RAID 60 Vs RAID 50 Analise De Risco E Performance Em Storage

O alerta no dashboard sinaliza a morte de um disco de 18TB, mas o verdadeiro crime ocorre durante a recuperação. Ao iniciar o *rebuild*, você submete o restante...
RAID 60 Vs RAID 50 Analise De Risco E Performance Em Storage
1. O Cenário: A Crise do Tempo de Rebuild
O alerta no dashboard sinaliza a morte de um disco de 18TB, mas o verdadeiro crime ocorre durante a recuperação. Ao iniciar o rebuild, você submete o restante do array a uma carga de trabalho brutal e contínua para recalcular a paridade. O sistema não apenas sofre com a latência operacional; ele entra em uma zona de perigo prolongada onde a matemática joga contra a integridade dos dados. A velocidade de gravação dos discos mecânicos não acompanhou o crescimento da capacidade, transformando a reconstrução em uma maratona de dias, não horas.
A raiz do problema é a "janela de vulnerabilidade". Ler dezenas de terabytes sob estresse aumenta drasticamente a probabilidade estatística de encontrar um Unrecoverable Read Error (URE) em um segundo disco saudável. Em configurações com paridade simples, como o RAID 50, um único setor defeituoso encontrado durante esse processo não é apenas um erro de leitura; é o ponto de ruptura que colapsa todo o sub-array e corrompe o volume.
O dilema forense aqui é claro: o risco de perda de dados não reside na falha inicial, mas na incapacidade do sistema de se curar rápido o suficiente antes que uma falha secundária ocorra. Com discos de alta densidade, a redundância simples tornou-se uma aposta de alto risco, exigindo uma análise fria sobre se a performance extra do RAID 50 justifica a exposição a um evento catastrófico durante o rebuild.
2. Anatomia Forense: Estrutura e Falhas
Examinamos a arquitetura aninhada e identificamos a vulnerabilidade crítica localizada nos sub-arrays. O RAID 50 executa o striping sobre múltiplos grupos RAID 5, o que limita a tolerância a falhas a estritamente um disco por sub-grupo; a perda de uma segunda unidade na mesma extensão corrompe irreversivelmente todo o volume lógico. Em contrapartida, o RAID 60 implementa paridade dupla distribuída dentro de cada span, permitindo que o sistema suporte até duas falhas mecânicas simultâneas por sub-array sem comprometer a integridade da evidência digital.
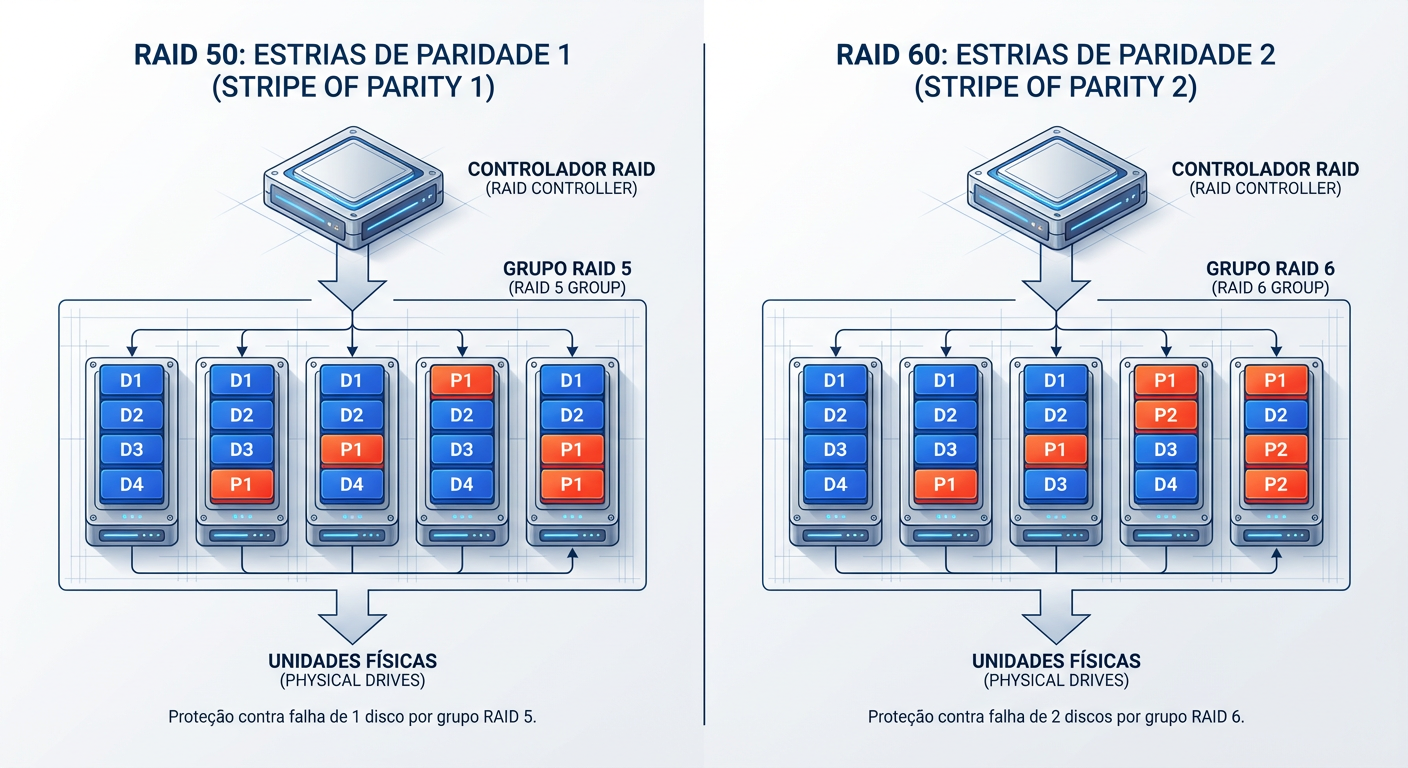
A causa raiz da perda de dados manifesta-se durante o estresse intensivo da reconstrução (rebuild). Ao regenerar um disco no RAID 50, o controlador lê obrigatoriamente todos os setores restantes; um único Erro de Leitura Irrecuperável (URE) ou uma falha secundária durante este ciclo resulta em destruição fatal do array. O RAID 60 neutraliza esse vetor de risco através do segundo bloco de paridade, que atua como um fail-safe aritmético. Matematicamente, à medida que a capacidade dos discos aumenta, a probabilidade estatística de colapso no RAID 50 aproxima-se da certeza, enquanto o RAID 60 reduz essa superfície de ataque exponencialmente.
3. Confronto de Métricas: Write Penalty vs. Segurança
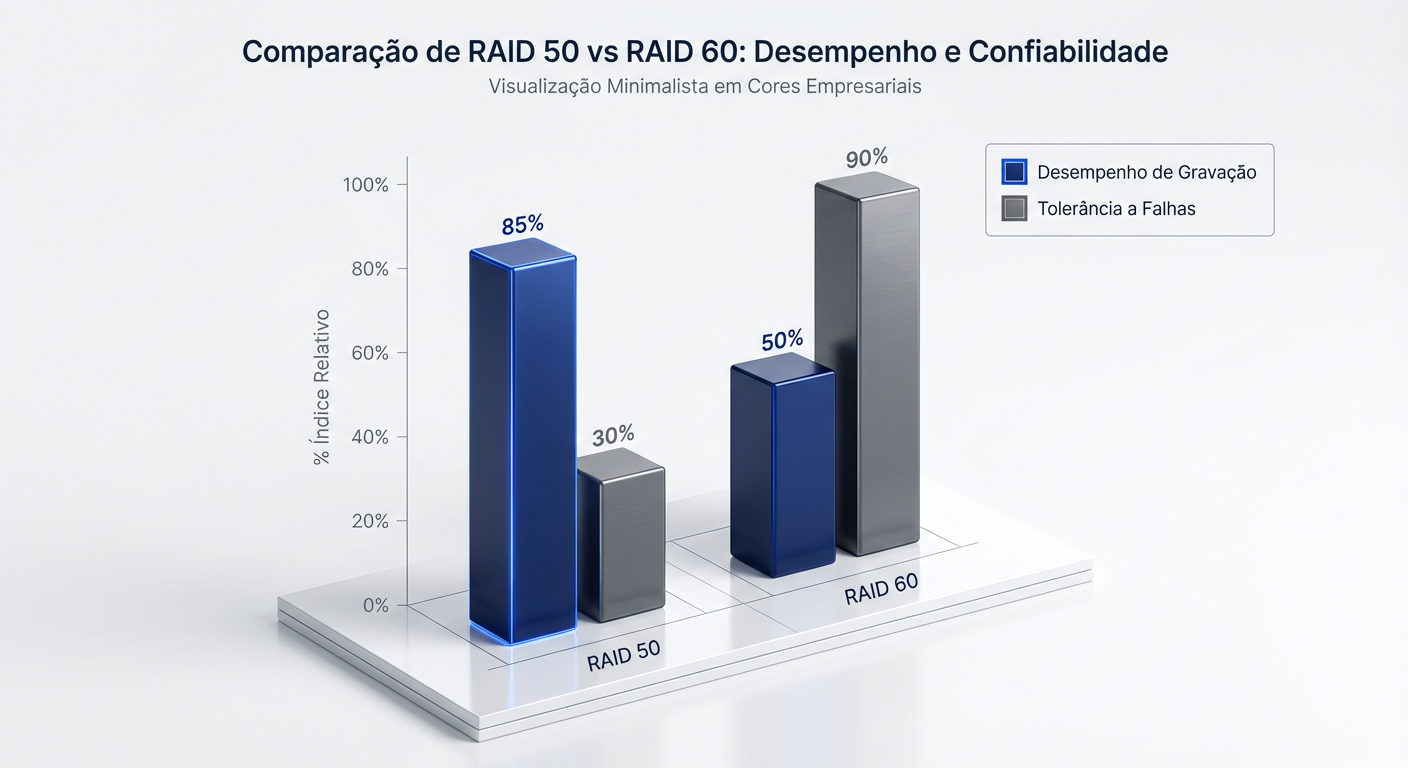
Identificamos o gargalo imediato nas operações de escrita aleatória: o "Write Penalty". No RAID 50, o controlador executa obrigatoriamente 4 operações de I/O (leitura de dados antigos/paridade, escrita de novos dados/paridade) para cada solicitação de gravação. O RAID 60 agrava severamente esse cenário, exigindo 6 operações (2 leituras e 4 escritas) para calcular e gravar a paridade dupla. Esse aumento de 50% na carga de trabalho do backend estrangula diretamente os IOPS efetivos, tornando o RAID 60 mensuravelmente mais lento em ingestão de dados.
A análise da eficiência de armazenamento expõe o custo estrutural dessa blindagem. Enquanto o RAID 50 consome apenas um disco por sub-grupo (span) para paridade, o RAID 60 exige dois, reduzindo drasticamente a capacidade útil total do array. Você sacrifica performance bruta e espaço de armazenamento no RAID 60 para eliminar a causa raiz de falhas catastróficas: a perda simultânea de um segundo disco no mesmo sub-grupo, um evento fatal para o RAID 50 que o RAID 60 neutraliza operacionalmente.
O sintoma inicial é a latência de escrita estrangulando bancos de dados transacionais e datastores de VMs. A causa raiz reside na sobrecarga excessiva do cálculo de paridade dupla em arquiteturas densas. Para mitigar esse gargalo, implemente RAID 50. Sua estrutura de striping aninhado reduz drasticamente a penalidade de escrita, entregando os IOPS necessários para sustentar cargas de trabalho intensivas sem sacrificar a redundância básica.
Por outro lado, em arrays com mais de 12 discos de alta capacidade, o sintoma crítico muda para o risco estatístico de falha secundária durante reconstruções prolongadas. A causa raiz aqui é a exposição temporal a erros de leitura irrecuperáveis (URE) enquanto o array está degradado. Para estes cenários, especificamente Cold Storage e backups imutáveis, adote RAID 60. A paridade dupla distribuída blinda o sistema contra a perda catastrófica de dados durante o rebuild, priorizando a integridade absoluta sobre a velocidade bruta.

Elena Kovacs
Arquiteta de Cloud Infrastructure
Focada em NVMe-oF e storage definido por software. Projeta clusters de petabytes para grandes provedores de nuvem.