RAID para Machine Learning: Como Alimentar GPUs sem Gargalos de I/O

Suas GPUs estão ociosas esperando dados? Aprenda a otimizar RAID e Filesystems (XFS/ZFS) para o throughput massivo exigido por treinos de Deep Learning.
Você comprou as GPUs H100 ou A100. Você pagou a licença do software de orquestração. Seus cientistas de dados estão prontos. Mas, quando o treinamento começa, o uso da GPU oscila em 60-70%. O cooler da GPU desacelera.
Isso é o som do dinheiro sendo queimado.
O culpado quase sempre é o subsistema de armazenamento. Existe um mito perigoso de que "SSD é rápido, então qualquer configuração serve". Isso é mentira. Em cargas de trabalho de Machine Learning (ML), a forma como você organiza seus bits no disco (RAID e Filesystem) determina se sua GPU passa o tempo processando tensores ou esperando o sistema operacional entregar o próximo lote de imagens.
Não vou falar de "melhores práticas" de manual. Vou falar sobre a física de mover dados do ponto A ao ponto B rápido o suficiente para alimentar um processador voraz.
Otimização de Storage para Machine Learning A configuração de armazenamento para ML deve priorizar Throughput Sequencial de Leitura (MB/s) em vez de IOPS aleatórios. Diferente de bancos de dados, o treinamento de modelos lê grandes blocos de dados (batches) repetidamente. Para evitar gargalos, deve-se utilizar RAID 0 (performance pura) ou RAID 10 (performance + segurança), alinhar o stripe size ao tamanho médio dos arquivos/batches e evitar RAID com paridade (5/6) em arrays NVMe devido à sobrecarga de CPU.
O Problema da GPU Faminta e a Irrelevância de IOPS
A maioria dos administradores de sistemas foi treinada para otimizar bancos de dados ou servidores de virtualização. Nesses cenários, a métrica rainha é o IOPS (Input/Output Operations Per Second) em 4K Random Read/Write.
Em Deep Learning, essa métrica é quase inútil.
O padrão de acesso de um DataLoader (seja PyTorch ou TensorFlow) não é aleatório no sentido tradicional. Ele pega um batch (um lote de dados), que pode ter de 32MB a 512MB, e o carrega na VRAM. O que importa aqui é a Banda (Throughput).
Se você tem um array que entrega 1 milhão de IOPS mas engasga em 2GB/s de taxa de transferência sustentada, sua GPU vai passar fome (starvation). Você precisa de um "duto" largo, não de um duto que aguente muitos "cliques" rápidos.
A Matemática do RAID: Stripe Size vs. Tamanho do Batch no PyTorch
Aqui é onde a maioria das implementações falha silenciosamente. O controlador RAID (seja hardware ou software via mdadm) divide os dados em pedaços chamados chunks ou strips.
Se o seu stripe size for 64KB (padrão antigo de muitos controladores) e seu arquivo de imagem tiver 1MB, o sistema precisa ler de múltiplos discos para montar um único arquivo. Isso é bom para paralelismo, certo? Nem sempre.
Se o stripe size não estiver alinhado com o sistema de arquivos e com o tamanho médio de leitura da sua aplicação, você gera o fenômeno de "Read Amplification" mecânico/elétrico.
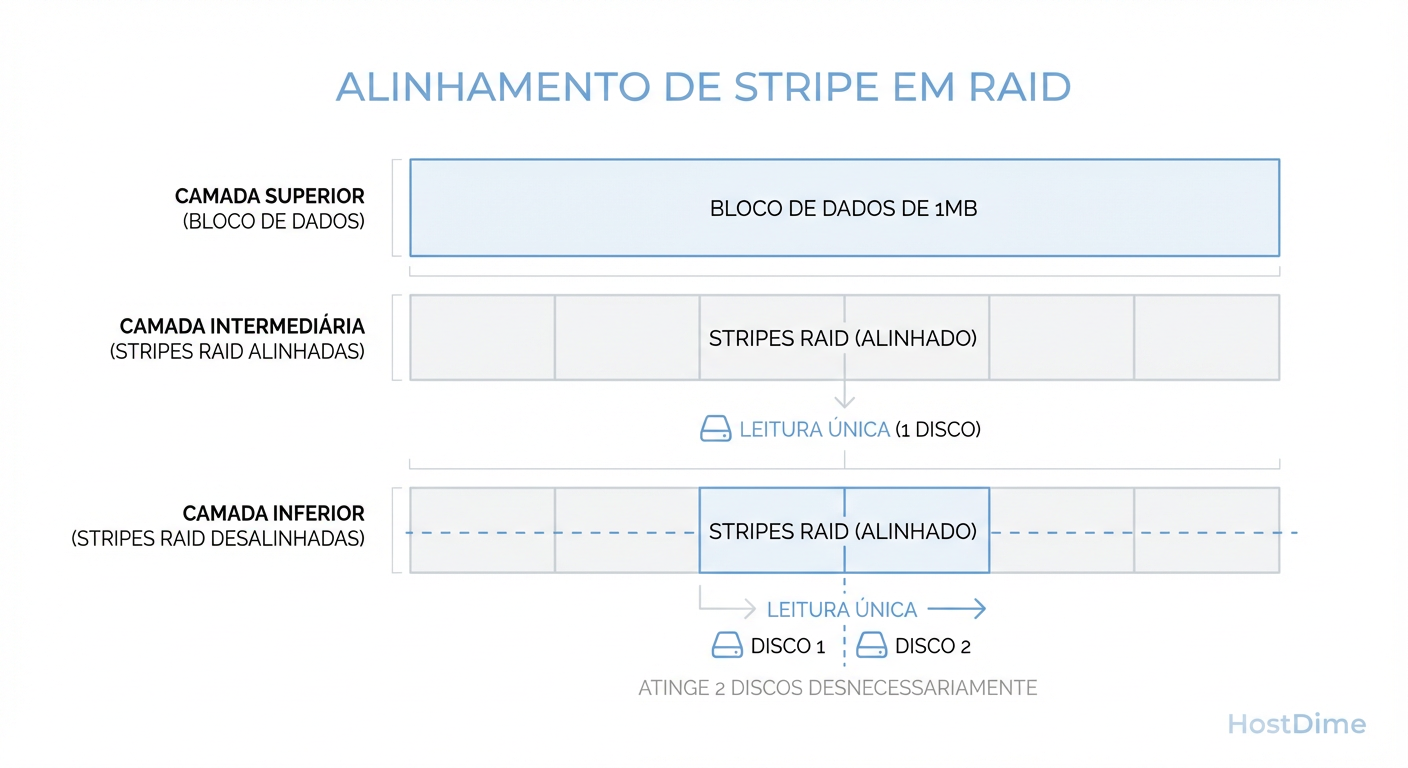 Figura: O impacto do desalinhamento de Stripe: Se seu chunk de leitura cruza a fronteira do disco, você dobra o trabalho mecânico/elétrico para o mesmo dado.
Figura: O impacto do desalinhamento de Stripe: Se seu chunk de leitura cruza a fronteira do disco, você dobra o trabalho mecânico/elétrico para o mesmo dado.
Se o seu DataLoader pede 128KB de dados, mas isso está espalhado em dois chunks de 64KB que cruzam a fronteira de dois discos físicos, você acabou de dobrar o número de comandos enviados ao barramento para ler o mesmo dado.
A regra de ouro: Configure o stripe size grande para ML. Algo entre 256KB e 1MB costuma ser o "sweet spot". Você quer que uma leitura de arquivo seja servida pelo menor número de discos possível para deixar os outros discos livres para servirem outras threads do DataLoader simultaneamente.
Por que RAID 5 e 6 Matam a Performance de NVMe em ML
Se você está usando HDDs mecânicos (spinners) para seu dataset de treinamento quente ("hot tier"), você já perdeu o jogo. Assumindo que você está usando NVMe, o RAID 5 ou 6 é uma armadilha matemática.
RAID 5 e 6 exigem cálculos de paridade (XOR para RAID 5, Polinômios de Reed-Solomon para RAID 6). Antigamente, placas RAID dedicadas faziam isso. Hoje, com NVMe, a latência do disco é tão baixa (microssegundos) que enviar o dado para uma placa RAID externa e voltar é mais lento do que o próprio disco.
Então fazemos RAID via Software (CPU).
O problema: Um único NVMe Gen4 pode ler a 7.000 MB/s. Quatro deles em RAID 5 leem teoricamente a 21.000 MB/s (n-1). Mas sua CPU consegue calcular checksums de paridade para 21 GB de dados por segundo enquanto também faz o pré-processamento das imagens e alimenta a GPU?
A resposta curta é não.
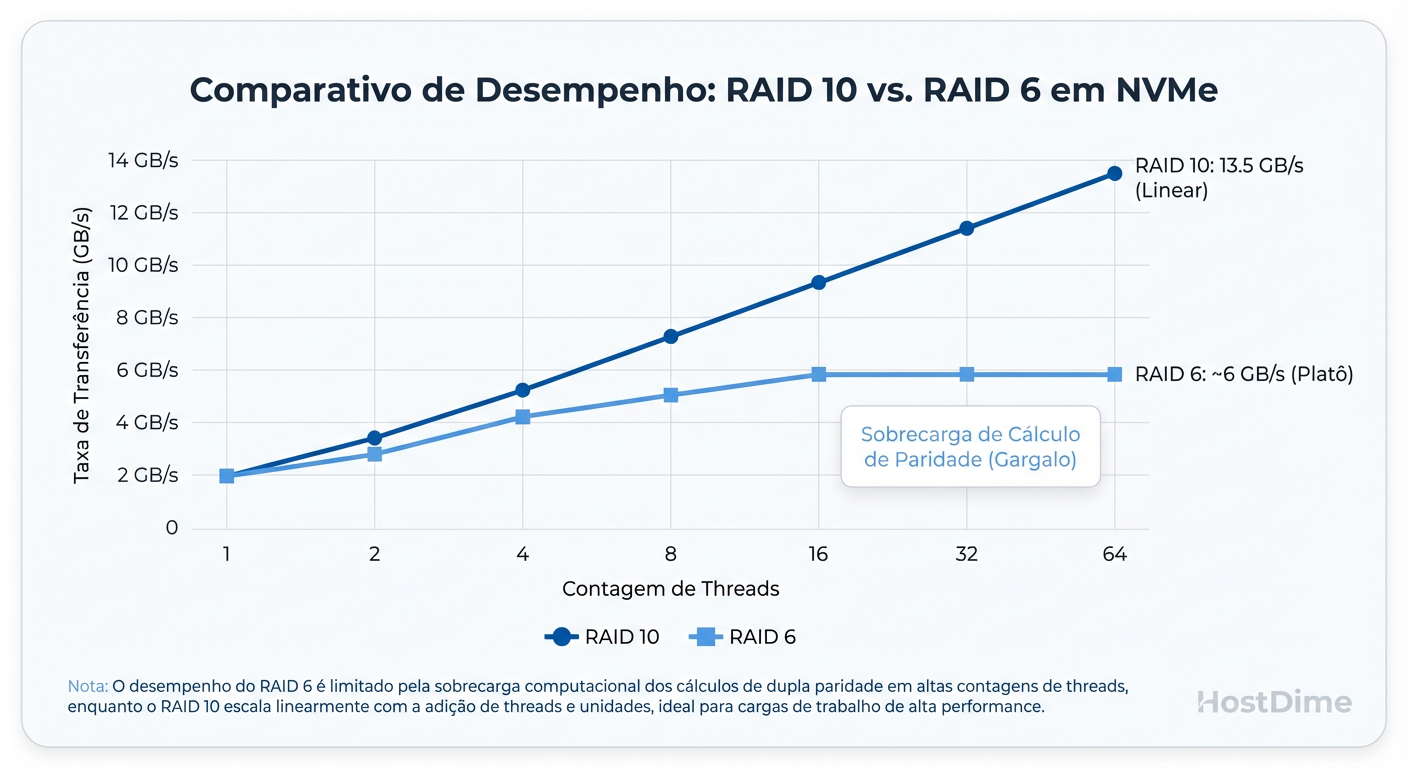 Figura: A Parede de Paridade em NVMe: CPUs modernas engasgam calculando checksums de RAID 5/6 antes de saturarem a banda dos SSDs.
Figura: A Parede de Paridade em NVMe: CPUs modernas engasgam calculando checksums de RAID 5/6 antes de saturarem a banda dos SSDs.
Você atinge a "Parede de Paridade" muito antes de atingir o limite dos SSDs. Para ML de alta performance, a paridade é um imposto que você não pode pagar.
Tabela Comparativa: Escolhendo o Nível de RAID para ML
| Característica | RAID 0 | RAID 10 | RAID 5 / 6 (ZRAID Z1/Z2) |
|---|---|---|---|
| Custo por TB | Baixo (100% útil) | Alto (50% útil) | Médio (67-80% útil) |
| Throughput Leitura | Máximo (Soma de todos) | Alto (Soma de todos) | Limitado pela CPU (Parity Calc) |
| Throughput Escrita | Máximo | Médio (2x escritas) | Péssimo (Read-Modify-Write) |
| Risco de Falha | Suicida (1 falha = perda total) | Seguro (Até 1 falha por par) | Seguro (1 ou 2 discos) |
| Veredito para ML | Apenas para cache local descartável. | Padrão Ouro para produção. | Evite para Hot Tier NVMe. |
Callout de Risco: Se o seu dataset existe apenas no servidor de treino, NÃO USE RAID 0. RAID 0 é aceitável apenas se o servidor for um nó de computação efêmero e os dados reais viverem em um Object Storage (S3) ou NAS central seguro. Se perder o RAID 0, você apenas baixa os dados novamente. Se não pode se dar a esse luxo, use RAID 10.
Tuning de Filesystem: Alinhamento no XFS e Recordsize no ZFS
O hardware é apenas a fundação. O sistema de arquivos é quem decide onde os bits morrem.
XFS: O Cavalo de Batalha
Para Linux e ML, XFS é geralmente a escolha segura. Mas o mkfs.xfs padrão é preguiçoso. Você precisa informar a ele a geometria do seu RAID subjacente.
Se você criou um RAID 0 de 4 discos com chunk de 256KB via mdadm, você deve formatar assim:
# sunit (stripe unit) = chunk size em blocos de 512b (256 * 1024 / 512 = 512)
# swidth (stripe width) = número de discos de dados * sunit (4 * 512 = 2048)
mkfs.xfs -d sunit=512,swidth=2048 /dev/md0
Se você não alinhar, o XFS pode tentar escrever metadados no meio de um chunk de dados, causando fragmentação e latência desnecessária.
ZFS: O Canivete Suíço (Com Cuidado)
ZFS é fantástico, mas seu recurso de Copy-on-Write (CoW) pode fragmentar arquivos se não for configurado. Para ML, o parâmetro crítico é o recordsize.
O padrão do ZFS é 128K. Se seus arquivos de treino são imagens de 1MB ou arquivos TFRecord de 100MB, o ZFS vai quebrá-los em pedaços de 128K. Isso aumenta a sobrecarga de metadados.
Para datasets com arquivos grandes, aumente o recordsize:
zfs set recordsize=1M poolname/dataset_ml
Nota: Isso também melhora a compressão (LZ4/ZSTD), pois o algoritmo tem blocos maiores para analisar redundância.
Gargalos de Hardware Além do Disco: PCIe Lanes e NUMA
Você comprou os NVMes mais rápidos, configurou RAID 0 e alinhou o XFS. Ainda está lento. Por quê?
PCIe Lane Starvation: CPUs de desktop (mesmo as Threadripper de entrada) ou servidores mal planejados têm limites de pistas PCIe. Se você tem 4 GPUs (x16 cada) e 4 NVMes (x4 cada), você precisa de 80 pistas PCIe. Se sua CPU só tem 64, algo vai operar em velocidade reduzida ou passar pelo Chipset (DMI bottleneck), que é um gargalo brutal.
NUMA (Non-Uniform Memory Access): Em servidores dual-socket, os discos conectados à CPU 1 são acessados "remotamente" pela CPU 2 através do link UPI/QPI.
- Se o processo de treinamento (Python) está rodando na CPU 2, mas os dados estão nos NVMes da CPU 1, você está saturando o link entre processadores.
- Solução: Use
numactlpara "pinnar" o processo de carregamento de dados na mesma CPU física onde estão os controladores PCIe dos discos.
Como Simular um Dataloader com FIO e Evitar Benchmarks Sintéticos
Não use dd. dd é single-threaded e sequencial puro, não reflete a realidade.
Não use CrystalDiskMark. Ele é otimizado para Windows e cargas de desktop.
Para simular um DataLoader de Deep Learning, precisamos de:
Leituras sequenciais pesadas (mas com múltiplos arquivos).
Múltiplas threads (num_workers > 0).
Queue Depth moderado.
Buffer de I/O (Direct=0 ou 1 dependendo de como o framework carrega, geralmente usamos direct=1 para testar o disco cru).
Aqui está o comando fio que separa a verdade do marketing:
# Simulação de Dataloader ML
# - rw=read: Leitura sequencial (maioria dos datasets)
# - bs=1M: Tamanho do bloco simulando imagens grandes ou chunks de tensores
# - numjobs=8: Simula num_workers=8 no PyTorch
# - iodepth=4: Profundidade da fila por worker
# - size=10G: Tamanho do teste por thread
fio --name=ml_simulation \
--ioengine=libaio \
--rw=read \
--bs=1M \
--direct=1 \
--numjobs=8 \
--iodepth=4 \
--size=10G \
--runtime=60 \
--group_reporting \
--filename=/mnt/raid_ml/testfile
O que observar no resultado:
Olhe para a linha bw= (Bandwidth). Se a soma for inferior à velocidade de gravação da sua GPU (uma A100 pode engolir dados a 4-5GB/s facilmente dependendo do modelo), você tem um gargalo. Se a latência (clat) pular para milissegundos, seus discos estão engasgando com o paralelismo.
Veredito Técnico Pragmática
Não existe mágica. Alimentar GPUs é um problema de encanamento.
Evite paridade (RAID 5/6) em NVMe.
Alinhe seu stripe size com seus dados (grandes).
Meça com
fio, não confie na caixa do fabricante.
Se você seguir isso, o único barulho no seu data center será o das ventoinhas das GPUs rodando a 100%, exatamente como deve ser.
Referências & Leitura Complementar
NVIDIA Data Loading Best Practices: Documentação técnica sobre gargalos de Dataloader em PyTorch/TensorFlow.
xfs(5) Man Page: Documentação oficial sobre geometria de stripe (
sunit/swidth).RFC 3514 (Fictícia/Humor): Apenas para lembrar que nem todo pacote (ou I/O) é benigno, monitore sua rede também.
ZFS on Linux - Workload Tuning: Guia oficial do projeto OpenZFS para tuning de
recordsize.

Dr. Marcus 'Bitrot' Silva
Engenheiro Sênior de Armazenamento
20 anos recuperando RAIDs quebrados. Especialista em ZFS e sistemas de arquivos distribuídos. Já viu mais falhas de disco do que gostaria.