Proxmox HA sem Ceph: A Realidade da Replicação ZFS e o Mito dos 2 Nós
Cluster Proxmox de 2 nós funciona? Domine a arquitetura de HA com ZFS Replication e QDevice. Entenda os riscos de RPO, evite split-brain e economize hardware.
Há uma sedução perigosa no mundo da virtualização para pequenas e médias empresas (SMB) e Edge Computing: a promessa de Alta Disponibilidade (HA) com apenas dois servidores e nenhum storage compartilhado (SAN/NAS). O marketing diz que é fácil. A engenharia diz que é um campo minado se você não entender a física por trás dos dados.
O Ceph é o padrão ouro para Proxmox, mas ele exige um "imposto": latência de rede ultrabaixa, muita CPU e, crucialmente, um mínimo de três nós (idealmente mais) para garantir consistência e performance. Se você tem apenas dois nós e um orçamento limitado, o Ceph não é apenas caro; é uma má escolha técnica.
A alternativa nativa é a Replicação ZFS. Mas, ao contrário do Ceph, que é síncrono e distribuído, o ZFS é assíncrono e local. Este artigo disseca a anatomia dessa arquitetura, destrói o mito de que "2 nós bastam" e ensina a medir o que você realmente perde quando um nó falha.
O Custo da Latência e a Escolha pela Assincronia
Para entender por que escolhemos ZFS Replication em vez de Ceph em cenários de 2 nós, precisamos olhar para a latência de gravação.
No Ceph, uma gravação (write) só é confirmada ao sistema operacional da VM quando foi escrita em X réplicas através da rede. Isso garante RPO (Recovery Point Objective) zero, mas introduz latência de rede no caminho crítico do IOPS.
Na Replicação ZFS, a gravação acontece na velocidade do disco local (NVMe/SSD). O dado é confirmado instantaneamente. Apenas depois, em um intervalo agendado, o sistema empacota as mudanças e as envia para o outro nó.
O Trade-off:
Ceph: RPO Zero, mas latência de escrita mais alta e exigência de hardware robusto.
ZFS Replication: Performance de disco local, hardware simples, mas RPO > Zero (perda de dados é possível).
Se você aceita que, em caso de desastre total de um nó, pode perder os últimos 5 ou 15 minutos de dados, o ZFS Replication oferece uma performance por dólar imbatível.
Matemática do Quorum: O Pacto Suicida dos 2 Nós
O erro número um em clusters de dois nós é ignorar a matemática do voto. Um cluster precisa de quórum ($50% + 1$) para funcionar.
Se você tem 2 nós (A e B) e o cabo de rede entre eles se rompe:
O Nó A tem 1 voto. Total de nós vivos que ele vê: 1. (50% do total). Não tem quórum.
O Nó B tem 1 voto. Total de nós vivos que ele vê: 1. (50% do total). Não tem quórum.
Resultado: Ambos os nós bloqueiam as operações de cluster ou reiniciam (fencing) para evitar corrupção de dados. Seu HA causou o downtime que deveria prevenir.
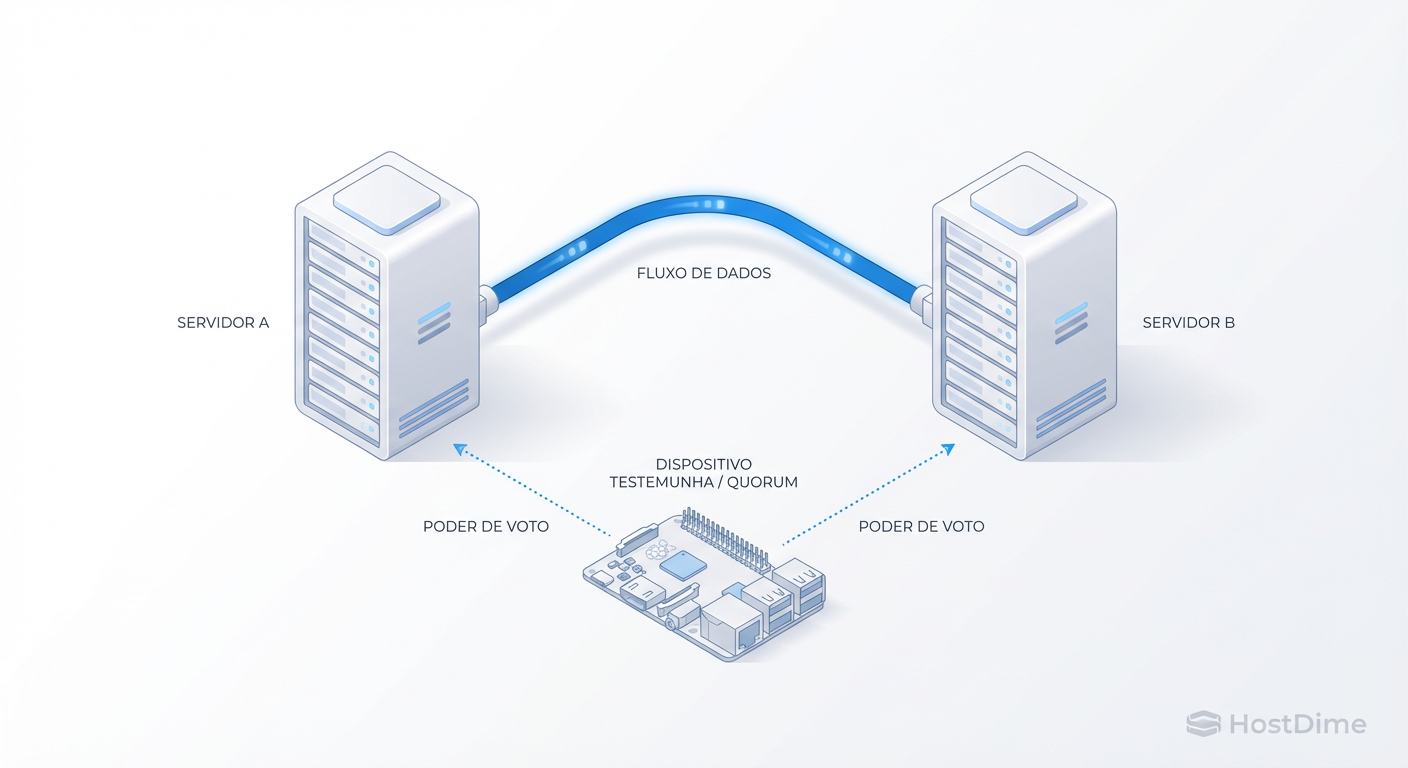
Para resolver isso, precisamos de um terceiro voto que não carregue dados, apenas decida quem vive. Chamamos isso de QDevice (Quorum Device). Pode ser um Raspberry Pi, uma VM em outra máquina ou até um PC de escritório, rodando o corosync-qnetd.
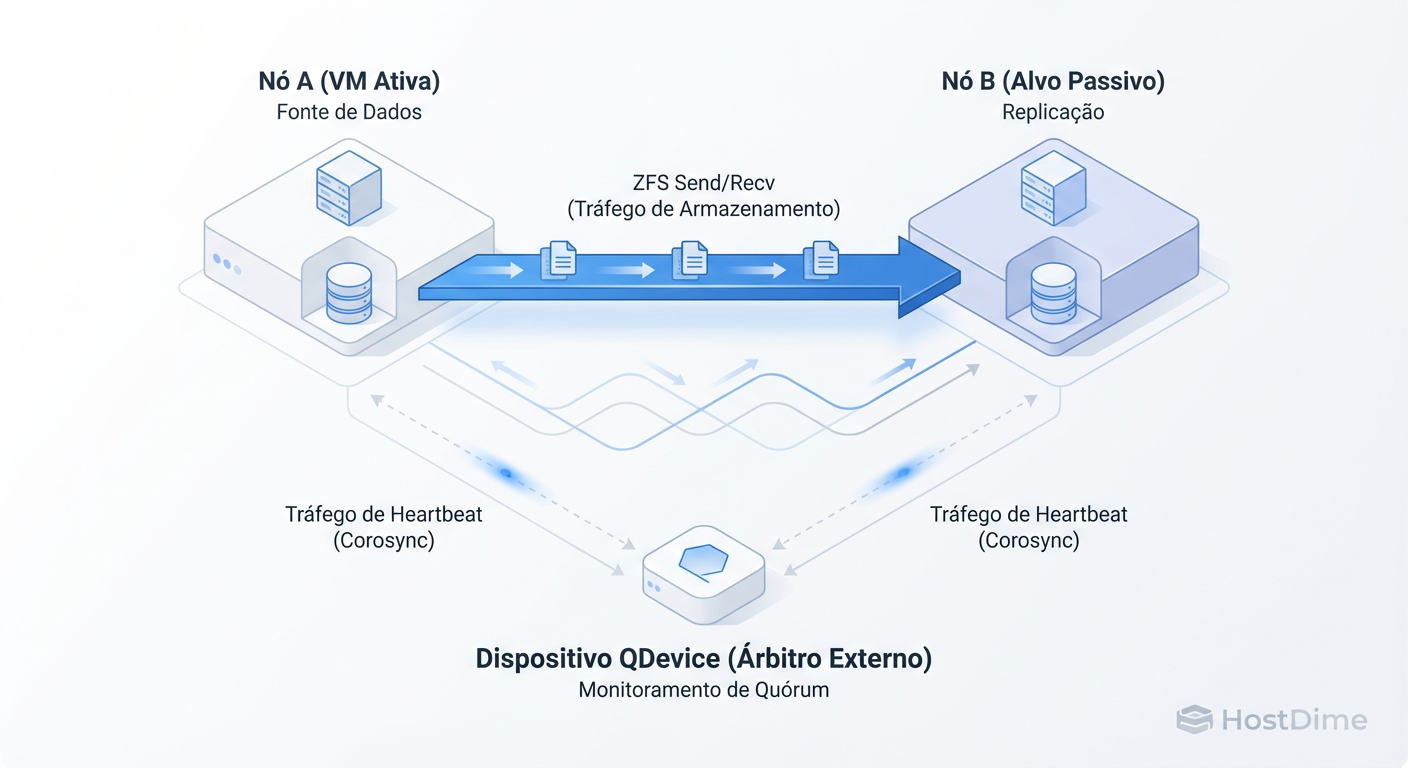 Figura: Arquitetura de 2+1: O tráfego de dados (ZFS) corre separado do tráfego de votos (Corosync). O QDevice é o árbitro que impede o split-brain.
Figura: Arquitetura de 2+1: O tráfego de dados (ZFS) corre separado do tráfego de votos (Corosync). O QDevice é o árbitro que impede o split-brain.
Com o QDevice, a matemática muda. Temos 3 votos. Se o Nó A cai, o Nó B + QDevice somam 2 votos (66%). O cluster sobrevive.
Implementando o Árbitro
Não confie na sorte. Instale o QDevice.
No dispositivo externo (ex: Debian/Raspberry Pi):
apt update && apt install corosync-qnetd
Nos nós do Proxmox:
apt update && apt install corosync-qdevice
# Adicione o QDevice (execute em apenas um nó)
pvecm qdevice setup <IP-DO-QDEVICE>
Valide com pvecm status. Você deve ver "Votes: 3". Se não vir, seu HA é uma ilusão.
Anatomia da Replicação ZFS: O que acontece "Under the Hood"
Diferente do DRBD ou de espelhamentos síncronos, o ZFS não envia blocos individuais assim que são escritos. Ele opera em batches baseados em snapshots.
O ciclo, simplificado, é:
Freeze/Snap: O ZFS tira um snapshot instantâneo do volume da VM no Nó A.
Delta Calc: Ele compara esse snapshot com o último snapshot enviado com sucesso ao Nó B.
Stream: Ele envia apenas os blocos modificados (o delta) através da rede via
zfs send.Receive: O Nó B recebe e aplica o stream (
zfs recv).Cleanup: Snapshots antigos (além da política de retenção) são removidos.
Isso significa que o tráfego de rede não é constante; é pulsante. A cada X minutos (o menor intervalo no Proxmox é 1 minuto), você terá um pico de uso de banda.
A Ilusão do RPO Zero: Calculando a Perda Real
Aqui é onde a realidade bate na porta. Muitos administradores configuram a replicação para "cada 15 minutos" e dizem ao chefe que, no pior caso, perderão 15 minutos de dados. Isso está errado.
O RPO real é a soma de: $$RPO = \text{Intervalo de Agendamento} + \text{Tempo de Transferência}$$
Se sua VM tem uma alta taxa de alteração de dados (churn rate), o "delta" de 15 minutos pode ser gigabytes de dados. Se levar 5 minutos para transferir esses dados pela rede, e o nó primário falhar no final dessa transferência, você perdeu dados desde o início do ciclo.
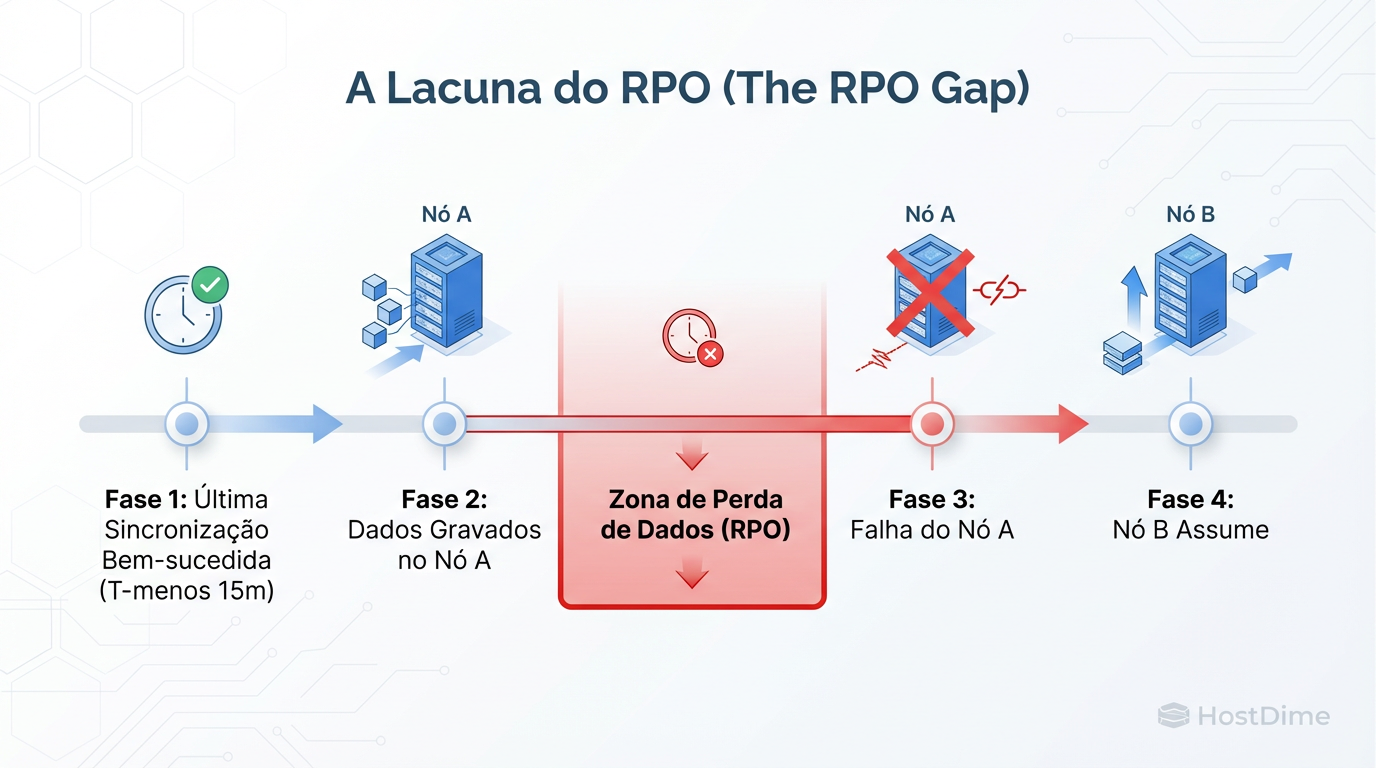 Figura: A dura realidade do RPO: Em replicação assíncrona, qualquer dado escrito após a última sincronização e antes da falha é perdido. HA aqui garante disponibilidade de serviço, não integridade total de dados recentes.
Figura: A dura realidade do RPO: Em replicação assíncrona, qualquer dado escrito após a última sincronização e antes da falha é perdido. HA aqui garante disponibilidade de serviço, não integridade total de dados recentes.
O Perigo do "Schedule": Se o nó A morre antes do próximo snapshot ser completado e enviado, o nó B só tem o estado da VM de 15 (ou 20) minutos atrás. Quando o HA ativar o nó B, a VM vai "voltar no tempo".
Para bancos de dados, isso é crítico. O sistema de arquivos estará consistente (graças ao snapshot atômico), mas as transações de negócios dos últimos minutos desaparecerão.
Impacto na Performance e Saturação de Link
Como a replicação é pulsante, ela cria o que chamamos de "Micro-bursts". Se você usa a mesma interface de rede para o tráfego da VM (banco de dados, web server) e para a replicação do ZFS, prepare-se para problemas.
Durante o zfs send, o throughput pode saturar facilmente uma interface de 1Gbps ou até 10Gbps, dependendo da velocidade dos discos. Quando o link satura, a latência das aplicações da VM dispara.
Como medir e mitigar
Não adivinhe. Meça. Use o iftop durante um ciclo de replicação para ver o impacto.
A Regra de Ouro do Isolamento: Sempre separe o tráfego de Cluster/Replicação do tráfego de VM.
Rede 1 (Public/VM): Acesso dos usuários.
Rede 2 (Cluster/Replication): Corosync e ZFS Send.
Se possível, use conexões "Back-to-Back" (cabo direto entre os servidores) para a replicação. Isso elimina o switch como ponto de falha e gargalo para o tráfego de dados massivo.
Para verificar a velocidade de gravação e leitura do ZFS que alimenta a replicação:
zpool iostat -v 1
Observe as colunas write e bandwidth. Se durante a replicação a latência de leitura do disco disparar, seus discos não estão aguentando ler o snapshot para enviar e servir a VM ao mesmo tempo.
Fluxo de Recuperação: O Passo a Passo Frio
O que acontece, exatamente, quando você puxa o cabo de energia do Nó A?
Detecção: O Corosync no Nó B percebe o silêncio do Nó A.
Votação: O Nó B consulta o QDevice. Ambos concordam: "O Nó A sumiu. Nós somos a maioria."
Fencing (Opcional mas recomendado): Se configurado (via hardware watchdog ou IPMI), o cluster garante que o Nó A esteja morto para evitar que ele volte e corrompa dados.
Decisão de HA: O Resource Manager do Proxmox vê que a VM 100 estava no Nó A e deve estar rodando.
Localização do Storage: Ele verifica o storage local ZFS do Nó B. Encontra o volume replicado.
Boot: A VM é iniciada usando o último snapshot completado.
Atenção: A VM vai bootar como se tivesse sofrido um desligamento abrupto (crash-consistent). O sistema operacional fará fsck, bancos de dados farão recuperação de journal.
Veredito Técnico Operacional
Proxmox HA com ZFS Replication e 2 nós é uma solução robusta e econômica, mas exige honestidade intelectual. Não é mágica.
Instale um QDevice. Sem ele, 2 nós não funcionam.
Calcule seu RPO real. Não prometa zero data loss.
Isole sua rede. Não deixe a replicação matar a performance da produção.
Se você controlar essas variáveis, terá uma infraestrutura resiliente que custa uma fração de um cluster Ceph ou VMware vSAN, com a confiabilidade da matemática ao seu lado.

Julia M. Santos
Enterprise Storage Consultant
Consultora para Fortune 500. Traduz 'economês' para 'técniquês' e ajuda empresas a não gastarem milhões em SANs desnecessárias.