RAID Adaptativo: O Fim da Geometria Estática e o Ajuste Dinâmico de Paridade
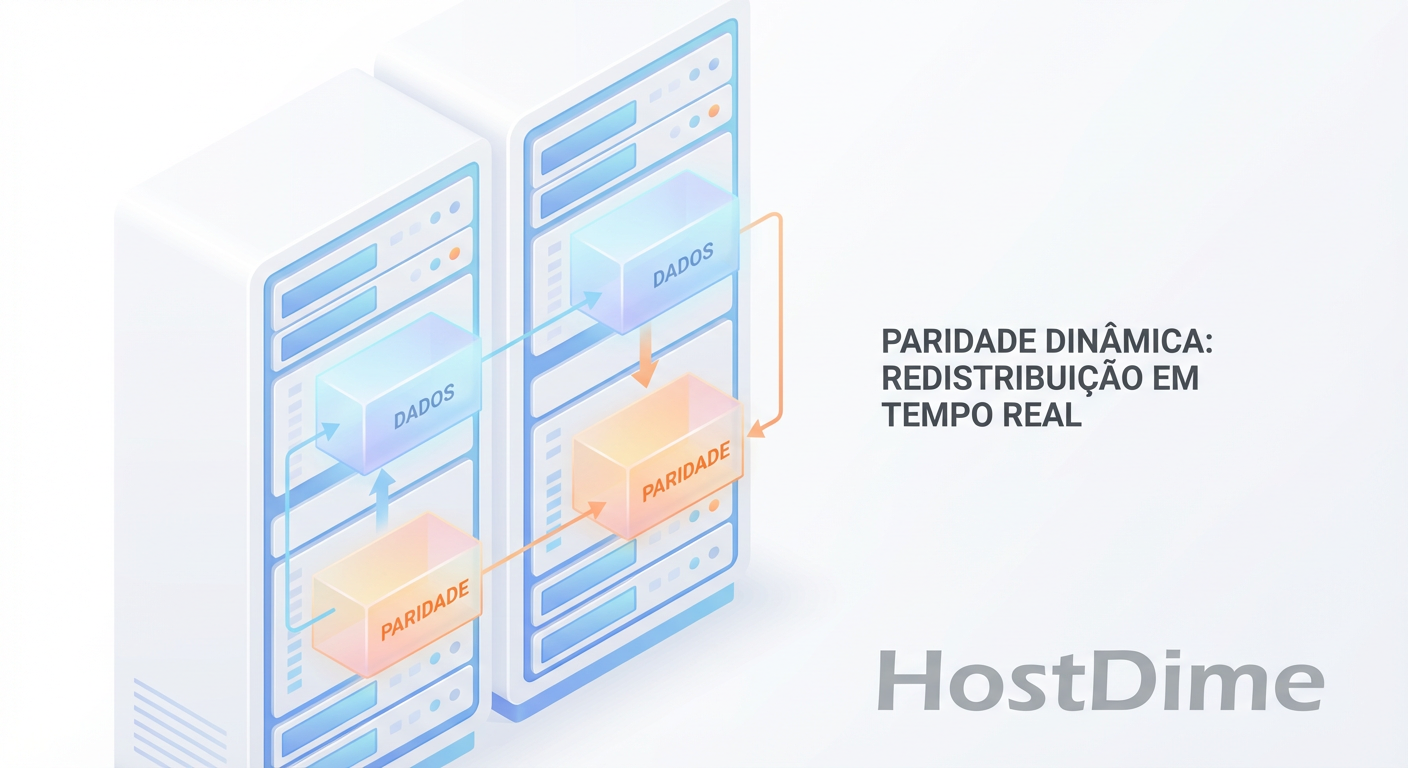
Esqueça o RAID 5 ou 6 fixo. Entenda como algoritmos de RAID Adaptativo e Erasure Coding ajustam a paridade em tempo real para equilibrar performance e proteção.
O RAID tradicional, como o conhecemos (níveis 5, 6, 50, 60), é um artefato de uma era onde o hardware era o gargalo e a lógica de controle precisava ser simples. Você definia um grupo de discos, estabelecia um stripe size fixo e rezava para que sua carga de trabalho se alinhasse perfeitamente com essa geometria. Se não alinhasse, você pagava o preço: a temida penalidade de escrita (Write Penalty).
No cenário atual de Enterprise Storage, onde SSDs NVMe saturam barramentos e discos mecânicos atingem capacidades de 20TB+, a rigidez da geometria fixa tornou-se um passivo operacional e financeiro. O conceito de "RAID Adaptativo" ou paridade dinâmica surge não como uma nova "feature", mas como uma necessidade arquitetural para lidar com a imprevisibilidade dos dados modernos.
O que é RAID Adaptativo?
O RAID Adaptativo é uma arquitetura de armazenamento que desacopla o layout lógico dos dados da geometria física dos discos. Em vez de gravar em larguras de faixa fixas (ex: 4 dados + 1 paridade), o sistema ajusta dinamicamente a proteção (Erasure Coding) e o tamanho do bloco com base no fluxo de entrada, geralmente utilizando técnicas de Log-Structuring para converter escritas aleatórias em sequenciais antes de calcular a paridade.
Por que a Geometria Fixa do RAID Tradicional Falha
Para entender o valor do adaptativo, precisamos dissecar a falha do modelo estático. Em um RAID 6 tradicional (digamos, 8 discos de dados + 2 de paridade), a geometria espera que você escreva dados suficientes para preencher uma faixa inteira (Full Stripe Write).
Se a sua aplicação — um banco de dados transacional ou uma VM — envia uma escrita pequena (4KB) para esse array, o controlador é forçado a realizar o ciclo Read-Modify-Write:
Ler os dados antigos.
Ler a paridade antiga.
Calcular a diferença.
Escrever os novos dados.
Escrever a nova paridade.
Isso transforma 1 IOPS de escrita lógica em 4 a 6 IOPS físicos nos discos. É o assassino silencioso de performance. Além disso, a reconstrução (rebuild) em geometrias fixas é limitada pela velocidade de um único disco, tornando arrays de alta capacidade perigosamente lentos para recuperar redundância.
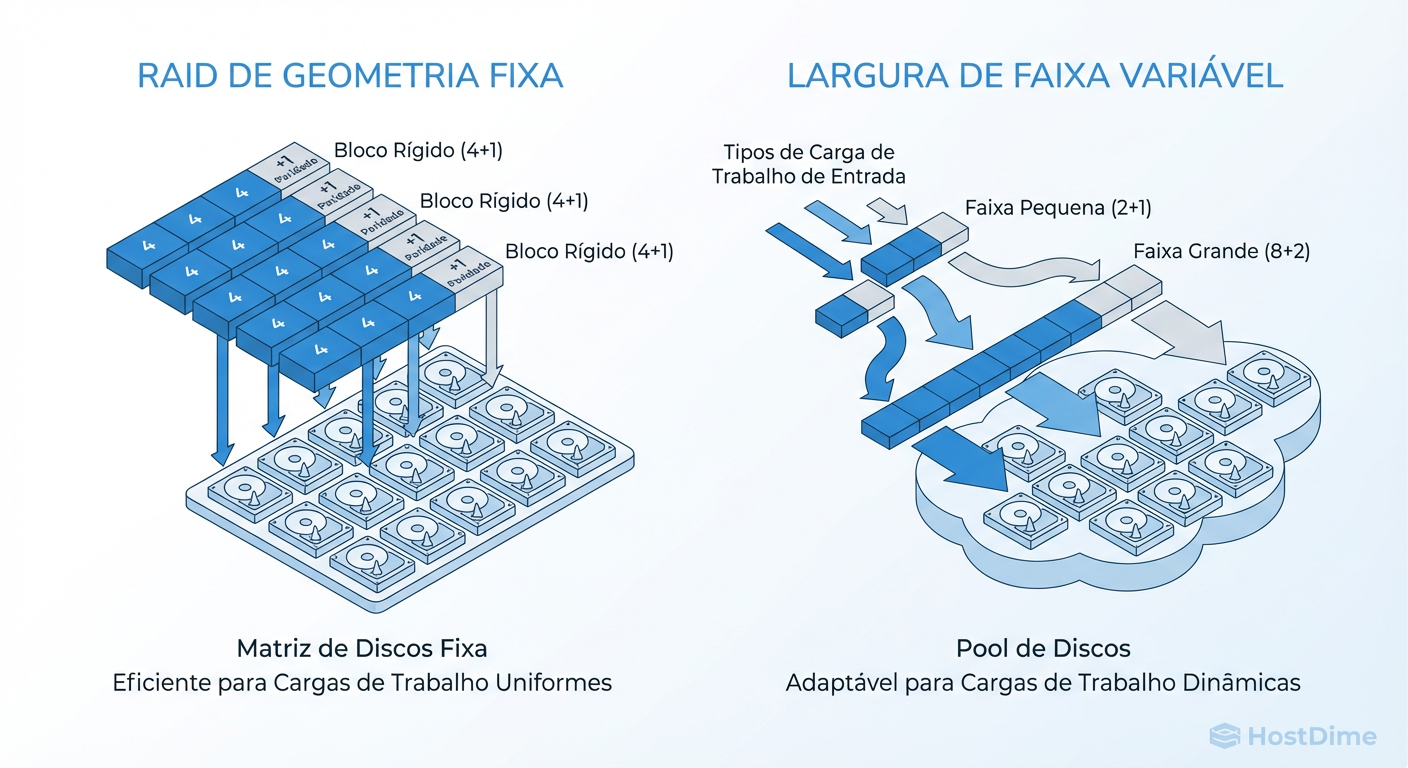 Figura: Comparativo visual: A rigidez do RAID tradicional versus a fluidez da largura de faixa variável no RAID Adaptativo.
Figura: Comparativo visual: A rigidez do RAID tradicional versus a fluidez da largura de faixa variável no RAID Adaptativo.
Anatomia do RAID Adaptativo e Erasure Coding
O RAID Adaptativo abandona a ideia de que "o disco 3 é sempre o terceiro bloco da sequência". Em vez disso, ele trata o pool de discos como um balde de blocos endereçáveis.
A mágica acontece através do Erasure Coding (EC) Variável. Diferente do RAID, onde a largura é fixa pelo grupo de discos, sistemas adaptativos (como implementações avançadas de Ceph, vSAN ou arrays proprietários como Pure Storage/Nimble) podem decidir a largura da proteção em tempo de voo.
Como funciona na prática:
Se o sistema recebe um fluxo massivo de dados sequenciais, ele pode criar uma faixa larga (ex: 16 dados + 2 paridade) para maximizar a eficiência de espaço (menos overhead de paridade). Se ele recebe dados pequenos e aleatórios que não podem ser coalescidos, ele pode optar por um espelhamento temporário (RAID 1) ou uma faixa estreita (2+1) e, posteriormente, reescrever esses dados em uma faixa larga eficiente em um processo de Garbage Collection em segundo plano.
Ponto de Atenção: Isso muda o cálculo de TCO. Você não compra mais discos para "fechar o RAID 10". Você compra capacidade bruta e CPU para gerenciar a complexidade matemática.
Como Log-Structured Writes Eliminam a Write Penalty
A peça fundamental para que a paridade dinâmica funcione sem destruir a latência é a transformação do padrão de I/O. Não adianta ter geometria flexível se você ainda precisa ler antes de escrever.
Aqui entra o conceito de Log-Structured Filesystems (ou Copy-on-Write em implementações como ZFS).
O sistema não sobrescreve dados no lugar (in-place). Ele acumula escritas aleatórias em um buffer de memória (NVRAM ou RAM protegida por bateria), organiza essas escritas em uma longa faixa sequencial perfeita e só então calcula a paridade e descarrega para os discos.
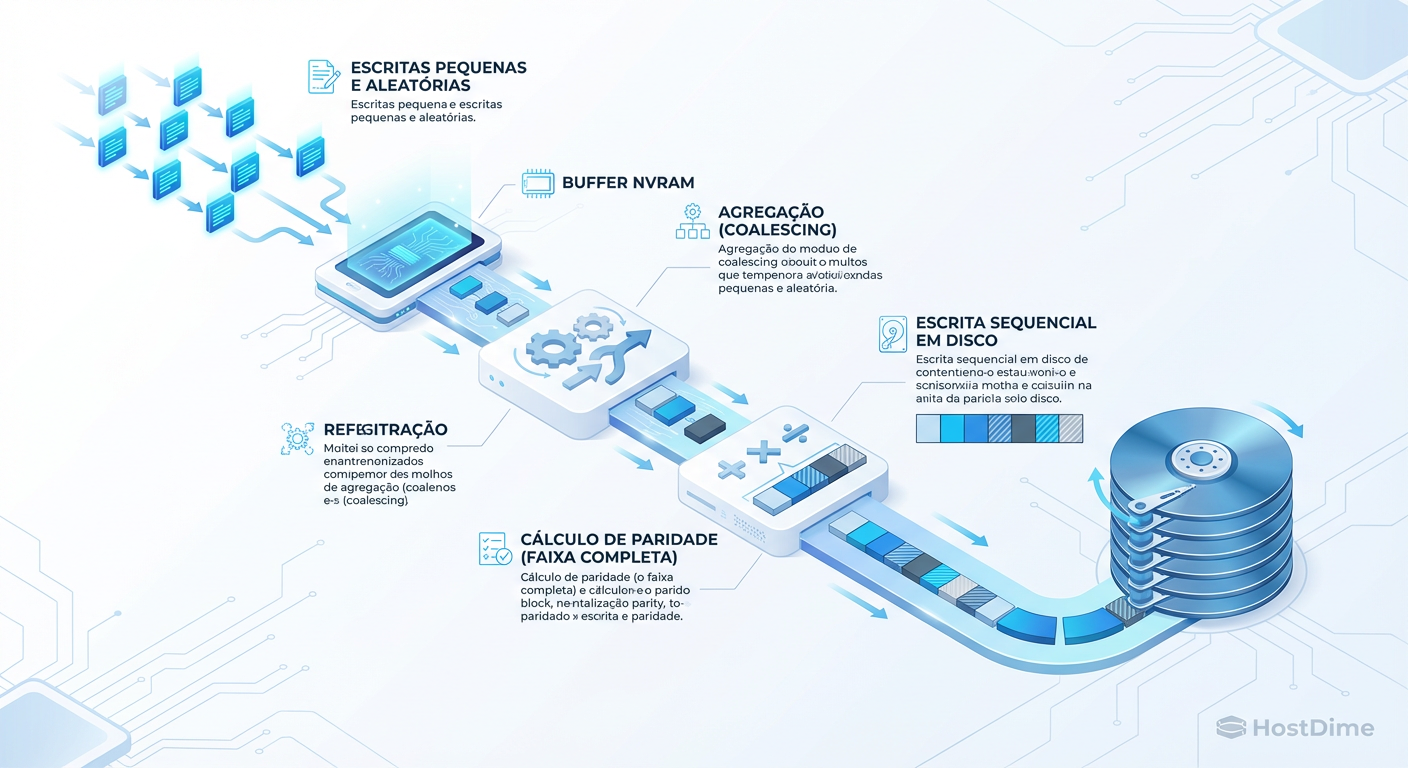 Figura: O fluxo de escrita Log-Structured: O segredo para evitar a penalidade de escrita (Write Penalty) em paridade dinâmica.
Figura: O fluxo de escrita Log-Structured: O segredo para evitar a penalidade de escrita (Write Penalty) em paridade dinâmica.
Ao transformar escritas aleatórias em sequenciais:
Eliminamos a leitura prévia (Read-Modify-Write desaparece).
A paridade é calculada sobre o buffer inteiro, sempre como um Full Stripe Write.
O disco físico, mesmo se for HDD, opera em seu modo mais eficiente (sequencial).
Custo Computacional da Paridade Dinâmica: CPU vs Latência
Como arquiteto, você deve ser cético: "Não existe almoço grátis". Se ganhamos flexibilidade e eficiência de espaço, o que estamos pagando?
A moeda de troca é Ciclo de CPU e Latência de Commit.
Calcular Erasure Coding (álgebra de Reed-Solomon ou similar) para geometrias variáveis exige muito mais do processador do storage do que um XOR simples de RAID 5.
O Trade-off: Em sistemas mal dimensionados, a CPU do storage controller torna-se o gargalo antes dos discos.
Latência: Embora o throughput aumente (pela serialização das escritas), a latência da primeira confirmação de escrita pode oscilar dependendo da carga da CPU e do preenchimento do buffer.
O que medir: Ao avaliar essas soluções, não olhe apenas para IOPS. Monitore o CPU Wait do controlador de storage durante picos de escrita e a latência de cauda (P99). Se a CPU colar em 90%, sua latência vai explodir, não importa quão rápidos sejam os SSDs.
Implementações de RAID Adaptativo: ZFS dRAID, Ceph e Proprietários
Nem todo "RAID Software" é adaptativo da mesma forma. Vamos analisar três abordagens de mercado.
1. ZFS dRAID (Declustered RAID)
O ZFS tradicional (RAID-Z) já resolvia o problema do "Write Hole" com escritas transacionais, mas sofria com rebuilds lentos e geometria fixa por VDEV. O dRAID (recurso mais recente do OpenZFS) introduz a paridade declusterizada.
O ganho: Ele espalha a paridade e os spares (discos de reserva) logicamente por todos os discos do pool.
O resultado: Quando um disco falha, todos os discos restantes participam da reconstrução, reduzindo o tempo de rebuild de dias para horas.
2. Ceph (Erasure Coding Pools)
O Ceph leva a abstração ao extremo com o algoritmo CRUSH. Não há "discos" no sentido de RAID, apenas OSDs (Object Storage Daemons).
Flexibilidade: Você define perfis de EC (ex: k=4, m=2) por pool de dados.
O Custo: O overhead de software do Ceph é alto. Ele exige muita CPU e rede de baixa latência para coordenar a paridade distribuída.
3. Arrays Proprietários (Pure, NetApp, HPE Nimble)
Muitos All-Flash Arrays modernos não usam RAID padrão internamente. Eles usam variações proprietárias de RAID 3D ou paridade dinâmica.
- Vantagem: O hardware (FPGA/ASIC) é desenhado para descarregar o cálculo da paridade, mitigando o custo de CPU mencionado anteriormente.
Tabela Comparativa: RAID Tradicional vs. Adaptativo
| Característica | RAID Tradicional (5/6) | ZFS RAID-Z / dRAID | Adaptativo Puro / Log-Structured |
|---|---|---|---|
| Write Penalty | Severa em Random I/O (4x-6x) | Inexistente (CoW), mas fragmenta | Inexistente (Log-Write) |
| Rebuild | Lento (Gargalo em 1 disco) | dRAID: Muito Rápido (N-discos) | Rápido (Apenas dados usados) |
| Expansão | Dolorosa (Reshape do array) | Adição de VDEVs (ainda rígido) | Fluida (Adiciona nós/discos) |
| Custo CPU | Baixo (XOR simples) | Médio (Checksums + Paridade) | Alto (Metadata complexo + EC) |
| Uso Ideal | Boot, Local Scratch | File Server, Backup, Virtualização | Cloud, Block Storage Geral |
Checklist de Decisão: Quando Migrar para RAID Adaptativo
Como Arquiteto, a resposta padrão é "Depende". Mas depende do quê? Use este checklist para decidir se abandona o RAID 10 ou 6 em favor de abordagens dinâmicas.
Sua carga de trabalho é "Write-Heavy" e aleatória?
- Sim: O RAID Adaptativo/Log-Structured vai economizar seus discos e aumentar performance. O RAID 5/6 tradicional vai sufocar.
Você precisa de eficiência de espaço acima de 80%?
- Sim: RAID 10 é inviável (50% de perda). Você precisa de Erasure Coding dinâmico para manter alta proteção com baixo overhead.
Qual é o seu orçamento de CPU/Controladora?
- Baixo: Cuidado. Soluções adaptativas em hardware fraco (ex: NAS de entrada com ZFS e Deduplicação ligada) vão travar. Prefira RAID 10 estático.
- Alto: O custo da CPU compensa a economia em discos e a agilidade operacional.
O tempo de Rebuild é crítico para o SLA?
- Sim: Discos de 18TB+ em RAID 6 tradicional são um risco de perda de dados (URE durante rebuild). Use dRAID ou Erasure Coding distribuído.
Exemplo Prático de Configuração (Conceitual)
Se você estivesse configurando um pool ZFS para usar dRAID (OpenZFS 2.1+), o comando refletiria a lógica de declusterização, onde definimos o número de discos de dados, paridade e spares virtuais dentro do comando de criação:
# Exemplo conceitual de criação de dRAID
# draid2: paridade dupla (semelhante a RAID6)
# 4d: 4 discos de dados por stripe lógico
# 11c: 11 'children' (discos físicos totais)
# 1s: 1 spare distribuído virtual
zpool create tank draid2:4d:11c:1s /dev/disk/by-id/wwn-0x500...[1-11]
Nota: Este comando cria uma topologia onde a capacidade de um disco é reservada como "spare", mas distribuída por todos os 11 discos para maximizar a velocidade de escrita do rebuild.
Referências & Leitura Complementar
OpenZFS dRAID Primer: Documentação técnica sobre a implementação matemática de Declustered RAID no ZFS.
"The RAID 6 Write Penalty": Análises clássicas de performance de I/O (ex: SNIA Whitepapers).
NetApp WAFL (Write Anywhere File Layout) Patent: A base histórica para entender Log-Structured Writes em enterprise storage.
Ceph Erasure Coding Profiles: Documentação do Ceph sobre plugins de EC (Jerasure, ISA-L) e trade-offs de performance.

David Ross
Linux Sysadmin Veterano
Vive no terminal. Mantenedor de diversos módulos kernel de storage. Acredita que GUI é bloatware.