor e muitas vezes mais rápido?
Evita Cache Duplo: Se você usa ZFS, o ZFS já tem seu próprio cache gigante na RAM (o ARC). Se você usa
Writeback, você tem o dado no ARC e no Page Cache do Linux. Você está desperdiçando RAM duplicando o mesmo dado.Latência Previsível: Como o Guest fala direto com o Storage, não há aquela "mentira" inicial seguida de um pico de latência quando o buffer enche.
Migração ao Vivo: O modo
Noneé o mais seguro e consistente para Live Migration, pois não há buffers "sujos" na RAM do Host que precisam ser sincronizados às pressas.
Se o seu backend é ZFS ou Ceph, Cache=None é a única configuração sã. Deixe o ZFS ou o Ceph gerenciarem a integridade. Eles são mais inteligentes que o Page Cache genérico do Linux.
Writethrough e DirectSync: A Paranoia Justificada
Existem cenários onde a integridade supera qualquer necessidade de velocidade.
Writethrough: O Host lê do cache (rápido), mas a escrita vai direto para o disco físico. O Guest só recebe o "OK" quando o disco físico confirma.
DirectSync: Semelhante ao Writethrough, mas ignora o cache de leitura também.
Esses modos são úteis se você não confia no sistema de arquivos do Host ou se não possui um controlador de disco com bateria (BBU) e quer garantir que cada bit esteja no prato magnético ou na célula flash. A penalidade de performance é severa.
Medindo a Realidade: O Teste do Fio
Não confie em gráficos de GUI que mostram médias de 5 minutos. Para armazenamento, a média é irrelevante; o que mata bancos de dados é a latência de cauda (o 1% das requisições mais lentas).
Para testar como seu cache está se comportando em relação à integridade (sync), use o fio dentro da VM. Vamos simular um banco de dados fazendo escritas síncronas.
# Comando para rodar DENTRO DA VM
# Simula I/O aleatório 4k (padrão de DB), com sincronização forçada a cada escrita.
fio --name=teste_integridade \
--ioengine=libaio \
--rw=randwrite \
--bs=4k \
--direct=1 \
--fsync=1 \
--size=1G \
--numjobs=1 \
--runtime=60 \
--group_reporting
O que observar nos resultados:
fdatasync/sync lat: Se este valor for próximo de 0 (microssegundos) e você não tem um SSD Optane ou RAM-disk, seu cache está mentindo (provavelmente Unsafe ou Writeback sem barreira).
IOPS: Em um SSD SATA Enterprise real com
Cache=None, espere algo entre 1.000 e 10.000 IOPS com sync=1. Se der 50.000 IOPS num SSD SATA, desconfie. O sistema não está gravando no disco a cada ciclo.
Veredito Operacional: Matriz de Decisão
A decisão de cache não é isolada; ela depende estritamente do que está "embaixo" do Proxmox. O erro mais comum que vejo em campo é configurar Cache Writeback em cima de ZFS.
O ZFS usa o ARC (Adaptive Replacement Cache), que é tecnicamente superior ao Page Cache do Linux (LRU). Quando você usa None, você permite que o ZFS sirva leituras frequentes da RAM (ARC) e agrupe escritas (Transaction Groups) de forma eficiente, mantendo a garantia de integridade via ZIL (ZFS Intent Log).
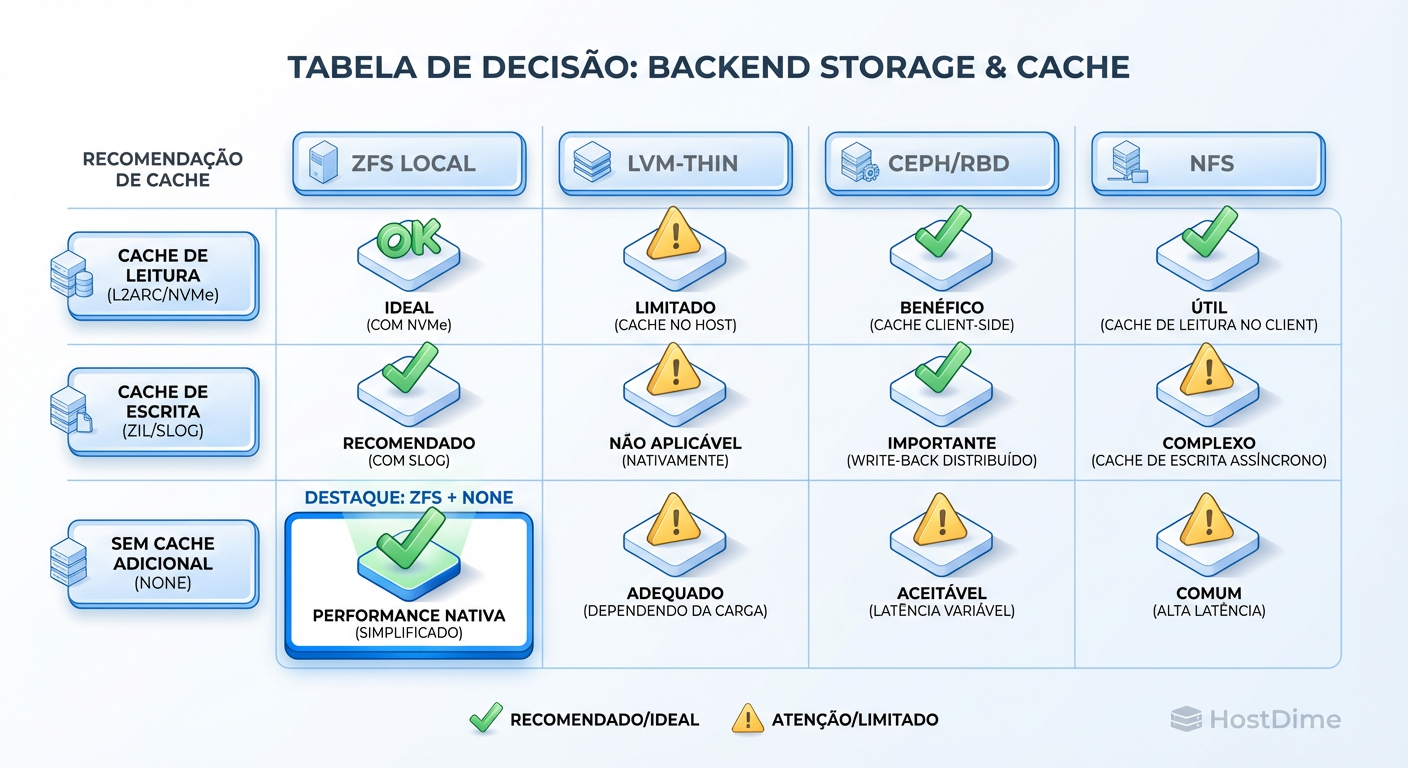 Figura: Cheat Sheet de Produção: Se você usa ZFS, o ARC já é seu cache. Não duplique trabalho.
Figura: Cheat Sheet de Produção: Se você usa ZFS, o ARC já é seu cache. Não duplique trabalho.
Aqui está a matriz de decisão baseada na realidade de produção:
| Backend Storage | Modo Recomendado | Por quê? |
|---|---|---|
| ZFS (Local) | None | Evita cache duplo (ARC + Page Cache). ZFS garante a integridade. |
| Ceph (RBD) | None | O librbd já faz o caching necessário. Writeback aqui pode causar inconsistência em caso de falha do OSD. |
| LVM-Thin (SSD Enterprise) | None | SSDs modernos com PLP (Power Loss Protection) são rápidos o suficiente para não precisar da "ajuda" do cache do Host. |
| LVM-Thin (HDD/SSD Consumer) | Writeback | Cuidado: Só use se aceitar risco moderado. Discos lentos podem travar a VM sem esse buffer. Garanta que o UPS funciona. |
| Arquivo qcow2 (Diretório) | Writeback | O overhead do qcow2 muitas vezes exige cache para performance aceitável, mas o risco de corrupção do arquivo de imagem aumenta. |
Nota Final sobre "Async I/O"
Além do modo de cache, o Proxmox permite escolher o controlador de I/O (io_uring vs native vs threads).
Para a maioria dos kernels modernos (5.15+), a combinação vencedora para performance e estabilidade em ZFS é:
Cache: None + Async IO: io_uring.
Não opere no escuro. Se a integridade dos dados é vital, desligue a "ajuda" do cache do Host e deixe o sistema de arquivos robusto fazer o trabalho dele.

Sarah 'The Backup' Connor
Gerente de Recuperação de Desastres
Seus dados não estão seguros até que ela diga que estão. Especialista em estratégias de backup imutável e RPO/RTO.