QLC vs. TLC em Workloads de AI: Realidade de Endurance e Latência para 2026

Pare de superdimensionar storage. Entenda a física dos estados de voltagem, o impacto real na latência de cauda (p99) e onde o QLC é seguro para Arquiteturas de AI Enterprise.
Se você perguntar a um vendedor de storage se deve usar QLC ou TLC para seus clusters de GPU, a resposta será baseada no que ele precisa desovar do estoque. Se você perguntar a um engenheiro de software, ele olhará apenas para o custo por Terabyte. Como arquiteto, sua resposta precisa ser um frustrante — mas necessário — "depende do estágio do pipeline".
A narrativa da indústria é sedutora: "O QLC Enterprise moderno é bom o suficiente para tudo". Isso é uma meia-verdade perigosa. Em infraestrutura de Inteligência Artificial, onde uma GPU H100 parada custa uma fortuna por minuto, a latência de cauda (tail latency) do storage não é apenas um detalhe técnico; é um problema financeiro.
Neste artigo, vamos desmontar o hype e analisar a física, os custos ocultos e a arquitetura correta para 2026, fugindo das métricas de "caixa de papelão" e focando no comportamento em produção.
Diferença entre QLC e TLC para Arquitetos: O TLC (Triple-Level Cell) armazena 3 bits por célula e prioriza performance sustentada e alta durabilidade, sendo mandatório para cargas de escrita intensiva como treinamento de modelos e checkpointing. O QLC (Quad-Level Cell) armazena 4 bits, aumentando a densidade e reduzindo o custo/TB em cerca de 20-30%, mas sofre com latência de escrita significativamente maior e menor endurance, sendo ideal para data lakes de inferência e leitura massiva (WORM).
A Física da Densidade: Por que QLC 'pensa' mais devagar que TLC
Para entender por que o QLC falha em certas cargas de AI, precisamos descer ao nível do elétron. Não é apenas "mais dados no mesmo espaço". É uma questão de precisão elétrica.
Um SSD não armazena "zeros e uns" magicamente. Ele armazena elétrons em uma armadilha de carga (charge trap) e mede a voltagem resultante.
SLC (Single-Level Cell): 1 bit. Precisa distinguir apenas entre "tem carga" ou "não tem". Rápido, brutal, indestrutível.
TLC (Triple-Level Cell): 3 bits. Precisa distinguir entre 8 níveis de voltagem distintos.
QLC (Quad-Level Cell): 4 bits. Precisa distinguir entre 16 níveis de voltagem.
O problema não é ler; é escrever. Para gravar em QLC, o controlador precisa aplicar pulsos de voltagem extremamente precisos para acertar um dos 16 estados alvo minúsculos. Se ele errar por milivolts, o dado corrompe. Isso exige algoritmos de programação mais lentos e verificações (ECC) mais pesadas.
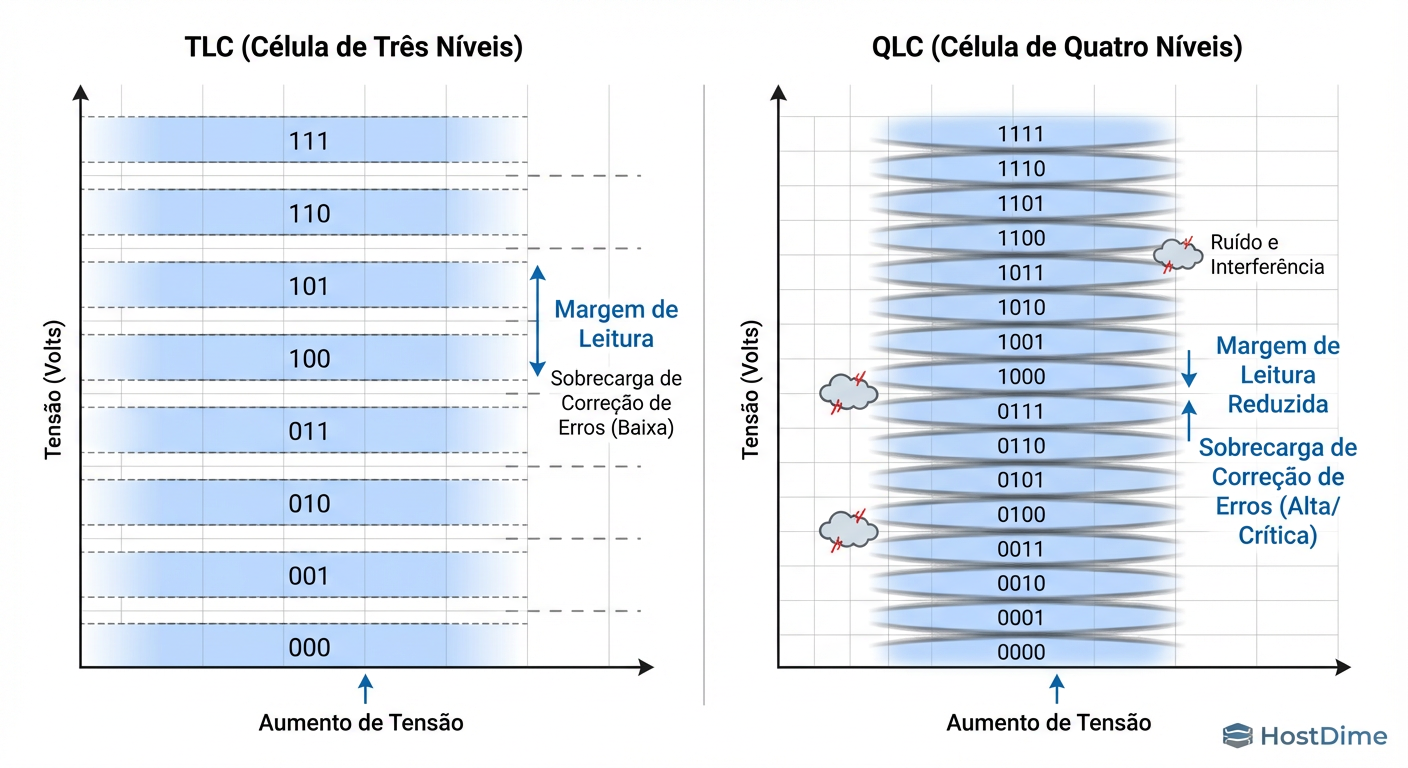 Figura: A Física do Erro: Comparativo de Estados de Voltagem TLC (8 estados) vs QLC (16 estados). Note a margem de erro reduzida no QLC, exigindo mais tempo de ECC.
Figura: A Física do Erro: Comparativo de Estados de Voltagem TLC (8 estados) vs QLC (16 estados). Note a margem de erro reduzida no QLC, exigindo mais tempo de ECC.
Como a imagem acima ilustra, a margem de erro (Noise Margin) no QLC é drasticamente menor. Isso significa que, à medida que a célula degrada, o controlador gasta mais ciclos de CPU tentando decodificar "o que diabos está escrito aqui", aumentando a latência de leitura ao longo do tempo (Read Disturb) e tornando a escrita uma operação cirúrgica lenta.
O Mito do Endurance em SSDs: DWPD vs. TBW Real em Checkpointing
Em arquitetura enterprise, ignoramos o DWPD (Drive Writes Per Day) de marketing. Ele é uma métrica derivada que esconde a realidade. O que importa é o TBW (Terabytes Written) confrontado com o seu WAF (Write Amplification Factor).
No treinamento de LLMs (Large Language Models), o padrão de I/O é bipolar:
Ingestão de Dados: Leitura massiva, aleatória ou sequencial. (Baixo desgaste).
Checkpointing: Escrita sequencial massiva e explosiva. O estado da memória da GPU é despejado no disco para salvar o progresso.
O QLC moderno tem um endurance "aceitável" para sequencial. O problema surge no pré-processamento de dados. Se seus ETLs fazem muitas pequenas escritas aleatórias (random writes de 4K ou 16K) antes de alimentar o modelo, você está assassinando o QLC.
O WAF em QLC para escritas aleatórias pode chegar a 4x ou 5x. Isso significa que para gravar 1TB de dados, você queima 5TB de vida útil da flash. Em TLC, esse fator raramente passa de 2x em cenários ruins.
A regra prática: Se o seu dataset é estático (ex: ImageNet, Common Crawl) e você só lê, o endurance do QLC é irrelevante. Se você está fazendo fine-tuning constante ou usando o storage como scratch space para ETL, o TCO do QLC inverte: você trocará de discos tão cedo que a economia inicial desaparece.
A Armadilha do Cache SLC: O que acontece quando o buffer enche
Este é o ponto onde a maioria dos benchmarks falha. Quase todo SSD QLC moderno usa uma porção da sua capacidade operando em modo "pseudo-SLC" (1 bit por célula) para absorver escritas rápidas.
Em benchmarks curtos, o drive parece voar. Mas workloads de AI não são curtos. Imagine um checkpoint de um modelo de 175B parâmetros. Estamos falando de Terabytes de dados sendo escritos o mais rápido possível para liberar a GPU.
Fase 1 (Cache SLC Vazio): O SSD grava a 3GB/s. Tudo parece ótimo.
Fase 2 (Cache Cheio): O drive precisa começar a gravar nativamente na célula QLC (que é lenta) E, simultaneamente, esvaziar o cache SLC para liberar espaço (folding).
O Abismo (Cliff Effect): A performance cai de 3GB/s para 150MB/s (sim, velocidade de HDD mecânico).
Enquanto o storage engasga a 150MB/s tentando limpar a bagunça, suas GPUs H100 ficam em idle, esperando o fsync retornar. Se você tem um cluster de 64 GPUs, esse "tempo de espera" pode custar milhares de dólares por hora. O TLC também tem cache, mas a velocidade nativa de escrita do TLC é alta o suficiente para não causar um colapso total quando o cache acaba.
Dissecando Workloads de AI: Onde a Latência de Escrita TLC supera o QLC
Não existe "Storage para AI". Existe storage para etapas do pipeline de AI. A chave para um TCO saudável em 2026 é a arquitetura híbrida inteligente.
 Figura: Arquitetura Híbrida para AI 2026: Onde posicionar QLC e TLC baseando-se no padrão de I/O de cada etapa do pipeline de Machine Learning.
Figura: Arquitetura Híbrida para AI 2026: Onde posicionar QLC e TLC baseando-se no padrão de I/O de cada etapa do pipeline de Machine Learning.
A imagem acima propõe a separação lógica e física. Vamos analisar o trade-off em uma tabela direta:
| Característica | TLC (Triple-Level Cell) | QLC (Quad-Level Cell) | Veredito para AI |
|---|---|---|---|
| Custo/TB | Alto ($$$) | Médio/Baixo ($$) | QLC vence para arquivamento e Data Lakes. |
| Latência de Escrita (Steady State) | Baixa e Previsível | Alta e Variável | TLC é obrigatório para Checkpoints e Scratch. |
| Latência de Leitura | Muito Baixa | Baixa (mas degrada sob carga mista) | Empate técnico para leitura pura (Inference). |
| Risco de "Cliff Effect" | Baixo | Crítico | QLC é perigoso para ingestão em tempo real. |
| Densidade (Rack Units) | Alta | Muito Alta (ex: 60TB+ por drive) | QLC maximiza o espaço no datacenter. |
O Horizonte 2026: ZNS e CXL mudando a matemática do QLC
Se você está desenhando uma solução hoje pensando em 3 a 5 anos, não pode ignorar o software-defined storage moderno. O QLC tem problemas físicos, mas o software está começando a contorná-los.
1. ZNS (Zoned Namespaces)
O ZNS muda a regra do jogo para o QLC. Em vez do SSD gerenciar complexamente onde cada bloco é escrito (o que causa Write Amplification), o sistema operacional (ou a aplicação de AI) escreve sequencialmente em "zonas". Isso elimina a necessidade de Garbage Collection agressivo no drive. Com ZNS, o QLC pode atingir durabilidade e performance de escrita sequencial muito próximas ao TLC, pois removemos a aleatoriedade da equação. O suporte a ZNS já está crescendo em frameworks como PyTorch via bibliotecas de I/O otimizadas.
2. CXL (Compute Express Link)
Para 2026, o CXL permitirá expandir a memória RAM usando flash. Embora o QLC seja lento para ser "RAM", ele é rápido o suficiente para ser uma camada de Memory Pooling para armazenar pesos de modelos gigantes que não cabem na VRAM, servindo como um tier intermediário muito mais barato que DRAM e muito mais rápido que NVMe via rede.
Protocolo de Validação: Medindo 'Steady State' em Storage de AI
Não aceite benchmarks de "fábrica" (Fresh out of Box). Todo SSD é rápido quando está vazio. Para validar se um array QLC ou TLC aguenta sua carga de AI, você precisa testar o Steady State (Estado Estacionário).
Aqui está como um arquiteto valida, não como um gamer testa:
Preenchimento: Encha o disco 2x com dados aleatórios. Isso força o controlador a trabalhar com tabelas de alocação cheias e sem blocos livres fáceis.
Saturação: Execute o teste por tempo suficiente para estourar qualquer cache SLC (pelo menos 30-60 minutos de escrita contínua).
Use o fio (Flexible I/O Tester), a ferramenta padrão da indústria. Esqueça CrystalDiskMark.
# Simula escrita de checkpoints massivos ignorando cache do sistema operacional
fio --name=ai_checkpoint_stress \
--filename=/dev/nvme0n1 \
--ioengine=libaio \
--direct=1 \
--rw=write \
--bs=1M \
--numjobs=4 \
--iodepth=32 \
--size=100% \
--runtime=3600 \
--time_based \
--group_reporting
O que observar nos resultados:
Não olhe para a média (avg). Olhe para o 99th percentile (clat 99.00th).
Se no TLC a latência é 2ms e no QLC salta para 500ms no percentil 99, você encontrou seu gargalo. Essa latência de 500ms é o momento em que sua GPU de $30.000 para de treinar.
Veredito Técnico: A Estratégia de Tiering é a Única Saída
A batalha "QLC vs. TLC" é uma falsa dicotomia. A resposta correta para 2026 é Tiering Inteligente.
Use TLC (NVMe) para o "Hot Tier": Scratch space, checkpoints de treinamento, logs de transação e datasets que sofrem ETL pesado. O custo por GB é irrelevante comparado ao custo de ociosidade da GPU.
Use QLC (NVMe/SAS) para o "Warm Tier": Data Lakes de leitura (Inference datasets), armazenamento de objetos (S3 on-prem) e retenção de modelos versionados.
Não tente economizar colocando o workload errado na mídia errada. O QLC é uma tecnologia fantástica de densidade, mas a física da voltagem não perdoa impaciência. Projete para o pior caso de latência, e seu cluster de AI agradecerá.
Referências & Leitura Complementar
SNIA (Storage Networking Industry Association): Solid State Storage Performance Test Specification (PTS) – A bíblia de como testar SSDs corretamente.
Western Digital / Micron Whitepapers: Zoned Namespaces (ZNS) SSDs: Transforming the Storage Layer – Detalhes sobre como ZNS recupera endurance em QLC.
NVIDIA Technical Blog: Storage Performance Requirements for Deep Learning Training – Análise do impacto de I/O wait em clusters H100/A100.
FIO Documentation: Manpage & Examples – Documentação oficial da ferramenta de benchmark de I/O.

Dr. Marcus 'Bitrot' Silva
Engenheiro Sênior de Armazenamento
20 anos recuperando RAIDs quebrados. Especialista em ZFS e sistemas de arquivos distribuídos. Já viu mais falhas de disco do que gostaria.