Proxmox: Storage Local vs. Compartilhado — A Batalha entre Latência e Mobilidade
Pare de seguir dogmas. Analisamos o 'imposto de rede' do storage compartilhado contra a performance bruta do disco local (ZFS) para decidir sua arquitetura.
Existe uma doença comum em administradores de sistemas que estão montando seus primeiros clusters Proxmox: a obsessão prematura pela "Alta Disponibilidade" (HA). O raciocínio geralmente segue um script de marketing: "Se eu quiser mover minhas VMs de um nó para outro sem desligar, preciso de um storage compartilhado. Logo, preciso de um SAN, um NAS parrudo ou montar um cluster Ceph hiperconvergente."
Pare. Respire.
Antes de gastar o orçamento da empresa em switches 100GbE ou sacrificar metade da performance de I/O em nome de uma mobilidade que você talvez use uma vez por mês, precisamos conversar sobre física.
A escolha entre storage local (NVMe/SSD no chassi) e storage compartilhado (NFS, iSCSI, Ceph) não é uma questão de "features". É uma negociação brutal entre Latência e Mobilidade. Você raramente pode ter os dois no nível máximo sem gastar uma fortuna obscena.
Vamos desmontar a ilusão do "Enterprise" e olhar para o caminho que o seu dado percorre.
A Física do I/O: Onde a velocidade morre
Para entender por que o storage compartilhado muitas vezes decepciona em cargas de trabalho intensas (como bancos de dados), você precisa visualizar a jornada de um bloco de dados.
Quando uma VM grava no disco local (digamos, um ZFS em cima de um NVMe), o caminho é curto:
A aplicação chama
fsync.O kernel do host processa.
O barramento PCIe entrega ao controlador NVMe.
O flash grava.
O ack (confirmação) volta.
Isso acontece em microssegundos.
Agora, olhe para o cenário de rede (iSCSI ou Ceph). O dado precisa descer a pilha TCP/IP, ser fragmentado em pacotes, entrar na fila da placa de rede, atravessar o cabo, passar pelo switch (store-and-forward), chegar ao storage destino, subir a pilha TCP/IP dele, ser processado pelo software de storage e, finalmente, ir para o disco. E o pior: a CPU da VM fica esperando a confirmação de que o dado foi gravado (o commit) antes de prosseguir.
 Figura: O Caminho do Dado: Visualizando onde a latência se esconde. O storage compartilhado introduz múltiplas trocas de contexto e hops de rede que o disco local ignora.
Figura: O Caminho do Dado: Visualizando onde a latência se esconde. O storage compartilhado introduz múltiplas trocas de contexto e hops de rede que o disco local ignora.
A latência de rede é o assassino silencioso de performance. Mesmo em redes 10GbE ou 25GbE, o overhead de protocolo e serialização adiciona milissegundos preciosos. Para um arquivo de vídeo grande (throughput), isso não importa. Para um banco de dados transacional fazendo milhares de pequenas escritas aleatórias (IOPS), é a diferença entre um sistema ágil e um sistema que parece estar rodando em câmera lenta.
O Custo Oculto da Sincronização
Em sistemas distribuídos como o Ceph, a situação é mais crítica. Para garantir a integridade, o Ceph precisa gravar o dado em múltiplos nós (geralmente 3) e receber a confirmação de todos eles antes de dizer à sua VM "ok, está salvo".
Sua velocidade de escrita não é a velocidade do seu disco mais rápido. É a velocidade do seu disco mais lento + a latência de rede mais alta + o tempo de consenso do algoritmo.
ZFS Local + Replicação: O "Quase HA" que você deveria usar
Se você não precisa de Live Migration instantânea (mover a VM ligada sem perder um ping), o Proxmox oferece uma arma poderosa que muitos ignoram: ZFS Local com Replicação Assíncrona.
Neste modelo, suas VMs rodam em SSDs/NVMes locais. A performance é nativa. O iowait é inexistente. O ZFS, então, envia snapshots incrementais (apenas as diferenças) para outro nó do cluster a cada X minutos (o mínimo é 1 minuto).
O Trade-off:
Vantagem: Performance de I/O brutal. Simplicidade de configuração. Sem necessidade de switches complexos ou Ceph tuning.
Desvantagem: Se o nó morrer subitamente, você perde os dados gerados desde a última replicação (máximo de 1 minuto no setup mais agressivo). E você precisa reiniciar a VM no outro nó (downtime de alguns minutos).
Para 95% das cargas de trabalho SMB (Small/Medium Business), perder 60 segundos de dados em uma falha catastrófica de hardware é aceitável em troca de ter um sistema 10x mais rápido durante 100% do tempo de operação normal.
Callout de Risco: A replicação do ZFS exige que os nomes dos Storage Pools sejam idênticos em ambos os nós (ex:
zfs-localem ambos). Sem isso, o Proxmox não consegue mapear o destino.
Storage Compartilhado: O Preço da Mobilidade
Se você realmente precisa de Live Migration (ex: manutenção de hardware durante o dia sem desconectar usuários), o storage compartilhado é obrigatório. Mas escolha seu veneno com sabedoria.
NFS / iSCSI (O Clássico)
É simples e funciona. Um NAS central (TrueNAS, Synology, NetApp) serve os discos.
O Perigo: O NAS vira um Ponto Único de Falha (SPoF). Se o switch ou o NAS travarem, todas as VMs do cluster congelam instantaneamente. O sistema de arquivos entra em modo read-only ou corrompe.
Mitigação: Requer hardware redundante caro (controladoras duplas, fontes duplas, switches empilhados).
Ceph (O Moderno)
Hiperconvergência. O storage é distribuído entre os próprios nós do Proxmox.
A Realidade: Ceph é fantástico para escalabilidade e resiliência, mas é faminto por recursos. Ele "come" CPU e RAM para gerenciar o mapa de dados.
Regra de Ouro: Nunca rode Ceph sem rede dedicada de 10GbE+ para o tráfego de replicação (cluster network) e discos SSD/NVMe de classe Enterprise (com proteção contra perda de energia - PLP). Ceph em HDDs mecânicos ou SSDs baratos sem PLP é pedir para sofrer.
Benchmarks que Importam: Pare de olhar para Leitura Sequencial
Fabricantes de disco adoram mostrar números de leitura sequencial ("5000 MB/s!"). Isso é irrelevante para virtualização. O sistema operacional é um caos de pequenas leituras e escritas aleatórias.
Para medir o impacto real da sua escolha de storage (Local vs. Rede), você deve testar Random 4K Writes com Sync. Isso simula o pior cenário: um banco de dados gravando logs de transação.
Use o fio dentro de uma VM para testar a realidade, não no host.
# Comando para testar latência de escrita síncrona (O teste da verdade)
# Rode isso dentro da VM para ver o que a aplicação sente.
fio --name=teste_latencia \
--ioengine=libaio \
--rw=randwrite \
--bs=4k \
--direct=1 \
--fsync=1 \
--size=1G \
--numjobs=1 \
--runtime=60 \
--group_reporting
Como ler o resultado:
Olhe para o IOPS.
Olhe para a latência clat (completion latency) no percentil 99th (99.00th).
NVMe Local: Latência de ~0.05ms a 0.2ms.
SSD SATA Local: ~1ms a 3ms.
Ceph (bem otimizado): ~2ms a 10ms.
NFS/iSCSI (Rede 1Gbps): Prepare-se para chorar.
Se a latência de sync passar de 10-20ms, bancos de dados começarão a reclamar e a interface de usuário das VMs ficará lenta ("laggy").
Matriz de Decisão: O Quadrante da Realidade
Não existe "melhor". Existe o adequado para o SLA (Service Level Agreement) e para o orçamento. A decisão deve ser baseada no custo do downtime versus o custo da performance.
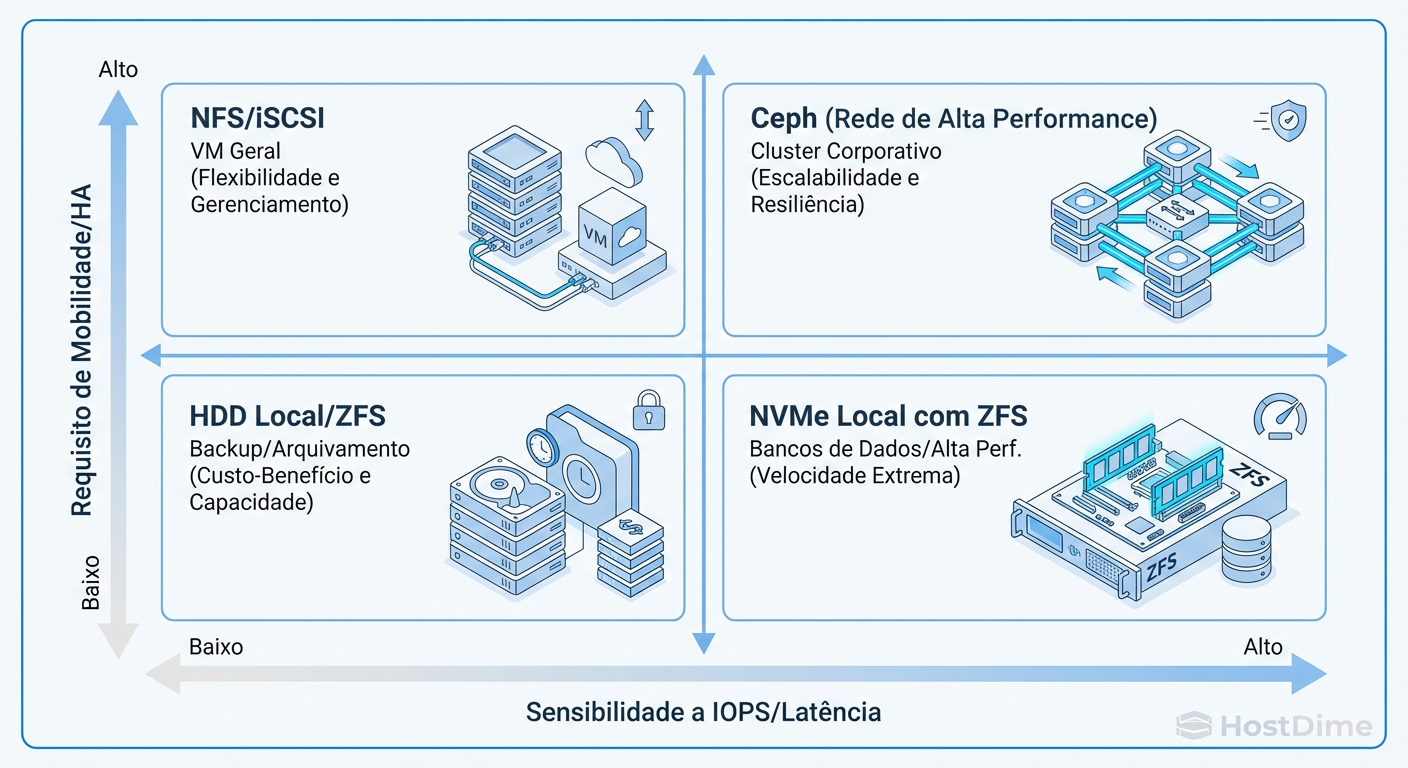 Figura: O Quadrante de Decisão: Não existe 'melhor', existe o adequado para a carga de trabalho.
Figura: O Quadrante de Decisão: Não existe 'melhor', existe o adequado para a carga de trabalho.
Resumo Pragmático para Tomada de Decisão:
| Cenário | Solução Recomendada | Por quê? |
|---|---|---|
| Banco de Dados Pesado | NVMe Local (ZFS) | Latência é rei. Rede introduz jitter inaceitável. Use replicação ZFS para backup frequente. |
| Cluster de Computação (HPC) | Local | A CPU não pode esperar o I/O de rede. |
| Servidor de Arquivos / Web | Ceph / NFS | Carga de leitura alta, escrita baixa. Mobilidade facilita manutenção. |
| Homelab / SMB (Orçamento Baixo) | ZFS Local + Replicação | Melhor custo-benefício. Ceph exige hardware demais para clusters pequenos (< 3 nós). |
| Enterprise (SLA 99.99%) | Ceph (All-Flash) ou SAN | O custo do hardware justifica a necessidade de zero downtime. |
Veredito Técnico: Simplifique até doer
A complexidade é o inimigo da disponibilidade. Um cluster Ceph mal configurado vai cair mais vezes do que um servidor standalone bem cuidado.
Se você não tem uma equipe dedicada para gerenciar storage distribuído, o Storage Local com ZFS é a aposta mais segura e performática. A mobilidade das VMs é uma conveniência incrível, mas pergunte-se: vale a pena sacrificar 50% da performance do seu hardware todos os dias apenas para poder migrar uma VM sem desligá-la uma vez a cada três meses?
Meça, teste o fsync, e decida com base nos números, não no hype.

Thomas 'Raid0' Wright
High-Performance Computing Researcher
Trabalha com supercomputadores. Para ele, velocidade é tudo, e redundância é problema do software.