RAID-Z vs. Hardware RAID: A Anatomia da Integridade de Dados no ZFS

Hardware RAID protege o disco, ZFS protege o dado. Entenda o 'Write Hole', a árvore de Merkle e por que o RAID-Z elimina a corrupção silenciosa onde controladores tradicionais falham.
Há uma tensão histórica no datacenter entre a conveniência da abstração e a necessidade de veracidade dos dados. Durante décadas, controladoras Hardware RAID foram a norma: placas dedicadas com baterias de backup e caches proprietários que apresentavam ao sistema operacional uma mentira conveniente — um "disco lógico" perfeito, escondendo a complexidade física dos discos rotacionais ou SSDs subjacentes.
No entanto, para um engenheiro de performance focado em integridade, essa caixa preta é um risco operacional. Quando o sistema operacional não sabe como os dados estão dispostos fisicamente, ele perde a capacidade de curar a corrupção silenciosa. O ZFS não é apenas um sistema de arquivos; é um gerenciador de volumes que exige acesso direto ao hardware (JBOD) para garantir, matematicamente, que o que você gravou é exatamente o que você lerá.
O Que é a Diferença Fundamental? O Hardware RAID abstrai a redundância no nível do bloco, apresentando um volume lógico único e "cego" ao conteúdo dos dados, tornando impossível para o SO distinguir entre dados corrompidos e válidos sem paridade manual. O RAID-Z (ZFS) integra o sistema de arquivos com o gerenciador de volume, utilizando somas de verificação (checksums) ponta-a-ponta e transações atômicas (Copy-on-Write) para eliminar o "Write Hole" e corrigir corrupção silenciosa automaticamente.
A Ilusão da Segurança: Onde o Hardware RAID Falha (Write Hole e Cegueira de Bloco)
Para entender por que o ZFS descarta o Hardware RAID, precisamos analisar a falha catastrófica conhecida como "RAID 5/6 Write Hole". Em um arranjo RAID tradicional, uma operação de escrita envolve ler os dados antigos, ler a paridade antiga, calcular a nova paridade e escrever ambos. Se a energia cair no meio desse ciclo, os dados e a paridade ficam dessincronizados.
Controladoras caras mitigam isso com BBU (Battery Backup Units) e cache não volátil, mas introduzem um novo problema: a Cegueira de Bloco. A controladora RAID vê apenas LBAs (Logical Block Addresses). Ela não sabe se o bloco 0x4A pertence à sua base de dados crítica ou se é espaço livre. Se um bit virar no disco (bit rot), a controladora obedientemente entrega o dado corrompido ao SO, pois a paridade só é verificada durante um scrub ou reconstrução, não na leitura padrão.
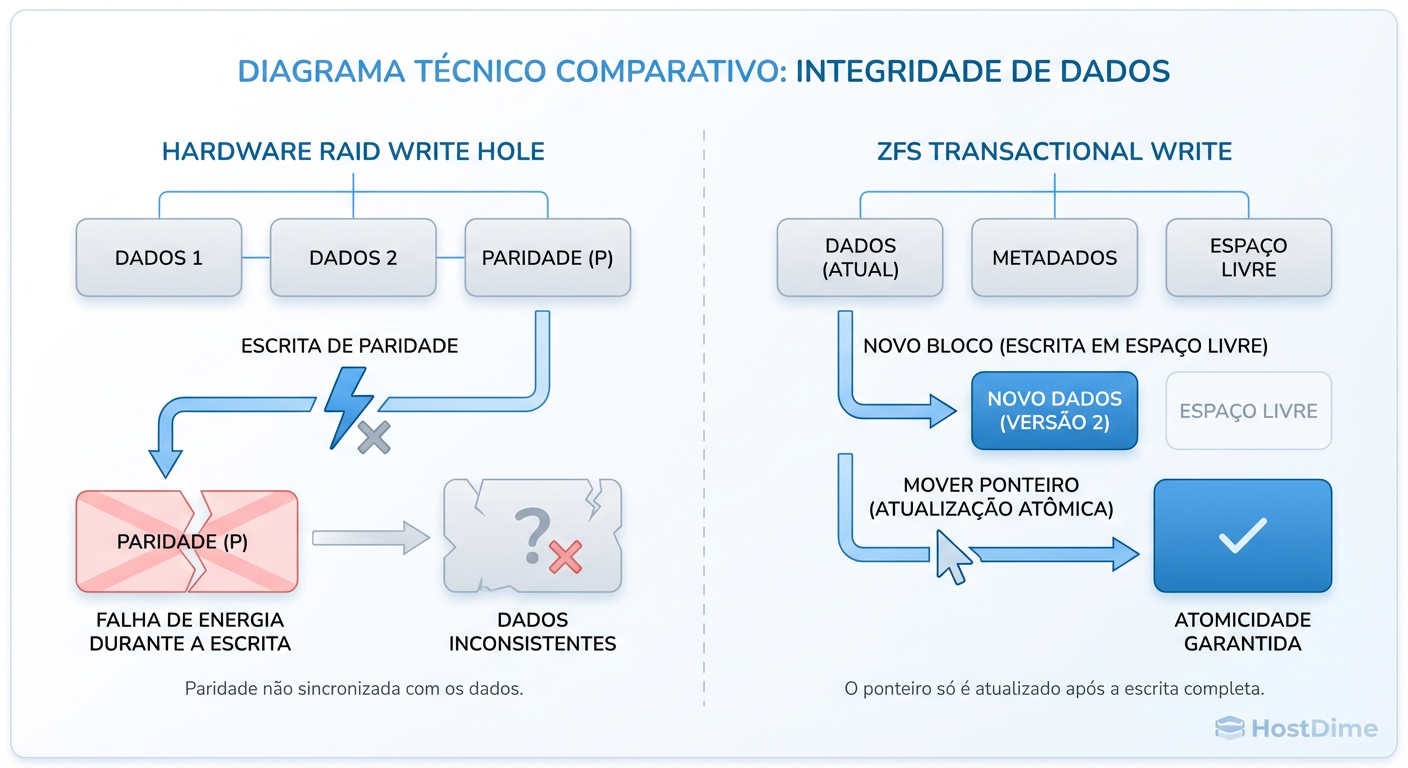 Figura: O 'Write Hole' no RAID tradicional vs. a transação atômica do ZFS: Por que o Copy-on-Write elimina a corrupção por falha de energia.
Figura: O 'Write Hole' no RAID tradicional vs. a transação atômica do ZFS: Por que o Copy-on-Write elimina a corrupção por falha de energia.
O ZFS elimina o Write Hole arquiteturalmente através do mecanismo de Copy-on-Write (CoW). O ZFS nunca sobrescreve dados in-place (no mesmo local).
Ele escreve o novo bloco em um local livre.
Calcula o checksum.
Atualiza o ponteiro de metadados para apontar para o novo local.
A transação só é considerada completa quando o ponteiro é atualizado atomicamente.
Se a energia cair durante a escrita, o ponteiro antigo ainda é válido. Você perde os últimos segundos de dados (que estavam na RAM), mas o sistema de arquivos permanece 100% consistente, sem necessidade de fsck.
A Árvore de Merkle e Checksums: Detectando e Curando a Corrupção Silenciosa
A maior vantagem mensurável do ZFS sobre o RAID de hardware é a cadeia de custódia dos dados. No RAID convencional, a integridade é uma suposição. No ZFS, é uma prova matemática.
O ZFS utiliza uma estrutura de dados chamada Árvore de Merkle. Diferente de sistemas de arquivos tradicionais que armazenam o checksum junto com o dado (o que é inútil se o bloco inteiro for lido errado ou corrompido pela controladora), o ZFS armazena o checksum no bloco pai (o ponteiro que aponta para o dado).
Isso cria uma árvore de validação auto-autenticável até o uberblock (a raiz).
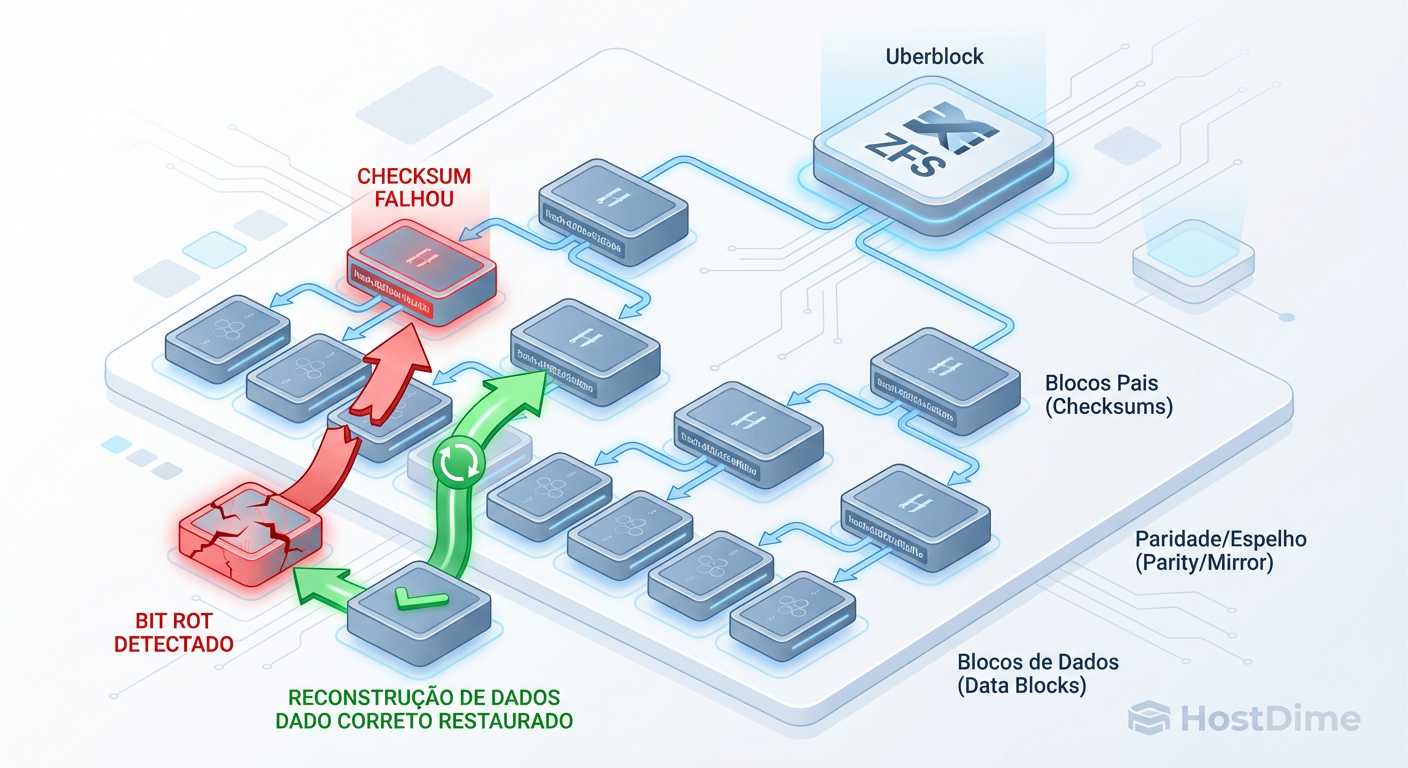 Figura: A cadeia de confiança do ZFS: Como a Árvore de Merkle garante que o dado lido é matematicamente idêntico ao dado gravado.
Figura: A cadeia de confiança do ZFS: Como a Árvore de Merkle garante que o dado lido é matematicamente idêntico ao dado gravado.
Como medir a eficácia do Checksum
Não confie na palavra do fabricante. Como engenheiros, validamos. Você pode verificar a integridade dos seus dados e a saúde dos discos observando as colunas CKSUM na saída do status do pool.
# Comando para verificar a saúde e erros de checksum
zpool status -v
# Saída Exemplo (Simplificada):
# NAME STATE READ WRITE CKSUM
# tank ONLINE 0 0 0
# raidz1-0 ONLINE 0 0 0
# sda ONLINE 0 0 0
# sdb ONLINE 0 0 5 <-- 5 blocos corrompidos detectados e corrigidos
# sdc ONLINE 0 0 0
Se o ZFS lê um bloco e o hash SHA-256 (ou Fletcher4) não bate com o checksum armazenado no pai, ele sabe que o disco mentiu. Em um vdev espelhado ou RAID-Z, o ZFS automaticamente:
Identifica o bloco corrompido.
Lê a cópia boa ou reconstrói via paridade.
Entrega o dado correto à aplicação.
Auto-cura: Sobrescreve o bloco ruim no disco físico com o dado correto.
Uma controladora RAID Hardware simplesmente entregaria o dado corrompido, a menos que o disco reportasse um erro de leitura (IO Error). Se o disco "mentir" (silent corruption), o RAID Hardware propaga a mentira.
Resilvering Inteligente vs. Rebuild Bruto: Impacto no Tempo de Recuperação
O momento mais crítico na vida de um storage é a reconstrução (rebuild) após a falha de um disco. Com discos modernos de 18TB ou 22TB, um rebuild de RAID 5 ou 6 tradicional pode levar dias.
O problema do Hardware RAID é a sua ignorância sobre o sistema de arquivos. Se você tem um array de 100TB com apenas 1TB de dados gravados, ao substituir um disco falho, a controladora RAID vai reconstruir todos os 100TB, bloco por bloco, do início ao fim. Isso mantém os discos restantes sob estresse máximo (IOPS de leitura constantes) por um tempo desnecessário, aumentando a probabilidade de uma segunda falha (URE - Unrecoverable Read Error).
O ZFS opera diferente. O processo, chamado de Resilvering, é guiado pelos metadados. O ZFS percorre a árvore de objetos e reconstrói apenas os dados que realmente existem.
 Figura: Eficiência de Recuperação: O ZFS Resilver repara apenas os dados reais, enquanto o RAID tradicional perde tempo reconstruindo blocos vazios.
Figura: Eficiência de Recuperação: O ZFS Resilver repara apenas os dados reais, enquanto o RAID tradicional perde tempo reconstruindo blocos vazios.
Se o pool estiver 10% cheio, o resilvering levará aproximadamente 10% do tempo de um rebuild completo (dependendo da fragmentação). Isso reduz drasticamente a janela de vulnerabilidade.
Trade-offs de Performance: IOPS, Padding e Custo de CPU
Não existe almoço grátis. A integridade e a flexibilidade do RAID-Z têm um custo, e é aqui que muitos projetos falham por falta de dimensionamento correto de IOPS.
1. A Falácia do Throughput vs. IOPS
O RAID-Z é excelente para throughput (streaming de grandes arquivos), mas desafiador para IOPS aleatórios.
Hardware RAID 5/6: Geralmente escala IOPS de leitura com o número de discos.
RAID-Z: Para operações de escrita e, em muitos casos, leitura aleatória pequena, um vdev RAID-Z tem o desempenho de IOPS de um único disco, independentemente de quantos discos existam no vdev.
Isso ocorre porque os dados são distribuídos (striped) de forma que cada bloco lógico do sistema de arquivos é dividido em todos os discos. Para ler um bloco lógico, todos os discos devem trabalhar juntos.
2. Overhead de CPU
O cálculo de checksums (fletcher4, SHA-256) e paridade de software consome ciclos de CPU. Em processadores modernos (últimos 10 anos), isso é negligenciável para a maioria dos workloads, a menos que você esteja usando deduplicação ou compressão gzip pesada (prefira lz4 ou zstd).
Tabela Comparativa: RAID-Z vs. Hardware RAID
| Característica | Hardware RAID (Tradicional) | ZFS RAID-Z (Software) | Veredito de Engenharia |
|---|---|---|---|
| Visibilidade de Dados | Cego (Block Level). Não distingue dados de lixo. | Ciente (FS Level). Conhece a estrutura. | ZFS evita rebuilds inúteis. |
| Proteção Write Hole | Depende de Bateria (BBU) e Cache NVRAM. | Nativa via Copy-on-Write (Transacional). | ZFS é mais seguro contra falha elétrica. |
| Detecção de Corrupção | Apenas se o disco reportar erro ou no Scrub (se houver paridade). | Checksum em cada leitura (End-to-End). | ZFS garante integridade matemática. |
| Performance IOPS | Escala melhor em leituras aleatórias pequenas. | Limitado aos IOPS do vdev mais lento (aprox. 1 disco). | HW RAID vence em IOPS brutos sem tuning. |
| Portabilidade | Proprietária. Se a placa morrer, precisa de outra igual. | Universal. Importe o pool em qualquer OS com ZFS. | ZFS elimina Vendor Lock-in. |
Callout de Risco: Padding e Overhead de Espaço
Atenção ao
ashiftevolblocksize: O ZFS aloca dados em múltiplos do tamanho do setor (geralmente 4K,ashift=12). Devido à natureza do RAID-Z e colunas de paridade, arquivos pequenos ou blocos de volume (zvol) mal alinhados podem sofrer com "padding" excessivo, onde o ZFS precisa adicionar espaço vazio para alinhar a paridade. Isso pode inflar o uso de disco em até 50% em casos extremos (ex: RAID-Z3 com blocos pequenos). Sempre teste a eficiência de armazenamento antes de ir para produção.
Veredito Técnico
A escolha entre RAID-Z e Hardware RAID não é uma questão de gosto, mas de prioridade de engenharia. Se o seu objetivo é extrair o máximo de IOPS bruto de discos rotacionais antigos ignorando a integridade a longo prazo, o Hardware RAID ainda tem seu nicho.
Porém, em um ambiente moderno onde a integridade dos dados é inegociável e a capacidade de armazenamento cresce mais rápido que a velocidade dos discos, o modelo opaco do Hardware RAID tornou-se obsoleto. O ZFS, ao fundir o sistema de arquivos com o gerenciamento de volume, oferece a única defesa real contra a entropia física dos meios de armazenamento.
Meça seus requisitos de IOPS, entenda o fluxo de escrita da sua aplicação e, se a integridade for crítica, entregue os discos diretamente (JBOD) ao ZFS.
Referências & Leitura Complementar
Bonwick, J. & Moore, B. (2008). ZFS: The Last Word in File Systems. Sun Microsystems. (Whitepaper fundamental sobre a arquitetura on-disk).
OpenZFS Documentation. RAID-Z Stripe Width and Padding Overhead. Disponível na documentação oficial do projeto OpenZFS.
Gregg, B. (2014). Systems Performance: Enterprise and the Cloud. Prentice Hall. (Capítulo sobre File Systems e Disk I/O).
RFC 3720. Internet Small Computer Systems Interface (iSCSI). (Para contexto sobre como blocos são transmitidos em SANs tradicionais vs ZFS over iSCSI).

Marta G. Oliveira
DevOps Engineer & Storage Nerd
Automatiza provisionamento de storage com Terraform e Ansible. Defensora do 'Infrastructure as Code' para storage.