RAID 10 (1+0) em Bancos de Dados: Performance, Trade-offs e Configuração Real

Esqueça o 'best practice' genérico. Entenda a matemática de IOPS do RAID 10, por que ele supera o RAID 5/6 em latência de escrita e como configurar o chunk size correto para seu banco de dados.
Se você perguntar a um vendedor de storage qual o melhor nível de RAID para o seu banco de dados, ele vai te vender a solução que consome menos disco para parecer mais barata, ou a que usa um algoritmo proprietário mágico de deduplicação. Se você perguntar ao banco de dados, a resposta é crua: ele quer latência zero e garantia de que o dado gravado está realmente no prato (ou na célula NAND).
Bancos de dados transacionais (OLTP) são criaturas de E/S aleatória. Eles não leem arquivos grandes sequencialmente como um servidor de streaming de vídeo. Eles fazem milhares de pequenas leituras e escritas em locais dispersos do disco. É aqui que a maioria das configurações de armazenamento falha: otimizar para throughput (MB/s) quando o jogo real é IOPS e Latência.
Vamos dissecar o RAID 10 (ou 1+0), remover o marketing e olhar para a física e a matemática por trás dessa topologia.
O que é RAID 10 em contextos de alta performance? O RAID 10 é uma configuração de armazenamento aninhada que combina o espelhamento de dados (RAID 1) com o striping (RAID 0). Diferente de níveis baseados em paridade, ele não exige cálculos matemáticos complexos para gravação, oferecendo a melhor performance de escrita aleatória e a reconstrução mais rápida em caso de falha, ao custo fixo de 50% da capacidade total bruta dos discos.
A Penalidade de Escrita (Write Penalty) em Bancos de Dados
O maior inimigo de um banco de dados como PostgreSQL, MySQL ou Oracle não é a falta de CPU, é a espera pelo disco (I/O Wait). Quando você escolhe RAID 5 ou RAID 6 para "economizar espaço", você está introduzindo um imposto severo em cada operação de INSERT, UPDATE ou DELETE.
Isso ocorre devido à Penalidade de Escrita. Em um RAID de paridade (5/6), você não pode simplesmente escrever o novo dado. O controlador precisa:
Ler o dado antigo.
Ler a paridade antiga.
Calcular a nova paridade (XOR).
Escrever o novo dado.
Escrever a nova paridade.
Isso transforma uma única operação lógica do banco de dados em até 4 operações físicas no disco (Read-Modify-Write). Em um cenário de escrita intensa, seu array de discos colapsa muito antes de atingir o limite teórico de transferência.
O RAID 10 elimina essa matemática.
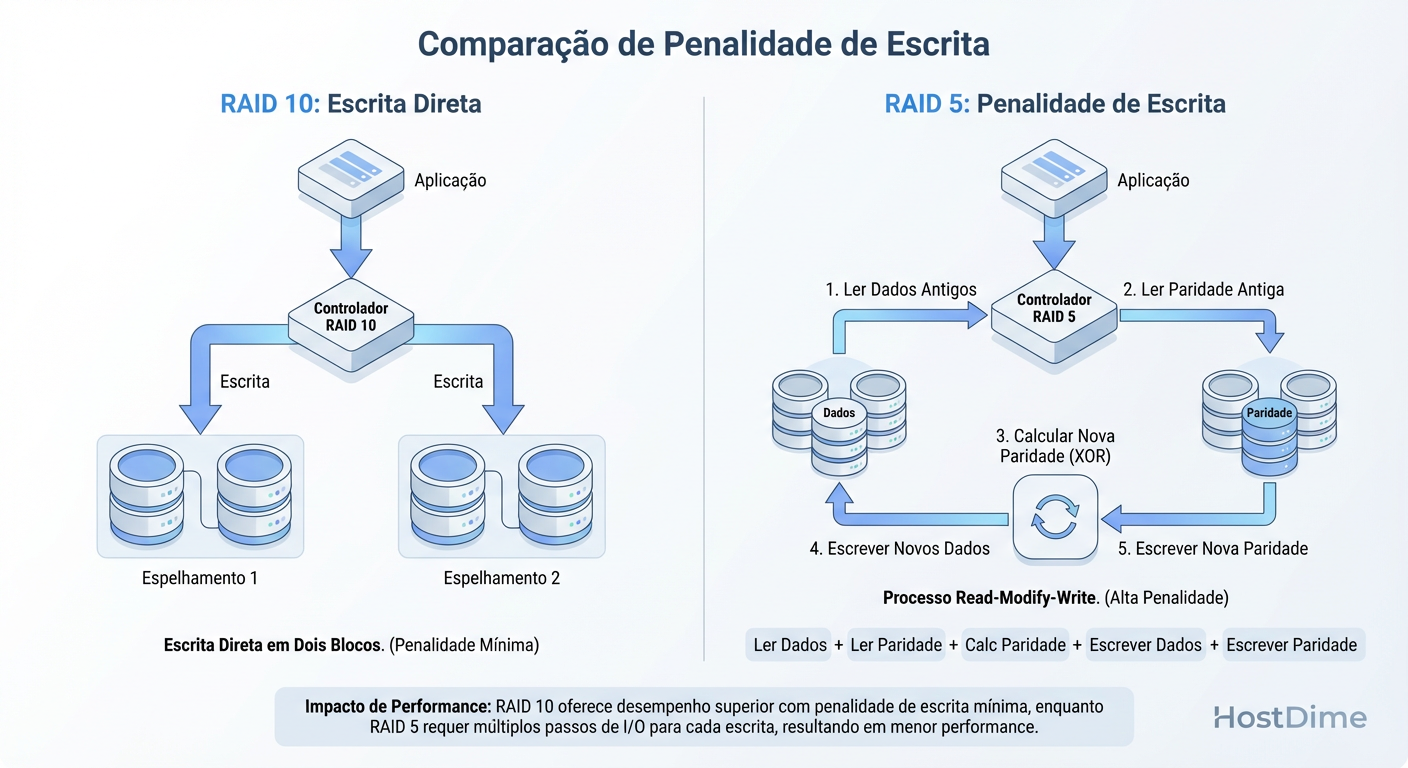 Figura: A Penalidade de Escrita (Write Penalty): Por que o RAID 5 realiza 4 operações de I/O para cada escrita lógica, enquanto o RAID 10 realiza apenas 2.
Figura: A Penalidade de Escrita (Write Penalty): Por que o RAID 5 realiza 4 operações de I/O para cada escrita lógica, enquanto o RAID 10 realiza apenas 2.
No RAID 10, a penalidade é simples: 2. Para escrever um dado, o controlador escreve no disco primário e no espelho. Não há leitura prévia, não há cálculo de XOR. O dado vai direto para o meio físico. Para um DBA, isso significa consistência na latência de escrita (Write Latency), crucial para evitar que o log de transações (WAL) se torne um gargalo.
Anatomia do RAID 10 vs 0+1: Diferenças na Resiliência de Dados
Muitos administradores usam os termos "RAID 10" e "RAID 0+1" de forma intercambiável. Isso é um erro perigoso. A ordem dos fatores altera drasticamente a probabilidade de você perder todos os seus dados durante uma falha de disco.
RAID 0+1 (Mirror of Stripes): Você cria dois arrays RAID 0 rápidos e depois faz um espelho (RAID 1) entre eles. Se um disco falha no lado A, o lado A inteiro torna-se inútil. Você perde a redundância. Se um disco falhar no lado B enquanto o A está sendo reconstruído, game over.
RAID 1+0 (Stripe of Mirrors): Você cria vários pares de espelhos (RAID 1) e depois faz um stripe (RAID 0) sobre esses pares.
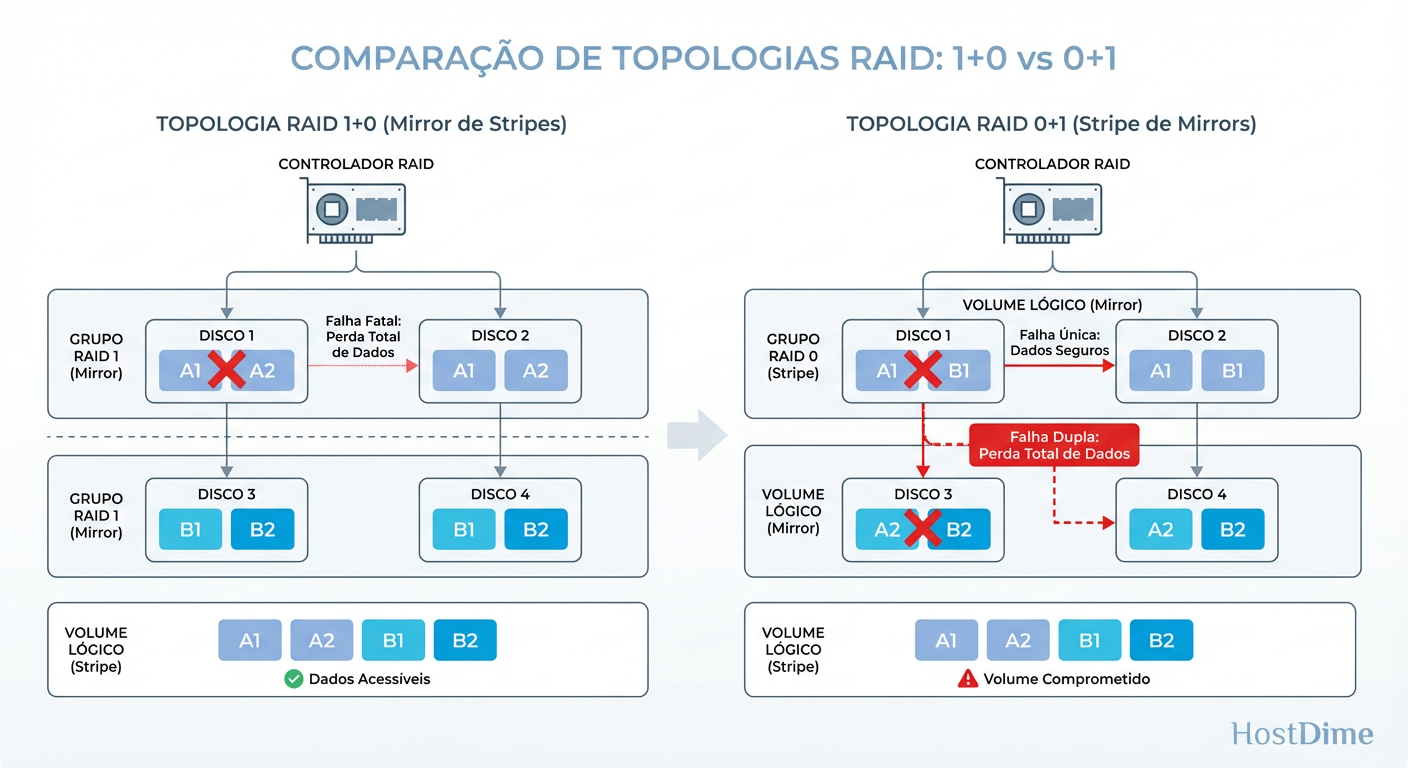 Figura: Topologia RAID 1+0 vs 0+1: No 1+0 (esquerda), a perda de um disco afeta apenas um espelho. No 0+1 (direita), a perda de um disco compromete todo um lado do stripe.
Figura: Topologia RAID 1+0 vs 0+1: No 1+0 (esquerda), a perda de um disco afeta apenas um espelho. No 0+1 (direita), a perda de um disco compromete todo um lado do stripe.
No RAID 1+0 (a configuração correta), se um disco falha, apenas aquele par específico perde a redundância. O restante do array continua protegido. Para haver perda de dados, o segundo disco a falhar precisa ser exatamente o par do primeiro disco morto. Estatisticamente, a resiliência do 1+0 é ordens de magnitude superior à do 0+1.
Callout de Risco: Verifique a documentação do seu controlador RAID ou Storage Area Network (SAN). Alguns vendors chamam tudo de "RAID 10", mas implementam a lógica de 0+1 internamente. Exija a topologia "Stripe of Mirrors".
Matemática de IOPS no RAID 10: Calculando Performance Real
Pare de adivinhar a performance. Você pode calcular o teto teórico do seu array antes de comprar o hardware. A fórmula básica para IOPS (Input/Output Operations Per Second) em RAID 10 considera a penalidade de escrita de 2x.
Suponha um array com 8 discos. Cada disco individual oferece, hipoteticamente, 200 IOPS (típico de SAS 15k, embora baixo para SSDs, a lógica se mantém).
Capacidade de Leitura (Read IOPS): O RAID 10 pode ler de todos os discos simultaneamente. $$IOPS_{Leitura} = N \times IOPS_{Disco}$$ $$8 \times 200 = 1600 \text{ IOPS de Leitura}$$
Capacidade de Escrita (Write IOPS): Aqui entra a penalidade. Cada escrita lógica consome 2 IOPS físicos. $$IOPS_{Escrita} = \frac{N \times IOPS_{Disco}}{2}$$ $$8 \times 200 / 2 = 800 \text{ IOPS de Escrita}$$
Comparação Rápida com RAID 5 (mesmos 8 discos): A escrita no RAID 5 tem penalidade de 4. $$IOPS_{Escrita(R5)} = \frac{8 \times 200}{4} = 400 \text{ IOPS}$$
O RAID 10 entrega o dobro da performance de escrita do RAID 5 com o mesmo número de spindles (eixos/discos). Se o seu workload é 50% leitura e 50% escrita (comum em ERPs e sistemas transacionais), o RAID 10 não é um luxo, é uma necessidade matemática.
RAID 10 com SSD e NVMe: Desgaste, Latência e Sobrecarga de CPU
"Mas eu uso All-Flash, preciso me preocupar com RAID?"
Sim, e talvez mais do que antes. Embora a latência do SSD mascare a penalidade de leitura/modificação do RAID 5/6, existem dois fatores críticos na era do Flash:
Write Amplification e Desgaste (Endurance): SSDs têm vida útil limitada por escritas (TBW - Terabytes Written). O RAID 5/6 gera escritas extras de paridade. Se você tem um banco de dados com escritas pesadas, o RAID 5 vai queimar suas células NAND mais rápido do que o RAID 10. O RAID 10 escreve exatamente 2x. O RAID 5/6, devido ao processo de read-modify-write, pode gerar tráfego interno excessivo e "write cliffs" (queda súbita de performance quando o garbage collection do SSD satura).
Gargalo de CPU (Software RAID): Com discos NVMe modernos capazes de milhões de IOPS, o gargalo mudou do disco para a CPU. Calcular paridade (RAID 5/6) custa ciclos de processador. Em arrays NVMe de alta velocidade, o cálculo de XOR pode saturar cores da CPU que deveriam estar servindo ao banco de dados. O RAID 10, sendo apenas cópia e distribuição, tem um overhead de CPU quase nulo.
Configuração Prática de RAID 10 no Linux: Alinhamento de Chunk e Page Size
Não basta criar o array. O alinhamento entre o sistema de arquivos, o driver RAID e o banco de dados é onde a performance é ganha ou perdida.
O parâmetro crítico é o Chunk Size (ou Stripe Unit Size). É a quantidade de dados que o controlador escreve em um disco antes de pular para o próximo.
Se o seu banco de dados (ex: PostgreSQL) usa páginas de 8KB, e seu Chunk Size é 64KB, uma leitura aleatória de 8KB virá de um único disco. Isso é bom para concorrência (outros discos ficam livres para outras queries). Se você configurar um Chunk Size muito pequeno (ex: 4KB), uma leitura de 8KB obrigará dois discos a trabalharem para entregar um único dado minúsculo, cortando seus IOPS pela metade.
Exemplo de Criação (mdadm)
Para um banco de dados padrão (Page size 8KB ou 16KB), um Chunk Size de 64KB a 256KB costuma ser o "sweet spot". Evite chunks gigantes (1MB+) para DBs, a menos que seja Data Warehouse (DW).
# Exemplo: Criando RAID 10 com 4 drives (nvme0n1 a nvme3n1)
# Layout 'f2' (far 2) pode oferecer leitura sequencial melhor em discos rotacionais,
# mas para SSD/NVMe o layout padrão 'n2' (near 2) é geralmente preferido por simplicidade e latência.
# Chunk de 64KB.
mdadm --create /dev/md0 --level=10 --raid-devices=4 --chunk=64 /dev/nvme0n1 /dev/nvme1n2 /dev/nvme2n3 /dev/nvme3n4
Checklist de Alinhamento:
RAID Chunk Size: 64KB (exemplo).
Partition Alignment: O início da partição deve ser múltiplo do Chunk Size.
Filesystem Stride: Ao formatar (mkfs.xfs ou mkfs.ext4), informe o tamanho do chunk e a largura do stripe para que o sistema de arquivos otimize a alocação.
Custo de Capacidade no RAID 10: Quando a Perda de 50% Compensa
O argumento contra o RAID 10 é sempre financeiro. Perder 50% da capacidade bruta dói no orçamento. Mas o custo deve ser analisado sob a ótica de "Custo por IOPS de Escrita", não "Custo por Terabyte".
Abaixo, uma comparação direta para auxiliar na decisão técnica:
| Característica | RAID 10 (1+0) | RAID 5 | RAID 6 |
|---|---|---|---|
| Eficiência de Espaço | 50% (Fixo) | 67% - 94% (Depende de N) | 50% - 88% (Depende de N) |
| Penalidade de Escrita | 2x (Baixa) | 4x (Alta) | 6x (Muito Alta) |
| Velocidade de Rebuild | Muito Rápida (Copia apenas dados) | Lenta (Lê todo o array + XOR) | Lenta (Lê todo o array + XOR) |
| Risco em Rebuild | Baixo (Stress apenas no espelho) | Alto (Stress em todos os discos) | Médio (Tolera 2 falhas) |
| Uso Ideal | DB Transacional (OLTP), VM Host | File Server, Web Server (Read Heavy) | Archive, Backup, Object Storage |
Veredito Operacional: Se o seu banco de dados é o coração da empresa e o tempo de inatividade ou lentidão custa dinheiro, o custo extra dos discos para RAID 10 é irrelevante comparado ao prejuízo de um sistema lento ou de uma reconstrução de RAID 5 que leva 48 horas (durante as quais a performance fica abismal).
Use RAID 10. Se não puder pagar por RAID 10 em SSDs, use RAID 10 em discos mecânicos SAS antes de tentar RAID 5 em SSDs baratos sem cache de escrita (PLP). A física não perdoa.
Referências & Leitura Complementar
The BAARF (Battle Against Any Raid Five) Archives: Artigos seminais sobre por que RAID 5 é perigoso para dados críticos.
Linux Kernel Documentation - MD RAID: Detalhes sobre algoritmos de alocação e layouts (near vs far) no driver
md.PostgreSQL Hardware Performance Tuning: Documentação e papers sobre alinhamento de WAL e storage.
RFC 3720 (iSCSI): Para entender como a latência de rede se soma à latência de disco em storages remotos.

Elena Kovacs
Arquiteta de Cloud Infrastructure
Focada em NVMe-oF e storage definido por software. Projeta clusters de petabytes para grandes provedores de nuvem.