RAID 0 com NVMe: O Mito da Escala Linear de IOPS e a Realidade da CPU

Descubra por que adicionar mais SSDs NVMe em RAID 0 não garante IOPS infinitos. Entenda os gargalos de CPU, PCIe e como calcular o desempenho real.
No papel, a matemática é sedutora. Se um SSD NVMe entrega 3.500 MB/s de leitura e 300.000 IOPS, então quatro deles em RAID 0 deveriam entregar 14.000 MB/s e 1.2 milhão de IOPS, certo? É esse raciocínio linear que leva muitos arquitetos e entusiastas a desenharem soluções de armazenamento que falham espetacularmente no mundo real.
A realidade da infraestrutura não aceita multiplicação simples. Quando saímos do mundo dos discos rotacionais (HDD) e entramos na era do NVMe, as regras do jogo mudam. O gargalo, que historicamente residia na física mecânica do disco, agora se esconde na arquitetura do processador e na topologia da placa-mãe. Antes de comprar quatro drives Gen4 caros esperando performance de mainframe, precisamos dissecar por que a escala linear é, na maioria das vezes, uma ficção.
RAID 0 com NVMe é uma configuração de agregação de armazenamento (striping) que visa multiplicar a taxa de transferência e IOPS, mas que em drives modernos colide com limitações de interrupções de CPU e largura de banda do barramento DMI/PCIe. Diferente de HDDs, onde o ganho é quase linear, em NVMes o overhead do kernel e a latência de contexto frequentemente impedem que o arranjo atinja a soma teórica das partes, enquanto o risco de perda de dados aumenta exponencialmente.
A Ilusão da Matemática Simples em Arranjos Flash
Para entender o problema, precisamos revisitar como o sistema operacional lida com I/O. Na era do HDD, a latência era medida em milissegundos. A CPU solicitava um dado e podia ir "tomar um café" (processar milhões de ciclos) antes que o disco respondesse. A CPU sobrava, o disco faltava.
Com o NVMe, a latência caiu para a casa dos microssegundos. O dispositivo é tão rápido que a CPU mal tem tempo de trocar de contexto. Quando você coloca 4 drives em RAID 0, você não está apenas somando largura de banda; você está somando interrupções.
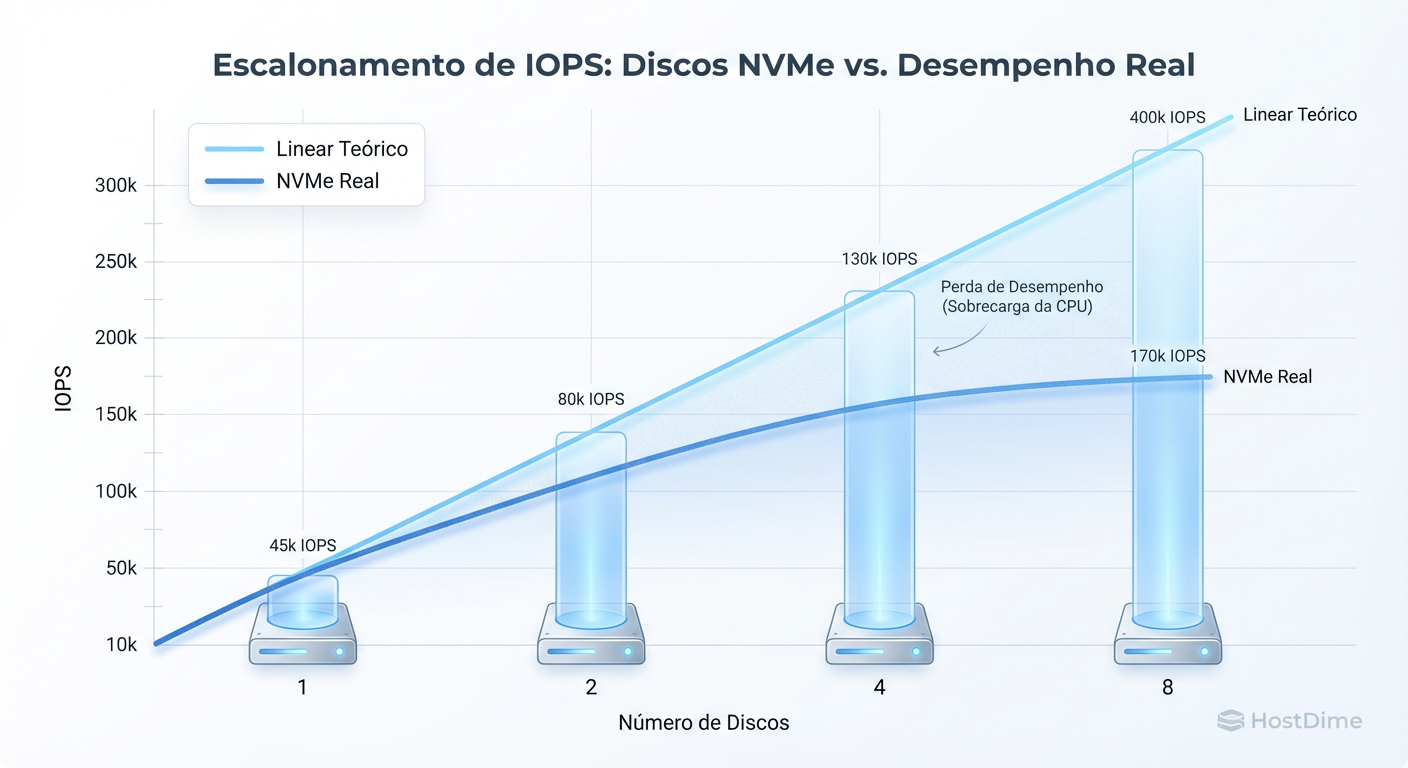 Figura: Curva de Retornos Decrescentes: A discrepância entre a multiplicação teórica e a realidade limitada por overhead de kernel e latência de interconexão.
Figura: Curva de Retornos Decrescentes: A discrepância entre a multiplicação teórica e a realidade limitada por overhead de kernel e latência de interconexão.
Como ilustrado acima, existe um ponto de retornos decrescentes. O sistema operacional (seja Linux, BSD ou Windows) precisa gerenciar o mapeamento de blocos, dividir as requisições (chunks), enviá-las para os drives corretos e remontar a resposta.
Esse gerenciamento tem um custo de CPU. Em um certo ponto, o tempo que o Kernel gasta decidindo "para onde esse dado vai" torna-se maior do que o tempo que o drive leva para gravar o dado. Se você não tiver núcleos de CPU suficientes e rápidos dedicados a processar essas interrupções de I/O, seus drives ficarão ociosos esperando o processador, e não o contrário.
O Novo Gargalo: Quando o Storage é Mais Rápido que a CPU
Aqui entramos no território de Brendan Gregg: a saturação não é óbvia. Você olha para o top ou htop e vê a CPU em 40%. "Tenho sobra", você pensa. Errado.
Você precisa olhar para o iowait e, mais especificamente, para o tempo gasto em softirqs e context switching.
Cada operação de I/O em um NVMe gera uma interrupção. Em um RAID 0 de 4 discos, uma leitura sequencial grande é quebrada em pedaços (stripes). Se o seu stripe size for 64k e você pede um arquivo de 1MB, o sistema gera múltiplas operações simultâneas.
A CPU precisa calcular o endereço.
A CPU envia o comando via barramento PCIe.
O drive responde.
A CPU recebe uma interrupção para tratar a resposta.
Se você tem um único núcleo lidando com o driver do RAID (comum em algumas implementações de software RAID mal configuradas), esse núcleo vai bater em 100% de uso (em modo kernel/system) muito antes de os SSDs saturarem suas interfaces. O gargalo se deslocou.
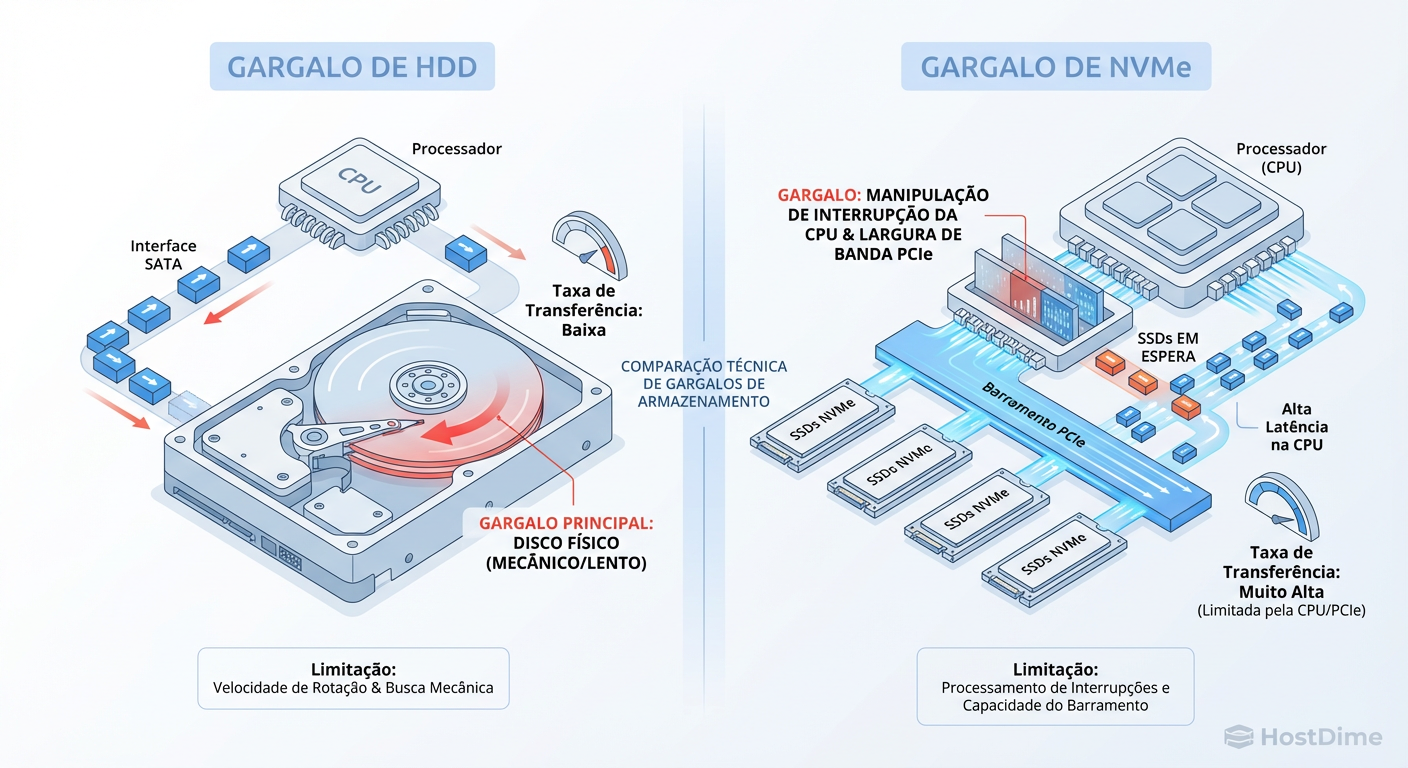 Figura: Diagrama de Deslocamento de Gargalo: Em arranjos NVMe, o 'cano' físico (PCIe) e o processador (CPU IRQ) saturam antes da mídia de armazenamento.
Figura: Diagrama de Deslocamento de Gargalo: Em arranjos NVMe, o 'cano' físico (PCIe) e o processador (CPU IRQ) saturam antes da mídia de armazenamento.
Limitações Físicas: A Mentira das Placas-Mãe e o DMI
Este é o ponto onde a maioria dos projetos de "Home Lab" ou servidores SMB erra feio. Você compra uma placa-mãe com 3 slots M.2 e uma placa PCIe adaptadora para mais 2. Você espeta 5 drives NVMe Gen4.
O problema é a topologia PCIe.
CPU Lanes: A maioria das CPUs consumer (e até alguns Xeons de entrada) tem um número limitado de linhas PCIe diretas (geralmente 16 a 24). A maioria vai para a GPU.
Chipset Lanes (PCH): Os slots M.2 extras geralmente passam pelo Chipset.
O Gargalo DMI: A conexão entre a CPU e o Chipset (DMI - Direct Media Interface) geralmente equivale a uma conexão PCIe x4 ou x8.
Se você colocar 3 drives NVMe em RAID 0 ligados ao chipset, eles podem até ter capacidade individual de 7GB/s cada. Mas eles todos terão que passar pelo "funil" do DMI para chegar à CPU. Se o DMI for equivalente a PCIe 4.0 x4 (aprox. 8GB/s totais), seu arranjo de 3 drives (teoricamente 21GB/s) nunca passará de 8GB/s. Você criou um engarrafamento de dados na placa-mãe.
Callout de Arquitetura: Para performance real em RAID 0 NVMe, você precisa de uma plataforma com linhas PCIe suficientes (Threadripper, EPYC, Xeon Scalable) para conectar todos os drives diretamente à CPU (CPU-attached storage), evitando o chipset completamente.
Hardware RAID vs. Software RAID vs. ZFS
Na era do disco mecânico, placas controladoras RAID (PERC, MegaRAID) eram obrigatórias. Elas tinham processadores dedicados para calcular paridade (RAID 5/6) e cache com bateria.
No mundo NVMe, Hardware RAID é frequentemente um gargalo. O processadorzinho ARM na placa RAID é muito mais lento que o seu processador principal (Xeon/EPYC/Core i9). Além disso, muitas placas RAID "Tri-mode" antigas limitam a largura de banda.
Comparativo de Implementações para NVMe
| Característica | Hardware RAID | Software RAID (mdraid/LVM) | ZFS (Striped vdevs) |
|---|---|---|---|
| Gargalo Principal | CPU da Controladora | CPU do Host (Kernel overhead) | CPU do Host (Checksums + Features) |
| Latência | Alta (adiciona hops) | Baixa (caminho direto) | Média (overhead de software) |
| Portabilidade | Péssima (Vendor lock-in) | Excelente (Linux nativo) | Excelente (Cross-platform) |
| Integridade | Confia no Drive | Confia no Drive | Checksum fim-a-fim (Self-healing*) |
| Veredito NVMe | Evite (salvo modelos high-end específicos) | Recomendado para performance bruta | Recomendado para gestão/segurança |
*Nota: ZFS em RAID 0 (stripe) detecta corrupção, mas não pode corrigi-la sem redundância.
Para performance bruta em Linux, mdraid (Linux Software RAID) geralmente vence porque é extremamente leve e roda no espaço do kernel com otimizações de multithreading maduras. ZFS é fantástico, mas o custo de calcular checksums e a complexidade do ARC (cache) consomem ciclos de CPU que, em velocidades de NVMe, reduzem o IOPS máximo.
Impacto do Stripe Size na Latência
O tamanho do bloco (Chunk/Stripe size) é a variável mais ignorada e impactante.
Stripe Pequeno (ex: 4k - 16k): Ótimo para bancos de dados transacionais com leituras aleatórias minúsculas. Porém, aumenta brutalmente o overhead da CPU (mais interrupções por MB transferido).
Stripe Grande (ex: 128k - 1M): Melhor para throughput sequencial (vídeo, backups). Reduz a carga na CPU.
O Trade-off: Se você usar um stripe de 512k e precisar escrever um arquivo de 4k, você está desperdiçando alinhamento e potencialmente causando Write Amplification dependendo do sistema de arquivos. Por outro lado, um stripe muito pequeno em NVMe pode fazer sua CPU engasgar tentando remontar arquivos grandes fragmentados em milhares de pedaços. Para uso geral em NVMe, 64k a 256k costuma ser o "sweet spot".
Como Medir a Realidade: Parâmetros do FIO
Não use dd para testar performance de disco. dd é single-threaded e mede velocidade de gravação sequencial simplista, o que não reflete cargas reais.
Para estressar um arranjo RAID 0 NVMe e ver o gargalo da CPU, você precisa de paralelismo (Queue Depth) e múltiplos jobs.
# Exemplo de teste de IOPS Randômico (O teste de fogo para a CPU)
# rw=randread: Leitura aleatória (pior cenário)
# bs=4k: Bloco pequeno para forçar máximo de IOPS
# iodepth=64: Enche a fila para saturar o protocolo NVMe
# numjobs=8: Usa 8 threads/processos para escalar na CPU
fio --name=random_read_test \
--ioengine=libaio \
--rw=randread \
--bs=4k \
--direct=1 \
--size=10G \
--numjobs=8 \
--iodepth=64 \
--runtime=60 \
--time_based \
--group_reporting \
--filename=/dev/md0
Se ao rodar este comando o seu IOPS parar de subir, mas o uso de CPU de um ou mais núcleos bater em 100% (especificamente em si ou sy no top), você encontrou o teto da sua solução. Adicionar mais discos não vai ajudar.
O Pacto Suicida: A Matemática da Falha
Por fim, como arquiteto, devo alertar sobre a responsabilidade. RAID 0 não é apenas "sem redundância". É redundância negativa.
A probabilidade de o arranjo sobreviver é o produto das probabilidades de sobrevivência de cada disco. Se um drive tem 1% de chance de falhar por ano (0.99 de sobrevivência):
1 Drive: 99% chance de sucesso.
2 Drives: $0.99 \times 0.99 = 98.01%$
4 Drives: $0.99^4 \approx 96.05%$
Parece pouco? Lembre-se que em NVMe, falhas não são apenas mecânicas. Um pico de energia, um bug de firmware ou uma corrupção lógica no controlador afeta o arranjo todo. Em RAID 0, a perda de qualquer componente resulta na perda de 100% dos dados. Não há recuperação parcial.
Use RAID 0 em NVMe apenas para:
Cache/Scratch disks (dados efêmeros).
Workspaces de edição de vídeo onde o dado original está no NAS.
Cenários onde a velocidade de restore do backup é aceitável para o negócio.
Se a sua aplicação precisa de velocidade NVMe e disponibilidade, o caminho correto é RAID 10 (espelhamento + striping). Você perde 50% da capacidade, mas mantém a velocidade de leitura (quase dobra, na verdade), mitiga o gargalo de escrita e dorme tranquilo à noite.
Referências & Leitura Complementar
NVM Express Base Specification 2.0: Detalhes sobre filas de comando e arbitragem em NVMe.
Intel® 64 and IA-32 Architectures Optimization Reference Manual: Seção sobre I/O e latência de interrupções.
Linux Kernel Documentation (mdraid): Documentação técnica sobre a implementação de multi-threading no driver
md.Gregg, Brendan. "Systems Performance: Enterprise and the Cloud, 2nd Edition": Capítulo sobre Discos e File Systems.

David Ross
Linux Sysadmin Veterano
Vive no terminal. Mantenedor de diversos módulos kernel de storage. Acredita que GUI é bloatware.