RAID 5 Write Hole: Por que seus dados correm perigo (e como corrigir)
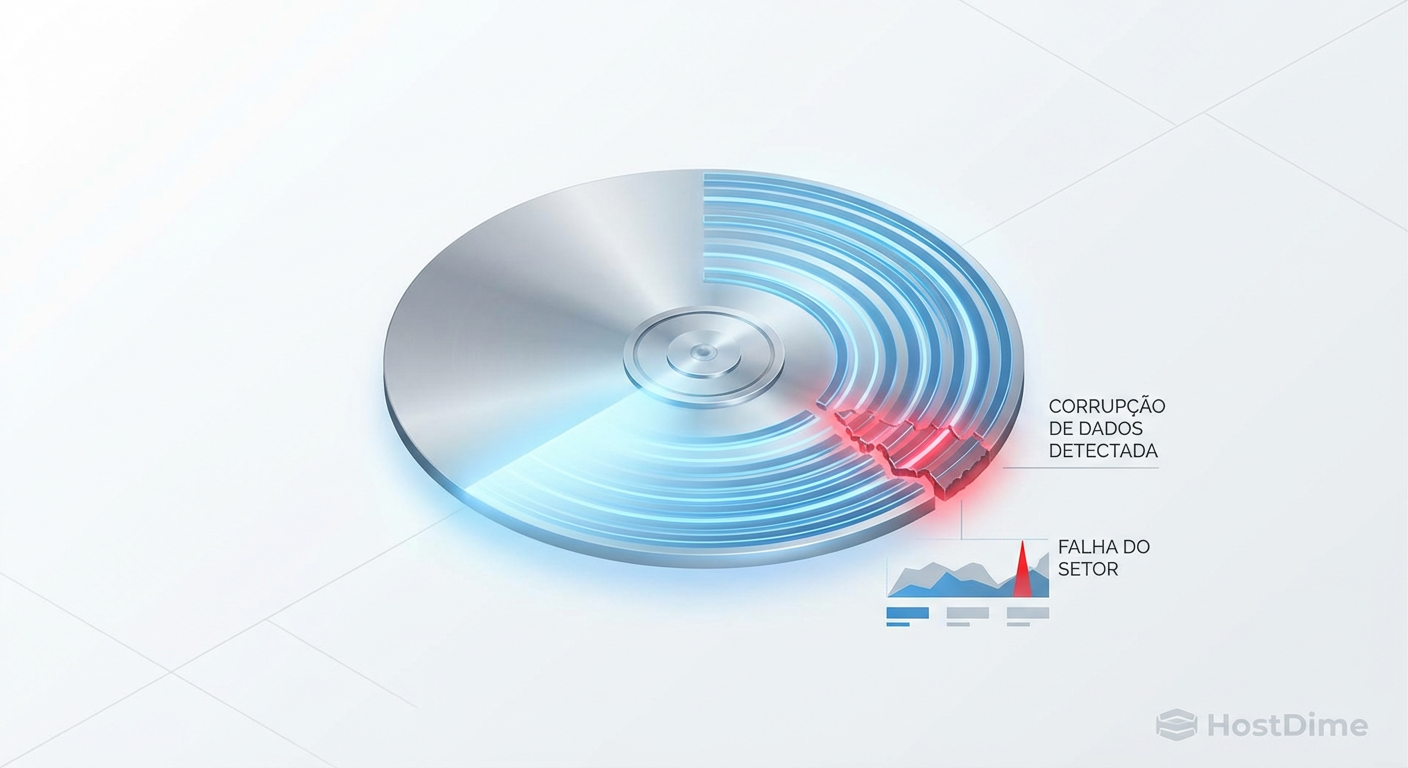
Entenda o 'Write Hole' no RAID 5: a falha de atomicidade que corrompe dados silenciosamente. Análise técnica de soluções via BBU, Journaling e ZFS.
Você entra no data center. O silêncio é pesado, interrompido apenas pelo zumbido dos ventiladores girando novamente após uma queda abrupta de energia. O servidor de arquivos reiniciou. O sistema operacional montou o volume RAID 5. O fsck ou o chkdsk disse que está "tudo limpo".
Como investigador forense de sistemas, eu afirmo: o sistema está mentindo para você.
Nesse exato momento, você pode ter blocos de dados corrompidos que permanecerão invisíveis por meses, até o dia em que um disco falhar e você precisar reconstruir o array. É aí que o crime se revela. O "RAID 5 Write Hole" não é um bug de software; é uma falha arquitetural na lógica de como a paridade é atualizada.
Vamos dissecar essa "cena do crime", entender a física por trás da perda de dados e, mais importante, como mitigar esse risco sem depender da sorte.
O que é o RAID 5 Write Hole?
O RAID 5 Write Hole é um fenômeno de corrupção silenciosa de dados que ocorre quando uma falha de energia interrompe uma gravação no meio do ciclo. Como o RAID 5 exige que dados e paridade sejam atualizados simultaneamente, uma interrupção súbita pode deixar a paridade dessincronizada com os dados. O sistema não percebe o erro até que uma leitura de recuperação seja necessária, resultando na restauração de lixo digital em vez de arquivos válidos.
Anatomia de uma Gravação Falha: A Quebra da Atomicidade
Para entender o Write Hole, precisamos abandonar a ideia de que "gravar um arquivo" é um evento único. Em storage, uma gravação em RAID 5 (ou RAID 6) é uma sequência complexa de operações, frequentemente chamada de ciclo Read-Modify-Write.
Imagine que você precisa alterar apenas um pequeno bloco de dados em um stripe (faixa) existente. O controlador RAID não pode simplesmente "jogar" o dado lá. Ele precisa:
Ler o dado antigo.
Ler a paridade antiga.
Calcular a nova paridade (XOR entre dado novo, dado antigo e paridade antiga).
Gravar o novo dado.
Gravar a nova paridade.
O problema reside nos passos 4 e 5. Eles não são atômicos. Eles não acontecem no mesmo nanossegundo.
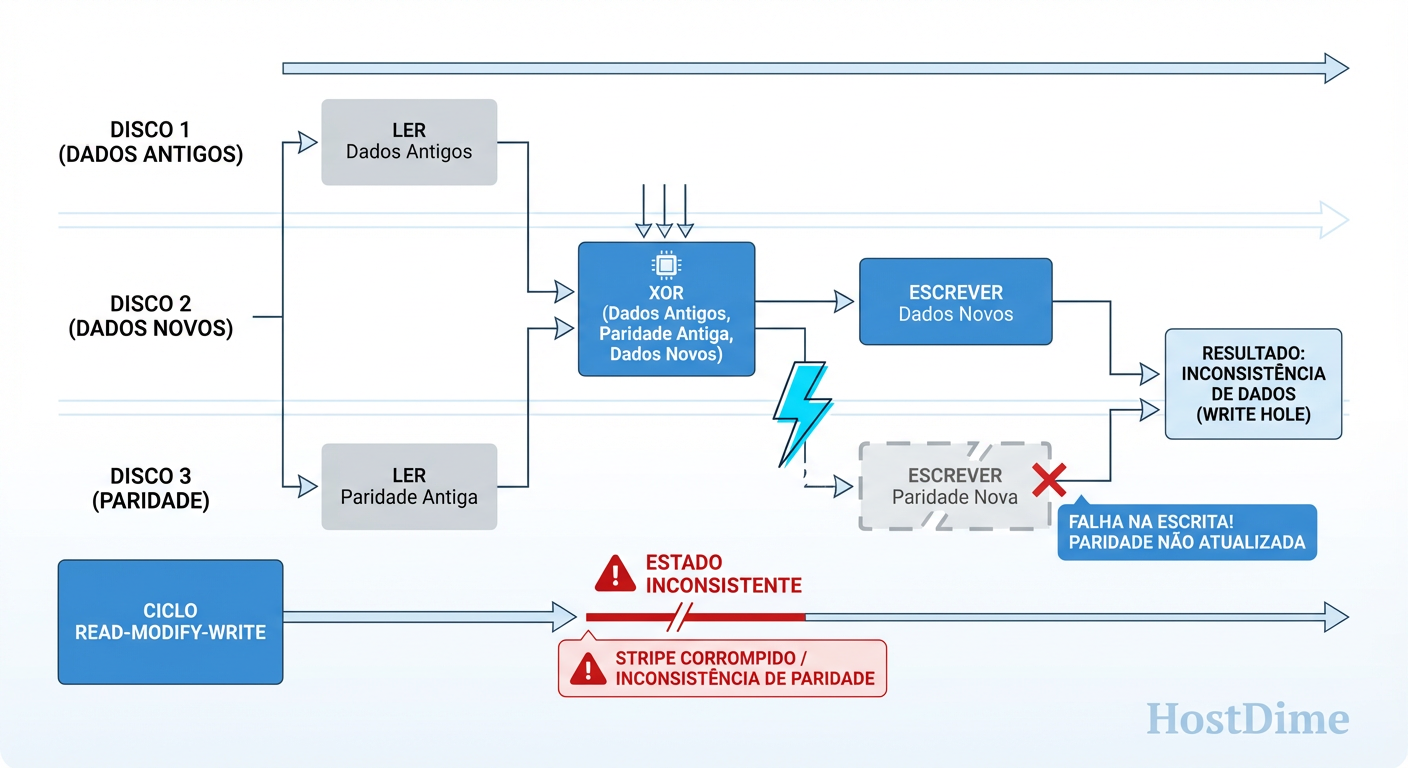 Figura: A Quebra da Atomicidade: O momento exato onde a paridade se desvincula dos dados reais.
Figura: A Quebra da Atomicidade: O momento exato onde a paridade se desvincula dos dados reais.
Se a energia cai exatamente entre o passo 4 e o 5, você tem o novo dado no disco, mas a velha paridade no disco de paridade. Ou vice-versa.
Quando a energia volta, o controlador RAID olha para os discos e diz: "Os metadados estão ok, o volume está montado". Ele não lê todos os terabytes de dados para verificar se o cálculo XOR de cada stripe bate. Isso seria um scrub ou resync completo, que leva horas ou dias.
A "arma do crime" (a paridade dessincronizada) fica escondida, esperando a próxima falha de disco para disparar.
A Ilusão da Segurança: Por que a paridade desincronizada é invisível
Muitos administradores operam sob a falsa premissa de que "RAID protege meus dados". O RAID protege disponibilidade, não integridade.
No cenário descrito acima, o sistema operacional lê o arquivo corrompido? Não. Em operação normal (degraded mode = false), o RAID 5 lê os dados diretamente dos discos de dados. A paridade é ignorada na leitura. Portanto, você lê o dado novo (que foi gravado com sucesso antes da queda) e tudo parece perfeito.
O desastre acontece 6 meses depois. O "Disco 3" falha.
O controlador RAID precisa reconstruir os dados do Disco 3 usando a matemática: Dado Perbido = Paridade XOR (Resto dos Dados).
Como a paridade naquele bloco específico nunca foi atualizada (devido àquela queda de energia meses atrás), o controlador reconstrói o dado usando a paridade antiga. O resultado é lixo. O arquivo é corrompido silenciosamente durante o rebuild. Você perdeu dados exatamente quando a redundância deveria salvá-lo.
Soluções de Hardware: Como o Cache com BBU mantém a verdade
Historicamente, a solução para o Write Hole era jogar dinheiro no problema. Controladoras RAID de hardware (PERC, HP SmartArray, Adaptec) introduziram o conceito de Cache Não-Volátil (NVRAM) apoiado por uma BBU (Battery Backup Unit).
O fluxo forense muda com esse hardware:
O SO envia o dado para gravar.
A controladora guarda o dado na memória RAM (cache).
A controladora diz ao SO: "Gravei, pode seguir!" (uma mentira conveniente para performance).
A controladora calcula a paridade e grava nos discos fisicamente quando possível.
O cenário de desastre: A energia cai enquanto os dados estão na RAM da controladora. A evidência: A bateria (BBU) mantém a RAM viva. Quando a energia volta, a controladora detecta que há "dados sujos" no cache que não foram para o disco e termina a gravação (passos 4 e 5) antes de disponibilizar o volume.
Veredito: Eficaz, mas caro e introduz um ponto de falha de manutenção (baterias incham, falham e precisam de ciclos de aprendizado). Se a bateria morrer e você não notar, o Write Hole volta a ser uma ameaça real.
Mitigação em Software: O trade-off brutal dos Write Intent Bitmaps
Com a migração massiva para Software RAID (Linux mdadm, LVM), perdemos a BBU. Como o kernel do Linux resolve isso sem hardware dedicado? A resposta é o Write Intent Bitmap.
O conceito é criar um "diário de intenções". Antes de iniciar a perigosa sequência Read-Modify-Write, o mdadm:
Grava em uma área reservada do disco: "Estou prestes a mexer nos blocos X a Y".
Executa a gravação dos dados e paridade.
Limpa a marcação no bitmap: "Terminei".
Se a energia cair, ao reiniciar, o mdadm olha o bitmap. "Ah, eu estava mexendo no bloco X". Ele força uma ressincronização apenas daquela pequena área, garantindo que a paridade bata com os dados.
O Custo da Performance
Segurança custa caro. O Write Intent Bitmap transforma gravações sequenciais em um pesadelo de seek (movimento da cabeça de leitura em HDDs), pois o disco precisa ir até a área do bitmap, escrever, ir até a área de dados, escrever, e voltar.
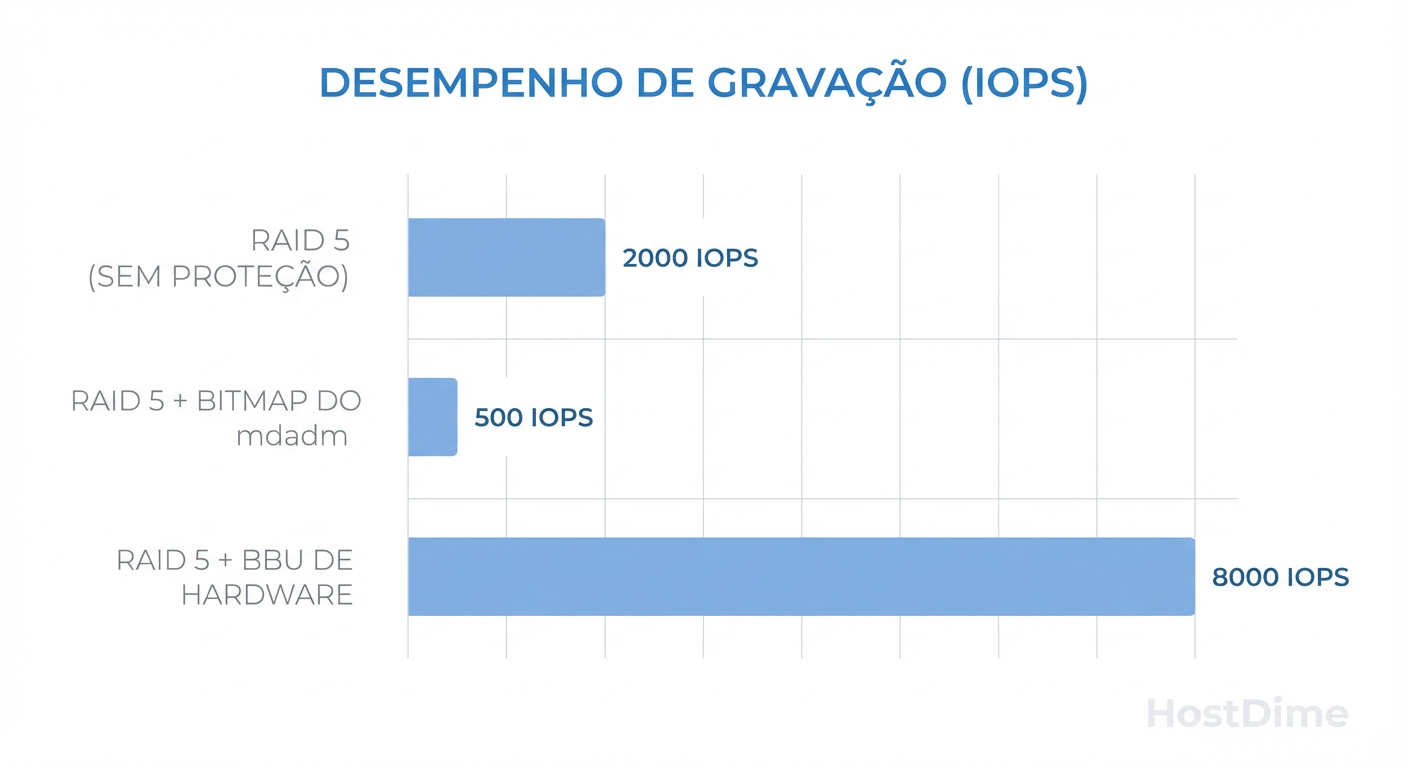 Figura: O Custo da Segurança: Impacto de performance entre Bitmaps de software e Cache protegido por hardware.
Figura: O Custo da Segurança: Impacto de performance entre Bitmaps de software e Cache protegido por hardware.
Em SSDs, o impacto é menor, mas em HDDs mecânicos, ativar o bitmap pode degradar a performance de escrita em até 50% dependendo da carga de trabalho.
Operando o mdadm (Comando real)
Se você tem um array RAID 5 crítico sem bateria, você deve considerar ativar o bitmap, aceitando a perda de performance:
# Verificar se o bitmap está ativo
cat /proc/mdstat
# Adicionar um bitmap interno (armazenado nos próprios discos do array)
mdadm --grow /dev/md0 --bitmap=internal
# Para remover (se a performance ficar inaceitável)
mdadm --grow /dev/md0 --bitmap=none
A Abordagem ZFS: Como o Copy-on-Write (CoW) altera a física
O ZFS (e sistemas similares como Btrfs) não tenta "consertar" o Write Hole; ele muda a física do problema para que o buraco não possa existir.
Em vez de sobrescrever dados e paridade no local (in-place update), o ZFS usa Copy-on-Write (CoW).
Você quer alterar um bloco.
O ZFS grava o novo dado e a nova paridade em um novo local livre no disco.
Só depois que ambos estão gravados com sucesso, o ZFS atualiza o ponteiro de metadados (o "Uberblock") para apontar para o novo local.
Essa atualização do ponteiro é atômica. Ou a transação inteira aconteceu (ponteiro atualizado), ou nada aconteceu (ponteiro antigo permanece).
Se a energia cair no meio da gravação, o ponteiro ainda aponta para os dados antigos (que são válidos e consistentes). Os "novos" dados incompletos são apenas lixo em espaço livre que será sobrescrito depois. Não existe momento onde a paridade esteja dessincronizada com os dados ativos.
Nota Forense: O ZFS RAIDZ sofre de penalidades de performance em IOPS aleatórios, mas a integridade estrutural contra o Write Hole é matematicamente superior ao RAID 5 tradicional.
Veredito Operacional: Comparativo de Soluções
Não existe "melhor" absoluto, existe o trade-off correto para o seu orçamento e risco aceitável.
| Característica | RAID Hardware (BBU) | Software RAID (mdadm + Bitmap) | ZFS (RAIDZ) |
|---|---|---|---|
| Proteção Write Hole | Alta (enquanto a bateria durar) | Alta | Total (por design) |
| Impacto Performance | Baixo (Cache acelera writes) | Alto (Latência de escrita) | Variável (CPU intensive) |
| Dependência de HW | Alta (Placa específica) | Nenhuma | Nenhuma (mas gosta de RAM) |
| Custo | $$$ | $ | $ (exige mais RAM/CPU) |
Quando confiar no UPS e quando exigir Journaling?
Muitos administradores dizem: "Eu tenho um UPS (Nobreak) online de dupla conversão, não preciso me preocupar".
Ceticismo necessário: O UPS protege contra cortes da concessionária. Ele não protege contra:
Alguém tropeçando no cabo de força (o clássico "teste do estagiário").
A fonte de alimentação (PSU) do servidor queimando.
Kernel Panic ou travamento do SO.
A Regra de Ouro: Se os dados valem mais que o hardware, não confie apenas no UPS.
Se usar Hardware RAID, monitore a saúde da bateria obsessivamente.
Se usar Linux mdadm, ative o bitmap ou mude para RAID 6 (que mitiga, mas não elimina totalmente o risco sem complexidade extra) ou RAID 10 (que não tem cálculo de paridade, eliminando o write hole por definição).
Se puder escolher a arquitetura do zero, use ZFS. A consistência transacional do CoW é a única defesa robusta contra a entropia do hardware.
Referências & Leitura Complementar
Patterson, D., et al. (1988). "A Case for Redundant Arrays of Inexpensive Disks (RAID)". University of California, Berkeley. (O documento fundacional).
Bonwick, J. (2005). "ZFS: The Last Word in File Systems". Sun Microsystems. (Explicação do modelo transacional CoW).
Linux Kernel Documentation. "Raid5 Write Hole and Write Intent Bitmaps". kernel.org.
Corbet, J. (2017). "The RAID5 write hole". LWN.net.

Dr. Marcus 'Bitrot' Silva
Engenheiro Sênior de Armazenamento
20 anos recuperando RAIDs quebrados. Especialista em ZFS e sistemas de arquivos distribuídos. Já viu mais falhas de disco do que gostaria.