Proxmox: Matando o Mito 'Disco Local vs. Storage' (Guia de Arquitetura)

Pare de adivinhar. Entenda os trade-offs reais de latência e confiabilidade entre ZFS Local, NFS/iSCSI e Ceph no Proxmox. Sem hype, apenas engenharia.
Há uma guerra religiosa nos fóruns de virtualização que dura décadas. De um lado, os puristas do Storage Centralizado (SAN/NAS) gritando "Alta Disponibilidade!". Do outro, os defensores do Disco Local gritando "Performance!".
Como engenheiro de performance, eu digo: ambos estão errados porque estão fazendo a pergunta errada.
A dicotomia "Local vs. Network" é uma simplificação grosseira. No mundo real, a física do I/O não se importa com a marca do seu storage, ela se importa com a latência de interrupção, overhead de protocolo e garantia de persistência.
Este guia não é sobre "qual é melhor". É uma autópsia de como o dado trafega, onde ele engarrafa e como você prova isso com números, não com palpites.
A Física da Latência: O Caminho do Dado
Para entender por que um banco de dados voa em um NVMe local e rasteja em um NFS (mesmo com rede 10Gbps), precisamos dissecar o caminho da escrita.
Quando seu PostgreSQL faz um COMMIT, ele exige que o dado esteja fisicamente seguro no disco (chamada fsync). O sistema operacional não pode mentir aqui; ele precisa esperar a confirmação do hardware.
Local (NVMe): CPU -> Barramento PCIe -> Controlador NVMe -> NAND Flash.
- Tempo: ~20 a 100 microssegundos.
- Overhead: Mínimo. É quase conversa direta com o hardware.
Network (iSCSI/NFS): CPU -> Stack TCP/IP -> Driver da NIC -> Cabo -> Switch -> Cabo -> NIC do Storage -> CPU do Storage -> Stack TCP/IP -> Controlador de Disco -> Disco.
- Tempo: 500 microssegundos a 5+ milissegundos.
- Overhead: Massivo. Serialização de pacotes, ACKs de TCP, filas de switch.
A rede adiciona uma "taxa fixa" de latência que nenhuma largura de banda (Throughput) consegue resolver. Você não conserta latência com um cabo mais grosso (40Gbps/100Gbps); a velocidade da luz e o processamento de pacotes continuam os mesmos.
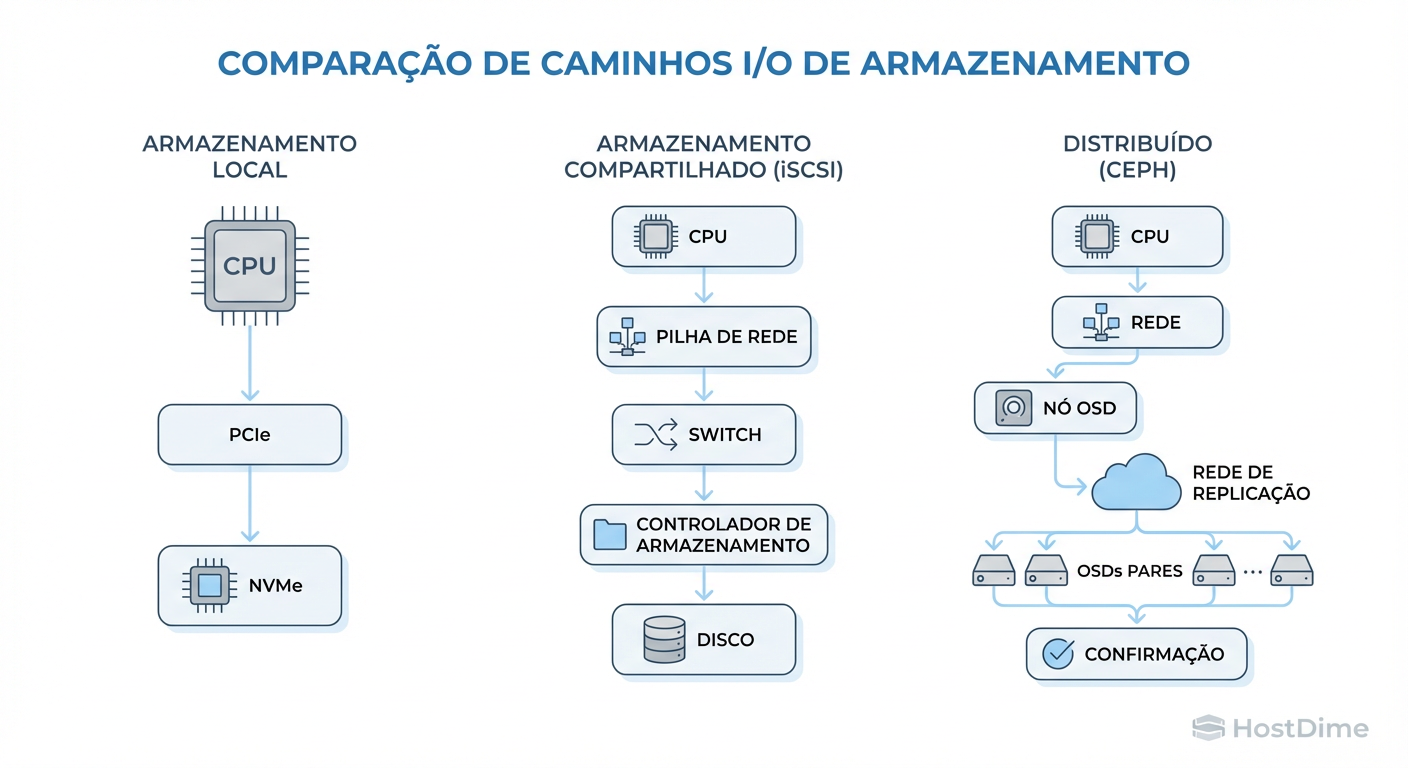 Figura: A Escada da Latência: Cada salto de rede e confirmação de escrita adiciona milissegundos que matam bancos de dados transacionais.
Figura: A Escada da Latência: Cada salto de rede e confirmação de escrita adiciona milissegundos que matam bancos de dados transacionais.
Onde a intuição falha
A maioria dos administradores olha para o gráfico de rede, vê 500Mbps de tráfego em um link de 10Gbps e pensa: "A rede está sobrando". Erro fatal. Para storage, a métrica rainha não é Throughput (MB/s), é Latência por I/O. Se cada escrita pequena precisa viajar pela rede e voltar, seu banco de dados se torna single-threaded esperando o "ok" da rede, mesmo que a banda esteja 95% livre.
ZFS Local + Replicação: O "Quase-HA" que vence em Performance
Se o seu SLA exige performance bruta de IOPS (Input/Output Operations Per Second) para bancos de dados transacionais, o disco local é imbatível.
No Proxmox, o padrão de ouro moderno é ZFS Local com NVMe.
O Modelo de Operação
O ZFS (Zettabyte File System) gerencia os discos diretamente. Ele usa a RAM como um cache de leitura adaptativo (ARC) e organiza as escritas de forma atômica. Ao usar ZFS Local, você elimina o "Homem do Meio" (a rede).
O "Pulo do Gato": Replicação ZFS (pve-zsync)
O argumento contra disco local sempre foi: "Se o servidor queimar, perco os dados ou demoro para restaurar". O Proxmox resolveu isso com a Replicação ZFS.
Ela envia apenas os deltas (diferenças) dos blocos alterados para outro nó do cluster.
Pode rodar a cada 1 minuto.
Crucial: É assíncrono. A escrita no disco local não espera a replicação terminar. O
fsyncdo banco de dados retorna assim que o disco local confirma.
Callout de Risco: A replicação ZFS tem um RPO (Recovery Point Objective) maior que zero. Se o nó explodir agora, você perde os dados gerados desde a última replicação (ex: últimos 59 segundos). Se seu negócio não suporta perder 1 minuto de dados em caso de catástrofe total do hardware, disco local não é para você.
Storage Compartilhado (SAN/NAS): O Gargalo Invisível
Storage centralizado (um TrueNAS, um storage Dell/HP via iSCSI ou NFS) é vendido como a solução para Alta Disponibilidade (HA). Se um nó do Proxmox cai, a VM reinicia no outro nó instantaneamente porque os "discos" são visíveis por todos.
O Custo Oculto: SPOF e "Noisy Neighbors"
SPOF (Single Point of Failure): Se o seu Storage Centralizado cair, todo o seu cluster para. Você trocou vários pontos de falha pequenos (discos locais) por um ponto de falha gigantesco.
O Efeito Vizinho Barulhento: Todas as VMs de todos os nós competem pela mesma fila de entrada do Storage e pelo mesmo link de rede. Um servidor de arquivos fazendo backup pode saturar a fila de comandos, fazendo o banco de dados da aplicação crítica engasgar, mesmo que estejam em nós físicos diferentes.
Use storage compartilhado para cargas de trabalho que exigem:
Migração ao vivo (Live Migration) constante sem tempo de cópia.
Aplicações "stateless" (servidores web, containers app) onde o disco é pouco usado.
Ceph e Hiperconvergência: O Custo do Consenso
O Ceph é a menina dos olhos da hiperconvergência no Proxmox. Ele transforma os discos locais de todos os nós em um "storage compartilhado virtual" distribuído. Parece mágica: você ganha HA e usa discos locais.
Mas a física cobra seu preço, e a moeda é a Latência de Escrita.
O Algoritmo da Lentidão Necessária
Para garantir consistência (que o dado não corrompa), o Ceph precisa de Quorum. Quando uma VM escreve um bloco no Ceph:
O dado vai para o OSD (disco) primário.
O OSD primário replica o dado pela rede para os OSDs secundários e terciários (Replica 3x).
O primário espera a confirmação de escrita dos secundários.
Só então ele diz ao sistema operacional da VM: "Escrita concluída".
Isso triplica (ou mais) a latência de rede e disco para cada operação de escrita.
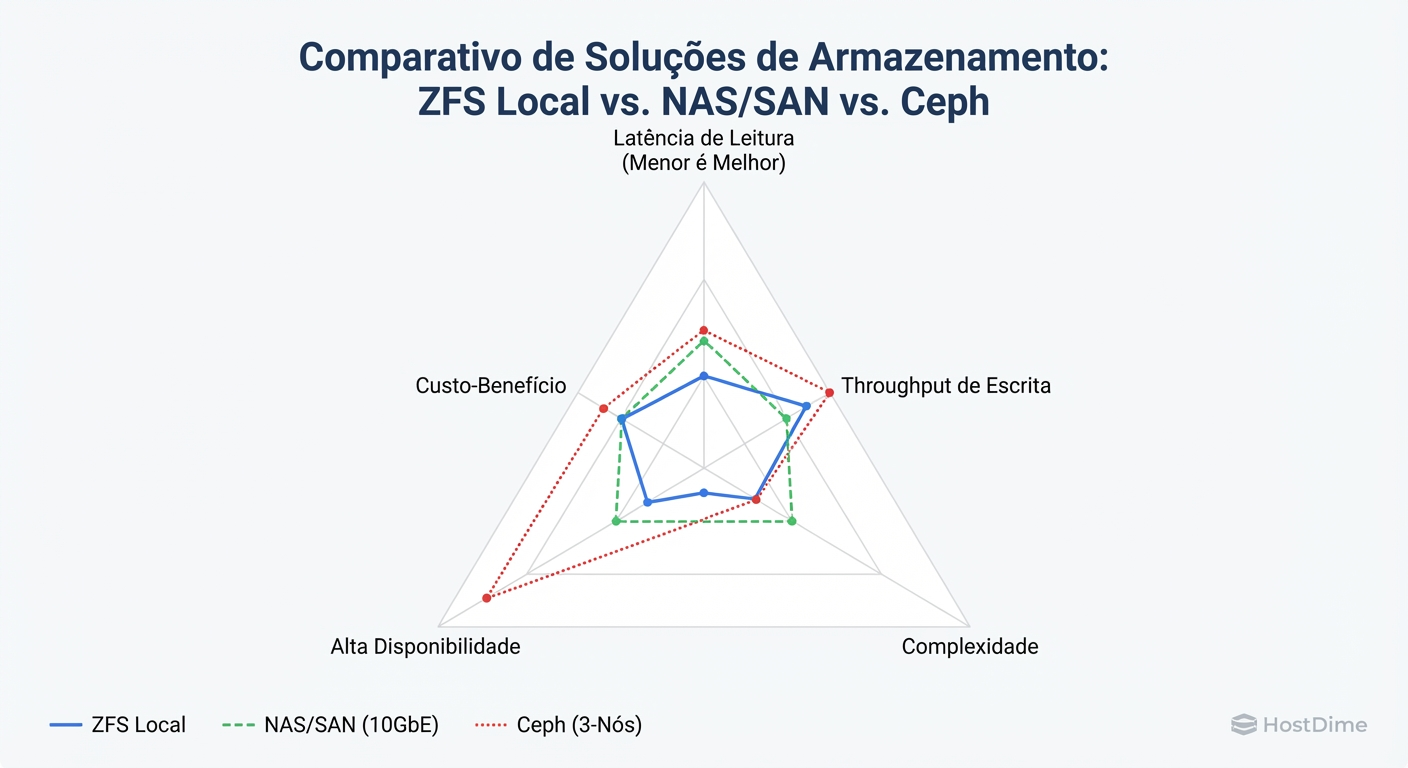 Figura: O Triângulo de Trade-offs: Não existe solução mágica. Você paga pela Alta Disponibilidade (HA) com latência ou complexidade.
Figura: O Triângulo de Trade-offs: Não existe solução mágica. Você paga pela Alta Disponibilidade (HA) com latência ou complexidade.
Callout de Performance: Jamais, em hipótese alguma, rode Ceph em rede de 1Gbps ou sem SSDs de classe Enterprise (com proteção contra perda de energia - PLP). A latência de reconvergir o cluster em HDDs mecânicos ou SSDs de consumo fará seu cluster parar.
Como Medir o Gargalo (Metodologia Científica)
Não confie no que o vendedor do storage disse. Não confie no "feeling". Meça.
1. A Ferramenta: Fio (Flexible I/O Tester)
Esqueça o dd. O dd mede throughput sequencial, o que é inútil para simular um sistema real. Use o fio para simular I/O aleatório com sincronização forçada (o pior cenário).
Comando para teste de Latência de Escrita (O "Teste da Verdade"):
fio --name=teste_latencia \
--ioengine=libaio \
--rw=randwrite \
--bs=4k \
--direct=1 \
--sync=1 \
--numjobs=1 \
--iodepth=1 \
--size=1G \
--runtime=60 \
--time_based \
--group_reporting
Por que esses parâmetros?
--rw=randwrite: Simula um banco de dados fragmentado.--sync=1: Obriga o disco a confirmar cada escrita (mata o cache de RAM). É aqui que storages de rede morrem.--iodepth=1: Mede a latência pura de uma única transação, sem paralelismo para mascarar a lentidão.
2. Interpretando os Resultados
Olhe para a saída clat (Completion Latency) percentil 99th (99.00th=[...]).
< 100 us (microssegundos): NVMe Local (Excelente para DBs pesados).
< 1 ms (milissegundo): SSD SATA Local ou All-Flash Array High-End (Muito bom).
1 ms - 5 ms: Ceph bem otimizado ou iSCSI 10Gbps decente (Aceitável para uso geral).
> 10 ms: Storage mecânico ou rede congestionada. (Seu banco de dados vai travar a aplicação).
3. Observando "Ao Vivo": iostat
No host Proxmox, use iostat -x 1.
Observe a coluna %iowait. Se a CPU está alta em iowait, significa que o processador está ocioso esperando o disco responder. Isso é a prova cabal de que seu storage é o gargalo.
Matriz de Decisão: O que escolher?
Não existe "Best Practice", existe alinhamento de requisitos. Use esta matriz para decidir sua arquitetura no Proxmox.
| Cenário | Arquitetura Recomendada | O "Porquê" Técnico | Trade-off Aceito |
|---|---|---|---|
| Banco de Dados Pesado (SQL, Alta Transação) | ZFS Local (NVMe) + Replicação | Menor latência física possível (PCIe). O fsync é imediato. |
RPO de alguns minutos em caso de falha total do nó. Sem Live Migration instantâneo. |
| Virtualização Geral (AD, Web Servers, App Servers) | Ceph (HCI) ou NFS/iSCSI | Facilidade de gestão e HA automatizado. A latência extra é tolerável. | Custo de hardware (Rede 10G+ obrigatória) ou complexidade (Ceph). |
| Arquivamento / File Server | NAS Dedicado (Pass-through ou NFS) | Custo por TB menor. Discos mecânicos (HDD) são aceitáveis. | Performance de IOPS baixa. |
| Cluster de Baixo Orçamento (Sem switch 10G) | ZFS Local | Ceph e iSCSI vão engasgar em 1Gbps. Local é a única opção viável. | Gestão manual de HA e backups. |
Veredito Técnico Pragmática
Se você precisa de IOPS, traga o dado para perto da CPU (Local). Se você precisa de conveniência e HA instantâneo, afaste o dado (Network/Ceph), mas prepare a carteira para mitigar a latência com redes rápidas e discos enterprise.
Pare de tentar vencer a física. Entenda-a, meça-a e projete de acordo.

Marta G. Oliveira
DevOps Engineer & Storage Nerd
Automatiza provisionamento de storage com Terraform e Ansible. Defensora do 'Infrastructure as Code' para storage.