RAID Crítico: Guia de Engenharia para Recuperação de Arrays com Múltiplas Falhas (2026)
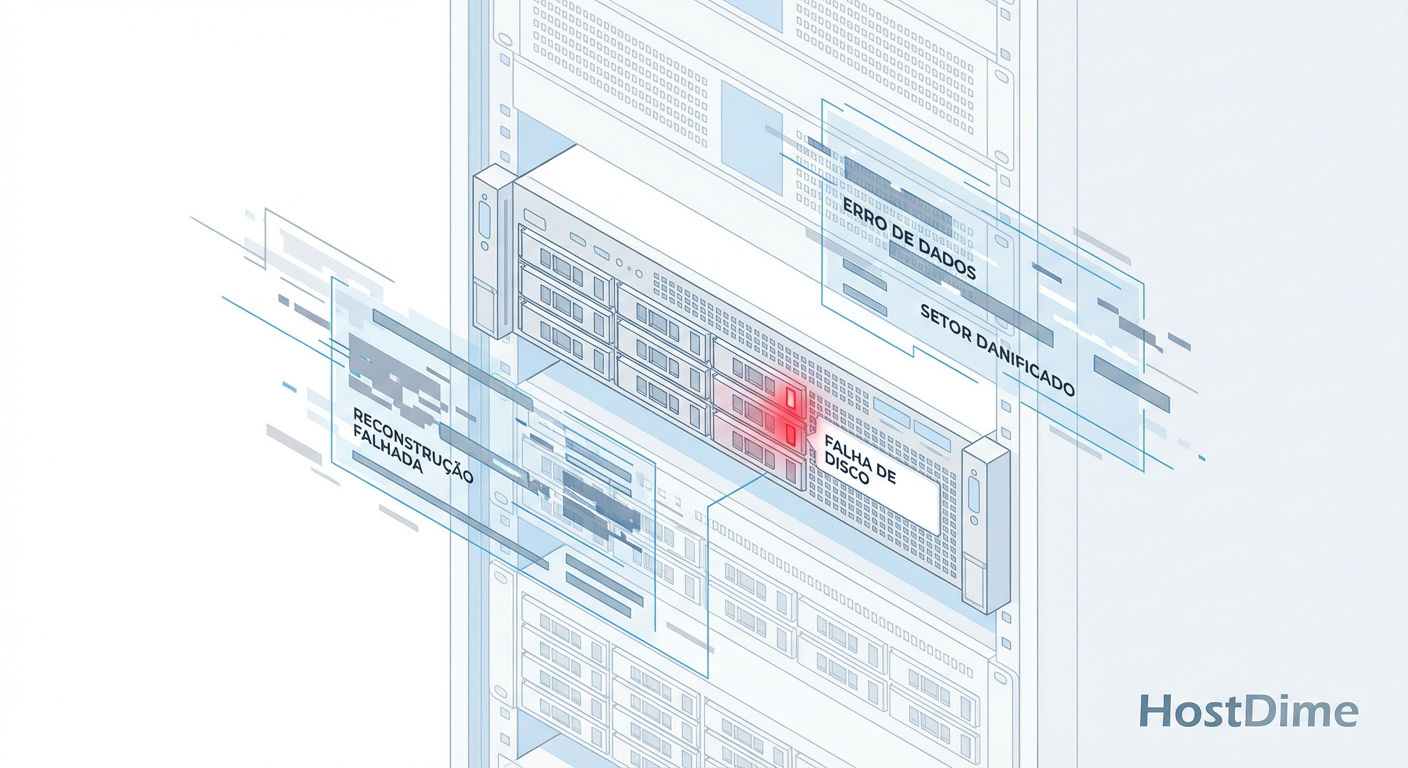
O array desmontou e o backup falhou? Pare tudo. Aprenda o protocolo 'Read-Only', clonagem forense com ddrescue e técnicas de remontagem virtual para salvar dados em cenários de desastre.
O silêncio na sala de servidores é aterrorizante quando o LED de status do storage muda de âmbar piscante para vermelho sólido. Em 2026, com densidades de disco ultrapassando 24TB por unidade, a matemática da recuperação de dados mudou. O tempo de reconstrução (rebuild) não é mais uma inconveniência; é uma janela de vulnerabilidade estatística onde a probabilidade de um erro de leitura irrecuperável (URE - Unrecoverable Read Error) em um segundo disco beira a certeza.
Se você está lendo isso, seu RAID não está apenas degradado; ele colapsou. Múltiplos membros falharam. O controlador desistiu. A seguir, apresento a metodologia de engenharia para lidar com esse cenário, abandonando a esperança em favor da evidência métrica e do isolamento de falhas.
O Que é Recuperação de RAID Crítico?
Recuperação de RAID Crítico é o processo de engenharia forense aplicado a arrays de armazenamento que sofreram falhas de disco além da tolerância de paridade do nível RAID configurado (ex: 2 discos em RAID 5). O objetivo não é reparar o array para produção imediata, mas sim estabilizar os meios físicos, clonar os dados brutos e extrair informações vitais usando remontagem virtual, evitando qualquer operação de escrita nos discos originais.
Anatomia do Colapso do RAID e a Física da Falha
Para resolver o problema, você precisa entender a física do que acabou de acontecer. Um RAID 5 tolera a perda de um disco. Um RAID 6, de dois. Quando você perde mais discos do que a paridade suporta, o volume lógico desmonta. No entanto, "falha" é um termo guarda-chuva impreciso.
Na engenharia de performance, distinguimos três estados de falha:
Falha Mecânica Total: O motor não gira, as cabeças bateram ou a PCB queimou. IOPS = 0.
Falha de Setor (URE): O disco funciona, mas certas áreas magnéticas não podem ser lidas. O controlador RAID expulsa o disco porque ele demorou mais de 8 segundos para responder (timeout), derrubando o array.
Falha Lógica/Firmware: O disco mente sobre sua capacidade ou entra em modo de proteção.
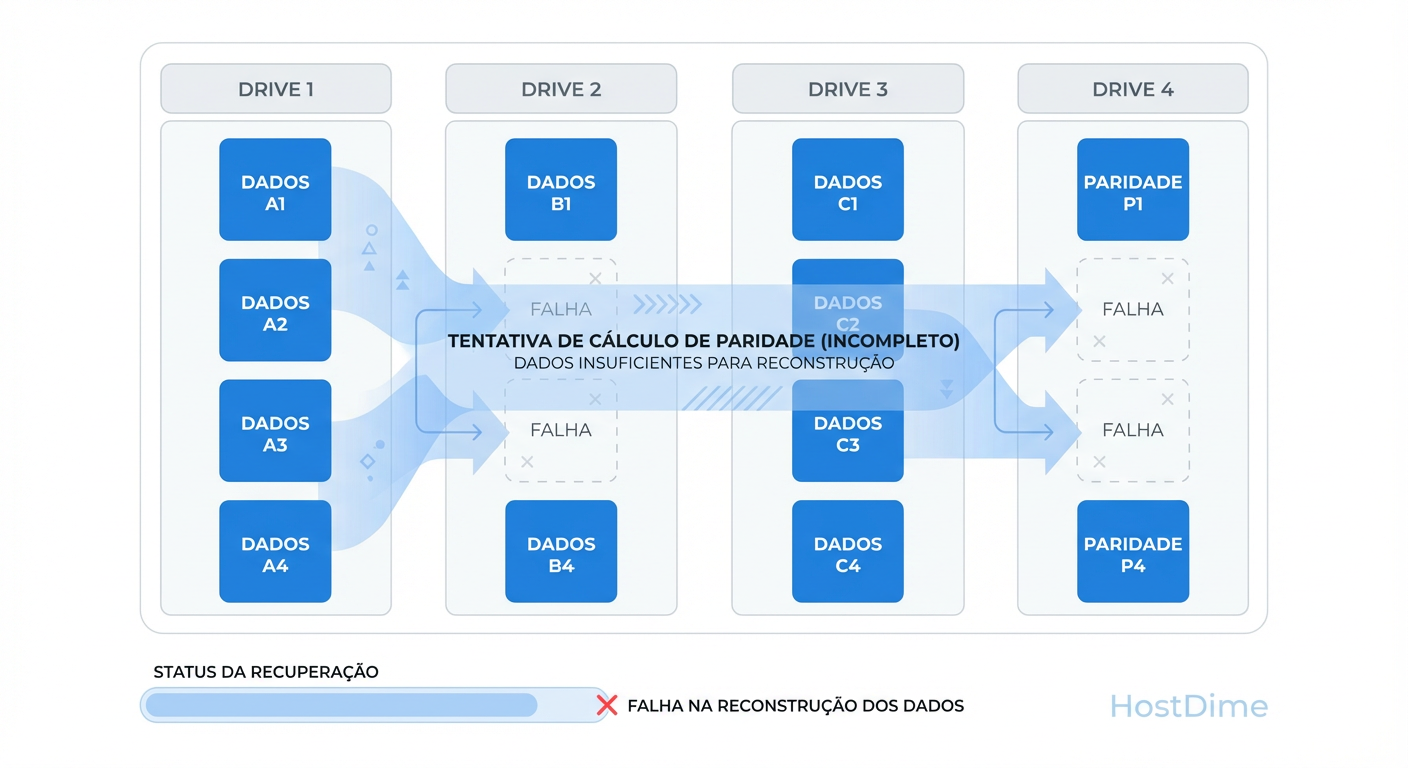 Figura: A Matemática da Perda: Como falhas múltiplas criam 'buracos' na paridade que tornam a reconstrução automática impossível.
Figura: A Matemática da Perda: Como falhas múltiplas criam 'buracos' na paridade que tornam a reconstrução automática impossível.
A maioria dos colapsos de múltiplos discos ocorre durante o rebuild. O estresse mecânico de ler cada setor do array restante para reconstruir um disco novo expõe setores defeituosos latentes em discos que pareciam saudáveis. Isso cria "buracos" na paridade (stripe holes). Se o controlador encontrar um buraco onde não há redundância, o array para.
O Protocolo Zero-Write e os Perigos do Rebuild Automático
A primeira regra da recuperação é: Pare de escrever.
Engenheiros inexperientes tentam forçar o disco online e rodar fsck (Linux) ou chkdsk (Windows). Isso é catastrófico. Ferramentas de reparo de sistema de arquivos assumem que o dispositivo de bloco subjacente é confiável. Em um RAID instável, o fsck vai "corrigir" erros apagando nós de diretórios e truncando arquivos, gravando lixo sobre dados que poderiam ser recuperados.
Checklist de Contenção Imediata:
Desativar Inicialização Automática: Garanta que o controlador RAID ou o SO não tentem montar o volume no boot.
Cancelar Rebuilds: Se o rebuild travou, não tente reiniciá-lo. O disco fonte está morrendo.
Rotulagem Física: Identifique a posição física de cada disco e sua ordem lógica, se conhecida.
Clonagem Forense com ddrescue e hddsuperclone para Preservação de Dados
Não trabalhamos nos discos originais. Nunca. A latência de um disco falhando é errática e o estresse de leitura sequencial pode ser o golpe final. Precisamos congelar o estado dos discos em imagens ou clones saudáveis.
Ferramentas como dd são inadequadas porque engasgam ao encontrar erros de leitura. Usamos ddrescue ou hddsuperclone. Estas ferramentas utilizam um algoritmo de log que:
Lê rapidamente as áreas fáceis (aumentando o throughput).
Pula grandes blocos ao encontrar erros.
Volta depois para tentar ler (scraping) apenas os setores danificados, de trás para frente ou dividindo blocos.
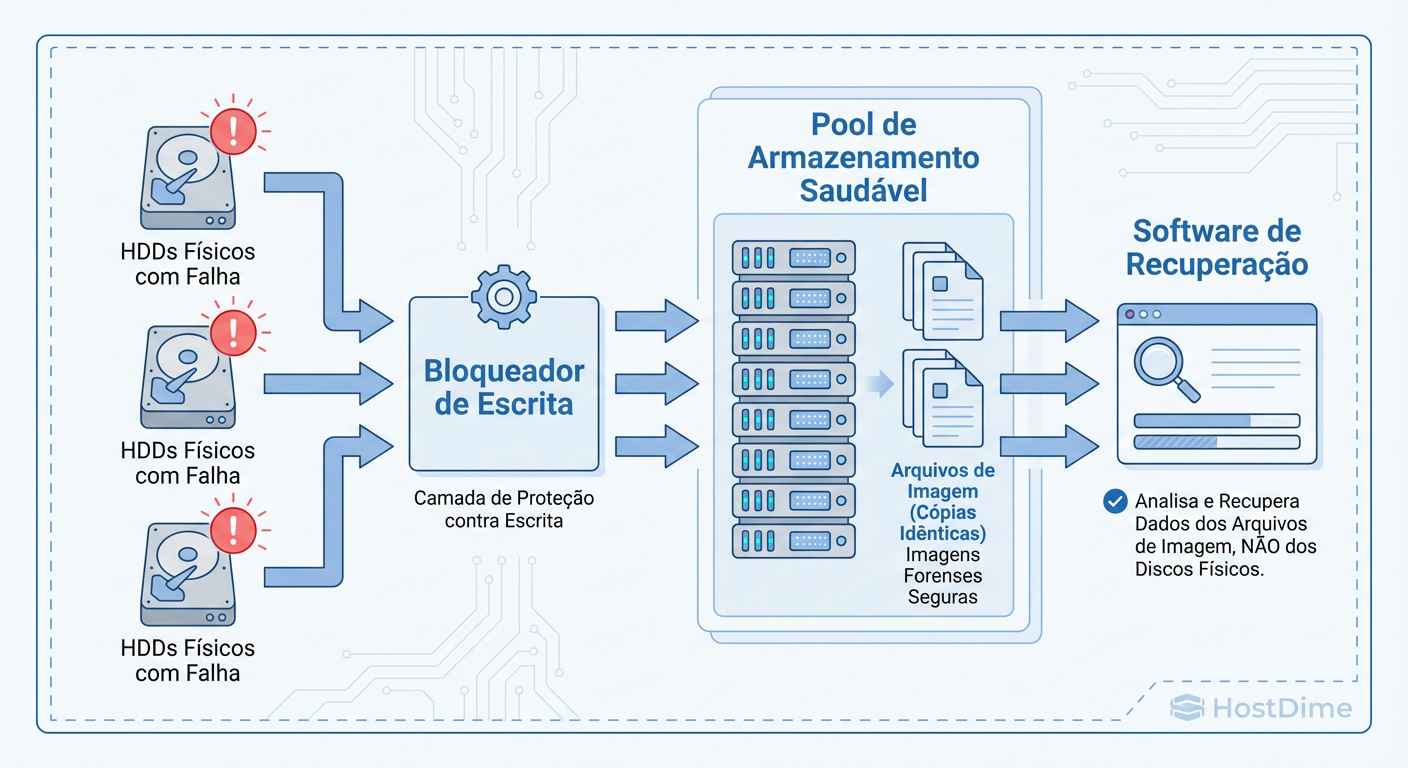 Figura: Fluxo de Recuperação Seguro: O princípio fundamental é nunca trabalhar nos discos originais danificados, mas sim em clones ou imagens.
Figura: Fluxo de Recuperação Seguro: O princípio fundamental é nunca trabalhar nos discos originais danificados, mas sim em clones ou imagens.
O objetivo é extrair 99.9% dos dados saudáveis com o mínimo de desgaste mecânico.
Exemplo de Procedimento de Clonagem
# Fase 1: Copiar o máximo possível sem tentar recuperar erros (rápido)
# -n: não faça scraping / -N: não faça trimming
ddrescue -n -N /dev/sdX /caminho/para/imagem_clone.img mapa_log.log
# Fase 2: Tentar ler os setores ruins (apenas 3 tentativas para não matar o disco)
# -r3: retry 3 vezes
ddrescue -r3 /dev/sdX /caminho/para/imagem_clone.img mapa_log.log
Se o disco estiver instável a ponto de desconectar via USB/SATA, o hddsuperclone é superior pois consegue enviar comandos de reset de hardware para a porta SATA/SCSI e continuar a cópia automaticamente.
Diagnóstico de Hardware: Identificando o Disco Recuperável no Array
Em um cenário de RAID 5 com 2 discos "falhos", um deles falhou primeiro e o outro falhou agora.
O disco que falhou primeiro contém dados antigos (stale data). Se você forçá-lo online, corromperá o sistema de arquivos com dados do passado.
O disco que falhou agora (provavelmente por URE) contém dados atuais, exceto pelos setores ruins.
Você precisa identificar o disco "menos pior".
Matriz de Decisão de Membros do RAID
| Estado do Disco | Sintoma Técnico | Ação Recomendada | Risco |
|---|---|---|---|
| Saudável | SMART OK, Latência estável | Clonar imediatamente | Baixo |
| Falha Recente (Last Dead) | UREs, Timeout, SMART "Pending Sectors" | Clonar com ddrescue. Forçar montagem neste clone. |
Médio (Perda pontual de dados) |
| Falha Antiga (Stale) | Saiu do array há dias/meses | NÃO USAR para remontagem, exceto último recurso | Crítico (Corrupção lógica massiva) |
| Falha Mecânica | Click of Death, não detectado | Requer sala limpa (Lab externo) | Alto (Custo/Tempo) |
Remontagem Virtual via Overlays e dm-snapshot para Testes Seguros
Uma vez que você tem as imagens (clones) dos discos, como você tenta montar o RAID sem arriscar corromper os clones caso a ordem dos discos ou o tamanho do stripe (chunk size) estejam errados?
A resposta é Copy-On-Write (COW) Overlays.
No Linux, podemos usar o device-mapper para criar uma camada gravável temporária sobre nossas imagens de disco que são somente leitura. Todas as escritas que o SO ou o comando mdadm tentarem fazer (como atualizar superblocos ou replay de journal) serão gravadas na RAM ou em um arquivo temporário, deixando a imagem base intocada.
O Conceito de Overlay Loop
Se você errar a ordem dos discos na montagem virtual, o sistema de arquivos parecerá lixo. Sem overlay, a tentativa de montagem pode escrever metadados no disco, invalidando tentativas futuras. Com overlay, basta descartar a camada temporária e tentar uma nova permutação.
# Exemplo conceitual de criação de overlay para teste seguro
# 1. Criar dispositivo de loop somente leitura para a imagem
losetup -r /dev/loop0 imagem_disco1.img
# 2. Criar um arquivo esparso para receber as escritas (overlay)
truncate -s 4T overlay1.img
losetup /dev/loop1 overlay1.img
# 3. Usar dm-setup para combinar (snapshot target)
# Isso cria um dispositivo /dev/mapper/disco1_virtual que pode ser escrito,
# mas as escritas vão para o overlay, não para a imagem base.
Este método permite "força bruta" inteligente nos parâmetros do RAID (ordem, paridade, rotação) até que o sistema de arquivos seja reconhecido.
Extração Cirúrgica de Arquivos vs. Reparo do Sistema de Arquivos
Chegamos ao ponto de decisão final. Você conseguiu montar o array virtualmente, mas o sistema de arquivos está sujo (dirty bit set) e há corrupção devido aos buracos de paridade.
Não tente consertar o sistema de arquivos para torná-lo bootável. O sistema operacional é descartável; os dados não.
Estratégia de Extração
Montagem Read-Only: Monte o volume lógico como somente leitura (
mount -o ro,noload). Onoloadimpede o replay do journal, que pode falhar se o journal estiver corrompido.Cópia de Arquivos Críticos: Copie bancos de dados, VHDs e documentos para um storage externo novo.
Validação de Aplicação: Teste a integridade dos arquivos copiados (ex:
DBCC CHECKDBpara SQL Server, teste de integridade de backup) antes de declarar sucesso.
Se a montagem falhar devido a danos severos nos metadados (superbloco destruído), ferramentas de "carving" como photorec ou scanners profissionais (R-Studio, UFS Explorer) devem ser apontadas para o array virtual reconstruído para extrair arquivos por assinatura binária, ignorando a tabela de arquivos.
Referências & Leitura Complementar
RFC 3720 (iSCSI) & SCSI Architecture Model (SAM-5): Para entender timeouts e tratamento de erros de bloco em nível de protocolo.
Manuais do GNU ddrescue: Documentação oficial sobre algoritmos de recuperação e uso de mapfiles.
Kernel.org Device Mapper Documentation: Detalhes técnicos sobre alvos de snapshot e implementação de overlays para testes não destrutivos.
Google Research: Failure Trends in a Large Disk Drive Population (Pinheiro et al.): Estudo fundamental sobre correlação de erros SMART e falhas reais.

Elena Kovacs
Arquiteta de Cloud Infrastructure
Focada em NVMe-oF e storage definido por software. Projeta clusters de petabytes para grandes provedores de nuvem.