QLC SSDs vs. Nearline HDDs: A Morte do Disco Mecânico no Data Center de IA?

A transição de HDDs Nearline para QLC SSDs em workloads de IA não é luxo, é física. Analisamos densidade, Watts/TB e o temido 'Write Cliff' para provar o TCO.
Vamos ser honestos: ninguém gosta de gastar orçamento de armazenamento. É o "imposto" que pagamos para poder rodar as coisas divertidas (GPUs, LLMs, bancos de dados vetoriais). Mas no cenário atual de IA, onde um cluster de H100s custa o PIB de uma pequena ilha, alimentar essas bestas com dados via discos mecânicos (HDDs) é como tentar abastecer um Fórmula 1 usando um canudinho de refrigerante.
Há um hype enorme em torno do fim do HDD. Os fabricantes de Flash dizem que o disco giratório morreu. Os fabricantes de HDD dizem que o custo por TB do Flash ainda é proibitivo. A verdade, como sempre, está no meio — e nos detalhes sórdidos da física dos semicondutores.
Vamos dissecar se o SSD QLC (Quad-Level Cell) é realmente o assassino do HDD Nearline ou apenas uma armadilha cara para quem não sabe configurar seu sistema de arquivos.
O Que é Armazenamento QLC Enterprise?
Definição Rápida: SSDs QLC (Quad-Level Cell) armazenam 4 bits de dados por célula de memória, resultando em alta densidade e menor custo por gigabyte comparado ao TLC ou MLC. No contexto Enterprise, eles substituem HDDs em cargas de leitura intensiva (como Data Lakes de IA e CDNs), trocando a durabilidade de escrita (DWPD) por eficiência energética (Watts/TB) e latência de leitura drasticamente menor.
A Física do Gargalo: Por que HDDs de 7.2k não alimentam GPUs H100
O problema não é a largura de banda sequencial. Um array de 24 HDDs SAS em RAID 60 pode entregar throughput decente. O problema é a latência e a natureza caótica do I/O de treinamento de IA.
Um HDD de 7.200 RPM é limitado pelas leis da física. A cabeça de leitura precisa se mover fisicamente e o prato precisa girar. Isso nos dá um teto rígido de cerca de 80-160 IOPS (operações de entrada/saída por segundo) por disco em acesso aleatório.
Quando você está treinando um modelo, você não está apenas lendo um arquivo gigante linearmente. Você está fazendo shuffling de datasets, lendo milhões de pequenos arquivos de imagem ou tokens de texto, e gravando checkpoints massivos periodicamente.
Se suas GPUs H100 (que custam $30k cada) ficarem paradas esperando o iowait do disco, você está queimando dinheiro. É uma questão de Custo de Oportunidade da GPU.
Cenário HDD: A GPU espera 10ms por um batch de dados.
Cenário NVMe QLC: A GPU espera 100µs (microssegundos).
Essa diferença de ordens de grandeza significa que, para manter as GPUs saturadas, você precisaria de racks inteiros de HDDs (Short-stroking para ganhar IOPS) contra meio U de SSDs NVMe.
Entendendo a Célula QLC: 16 Estados de Voltagem e o Custo
Aqui é onde o marketing morre e a engenharia começa. Para fazer o SSD ficar barato, os engenheiros não mudaram a magia, eles apenas apertaram mais dados no mesmo espaço.
SLC (Single Level Cell): 1 bit. Estado 0 ou 1. Fácil de ler, fácil de gravar. Rápido e imortal.
QLC (Quad Level Cell): 4 bits. Isso significa $2^4 = 16$ estados de voltagem diferentes dentro de uma única célula microscópica.
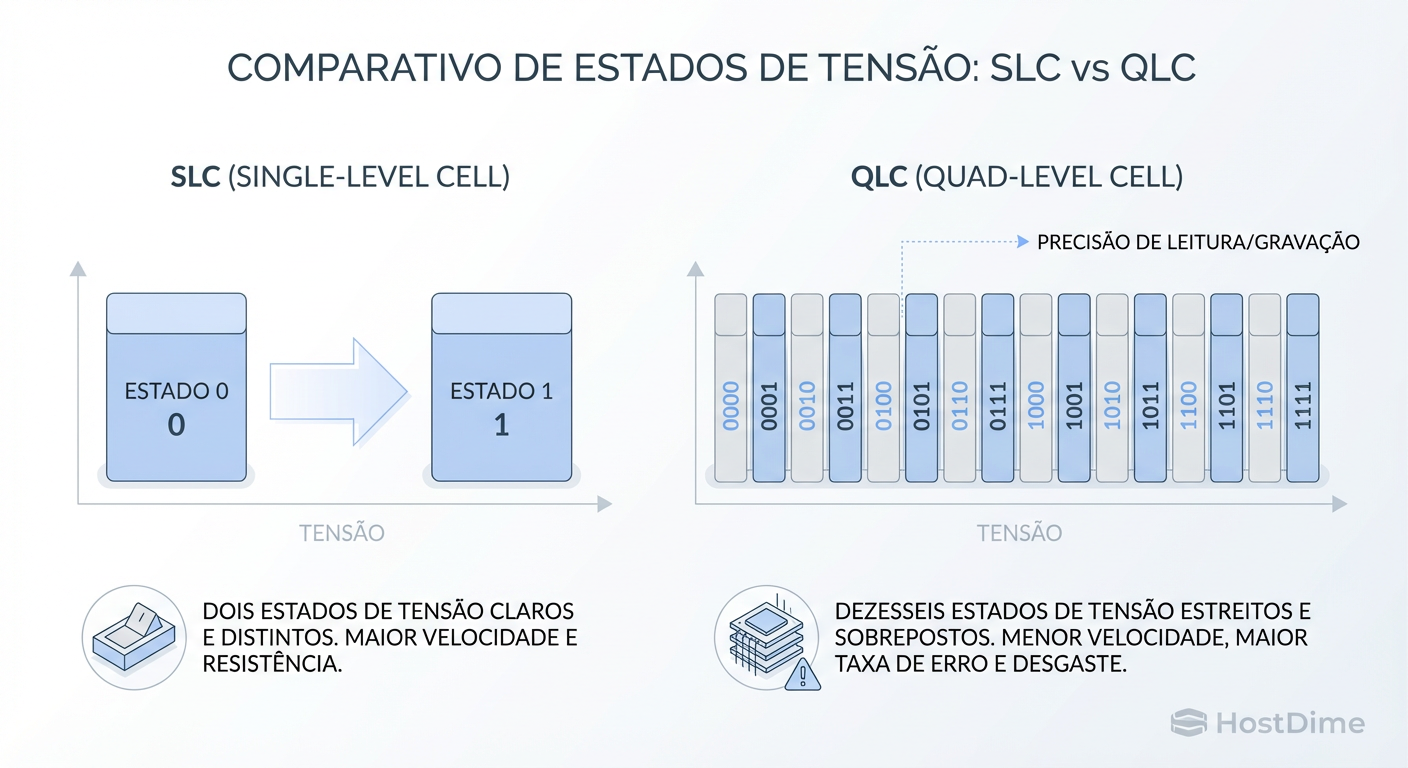 Figura: SLC vs QLC: A complexidade de gerenciar 16 estados de voltagem explica a latência e o desgaste do QLC.
Figura: SLC vs QLC: A complexidade de gerenciar 16 estados de voltagem explica a latência e o desgaste do QLC.
Para gravar em um QLC, o controlador do SSD precisa aplicar uma carga elétrica com precisão cirúrgica para atingir um dos 16 níveis exatos. Se errar um pouco, corrompe o dado. Isso leva tempo.
Para ler, o controlador precisa medir essa voltagem com extrema cautela para distinguir se é o nível 14 ou 15. À medida que o drive envelhece e as células degradam, essa leitura fica mais difícil e lenta (necessitando de mais correção de erro ECC).
O Trade-off: Você ganha densidade massiva (SSDs de 30TB, 60TB num formato de régua), mas a escrita se torna um processo lento e destrutivo.
A Armadilha do 'Write Cliff': O que acontece quando o Cache pSLC Estoura
Todo SSD QLC moderno mente para você. Quando você começa a gravar, ele parece incrivelmente rápido. Isso porque ele não está gravando em modo QLC (4 bits). Ele está usando uma parte da sua capacidade como um cache pseudo-SLC (1 bit).
Ele trata as células QLC como se fossem SLC, gravando apenas 0 ou 1. Isso é muito rápido. Mas esse cache é finito (geralmente uma porcentagem do espaço livre, ex: 20-50GB em drives menores, ou mais em drives Enterprise).
O que acontece quando você está ingerindo um dataset de 100TB para seu Data Lake e o cache enche? Você atinge o Write Cliff (Penhasco de Escrita).
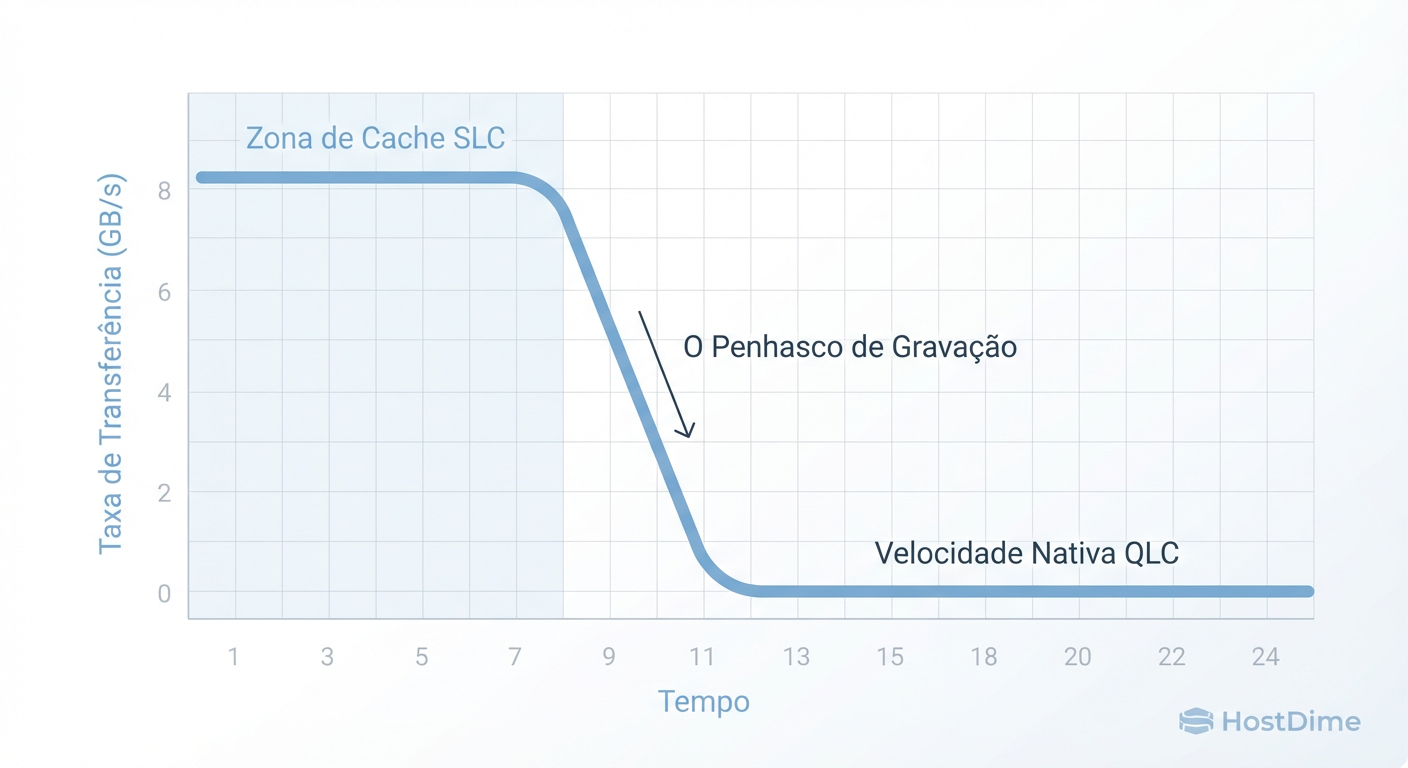 Figura: O 'Write Cliff' em ação: O momento exato em que seu SSD NVMe se torna mais lento que um Pen Drive.
Figura: O 'Write Cliff' em ação: O momento exato em que seu SSD NVMe se torna mais lento que um Pen Drive.
Neste momento, o drive é forçado a:
Gravar os novos dados diretamente em modo QLC (lento).
Compactar os dados do cache SLC antigo para QLC para liberar espaço (Garbage Collection).
O resultado? Seu SSD NVMe de 3GB/s cai repentinamente para 100MB/s — muitas vezes mais lento que um HDD mecânico sustentado.
Como mitigar:
Em ingestão de IA, dimensione o array para que a taxa de ingestão sustentada não exceda a velocidade nativa do QLC pós-cache.
Monitore a saturação do cache se o drive expuser essa métrica via SMART ou logs do fornecedor.
O Mito da Durabilidade (DWPD) em Workloads de IA
Vendedores de storage adoram empurrar drives TLC de 3 DWPD (Drive Writes Per Day) para "segurança". Para IA e Data Lakes, isso é jogar dinheiro fora.
A carga de trabalho de IA segue o padrão WORM (Write Once, Read Many):
Ingestão: Você grava o dataset de treinamento (Write).
Treinamento: Você lê esse dataset milhares de vezes durante as épocas (Read, Read, Read).
Checkpoints: Escritas ocasionais.
A proporção costuma ser 90% Leitura / 10% Escrita.
Drives QLC Enterprise modernos (como Solidigm D5 ou Micron 6500) oferecem algo entre 0.1 a 0.5 DWPD. Parece pouco? Vamos fazer a conta. Em um drive de 30TB, 0.3 DWPD significa que você pode gravar 9 Terabytes por dia, todos os dias, por 5 anos.
Você realmente vai reescrever seu Data Lake inteiro de 1PB a cada 3 dias? Provavelmente não. Você vai apenas adicionar dados novos. Para cargas de leitura intensiva, a baixa durabilidade de escrita do QLC é um "não-problema" fabricado.
Matemática de TCO: Watts por TB e Densidade vs. HDDs
Aqui é onde o HDD perde a guerra no Data Center moderno. O custo de aquisição ($/GB) do HDD ainda é menor (cerca de 5x a 7x mais barato que Flash Enterprise). Mas o TCO (Custo Total de Propriedade) conta outra história.
O espaço em rack e a energia são os recursos mais escassos hoje.
| Métrica | HDD Nearline (22TB) | QLC SSD Enterprise (30TB-61TB) | O Veredito |
|---|---|---|---|
| Densidade (PB por U) | ~0.3 PB (12 drives 3.5") | ~1.0 - 2.0 PB (Drives E1.L/U.2) | QLC esmaga em densidade. |
| Consumo (Watts/TB) | Alto (Motor girando constante) | Baixo (Dormência eficiente) | QLC reduz a conta de luz. |
| Peso por PB | Toneladas de metal | Plástico e silício leve | Importante para pisos elevados. |
| Refrigeração | Crítica (HDDs aquecem muito) | Menos crítica | Menor OPEX de HVAC. |
| Falhas Anuais (AFR) | 1-2% (Mecânico falha) | < 0.5% (Sem partes móveis) | Menos trocas de disco ("Swivel chair patrol"). |
Se você precisa de 5PB para treinar um LLM:
Com HDD: Você precisa de vários racks, switches de agregação complexos e muita refrigeração.
Com QLC: Você resolve com 2 a 4 unidades de rack (U).
A economia em portas de switch, cabos e energia muitas vezes paga a diferença do preço do drive em 24-36 meses.
Estratégias de Mitigação: Configurando ZFS para QLC
Se você tratar QLC como um disco normal, você vai matá-lo. A maior fraqueza do QLC é a Amplificação de Escrita. Pequenas escritas aleatórias forçam o drive a reescrever blocos grandes inteiros.
Se você usa ZFS, aqui está o seu checklist de sobrevivência para QLC:
1. Recordsize é Rei
O padrão do ZFS é 128K. Drives QLC modernos têm "Indirection Units" (IU) geralmente de 16K a 64K, mas preferem blocos grandes. Para um repositório de objetos ou arquivos grandes de IA:
# NÃO USE O PADRÃO. Aumente para 1M se seus arquivos forem grandes.
zfs set recordsize=1M tank/ai-dataset
Isso garante que o ZFS envie gravações grandes e sequenciais, que o QLC adora, e minimiza a fragmentação.
2. Evite RAIDZ1/Z2 com Blocos Pequenos
O pesadelo do QLC é o "Read-Modify-Write". Se você usar RAIDZ com um recordsize pequeno, cada escrita parcial força o drive a ler o bloco, calcular paridade e regravar.
Preferência: Espelhamento (Mirror) para performance máxima (mas perde capacidade).
Compromisso: RAIDZ2 apenas com
recordsizegrande (1M) eashift=12(ou 13/14 dependendo do drive, verifique o datasheet físico).
3. Autotrim e Alocação
Mantenha o autotrim ligado para que o controlador do SSD saiba quais blocos estão livres e possa fazer sua manutenção interna (Garbage Collection) de forma eficiente.
zpool set autotrim=on tank
4. Alinhamento de Partição
Garanta que suas partições estejam alinhadas com os limites físicos da página do flash. Ferramentas modernas fazem isso, mas se você particionar manualmente com fdisk ou parted antigo, pode criar um desalinhamento que corta a performance e a vida útil pela metade.
Veredito Técnico: O HDD Morreu?
Para Cold Storage (arquivamento de conformidade, backups que você espera nunca restaurar)? Não. O HDD ainda é o rei do custo por bit. O "Tape" (Fita LTO) é o imperador.
Mas para o Data Center de IA ativo, onde os dados precisam alimentar GPUs famintas? Sim, o disco mecânico é um zumbi. Ele anda, mas não corre.
A matemática do QLC fecha quando você para de olhar para o preço de compra e começa a olhar para o custo de manter suas GPUs H100 ociosas. Se o seu armazenamento é o gargalo da sua IA, você não tem um problema de armazenamento; você tem um problema de finanças.
Pense certo. Meça a latência de cauda (P99). E pare de comprar IOPS de escrita que você não vai usar.
Referências & Leitura Complementar
SNIA (Storage Networking Industry Association): "Understanding SSD Endurance: DWPD vs TBW" - Whitepapers sobre métricas reais de durabilidade.
Solidigm/Micron Tech Notes: Procure pelos datasheets técnicos dos drives D5-P5316 ou 6500 ION para ver os gráficos de "Steady State Write" (o Write Cliff real).
OpenZFS Documentation: Seção sobre "Workload Tuning" e alinhamento de
ashift.Brendan Gregg's Blog: "Disk Latency Heatmaps" - Essencial para visualizar por que a média de latência mente e os outliers destroem a performance.

Julia M. Santos
Enterprise Storage Consultant
Consultora para Fortune 500. Traduz 'economês' para 'técniquês' e ajuda empresas a não gastarem milhões em SANs desnecessárias.