RAID 60 Vs RAID 50 Quando A Complexidade Vale A Pena

Para entender por que o RAID 50 está se tornando obsoleto para *bulk storage*, precisamos primeiro alinhar nosso modelo mental sobre o que "Nested RAID" (RAID A...
RAID 60 Vs RAID 50 Quando A Complexidade Vale A Pena
A Anatomia do Aninhamento (Nested RAID)
Para entender por que o RAID 50 está se tornando obsoleto para bulk storage, precisamos primeiro alinhar nosso modelo mental sobre o que "Nested RAID" (RAID Aninhado) realmente faz.
Esqueça a ideia de um "pool gigante de discos". O RAID 50 e 60 não são monolitos. Eles são federações de arrays menores.
Imagine que você tem 24 discos.
- No RAID 50 (com 3 spans): Você tem três arrays RAID 5 independentes (8 discos cada). O controlador então faz um Stripe (RAID 0) por cima desses três arrays.
- No RAID 60 (com 3 spans): Você tem três arrays RAID 6 independentes. O Stripe (RAID 0) conecta os três.
A mágica — e o perigo — está na palavra "independente". O RAID 0 no topo é apenas um distribuidor de tráfego. Ele não oferece redundância. A proteção de dados vive inteiramente no nível inferior (os Sub-arrays ou "Spans").
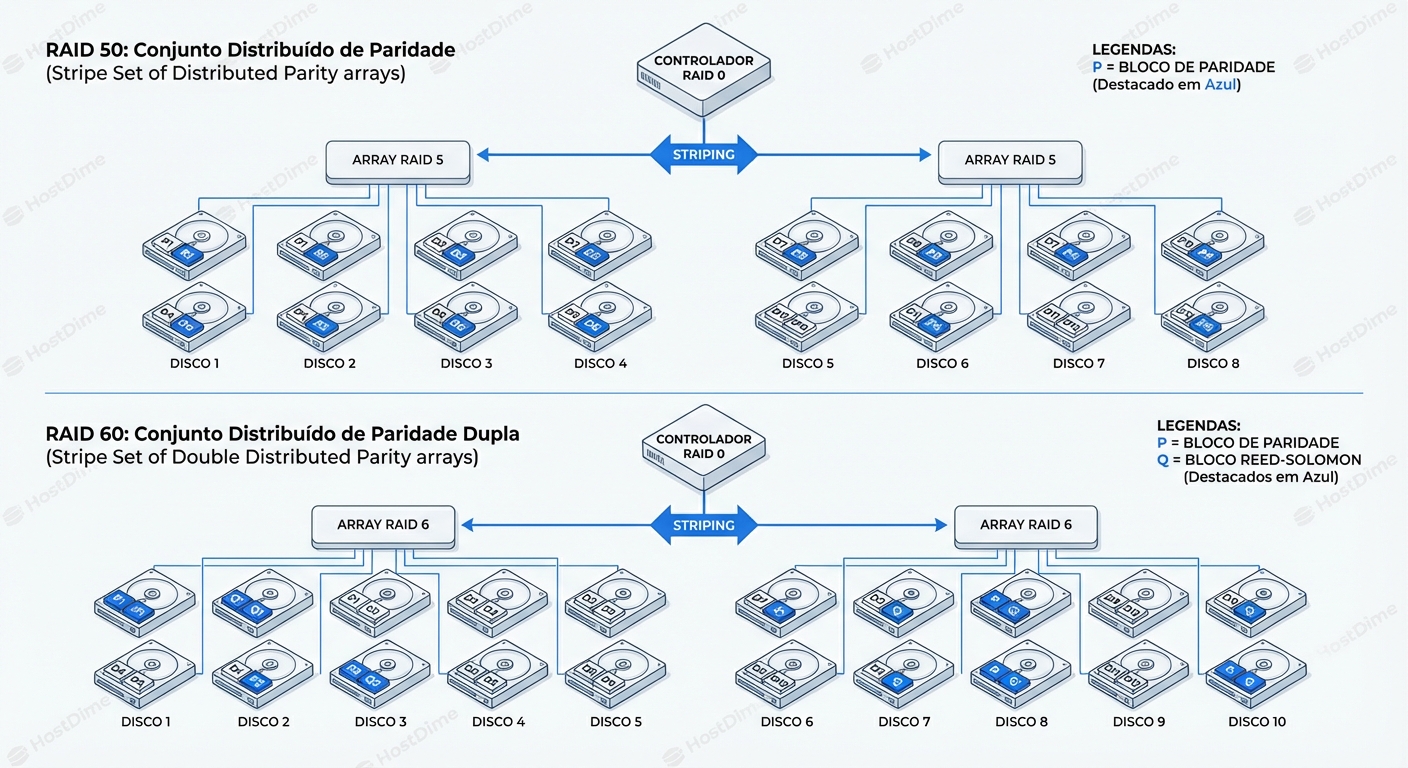
Se um Span falha, o RAID 0 quebra. Se o RAID 0 quebra, o volume lógico desaparece.
Portanto, quando falamos de falha, não estamos perguntando "quantos discos o array total aguenta perder?". Estamos perguntando: "Qual a probabilidade de um único span colapsar?".
No RAID 50, um span colapsa se perder 2 discos. No RAID 60, um span colapsa se perder 3 discos.
Parece uma diferença pequena — apenas um disco a mais — mas quando aplicamos a matemática das probabilidades em discos de 20TB, essa diferença é exponencial.
O Assassino Silencioso: URE e a Matemática do Rebuild
Aqui é onde a intuição falha e a matemática assume.
Antigamente, quando tínhamos discos de 300GB SAS 15k, um rebuild levava talvez uma ou duas horas. A janela de vulnerabilidade (o tempo em que o array está degradado e sem proteção) era minúscula.
Hoje, temos discos Nearline-SAS ou SATA de 20TB ou 24TB. A velocidade física de leitura/escrita desses discos (throughput sequencial) não acompanhou o crescimento da capacidade. Um disco de 20TB ainda lê a cerca de 250-280 MB/s nas bordas externas, e cai para 120 MB/s nas internas.
O Cálculo do Medo:
Para reconstruir um disco de 20TB cheio, você precisa ler e escrever 20TB de dados.
A uma média otimista de 200MB/s (sem considerar a carga de produção concorrente), isso leva:
20,000,000 MB / 200 MB/s = 100,000 segundos ≈ 27.7 horas.
Isso é o cenário perfeito. Na vida real, com o servidor servindo arquivos, banco de dados ou VMs, esse rebuild pode levar dias ou até uma semana.
Durante esses dias, no RAID 50, seu span afetado está rodando como um RAID 0. Zero redundância. Se qualquer outro disco nesse mesmo span falhar, acabou.
Mas há algo pior que uma falha total do disco: o URE (Unrecoverable Read Error).
A Falácia do Bit Perfeito
Discos rígidos têm uma especificação chamada "Non-recoverable Read Error rate".
- Discos Enterprise (SAS/SATA): Geralmente 1 setor a cada $10^{15}$ bits lidos.
- Discos Consumer/NAS (SATA): Geralmente 1 setor a cada $10^{14}$ bits lidos.
Vamos fazer a conta para discos SATA comuns em storage de backup ($10^{14}$): 20TB é aproximadamente $1.6 \times 10^{14}$ bits.
Estatisticamente, ao ler 20TB de dados para reconstruir o array, você tem uma chance maior que 100% de encontrar um erro de leitura irrecuperável se a taxa do fabricante for exata (e muitas vezes é pior com o envelhecimento do drive).
O Cenário de Pesadelo no RAID 50:
- Disco A falha.
- Controladora inicia o rebuild usando a paridade.
- Para reconstruir o bloco X do Disco A, a controladora precisa ler o bloco X de todos os outros discos do span.
- No meio do processo, o Disco B encontra um URE (bad block).
- A controladora tenta ler. Falha.
- Como é RAID 5 (dentro do span), não há outra paridade para calcular o dado perdido.
- Resultado: O processo de rebuild falha (o array desmonta) OU o dado é corrompido silenciosamente e o rebuild continua, entregando lixo para o sistema de arquivos.
No RAID 60, esse cenário é um "não-evento".
- Disco A falha.
- Rebuild inicia.
- Disco B encontra um URE.
- A controladora diz: "Sem problemas, tenho a paridade Q (Dual Parity). Vou usar os outros discos + Paridade Q para reconstruir o dado, ignorando o erro do Disco B".
- O rebuild continua. Você dorme tranquilo.
Trade-offs de Performance: O Custo da Paridade Dupla
Se o RAID 60 é tão mais seguro, por que alguém ainda usa RAID 50? A resposta curta: Write Penalty (Penalidade de Escrita).
Para ler dados, RAID 50 e 60 são muito similares (ambos leem de N discos). O problema é a escrita aleatória (Random Write).
Sempre que você modifica um bloco em um RAID com paridade, o controlador deve:
- Ler o dado antigo.
- Ler a paridade antiga.
- Calcular a nova paridade.
- Escrever o novo dado.
- Escrever a nova paridade.
Isso é o ciclo Read-Modify-Write.
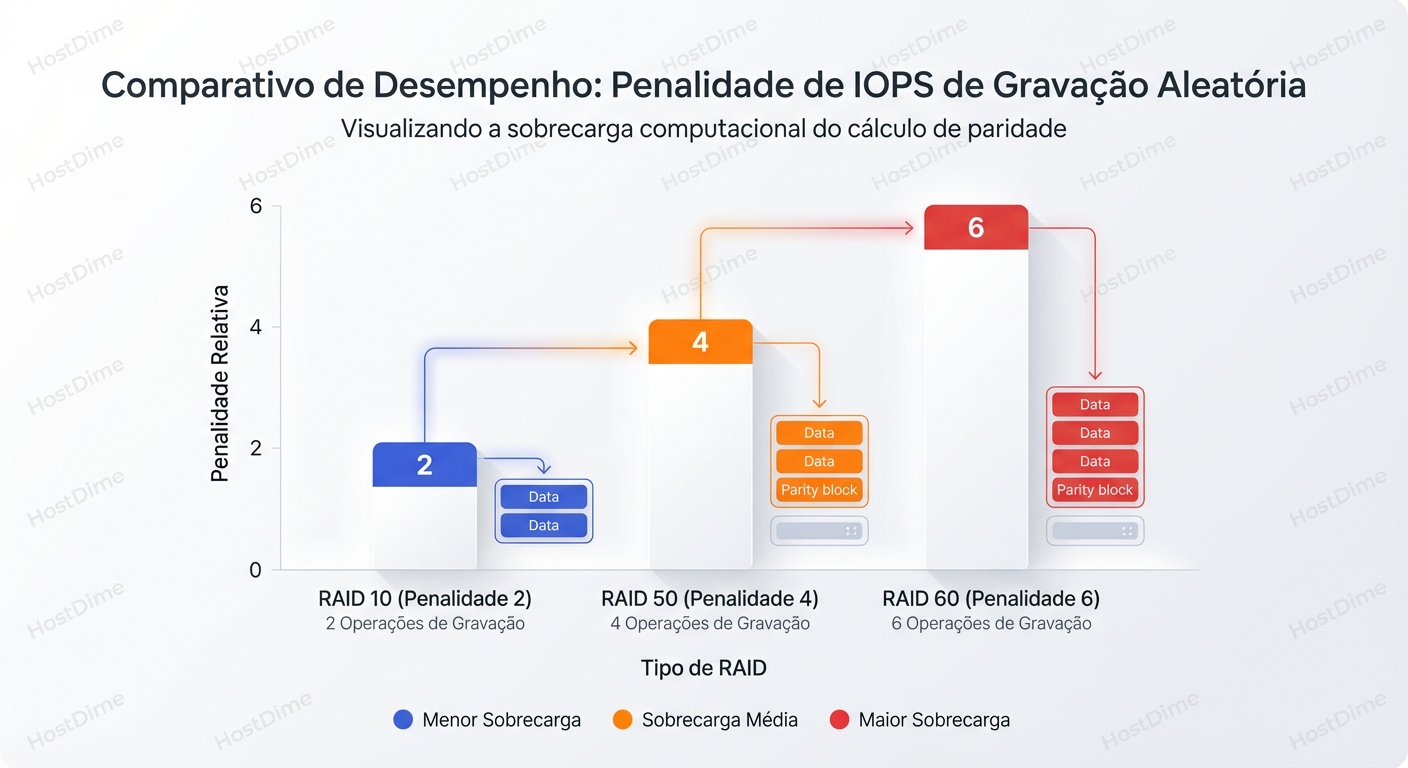
A Matemática dos IOPS:
| Tipo de RAID | Operações de I/O por Escrita Lógica | Custo Computacional |
|---|---|---|
| RAID 50 | 4 I/Os (2 Leituras + 2 Escritas) | Baixo (XOR simples) |
| RAID 60 | 6 I/Os (3 Leituras + 3 Escritas) | Médio (XOR + Reed-Solomon/Galois Field) |
No RAID 60, para cada bit que você escreve, o backend sofre 50% mais carga de IOPS do que no RAID 50.
Onde isso importa:
- Bancos de Dados OLTP: O RAID 60 vai matar sua latência de escrita se você não tiver um cache de escrita robusto (NVRAM/Battery Backed Cache) na controladora.
- VMware/Virtualização: "Storms" de escrita (como boot storms ou atualizações do Windows em massa) vão saturar os discos mecânicos muito mais rápido em RAID 60.
Onde isso NÃO importa:
- Backup Repositories (Veeam, Commvault): Geralmente são escritas sequenciais grandes. O cache da controladora absorve e lineariza isso. RAID 60 é perfeitamente aceitável aqui.
- File Servers / Archives: A proporção de leitura/escrita é geralmente 80/20 ou 90/10. O impacto na escrita é diluído.
Diagnóstico e Observabilidade: Olhando Sob o Capô
Como administradores, não confiamos em "luzes verdes". Precisamos ver os contadores de erro antes que eles virem falhas.
A ferramenta que você usa depende do seu hardware, mas a lógica é a mesma: procurar por Media Errors e Predictive Failures.
Cenário 1: Linux Software RAID (mdadm)
Muitos ambientes modernos de SDS (Software Defined Storage) usam o md do Linux.
Para ver a estrutura real e a saúde:
mdadm --detail /dev/md0
# O que procurar na saída:
# "State : clean" ou "active" -> Bom.
# "State : clean, degraded" -> PERIGO. Rebuild necessário.
# "Active Devices" vs "Working Devices" -> Devem ser iguais.
Durante um rebuild, o /proc/mdstat é sua janela para a alma do sistema:
watch -n 1 cat /proc/mdstat
Interpretação:
Olhe para a linha [UUU_U]. O _ indica o disco falho.
Olhe para a velocidade: speed=140000K/sec. Se isso cair abaixo de 50MB/s em discos modernos, seu rebuild vai levar uma eternidade. Isso geralmente indica que os discos restantes estão sobrecarregados com I/O de produção.
Cenário 2: Hardware RAID (Broadcom/LSI/Avago)
Usando storcli (o padrão da indústria para controladoras MegaRAID).
# Listar todos os discos e procurar erros
storcli /c0 /eall /sall show all | grep -iE "Media Error|Predictive Failure"
Sinais de Perigo:
- Media Error Count > 0: O disco já encontrou setores ruins e teve que remapeá-los ou usar paridade para recuperar. Em um RAID 50, se você ver contagens de erro de mídia crescendo em múltiplos discos do mesmo span, você está sentado em uma bomba relógio. Migre os dados. Agora.
- Predictive Failure Count > 0: O limiar S.M.A.R.T. foi atingido. O disco é um zumbi. Troque-o preventivamente.
O Salvador: Patrol Read (Scrubbing)
Tanto no Linux (echo check > /sys/block/md0/md/sync_action) quanto em Hardware RAID, existe o conceito de Patrol Read ou Data Scrubbing.
Isso força a controladora a ler todos os setores do disco periodicamente e verificar a consistência da paridade.
- Por que é vital no RAID 50: Ele encontra os UREs (bad blocks) enquanto o array está saudável. Ele corrige o setor ruim usando a paridade e reescreve o dado em um setor bom (remapeamento).
- Se você não rodar Patrol Read, o URE ficará latente ("bit rot"). Você só vai descobri-lo quando o Disco A falhar e você tentar ler o Disco B para o rebuild. Aí será tarde demais.
Comando para verificar status do Patrol Read (LSI):
storcli /c0 show patrolread
Se estiver "Disable", ative imediatamente. Configure para rodar a cada 7 dias ou continuamente em baixa prioridade.
Tabela de Decisão: O Veredito Prático
Não existe "melhor", existe "menos pior" para o seu cenário.
| Característica | RAID 50 | RAID 60 |
|---|---|---|
| Capacidade Utilizável | Alta (N - 1 por span) | Média (N - 2 por span) |
| Tolerância a Falhas | 1 disco por span. (2º disco no mesmo span = Perda de Dados) | 2 discos por span. (3º disco no mesmo span = Perda de Dados) |
| Performance de Leitura | Excelente | Excelente |
| Performance de Escrita | Boa (Penalty 4x) | Ruim (Penalty 6x) |
| Rebuild Stress | Crítico. Risco alto de URE secundário. | Gerenciável. Tolera UREs durante rebuild. |
| Caso de Uso Ideal | SSDs (rebuild rápido), Dados temporários, Caches, Streaming de Mídia (Write Once, Read Many). | Backup, Arquivamento, Virtualização em HDDs grandes, Qualquer array com discos > 8TB. |
O Veredito do Arquiteto: A Morte do RAID 50 em HDDs Grandes
Se você está desenhando uma solução hoje com discos mecânicos (HDDs) maiores que 8TB, o RAID 50 é uma negligência arquitetural.
O ganho de espaço (um disco a mais por span) e o ganho de IOPS de escrita não justificam o risco de perda total de dados durante um rebuild que pode durar dias. A probabilidade de um URE ou de uma falha mecânica secundária devido ao estresse térmico e mecânico do rebuild é simplesmente alta demais.
Minha regra de ouro:
- All-Flash Arrays (SSD/NVMe): RAID 50 é aceitável. O rebuild é rápido (minutos/horas) e SSDs não sofrem de UREs da mesma forma mecânica que HDDs. A latência de escrita menor do RAID 50 ajuda a extrair performance do Flash.
- HDDs Grandes (>8TB): RAID 60 é obrigatório. Ponto final. Se você precisa de mais IOPS do que o RAID 60 pode dar em HDDs, você não deveria estar usando RAID 50; você deveria estar usando RAID 10 ou adicionando uma camada de Flash.
Não tente lutar contra a matemática dos discos giratórios. Eles são lentos, eles falham, e quando são grandes, eles são hostis à recuperação. Use o RAID 60 como seu seguro de vida, ou esteja preparado para explicar ao CTO por que a restauração do backup de fitas (se existir) vai levar duas semanas.
Para Onde Ir Daqui?
O hardware RAID clássico está morrendo. O futuro (e o presente) é o armazenamento definido por software (SDS) como Ceph, ZFS ou vSAN.
- ZFS (RAID-Z2 / RAID-Z3): O ZFS entende a geometria dos dados e checksums. Ele não sofre do "Write Hole" do RAID tradicional e pode curar corrupção silenciosa on-the-fly.
- Erasure Coding (Ceph): Permite definir níveis de proteção muito mais granulares (ex: 4+2, 8+3) que superam as limitações rígidas do RAID 60.
Mas enquanto tivermos controladoras PERC, MegaRAID e SmartArray em nossos datacenters, entender a fragilidade do RAID 50 em discos densos é uma habilidade de sobrevivência. Verifique seus backups. Verifique seus Patrol Reads. E se puder, adicione aquele segundo disco de paridade.

Alexei Volkov
Ceph Cluster Administrator
Escala clusters Ceph para o infinito. Mestre em CRUSH maps e recuperação de placement groups.