RAID em SSDs: A Verdade Sobre Bit Rot, Rebuilds e Degradação de Performance

Seu array All-Flash não é invencível. Entenda a física da amplificação de escrita, por que o Bit Rot acontece em SSDs e como evitar que um rebuild mate seus dados.
O chamado chegou às 03:00 da manhã. O banco de dados não estava "fora do ar", mas as consultas que levavam milissegundos agora demoravam segundos. O administrador do sistema jurava que os discos eram novos — SSDs de consumo de alta performance em RAID 5. "É impossível ser o disco, o throughput está alto", dizia ele.
Minha abordagem forense começa ignorando o throughput. Throughput é vaidade; latência é sanidade. Ao isolar as variáveis, encontrei o culpado: não foi um bug de software, nem a rede. Foi uma colisão fundamental entre a lógica arcaica do RAID e a física complexa da memória Flash. O array não estava falhando; ele estava se afogando em sua própria complexidade.
RAID em SSDs é a prática de combinar unidades de estado sólido para redundância ou performance, mas que introduz desafios únicos de Amplificação de Escrita (Write Amplification) e latência de Garbage Collection. Diferente dos HDDs, a abstração do RAID tradicional pode conflitar com os algoritmos internos do SSD, acelerando o desgaste das células NAND e criando gargalos de performance invisíveis em métricas superficiais.
A Colisão entre Lógica RAID Legada e Física Flash
Para entender o crime, precisamos entender a vítima. Um controlador RAID tradicional (seja hardware ou software como mdadm padrão) pensa que está gravando em um prato magnético. Ele assume que sobrescrever um setor é uma operação de custo fixo.
A memória Flash não funciona assim. Você não pode simplesmente sobrescrever dados. Você deve:
Ler o bloco inteiro para a memória.
Modificar a página desejada.
Apagar o bloco original (uma operação de alta voltagem e lenta).
Gravar o bloco modificado em um novo local.
Quando você coloca um RAID 5 ou 6 em cima disso, você introduz a penalidade de "Read-Modify-Write" da paridade. O controlador RAID lê os dados antigos e a paridade antiga, calcula a nova paridade e grava os dois.
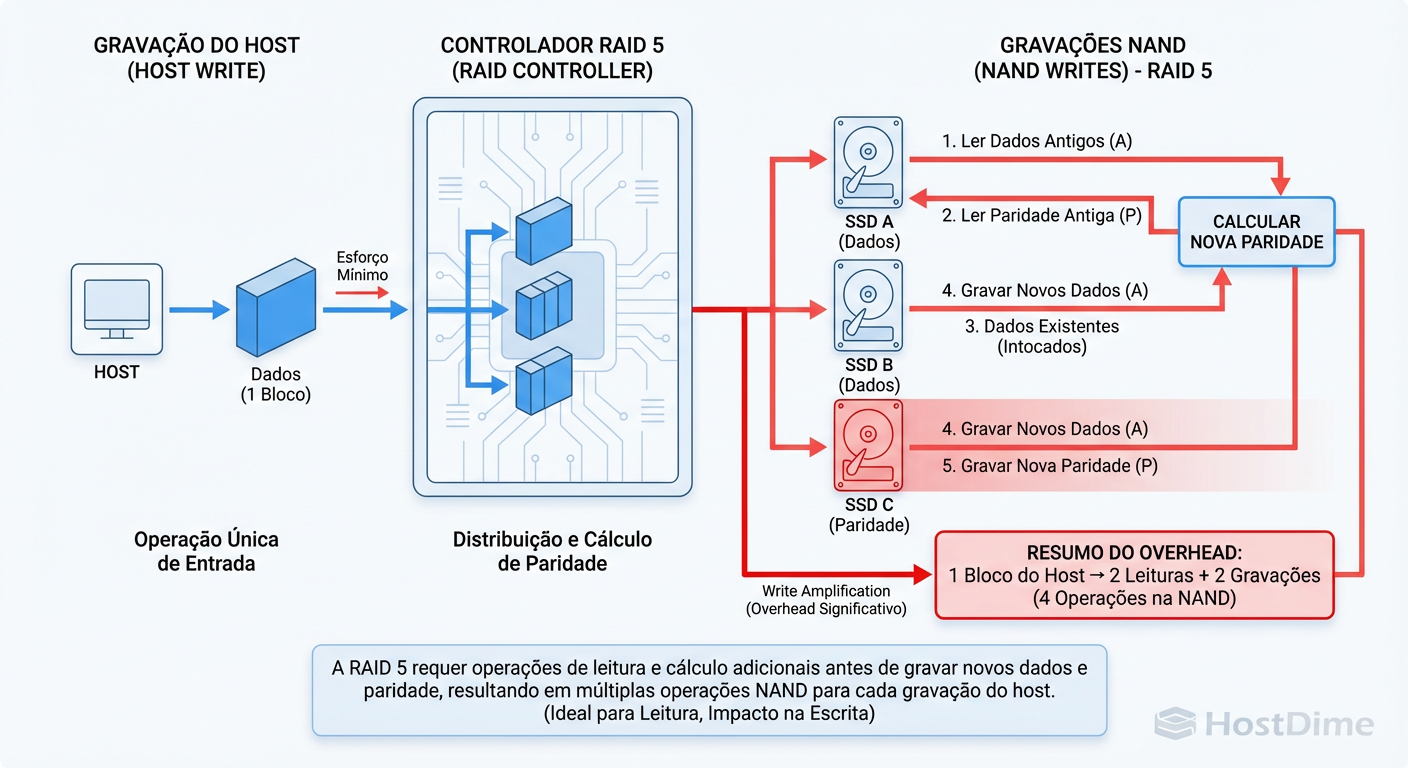 Figura: Amplificação de Escrita em RAID 5: O assassino silencioso da performance e durabilidade dos SSDs.
Figura: Amplificação de Escrita em RAID 5: O assassino silencioso da performance e durabilidade dos SSDs.
Isso gera um efeito multiplicador devastador. O sistema operacional pede para gravar 4KB. O RAID transforma isso em duas leituras e duas escritas. O controlador do SSD, lidando com páginas de 4KB mas blocos de apagamento de 2MB, acaba movendo megabytes de dados internamente para acomodar essa pequena gravação. O resultado é latência instável e morte prematura do drive.
A Armadilha da Amplificação de Escrita em RAID 5/6
A "Amplificação de Escrita" (Write Amplification - WA) é o assassino silencioso em arrays All-Flash mal configurados. Em um cenário forense, frequentemente encontro SSDs com 10% de vida útil restante após apenas seis meses de uso.
O problema se agrava com drives de consumo (QLC ou TLC sem DRAM). Esses drives dependem de um cache SLC (Single-Level Cell) pseudo-estático para performance. O RAID, com suas escritas de paridade constantes, satura esse cache rapidamente.
Tabela de Risco: RAID em SSDs
Aqui está a análise comparativa do impacto real na durabilidade e performance:
| Nível RAID | Penalidade de Escrita (Lógica) | Impacto na Amplificação de Escrita (SSD) | Risco de Latência (Stall) | Custo de Capacidade |
|---|---|---|---|---|
| RAID 0 | Nenhuma (1:1) | Baixo | Baixo | Baixo |
| RAID 1/10 | Baixa (2x escritas) | Moderado | Baixo | Alto (-50%) |
| RAID 5 | Alta (4 I/Os por escrita) | Crítico (Extreme WA) | Alto (GC Storms) | Baixo (-1 drive) |
| RAID 6 | Muito Alta (6 I/Os por escrita) | Severo | Muito Alto | Moderado (-2 drives) |
| RAID-Z (ZFS) | Variável (CoW) | Moderado (Transforma random em sequencial) | Moderado | Baixo |
Se você está usando drives de consumo em RAID 5, você não tem um sistema de armazenamento; você tem um relógio-bomba com o fusível aceso.
O Fenômeno do Bit Rot em SSDs e Controladores Mentirosos
Bit Rot (apodrecimento de bits) em SSDs é diferente de HDDs. Em HDDs, o meio magnético degrada. Em SSDs, elétrons vazam das armadilhas de carga flutuante (floating gates).
O problema forense surge quando o controlador de hardware "mente". Controladores RAID com cache de escrita (Write Back) confirmam a gravação para o SO antes de os dados tocarem a memória NAND. Se houver uma falha de energia e a bateria do cache (BBU) falhar ou não existir, os dados somem.
Pior ainda é a corrupção silenciosa. O SSD tem seu próprio ECC (Error Correction Code). O RAID tem sua paridade. Mas se o SSD sofrer um "bit flip" silencioso na transmissão ou no buffer interno antes de gravar, e o controlador RAID não fizer scrub (verificação de integridade) frequente, você terá dados corrompidos que só serão descobertos no backup — quando for tarde demais.
Anatomia de um Rebuild Lento e Latência de Cauda
O cenário clássico de desastre: Um SSD falha em um RAID 5. Você insere um novo. O rebuild começa. De repente, a latência da aplicação salta de 2ms para 500ms, com picos de 2 segundos.
Por que isso acontece?
Leitura Competitiva: Todos os SSDs sobreviventes devem ler 100% de seus dados para recalcular o que falta.
Esgotamento de Cache SLC: O drive novo está recebendo gravações contínuas. Seu cache SLC enche em segundos. Ele cai para a velocidade nativa da NAND (que em drives QLC pode ser tão lenta quanto 80MB/s).
Bloqueio de I/O: O controlador RAID espera o drive mais lento (o novo, escrevendo sem cache) para confirmar cada stripe. O array inteiro opera na velocidade do drive mais lento.
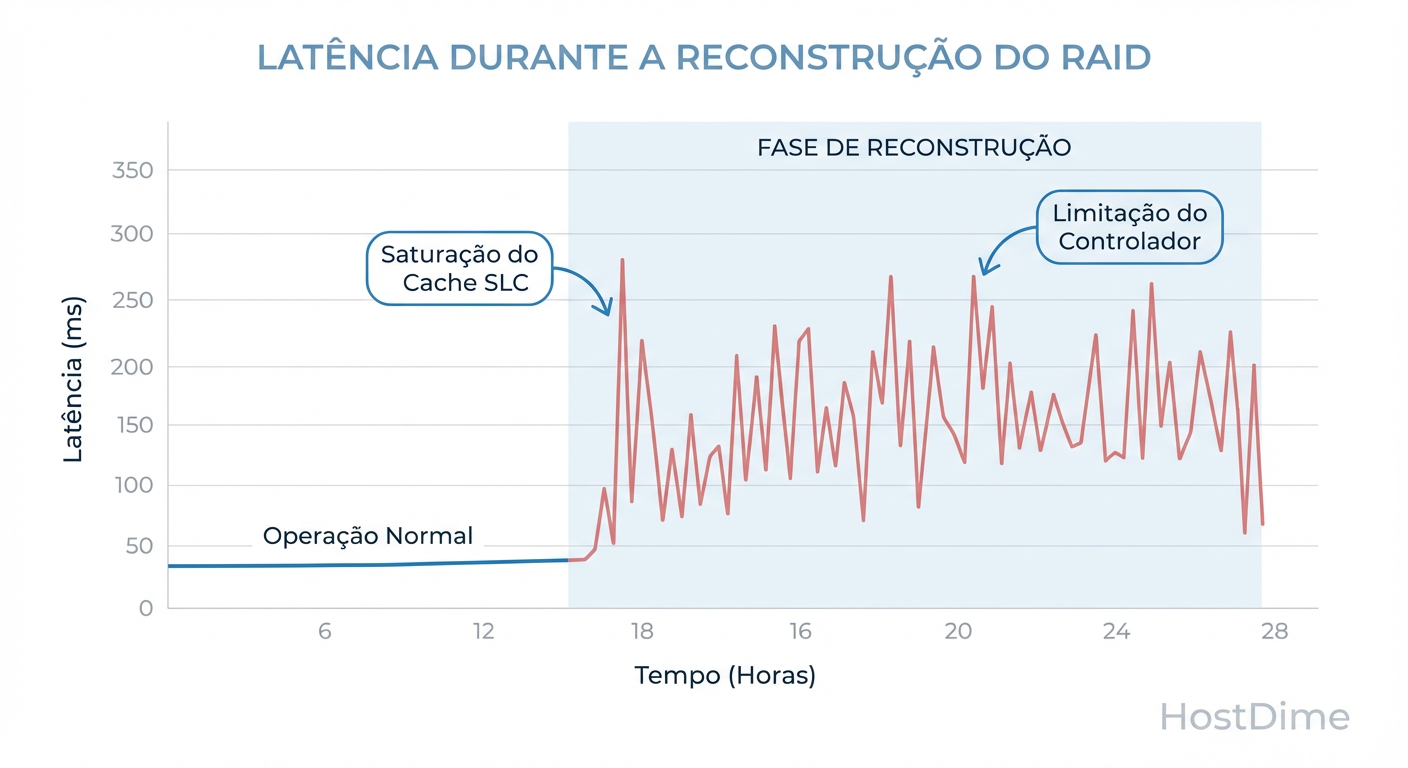 Figura: O impacto da saturação do Cache SLC na latência durante um rebuild.
Figura: O impacto da saturação do Cache SLC na latência durante um rebuild.
Isso cria uma "latência de cauda" (tail latency). A média pode parecer boa, mas 1% das requisições (as que ficam presas atrás de uma operação de Garbage Collection forçada) demoram segundos, travando aplicações sensíveis.
Diagnóstico Forense: Identificando o Gargalo
Não adivinhe. Meça. Se você suspeita que seus SSDs estão sofrendo com a lógica do RAID, use as ferramentas certas.
1. Verificando Desgaste Prematuro (smartctl)
Ignore o status "OK". Olhe para o Media_Wearout_Indicator ou Percentage_Used.
# Verifique a vida útil restante e o total de escritas
sudo smartctl -a /dev/sdX | grep -E "Percentage Used|Total_LBAs_Written|Media_Wearout"
Se o Total_LBAs_Written for desproporcionalmente alto comparado ao que sua aplicação gera, você tem um problema de Amplificação de Escrita induzido pelo RAID.
2. Identificando Latência de Dispositivo (iostat)
O iostat revela se um disco específico está segurando o array. Foco na coluna w_await (tempo de espera para escrita) e %util.
# Monitoramento a cada 1 segundo, exibindo apenas discos ativos e tempo estendido
iostat -xnz 1
Se você vir w_await acima de 10-20ms em um SSD consistentemente, o Garbage Collection interno está lutando para encontrar blocos livres. O disco está "asfixiado".
Estratégias de Mitigação e Sobrevivência
Como investigador, meu veredito para evitar a reincidência do problema é claro: pare de tratar SSDs como HDDs rápidos.
ZFS: O Aliado Inteligente
O ZFS (e sistemas similares Copy-on-Write) mitiga o problema do "Read-Modify-Write" do RAID 5 tradicional. O ZFS transforma gravações aleatórias em transações sequenciais. Isso alinha melhor com a física do SSD, que adora gravações sequenciais (menos fragmentação de blocos).
- Dica: Use
recordsizealinhado com a carga de trabalho (ex: 16k ou 64k para bancos de dados) para evitar ler 128k apenas para modificar 4k.
Overprovisioning: Espaço para Respirar
Nunca formate 100% do SSD. Deixe 10% a 20% do espaço não particionado. Isso dá ao controlador do SSD "espaço de manobra" para realizar o Garbage Collection em segundo plano sem impactar a performance de escrita ativa. É a maneira mais barata de aumentar a longevidade.
PLP (Power Loss Protection) é Obrigatório
Para uso em RAID ou ZFS (especialmente com SLOG/ZIL), use apenas SSDs com PLP (capacitores visíveis na placa).
Sem PLP: O drive deve confirmar a gravação apenas quando ela atinge a NAND (lento).
Com PLP: O drive confirma assim que atinge a DRAM (rápido), pois os capacitores garantem a energia para mover da DRAM para a NAND em caso de corte de luz.
Veredito Técnico Forense
O sintoma inicial — lentidão no banco de dados — não era culpa do software. Foi um erro de arquitetura. Construir arrays RAID 5/6 com SSDs de consumo sem entender a amplificação de escrita é negligência técnica.
Para operar certo:
Pense: Entenda que SSDs precisam apagar antes de gravar.
Meça: Monitore o
Percentage_Usede a latência de cauda, não apenas throughput.Decida: Use RAID 10 para cargas de escrita pesada, ZFS para integridade e sempre, sempre, exija PLP em ambientes de produção.
Referências & Leitura Complementar
"The RAID 5 Write Hole" - Exploração técnica sobre a falha atômica de paridade em quedas de energia.
JEDEC JESD218 - Padrão para requisitos de resistência e métodos de teste para SSDs (Client vs. Enterprise).
Intel Whitepaper: "Write Amplification: Impact of RAID on SSD Performance and Life".
OpenZFS Documentation: "ZFS on Flash - Tuning and Best Practices".

Alexei Volkov
Ceph Cluster Administrator
Escala clusters Ceph para o infinito. Mestre em CRUSH maps e recuperação de placement groups.