Qos Para Storage Quando Aplicar E Como Medir Ganhos

São 03:00 da manhã. O pager toca. O alerta é crítico: latência da API de checkout disparou para 4 segundos. Você abre o dashboard do banco de dados e vê o uso d...
Qos Para Storage Quando Aplicar E Como Medir Ganhos
São 03:00 da manhã. O pager toca. O alerta é crítico: latência da API de checkout disparou para 4 segundos. Você abre o dashboard do banco de dados e vê o uso de CPU normal, memória estável, e locks sob controle. Mas o Wait Time de I/O está no teto.
Você corre para o hypervisor ou para a console da SAN e descobre o culpado: uma VM de "Dev/Test" que alguém configurou para rodar um backup full não agendado, ou talvez um job de ETL mal otimizado que decidiu reescrever terabytes de logs. Essa VM irrelevante está drenando toda a capacidade de I/O do array de discos, asfixiando seu banco de dados de produção.
Este é o cenário clássico do Noisy Neighbor (Vizinho Barulhento). Em ambientes compartilhados — seja numa nuvem privada com VMware/KVM ou em instâncias EC2 com EBS compartilhado — o armazenamento é o recurso mais difícil de isolar. CPU tem o scheduler do kernel. Memória tem o OOM killer e cgroups. Mas o I/O? O I/O é o "velho oeste" se você não aplicar leis estritas.
A maioria dos sysadmins tenta resolver problemas de storage jogando mais hardware no problema: "Vamos comprar mais SSDs", "Vamos migrar para NVMe". Mas em sistemas distribuídos e multi-tenant, velocidade bruta não resolve contenção. O que você precisa não é de mais velocidade; é de controle. É aqui que entra o Quality of Service (QoS) para storage. Não como uma ferramenta de punição, mas como o único mecanismo capaz de garantir previsibilidade.
O A Lógica por Trás: A Fila da Balada vs. O VIP
Para entender QoS de storage, pare de pensar em discos como canos de água (onde o foco é o fluxo/vazão). Comece a pensar neles como uma bilheteria com um número finito de atendentes.
Cada operação de leitura ou escrita (IOPS) é uma pessoa tentando comprar um ingresso. A Latência é o tempo que a pessoa passa na fila esperando + o tempo sendo atendida. O Throughput é quantas pessoas conseguem entrar por minuto. A Queue Depth (Profundidade da Fila) é o tamanho da aglomeração na frente do guichê.
Sem QoS, a fila é "First-Come, First-Served" (FCFS). Se o vizinho barulhento (o job de backup) chega com 10.000 pessoas (requisições) de uma vez, seu banco de dados (que só tem 50 requisições críticas) vai para o final da fila. O atendente (o disco) não sabe que aquelas 50 pessoas são VIPs. Ele só vê uma multidão.
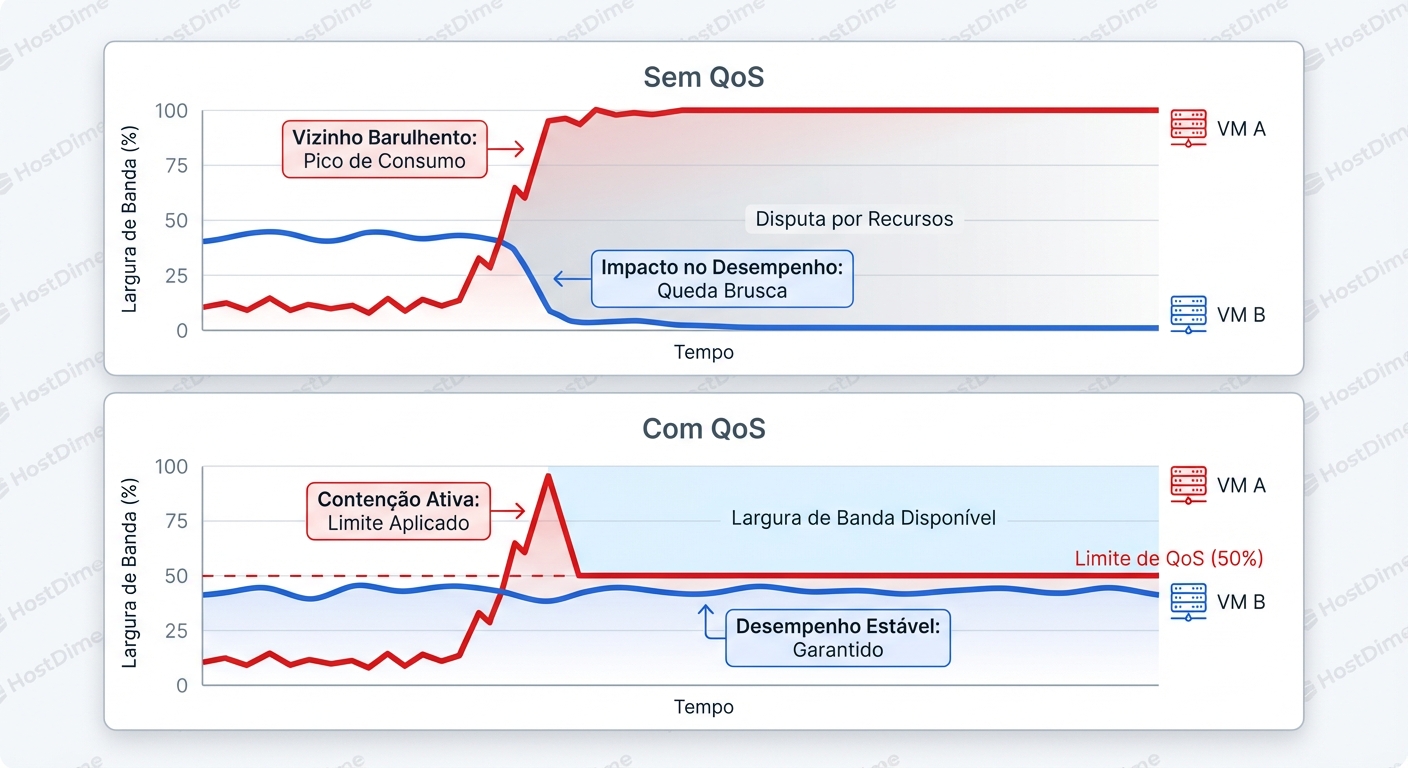
O QoS atua como o segurança da balada. Ele não cria mais atendentes. O que ele faz é impor regras de admissão. Ele diz para o vizinho barulhento: "Você só pode colocar 100 pessoas na fila por segundo. O resto espera lá fora (Throttling)". Isso esvazia a fila principal, permitindo que as requisições do banco de dados sejam atendidas quase instantaneamente.
O ganho aqui não é fazer o disco rodar mais rápido. O ganho é a Latência Determinística. Você sacrifica o pico teórico de performance da VM de backup para garantir que a latência da VM de produção nunca ultrapasse um limite aceitável.
A Tirania da Média vs. A Realidade do p99
Um erro fatal ao analisar performance de storage é olhar para a latência média. A média é uma mentira estatística em sistemas de I/O.
Imagine que em um minuto, seu disco atendeu:
- 99 requisições em 1ms.
- 1 requisição em 1000ms (1 segundo).
A latência média é de aproximadamente ~11ms. Parece ótimo, certo? O dashboard fica verde. Mas para o usuário que caiu naquela 1 requisição de 1 segundo, o sistema travou. Se essa requisição for um lock de banco de dados, ela pode causar um efeito cascata que derruba a aplicação inteira.
Em ambientes multi-tenant sem QoS, a distribuição da latência tem uma "cauda longa" (Long Tail). A maioria das operações é rápida, mas os momentos de contenção criam picos absurdos.
O foco do SRE deve ser a métrica p99 (ou p99.9). Isso significa: "99% das minhas requisições são atendidas abaixo de X ms".
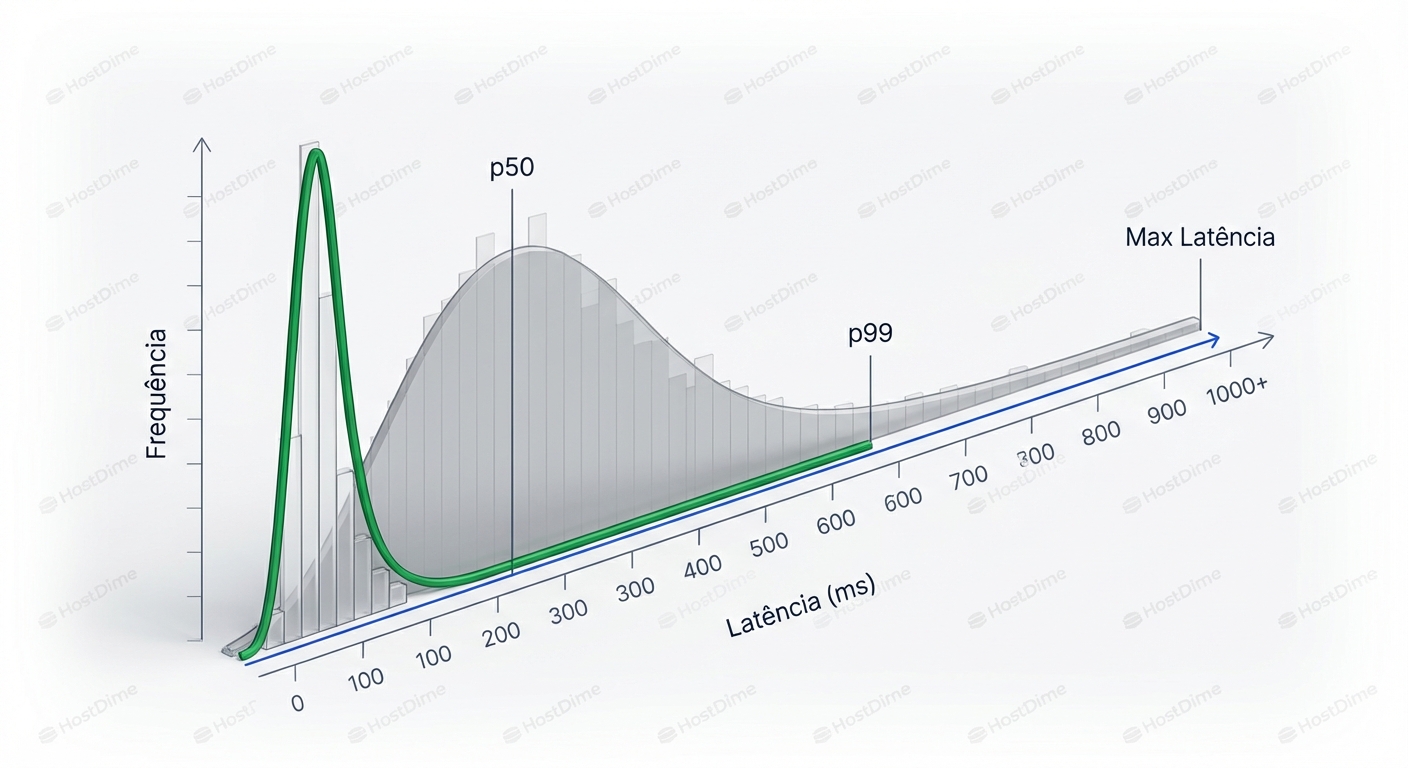
Quando aplicamos QoS, nós cortamos essa cauda. Nós definimos um teto (Ceiling). Ao limitar os IOPS máximos de cada tenant, impedimos que a fila sature. O resultado visual num histograma é que a curva se comprime para a esquerda. O pico de throughput do sistema pode até cair (porque estamos limitando o "barulhento"), mas a consistência sobe drasticamente. Em produção, consistência vale mais que velocidade máxima.
Sob o Capô: Token Buckets e Leaky Buckets
Como o QoS é implementado tecnicamente? Seja no KVM (via cgroups), no VMware (SIOC) ou em volumes de nuvem (EBS, Azure Disk), o algoritmo subjacente quase sempre é uma variação do Token Bucket.
Visualize um balde com um furo no fundo.
- Tokens (Créditos): O sistema joga moedas (tokens) dentro do balde a uma taxa constante. Digamos, 1000 tokens por segundo (este é o seu limite de IOPS configurado).
- Consumo: Cada vez que a VM quer fazer uma operação de I/O, ela precisa pegar um token do balde.
- O Balde Cheio: Se a VM não faz I/O, o balde enche até uma capacidade máxima (o tamanho do Burst).
- O Balde Vazio: Se a VM tenta fazer mais I/O do que a taxa de reposição de tokens, o balde esvazia.
O que acontece quando o balde está vazio? Aqui temos dois comportamentos distintos:
- Throttling (Policiamento): O hypervisor segura a requisição de I/O numa fila artificial antes de enviá-la ao disco. A VM percebe isso como latência aumentada. O sistema operacional da VM vê o disco "lento", mas não vê erros.
- Rejeição: Em alguns cenários de rede/API, o sistema simplesmente rejeita o pacote (Drop). Em storage local, isso é raro, pois causaria corrupção de dados ou falha de sistema de arquivos. O padrão é enfileirar e atrasar.
O Perigo do Bursting
Muitos provedores de nuvem e configurações padrão permitem "Bursting". A ideia é: "Se você não usou seu disco por uma hora, acumulou créditos. Agora pode gastá-los todos de uma vez por 30 minutos".
Para ambientes isolados, isso é ótimo. Para ambientes multi-tenant, Bursting é o inimigo da estabilidade. O Bursting permite que o Noisy Neighbor viole as regras de convivência temporariamente. Se todos os tenants decidirem usar seus créditos de burst ao mesmo tempo (ex: cronjobs rodando à meia-noite), o array de storage físico satura, e o QoS baseado em software perde a eficácia porque o gargalo desceu para o hardware físico.
Regra de Ouro: Para cargas de trabalho críticas (Bancos de Dados, Filas de Mensageria), prefira Provisioned IOPS (limites fixos e garantidos) em vez de modelos baseados em Burst/Créditos.
Estratégia de Implementação: O que Limitar?
Não basta "ligar o QoS". Você precisa saber qual métrica limitar. As duas principais alavancas são IOPS e Bandwidth (Throughput). Elas não são a mesma coisa e afetam cargas de trabalho diferentes.
| Métrica | O que controla | Cargas de Trabalho Afetadas | Sintoma de Saturação |
|---|---|---|---|
| IOPS (Limit) | Número de transações por segundo. | Bancos de Dados (OLTP), Servidores Web, Microservices. | Latência alta em queries pequenas. O sistema fica "engasgado". |
| Bandwidth (Limit) | Volume de dados (MB/s). | Backups, Streaming de Vídeo, ETL, Big Data, Restauração de Logs. | Transferências demoram mais, mas o sistema responde (se os IOPS estiverem livres). |
Cenário Prático: A Combinação Vencedora
Para proteger um cluster de virtualização, a configuração mais robusta geralmente envolve limitar ambos, mas com focos diferentes:
- VMs de Aplicação/DB: Limite alto de IOPS (para garantir responsividade), mas limite moderado de Bandwidth. Por quê? Porque um
SELECT *mal feito não deve conseguir saturar o link de fibra/rede da SAN. - VMs de Backup/Logs: Limite baixo de IOPS, limite moderado de Bandwidth. Backups são sequenciais; eles precisam de banda, não de milhares de operações por segundo. Ao limitar os IOPS, você impede que o software de backup fragmente o disco com leituras aleatórias agressivas.
Diagnóstico e Observabilidade: Interpretando os Sinais
Como saber se o QoS está funcionando ou se está sendo agressivo demais? Como diferenciar "O disco é lento" de "O QoS está me limitando"?
Vamos para o terminal. O comando universal em Linux é o iostat. Mas a maioria usa errado.
Execute: iostat -x -k 1
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.00 500.00 0.00 2000.00 0.00 8.00 2.50 5.00 5.00 0.00 0.50 25.00
Aqui está como ler isso com a mentalidade de QoS:
r/s+w/s(IOPS): Some esses dois. Se a soma estiver cravada no seu limite de QoS (ex: 500 IOPS) e o gráfico for uma linha reta, parabéns: você atingiu o teto (Ceiling). O QoS está atuando.awaitvssvctm(A Chave do Diagnóstico):await: É o tempo total que o I/O levou (tempo na fila do OS + tempo no disco).svctm: (Descontinuado em kernels novos, mas o conceito persiste) É a estimativa de tempo que o disco realmente levou para processar.Cenário A (Gargalo Físico):
awaitalto (20ms) esvctmalto (19ms).- Veredito: O disco físico está lento ou saturado. O QoS não é o culpado direto, o hardware que não aguenta.
Cenário B (QoS / Throttling):
awaitalto (50ms) esvctmbaixo (0.5ms).- Veredito: O disco é rápido, mas a requisição ficou parada na fila do kernel ou do hypervisor. Isso é a prova de que o QoS está limitando a VM. A "latência artificial" está sendo injetada para manter o limite de IOPS.
avgqu-sz(Queue Depth): Se este número estiver alto (ex: > 10 ou 20 para um único disco virtual), significa que a aplicação está empilhando requisições mais rápido do que o QoS permite que elas passem. Isso causa backpressure na aplicação.
Observabilidade no Lado do Hypervisor/Storage
Dentro da VM (Guest), você só vê os sintomas. Para ver a verdade, você precisa olhar de fora.
Em sistemas Linux KVM, você pode usar o virsh domblklist para achar o device e depois consultar as estatísticas de cgroup.
Mas a métrica mais importante para monitorar em dashboards (Grafana/Datadog) é a Throttled Time ou Throttled IOPS.
- Se o gráfico de Throttled Time for maior que zero, o QoS está ativo.
- Se for frequentemente alto, você sub-provisionou a VM e está prejudicando a performance legítima da aplicação.
A Armadilha da Latência Artificial (O Lado Sombrio do QoS)
Aplicar QoS não é isento de riscos. Quando você configura um limite rígido (Hard Limit), você muda o comportamento de falha do sistema.
Imagine um banco de dados tentando fazer um checkpoint crítico. Ele precisa de 5000 IOPS por 10 segundos. Você limitou a 1000. O banco de dados não recebe um erro "Disk Full". Ele apenas vê o disco ficar incrivelmente lento. O que o banco faz?
- Aumenta o tempo de retenção de locks.
- As queries de leitura começam a empilhar atrás desses locks.
- A fila de conexões da aplicação enche.
- A aplicação começa a dar timeout 504 Gateway Time-out.
Você causou uma indisponibilidade não porque o disco falhou, mas porque impediu o banco de "respirar" num momento crítico.
Como mitigar:
- Monitoramento de Saturação: Configure alertas quando uma VM atingir 90% do seu limite de QoS por mais de 5 minutos. QoS deve cortar picos anômalos, não ser um teto constante para a operação normal.
- Use Reservas (Minimum Guarantee) além de Limites: A maioria dos sistemas modernos permite configurar um "Piso" (Reservation) e um "Teto" (Limit).
- Reservation: Garante que, mesmo com o vizinho barulhento, esta VM terá sempre, no mínimo, 1000 IOPS.
- Limit: Garante que esta VM nunca passará de 5000 IOPS. O uso de Reservas é muito mais seguro para produção do que Limites rígidos, pois protege o SLA sem impedir picos de performance se o array estiver ocioso.
I/O Scheduler: O Aliado Oculto
Antes de aplicar QoS agressivo, verifique o I/O Scheduler dentro das suas VMs Linux.
Muitas distros antigas usavam cfq (Complete Fair Queuing), que tentava fazer seu próprio QoS interno. Em ambientes virtualizados, isso é redundante e custoso. O hypervisor já está gerenciando a fila.
Para VMs modernas (especialmente em NVMe ou SSDs rápidos), mude o scheduler para:
noneounoop: Deixa o hypervisor cuidar de tudo. Menor overhead de CPU.mq-deadlineoukyber: Úteis se você precisa de priorização simples dentro da VM, mas geralmentenoneé preferível sob QoS estrito.
Comando para verificar:
cat /sys/block/sda/queue/scheduler
Comando para alterar (sem reboot):
echo none > /sys/block/sda/queue/scheduler
Isso remove uma camada de complexidade e torna o comportamento da latência mais previsível sob carga de QoS.
O Custo da Previsibilidade
Implementar QoS em storage é admitir uma derrota parcial: você está aceitando que não pode ter performance infinita e que o isolamento de software é necessário.
Ao limitar o throughput máximo, você pode ver jobs de backup demorarem 20% mais. Você pode ver a instalação de pacotes demorar um pouco mais. Esse é o "imposto" que pagamos pela estabilidade.
A pergunta que você deve fazer não é "Quanto de IOPS meu storage aguenta no máximo?", mas sim "Qual é a latência máxima aceitável para minha aplicação no pior dia possível?".
Configure seu QoS de trás para frente:
- Defina o SLA de latência (ex: 10ms p99).
- Faça testes de carga (com
fioouvdbench) para descobrir em qual nível de IOPS o seu storage array começa a violar esses 10ms. - A soma dos Limites de QoS de todas as suas VMs críticas não deve exceder esse número de "quebra".
Se a soma dos limites excede a capacidade física em latência aceitável, você está fazendo Overbooking de Performance. Funciona bem enquanto todos dormem, mas falha catastroficamente quando todos acordam. E como SRE, seu trabalho é garantir que o sistema sobreviva ao momento em que todos acordam gritando ao mesmo tempo.
A consistência é a nova velocidade. Um sistema que responde sempre em 5ms é infinitamente superior a um que responde em 0.5ms na maior parte do tempo, mas trava por 2 segundos a cada hora. O QoS é a ferramenta que transforma o caos estatístico em engenharia determinística.

Sarah 'The Backup' Connor
Gerente de Recuperação de Desastres
Seus dados não estão seguros até que ela diga que estão. Especialista em estratégias de backup imutável e RPO/RTO.