RAID 5 Rebuild: Otimizando Tempos de Reconstrução com Distributed Spares

Reduza o tempo de rebuild do RAID 5 de dias para horas. Entenda a matemática dos Distributed Spares (dRAID), elimine o gargalo do disco único e evite falhas catastróficas por URE.
Todo sysadmin veterano conhece o som do silêncio que precede o desastre. É sexta-feira, 17:00, e o sistema de monitoramento dispara um alerta crítico: um disco falhou no seu array principal. Se você está rodando RAID 5 (ou RAIDZ1) com discos modernos de alta capacidade, esse alerta não é apenas um inconveniente; é uma roleta russa estatística.
Durante a próxima semana — sim, pode levar dias — você estará rezando para a "Deusa da Probabilidade". Por quê? Porque a capacidade dos discos cresceu exponencialmente (20TB+), mas a velocidade mecânica dos atuadores (IOPS) e a taxa de transferência sequencial estagnaram. O resultado é um tempo de reconstrução (rebuild) que deixa sua infraestrutura exposta a uma segunda falha fatal por tempo demais.
A indústria tentou vender discos mais rápidos, mas a física venceu. A solução real não é hardware mais rápido, é uma arquitetura mais inteligente: Distributed Spares (Reservas Distribuídas). Vamos dissecar por que o modelo tradicional de Hot Spare é um gargalo obsoleto e como o conceito de distribuição de reserva resolve a matemática do medo.
O que é Distributed Spare (dRAID)?
Distributed Spare (ou dRAID) é uma arquitetura de armazenamento onde, em vez de manter um disco físico inteiro ocioso e vazio esperando uma falha (Hot Spare dedicado), a capacidade de reserva é espalhada logicamente por todos os discos do array. Quando uma falha ocorre, o processo de reconstrução utiliza a largura de banda de escrita de todos os discos restantes simultaneamente, reduzindo o tempo de recuperação de dias para horas, minimizando drasticamente a janela de vulnerabilidade a falhas secundárias.
A Matemática do Medo: Por que o Rebuild do RAID 5 Falha com Discos Grandes
Esqueça o marketing dos fabricantes de storage por um minuto. Vamos falar de URE (Unrecoverable Read Error). Um disco SATA de consumo típico tem uma taxa de URE de 1 em $10^{14}$ bits lidos. Um disco Enterprise SAS, talvez 1 em $10^{15}$.
Parece muito, até você fazer a conta. Se você tem um array RAID 5 com discos de 18TB ou 20TB, para reconstruir um disco falho, você precisa ler cada bit dos discos restantes para recalcular a paridade.
Ao ler 100TB de dados para reconstruir o array, a probabilidade estatística de encontrar um setor ilegível (bad block) em um dos discos "saudáveis" aproxima-se de 100% em drives de consumo e torna-se perigosamente alta em drives Enterprise. No RAID 5 clássico, se você encontrar um erro de leitura durante o rebuild: Game Over. O array falha ou, na melhor das hipóteses, você corrompe arquivos silenciosamente.
Além do URE, o problema é o tempo. O rebuild é uma corrida contra o relógio antes que o próximo disco falhe. E é aqui que o modelo tradicional quebra.
O Gargalo Físico do Hot Spare Dedicado
No modelo clássico, você tem, digamos, 10 discos ativos e 1 disco Hot Spare parado, acumulando poeira. Quando o Disco 3 morre, a controladora acorda o Hot Spare e começa a reconstruir os dados nele.
O problema de física aqui é simples: Gargalo de um único eixo.
Você tem 9 discos lendo dados para gerar a paridade. Somados, eles têm uma largura de banda enorme. Mas você está escrevendo esses dados recuperados em apenas um disco (o Spare). A velocidade de reconstrução do seu array inteiro está limitada à velocidade de escrita sequencial desse único disco de destino (talvez 150MB/s a 250MB/s em spinning rust).
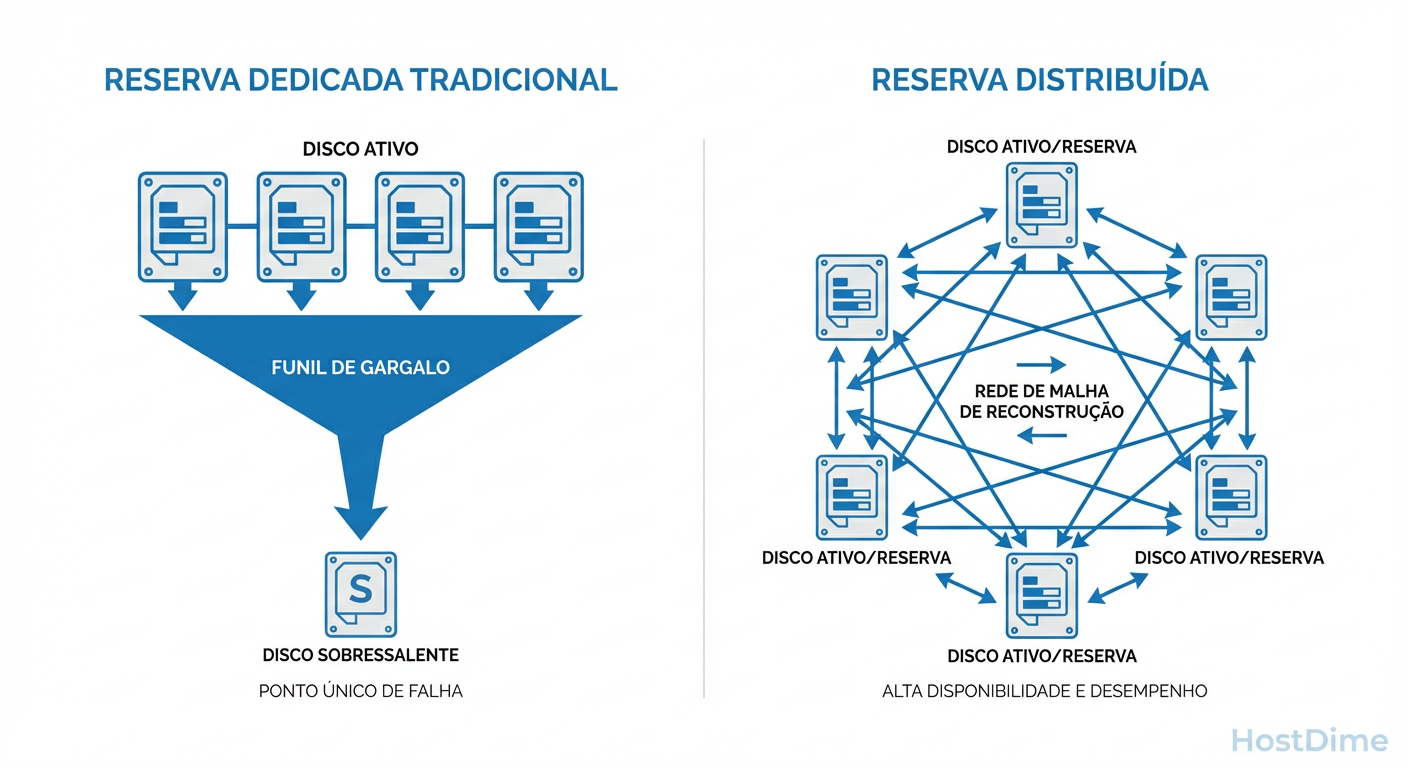 Figura: Diagrama Comparativo: O gargalo do Spare Dedicado (limitado à velocidade de escrita de um disco) versus o paralelismo do Spare Distribuído.
Figura: Diagrama Comparativo: O gargalo do Spare Dedicado (limitado à velocidade de escrita de um disco) versus o paralelismo do Spare Distribuído.
Isso significa que, não importa quão potente seja sua CPU ou quão rápida seja sua controladora, a física do prato magnético dita que encher um disco de 20TB levará, na melhor das hipóteses teóricas, cerca de 22 a 24 horas. Na prática, com a carga de trabalho dos usuários competindo por IOPS, isso vira 4, 5 ou 7 dias.
Como o Distributed Spare Otimiza a Reconstrução
O conceito de Distributed Spare (popularizado pelo IBM GPFS e agora acessível via OpenZFS dRAID) muda a topologia. Não existe um "disco vazio". A capacidade de reserva é fatiada e espalhada por todos os drives do pool.
Se você tem um array de 50 discos com capacidade equivalente a 2 Spares Distribuídos:
Operação Normal: Todos os 50 discos estão ativos e servindo dados. Você ganha a performance de 50 eixos, não 48.
Falha: Quando um disco morre, o sistema não precisa escrever tudo em um único drive substituto. Ele reconstrói os dados perdidos usando o espaço livre reservado nos 49 discos restantes.
O ganho de performance: Em vez de 1 disco escrevendo, você tem 49 discos escrevendo simultaneamente. O gargalo deixa de ser o disco de destino e passa a ser a CPU da controladora (que é muito mais rápida).
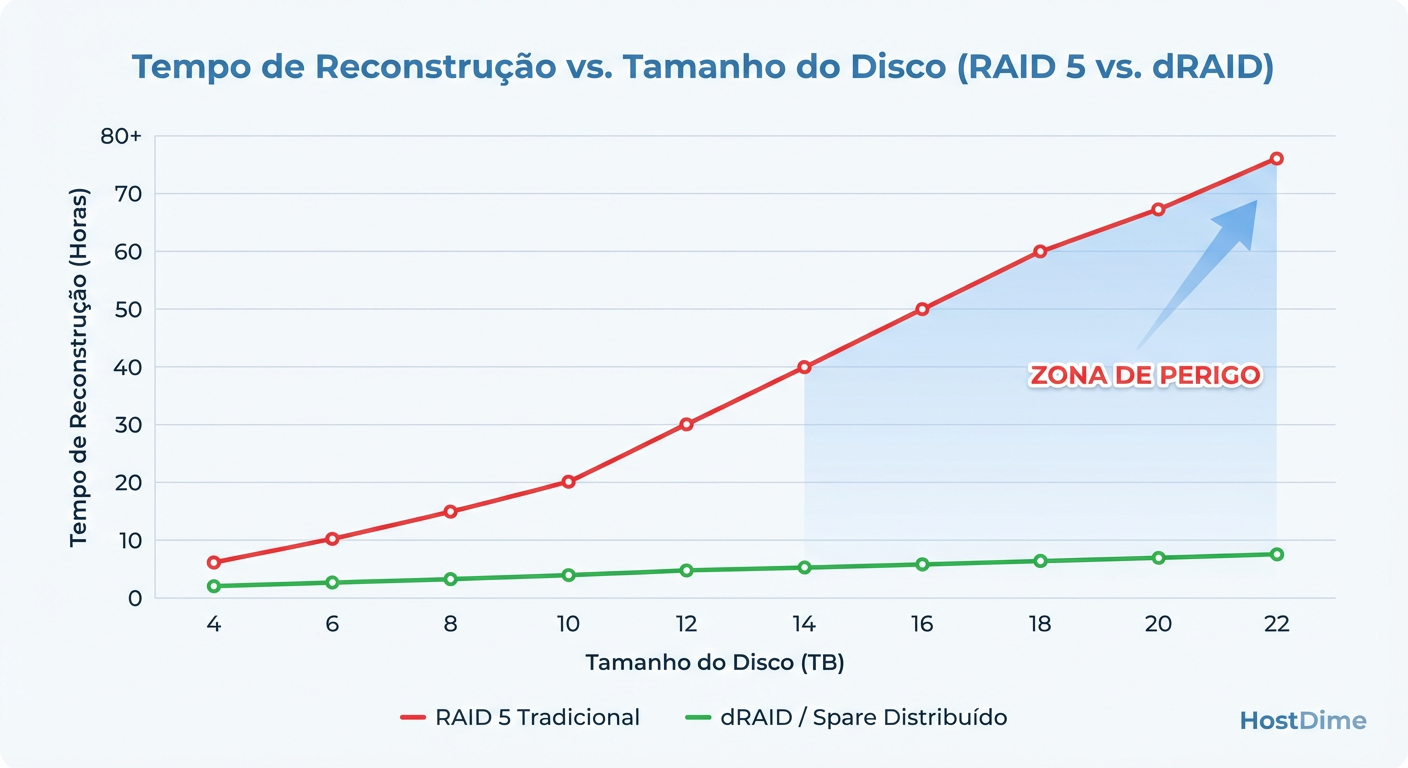 Figura: Gráfico de Tempo de Rebuild: Como o Distributed Spare mantém o tempo de recuperação gerenciável mesmo com o aumento da capacidade dos discos.
Figura: Gráfico de Tempo de Rebuild: Como o Distributed Spare mantém o tempo de recuperação gerenciável mesmo com o aumento da capacidade dos discos.
Isso transforma um rebuild de 4 dias em um rebuild de 4 horas. Essa redução de tempo diminui a "Janela de Vulnerabilidade" em uma ordem de magnitude.
Implementação Real: ZFS dRAID vs Tradicional
Para quem opera em ambientes Linux ou BSD modernos, o ZFS dRAID (introduzido no OpenZFS 2.1) é a implementação mais acessível dessa tecnologia. Diferente de controladoras de hardware proprietárias (como as da Dell/EMC ou NetApp que cobram licenças caras por isso), o dRAID é software-defined.
Comparativo de Arquitetura: RAIDZ vs dRAID
| Característica | RAIDZ (Tradicional) + Hot Spare | ZFS dRAID (Distributed Spare) |
|---|---|---|
| Uso de IOPS (Normal) | Apenas discos de dados (N-1) | Todos os discos do array (N) |
| Gargalo de Rebuild | Velocidade de escrita de 1 disco (Spare) | Largura de banda agregada de todos os discos |
| Tempo de Rebuild (20TB) | ~30 a 100+ Horas | ~5 a 15 Horas (depende da largura do array) |
| Complexidade | Baixa (Conceito simples) | Média/Alta (Layout fixo na criação) |
| Flexibilidade | Fácil adicionar/remover spares | Capacidade de spare é fixa na criação do VDEV |
Exemplo Prático: Criando um Pool dRAID
Não basta teoria. Se você for implementar isso, precisa entender a sintaxe. Abaixo, um exemplo de criação de um pool com redundância dupla (equivalente a RAID 6), com capacidade de reserva virtual equivalente a 2 discos, espalhada por 11 discos físicos.
# Exemplo: draid2 (paridade dupla), 8 dados + 2 paridade (implícito), 2 spares virtuais
zpool create tank draid2:8d:2s /dev/disk/by-id/scsi-SATA_disk{1..11}
Nota do Cético: Perceba que definimos :2s. Não há dois discos parados. O ZFS reserva o espaço equivalente a dois discos distribuído entre os 11. Se um disco falhar, o rebuild começa imediatamente para esse espaço reservado.
Trade-offs e Riscos: Quando o Distribuído não vale a pena
Como engenheiro, você sabe que não existe almoço grátis. O Distributed Spare resolve o problema do tempo de rebuild, mas introduz rigidez.
Imutabilidade do Layout: Uma vez criado um VDEV dRAID, você não pode simplesmente "remover" o distributed spare para ganhar espaço, nem converter um dRAID em RAIDZ normal. O layout é fixo.
Overhead de Pequenos Arrays: Se você tem um servidor com apenas 4 ou 6 discos, o dRAID não faz sentido matemático. O ganho de paralelismo é irrelevante comparado à complexidade. Essa tecnologia brilha em arrays com 20, 50, 100 discos (JBODs de alta densidade).
IOPS de Leitura: Embora o rebuild seja rápido, a leitura de arquivos pequenos pode ter latências ligeiramente diferentes devido ao mapeamento complexo dos blocos, embora em cargas sequenciais o ganho de ter todos os eixos ativos geralmente compense.
Veredito Operacional
Se você gerencia storage de alta densidade (Petabytes) com discos mecânicos grandes, RAID 5/6 tradicional com Hot Spare dedicado é negligência operacional. O tempo de reconstrução é matematicamente incompatível com a confiabilidade exigida em produção.
O Distributed Spare não é "hype"; é a única maneira física de drenar a taxa de transferência necessária para reconstruir drives de 20TB antes que a entropia leve seu segundo disco para o túmulo. Meça seu tempo de rebuild atual. Se for maior que 24 horas, é hora de mudar sua arquitetura.
Referências & Leitura Complementar
OpenZFS Documentation - dRAID Feature Guide & Topology.
RFC 3514 (Ironia/Humor, mas relevante sobre segurança) - The Evil Bit.
Leventhal, Adam - ZFS: The Last Word in File Systems (Conceitos fundamentais de integridade).
Datasheets Seagate Exos / WD Gold - Verifique as tabelas de Sustained Transfer Rate vs Capacity para calcular seus próprios tempos de rebuild.
Patterson, Gibson, Katz (1988) - A Case for Redundant Arrays of Inexpensive Disks (RAID) - O paper original, para entender onde tudo começou e por que o modelo de 1988 não escala para 2024.

Alexei Volkov
Ceph Cluster Administrator
Escala clusters Ceph para o infinito. Mestre em CRUSH maps e recuperação de placement groups.