RAID com Discos SMR: O Guia de Sobrevivência e Armadilhas (2026)

Evite o desastre no seu storage. Entenda por que discos SMR destroem arrays RAID, a diferença crítica entre DM-SMR e HM-SMR, e como diagnosticar gargalos de escrita antes de perder dados.
Se você está lendo isso em 2026, provavelmente já ouviu o eco do escândalo dos discos SMR de alguns anos atrás. Talvez você tenha encontrado um disco rígido barato de 8TB ou 10TB, colocou em um NAS doméstico ou servidor de arquivos da empresa e tudo parecia bem. Até o dia em que um disco falhou.
No momento em que você substituiu o disco e iniciou a reconstrução (resilver/rebuild), o sistema parou. O tempo estimado de recuperação pulou de 10 horas para 14 dias. O array desmontou. Você perdeu dados. Este artigo não é sobre "boas práticas" de fabricantes que tentam vender densidade a qualquer custo. É sobre física, limites de hardware e como não ser demitido porque seu storage entrou em colapso durante uma reconstrução.
O que é SMR e por que falha em RAID? Shingled Magnetic Recording (SMR) é uma tecnologia que aumenta a densidade sobrepondo trilhas magnéticas como telhas. Em discos gerenciados pelo drive (DM-SMR), qualquer alteração de dados exige ler, modificar e reescrever zonas inteiras (Read-Modify-Write), gerando latências massivas. Em RAID, essas pausas longas são interpretadas como falha do disco, quebrando o array durante reconstruções intensivas.
A Mecânica Física do SMR e o Perigo para RAID
Para entender o risco, precisamos ignorar o marketing e olhar para o prato magnético. Em um disco convencional (CMR - Conventional Magnetic Recording), as trilhas de dados são paralelas e isoladas. Você pode gravar no setor 500 sem incomodar o setor 501.
No SMR, para espremer mais terabytes no mesmo espaço físico, os fabricantes sobrepõem as trilhas. A cabeça de leitura é fina o suficiente para ler a trilha "espremida", mas a cabeça de gravação é larga.
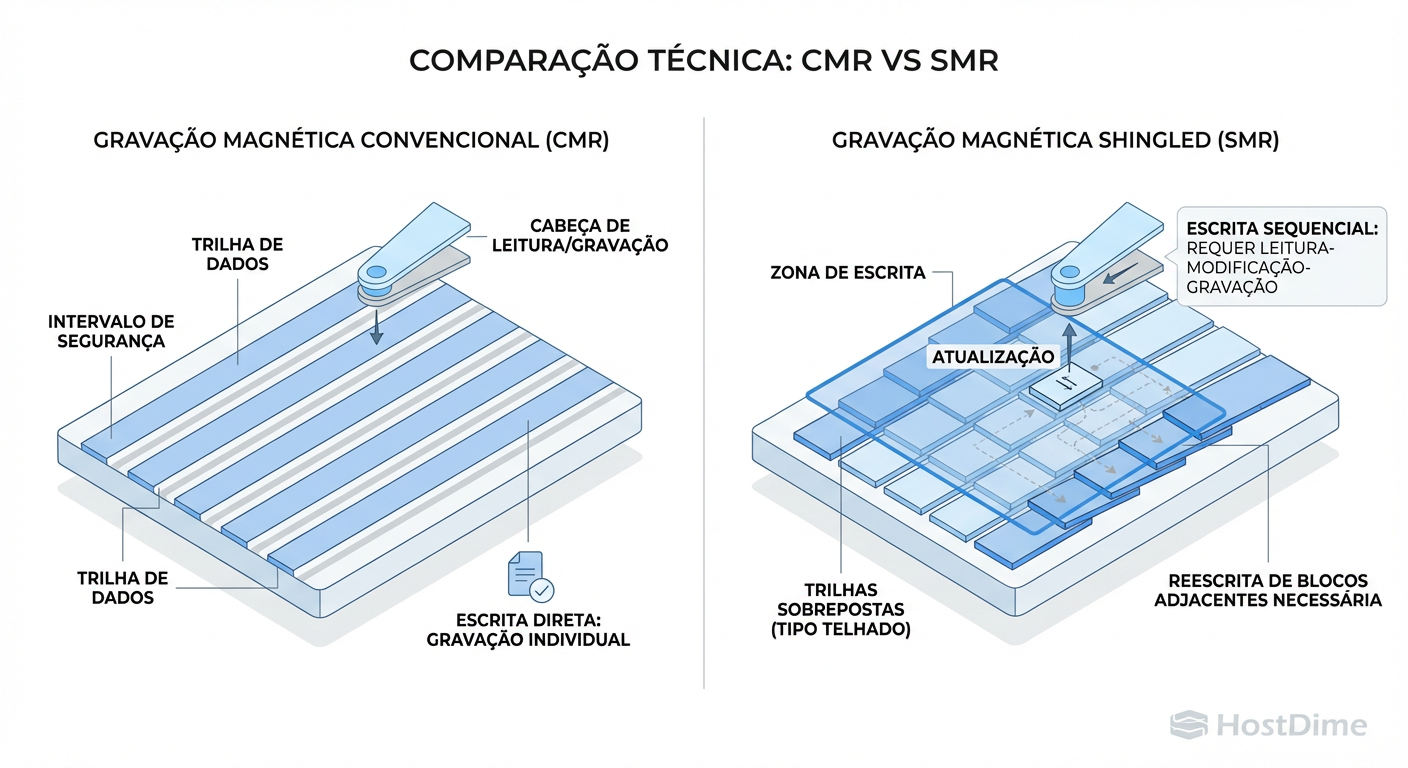 Figura: O Efeito Dominó: Por que alterar um setor em SMR obriga o disco a reescrever trilhas vizinhas (Read-Modify-Write).
Figura: O Efeito Dominó: Por que alterar um setor em SMR obriga o disco a reescrever trilhas vizinhas (Read-Modify-Write).
Isso cria um problema brutal de física: você não pode alterar um dado no meio de uma "telha" sem destruir os dados da telha seguinte. O disco precisa ler todo o bloco de telhas (uma Zona), modificar o dado na memória e reescrever a zona inteira sequencialmente.
Isso se chama Amplificação de Escrita. O seu sistema operacional pediu para gravar 4KB. O disco, internamente, pode ter que mover 256MB de dados para cumprir essa ordem. Para um único arquivo de Excel, você não nota. Para um ZFS Scrub ou uma reconstrução de RAID 5/6, onde a escrita é constante e sustentada, o disco entra em estado de choque.
O Estouro do Cache CMR e a Latência em Reconstrução
"Mas eu testei o disco copiando um filme e ele bateu 180MB/s!" — diz o administrador otimista.
Aqui reside a maior armadilha. Todos os discos SMR possuem uma "zona de aterrissagem" (Landing Zone) feita de trilhas CMR convencionais, atuando como um cache de escrita rápido. Enquanto você está gravando dados e esse cache tem espaço, o disco se comporta como um drive normal.
O problema surge quando o cache enche. Em uma reconstrução de RAID, você está jogando terabytes de dados continuamente. O cache CMR enche em minutos. Quando isso acontece, o disco precisa fazer duas coisas ao mesmo tempo:
Gravar os novos dados que chegam.
Esvaziar o cache CMR para as trilhas SMR lentas (shingled) para liberar espaço.
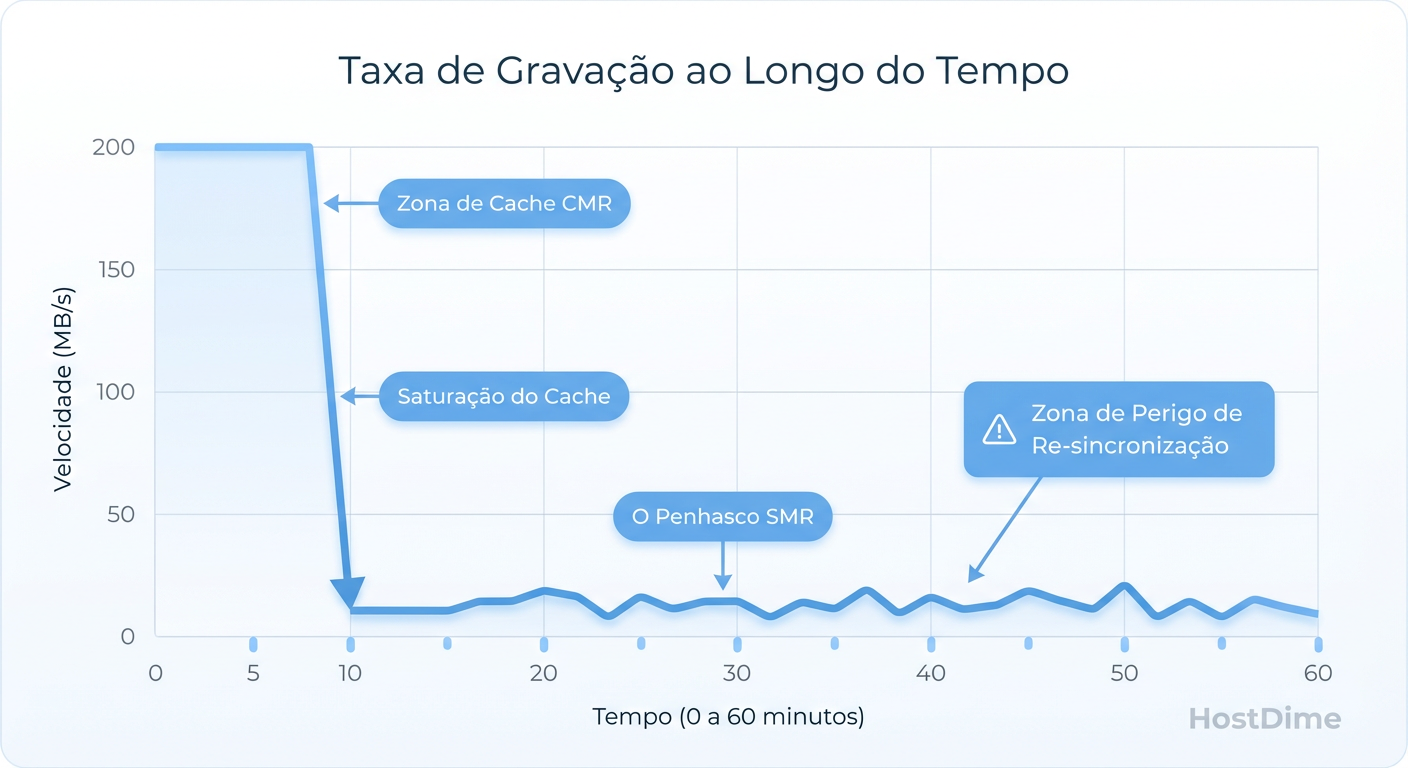 Figura: O Penhasco do SMR: O comportamento real de um disco DM-SMR quando o cache CMR se esgota durante uma reconstrução de RAID.
Figura: O Penhasco do SMR: O comportamento real de um disco DM-SMR quando o cache CMR se esgota durante uma reconstrução de RAID.
Neste ponto, a performance cai de um penhasco. De 150MB/s para 10MB/s ou menos. Pior que a velocidade é a latência. O disco para de responder por segundos (às vezes minutos) enquanto reorganiza os dados internamente. Controladores RAID de hardware (LSI, Dell PERC) e softwares como mdadm têm limites de tempo (timeouts). Se o disco não responder em 8 ou 30 segundos, o controlador assume que o disco morreu e o expulsa do array.
Diferenças entre DM-SMR e HM-SMR em 2026
Estamos em 2026 e o cenário amadureceu, mas a confusão persiste. É vital distinguir o "vilão" da tecnologia enterprise legítima. O problema não é o SMR em si, mas quem gerencia a complexidade das zonas.
| Característica | DM-SMR (Drive Managed) | HM-SMR (Host Managed) / ZNS |
|---|---|---|
| Quem controla as zonas? | O firmware do disco (Caixa Preta). | O Sistema Operacional / File System. |
| Visibilidade | O disco "mente" que é um bloco contínuo. | O disco expõe as zonas e restrições. |
| Comportamento RAID | Perigoso. Latência imprevisível. | Seguro (se configurado). O OS alinha writes sequenciais. |
| Uso Ideal | Backup frio (Cold Storage) disco único. | Datacenters, Dropbox, Arquivamento em escala. |
| Sintoma de Falha | Timeout do controlador, array degradado. | Erro de I/O se tentar gravar aleatoriamente. |
O Vilão é o DM-SMR. Ele tenta esconder a natureza SMR do sistema operacional. É esse tipo de disco que você encontra em HDDs externos baratos e linhas "desktop" que acabam parando em servidores por engano. O HM-SMR (muitas vezes ligado ao padrão ZNS - Zoned Namespaces) é excelente, mas exige sistemas de arquivos preparados (como F2FS, Btrfs ou ZFS com suporte a Zoned Storage).
Identificando Discos SMR com smartctl e Fio
Os fabricantes nem sempre são transparentes nos datasheets. Você precisa de ferramentas forenses. Se você já tem os discos, não confie no rótulo.
1. A pista do TRIM (smartctl)
Discos rígidos mecânicos (HDD) tradicionalmente não suportam o comando TRIM (usado em SSDs). No entanto, discos SMR precisam saber quais setores são lixo para não perder tempo movendo dados inúteis durante a reorganização das zonas. Se um HDD reporta suporte a TRIM, há 99% de chance de ser SMR.
sudo smartctl -x /dev/sdX | grep -i "TRIM"
# Saída suspeita (Sinal de SMR):
# "Data Set Management TRIM supported (limit 8 blocks)"
2. O Teste de Estresse (fio)
Se o smartctl for inconclusivo, force o estouro do cache. Usaremos o fio para escrever aleatoriamente (o pior pesadelo do SMR) e observar a latência.
Atenção: Execute isso apenas em discos vazios ou de teste.
# Teste de escrita aleatória sustentada para estourar o cache CMR
fio --name=smr_test --ioengine=libaio --rw=randwrite --bs=4k \
--direct=1 --size=10G --numjobs=1 --runtime=300 --group_reporting \
--filename=/dev/sdX
Como interpretar:
Disco CMR: Manterá IOPS consistentes (ex: 80-120 IOPS) durante todo o teste.
Disco DM-SMR: Começará rápido (cache). Após alguns GBs, os IOPS cairão para números de um dígito (ex: 5-10 IOPS) e a latência de clat (completion latency) saltará de milissegundos para centenas de milissegundos.
O Papel do ZFS e Zoned Storage no SMR Moderno
O ZFS, sendo um sistema Copy-on-Write (CoW), é teoricamente mais amigável ao SMR do que sistemas que sobrescrevem dados no lugar (como EXT4), pois o ZFS sempre grava em novos blocos. No entanto, o ZFS ama metadados e operações de limpeza (scrub), que podem ser mortais para SMR.
A Salvação: Special VDEVs
Se você é obrigado a usar discos SMR em um pool ZFS, a melhor mitigação técnica (além de trocar os discos) é o uso de um Special VDEV.
Ao adicionar um espelho de SSDs (mesmo que pequenos) dedicado a armazenar Metadados, você remove a carga de escrita aleatória pequena dos discos SMR rotacionais. O SMR fica encarregado apenas dos blocos de dados grandes e sequenciais, que é o que ele consegue fazer razoavelmente bem.
# Exemplo conceitual de criação de pool com mitigação
zpool create tank raidz2 /dev/disk-smr-1 /dev/disk-smr-2 ... \
special mirror /dev/ssd-meta-1 /dev/ssd-meta-2
Nota: Se o Special VDEV falhar, o pool morre. Use redundância (mirror) nos SSDs.
Checklist de Mitigação para RAID com Discos SMR
Se você já comprou os discos e não pode devolvê-los, aqui está seu guia de sobrevivência para minimizar a chance de perda total.
Evite RAID 5 ou RAID 6 (Paridade): O cálculo de paridade gera um padrão de leitura-modificação-escrita que amplifica o problema do SMR. Reconstruir um RAID 5 com discos SMR é quase garantia de falha de um segundo disco durante o processo.
Prefira Espelhamento (RAID 1 / RAID 10): A reconstrução de um espelho é puramente sequencial (leia A, escreva em B). O SMR lida muito melhor com escritas sequenciais longas do que com a matemática aleatória da paridade.
Aumente o Timeout do Controlador: Se usar Linux Software RAID (
mdadm) ou ZFS, aumente a tolerância para discos lentos para evitar que sejam expulsos.# Aumentar timeout para 180 segundos (Linux genérico) echo 180 > /sys/block/sdX/device/timeoutAgende Scrubs/Resilvering com Cuidado: Não deixe processos de verificação rodarem durante horário de pico. Em SMR, um scrub pode inutilizar a performance do array por dias.
Backup é Obrigatório: Um array de SMR não é redundância confiável. Considere-o um volume grande e frágil. Tenha backup externo.
Veredito Técnico Pragmática
Discos SMR (especialmente DM-SMR) não são "ruins" universalmente; eles são ruins para a carga de trabalho errada. Eles são excelentes para "Write Once, Read Many" (WORM) como arquivamento de vídeo ou backups noturnos sequenciais. Para VM storage, bancos de dados ou RAID convencional de alta disponibilidade, eles são uma bomba-relógio. Meça a latência, verifique o modelo e não deixe o preço baixo por TB cegar sua arquitetura.
Referências & Leitura Complementar
Zoned Block Commands (ZBC) & Zoned Device ATA Command Set (ZAC): Especificações T10/T13 que definem como o host deve interagir com zonas.
USENIX FAST '20: "Geomancy: Automated Performance Characterization of SMR Drives" – Análise acadêmica profunda sobre o comportamento oculto de tradução de endereços em SMR.
Western Digital Tech Brief: "SMR: What We Learned" (Análise pós-incidente WD Red 2020).
Manpages:
man 8 smartctl,man 1 fio.

Kenji Tanaka
Especialista em Performance de I/O
Obscecado por latência zero. Analisa traces de kernel e otimiza drivers de storage para bancos de dados de alta frequência.