Rdma O Que E E Quando Faz Sentido
Para entender por que precisamos do RDMA, precisamos primeiro dissecar a ineficiência brutal de uma transferência de rede convencional....
Rdma O Que E E Quando Faz Sentido
O Custo Invisível do "Bom e Velho" TCP
Para entender por que precisamos do RDMA, precisamos primeiro dissecar a ineficiência brutal de uma transferência de rede convencional.
Imagine que uma aplicação (digamos, um banco de dados Redis ou um treino de IA distribuído) quer enviar um buffer de dados para outro servidor. No modelo clássico de Sockets (TCP/IP), o fluxo é burocrático:
- User Space: A aplicação chama
send(). - Context Switch: A CPU para a aplicação e muda para o modo Kernel.
- Copy #1: O Kernel copia os dados do buffer da aplicação para um buffer interno do Kernel (sk_buff).
- Protocol Processing: O Kernel calcula checksums, adiciona cabeçalhos TCP, cabeçalhos IP, consulta tabelas de roteamento e aplica regras de firewall (iptables/nftables).
- Driver: O driver da NIC pega esse pacote.
- DMA: A NIC lê o pacote da RAM via DMA e o coloca no fio.
No lado do receptor, o processo inverso acontece, gerando uma interrupção na CPU para cada pacote (ou grupo deles) que chega.
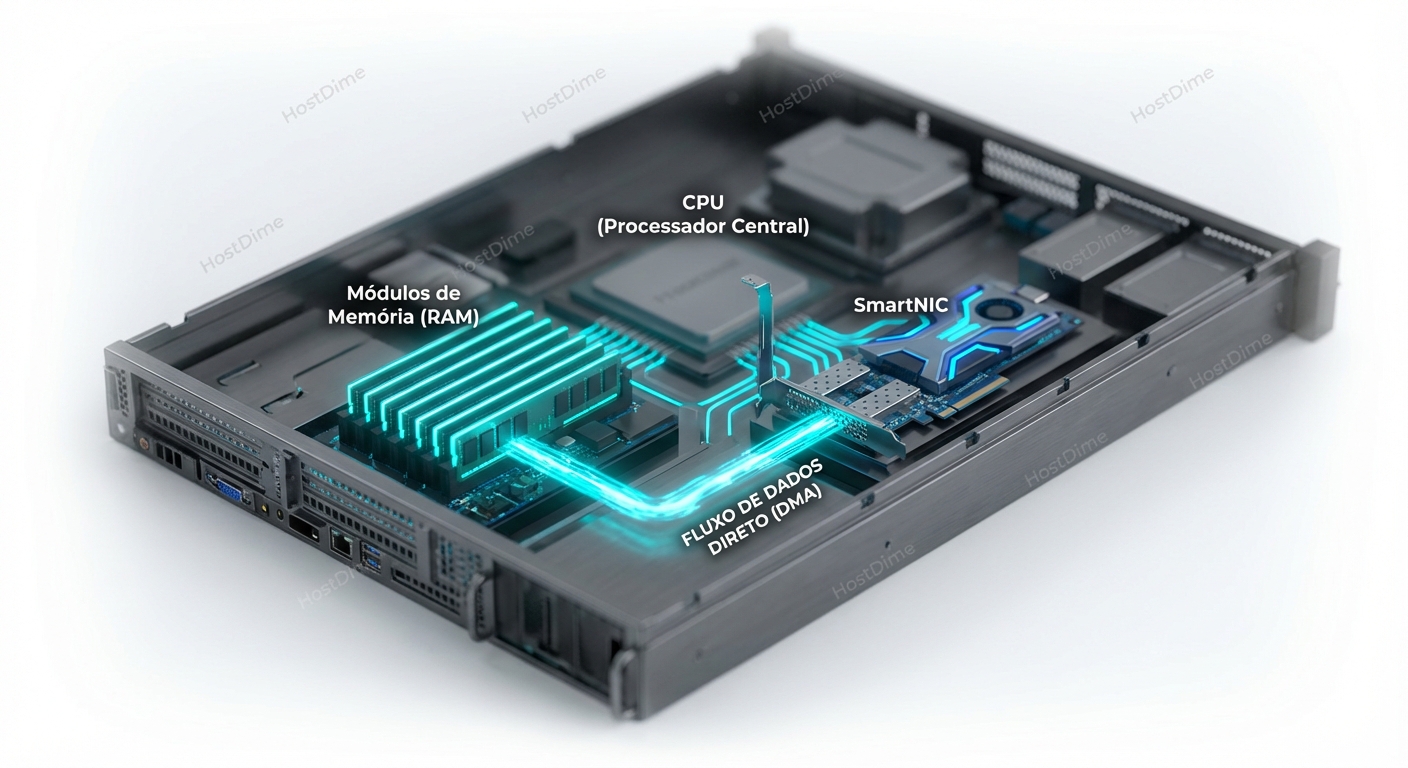
Essa "dança" consome ciclos de CPU preciosos apenas para mover bits de A para B. Em 10Gbps, isso é gerenciável. Em 100Gbps ou 400Gbps, a CPU se torna um roteador glorificado, sem tempo para processar a lógica de negócio real.
O Modelo Mental do RDMA: Teletransporte de Memória
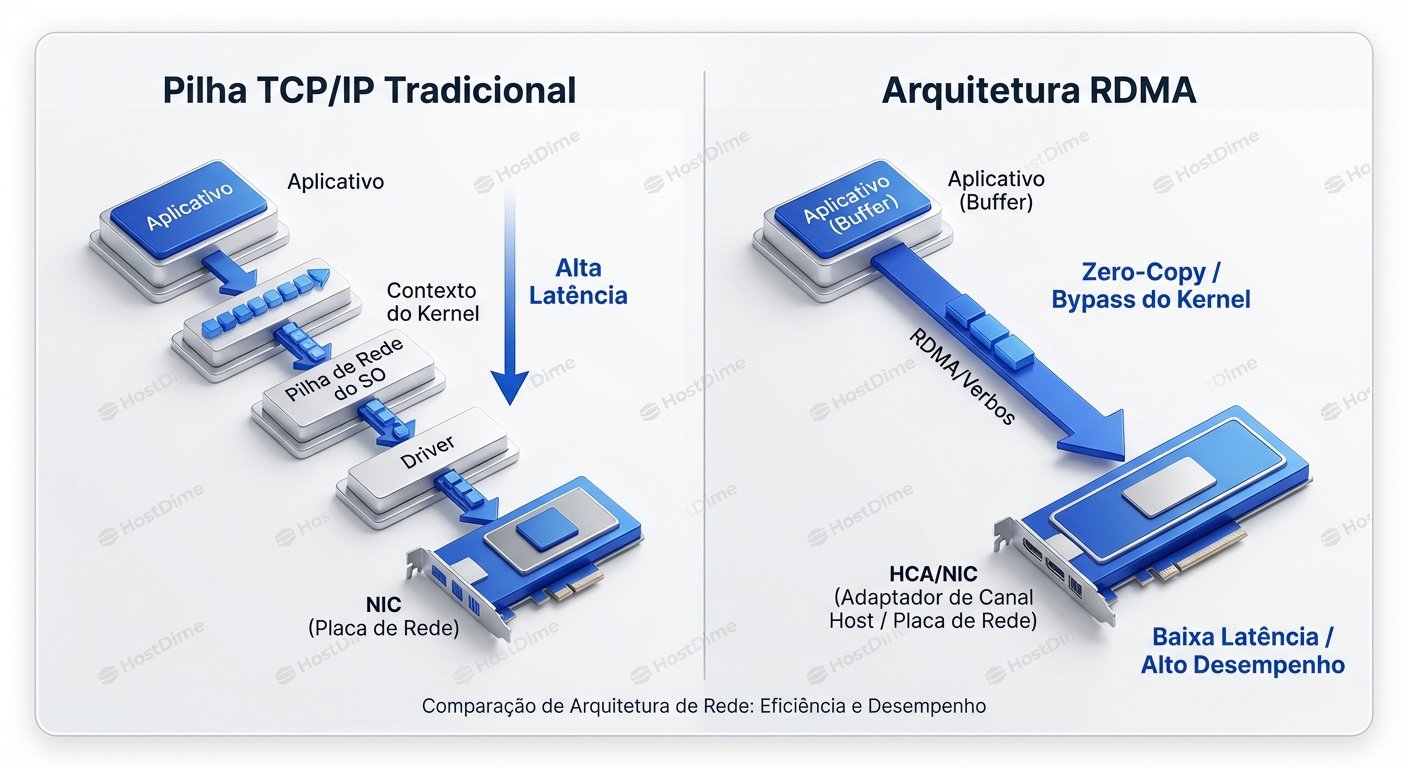
Esqueça sockets. Esqueça streams de bytes. O modelo mental correto para RDMA é memória compartilhada à distância.
No RDMA, a aplicação diz à placa de rede (chamada aqui de HCA - Host Channel Adapter): "Aqui está o endereço de memória X contendo meus dados. Coloque-os diretamente no endereço de memória Y daquele servidor remoto."
O que acontece depois é a mágica do Kernel Bypass (Zero-Copy):
- A aplicação fala diretamente com o hardware da NIC (via userspace driver/library).
- Não há cópia para buffers do Kernel.
- Não há processamento de TCP/IP pela CPU do host.
- A NIC lê a memória da aplicação (DMA) e a NIC remota escreve na memória da aplicação remota (DMA).
A CPU do host remoto nem sequer sabe que a transferência aconteceu até que ela seja concluída. É como se a memória tivesse sido teletransportada. O resultado? Latências na casa de microssegundos de um dígito (vs dezenas ou centenas no TCP) e uso de CPU próximo de zero para a transferência.
O Ecossistema de Protocolos: Onde o RoCE se encaixa
O RDMA nasceu no mundo da Computação de Alto Desempenho (HPC) com o InfiniBand. O InfiniBand é fantástico: é uma tecnologia desenhada do zero para ser lossless (sem perda de pacotes), com latência ultra-baixa e controle de fluxo baseado em créditos no hardware.
O problema do InfiniBand? Ele exige switches InfiniBand, cabos InfiniBand e administradores que entendam InfiniBand (Subnet Managers, LIDs, GIDs). É uma ilha isolada no seu data center Ethernet.
Para trazer os benefícios do RDMA para o mundo Ethernet (que já temos e pagamos caro), a indústria criou o RoCE (RDMA over Converged Ethernet) e o iWARP.
Vamos descartar o iWARP rapidamente: ele implementa RDMA sobre TCP. É mais fácil de implementar na rede (funciona em qualquer lugar), mas a complexidade do TCP no hardware da NIC torna as placas mais caras e a latência é maior. O mercado, especialmente em IA e Storage, convergiu massivamente para o RoCE.
Aqui está a topologia atual:
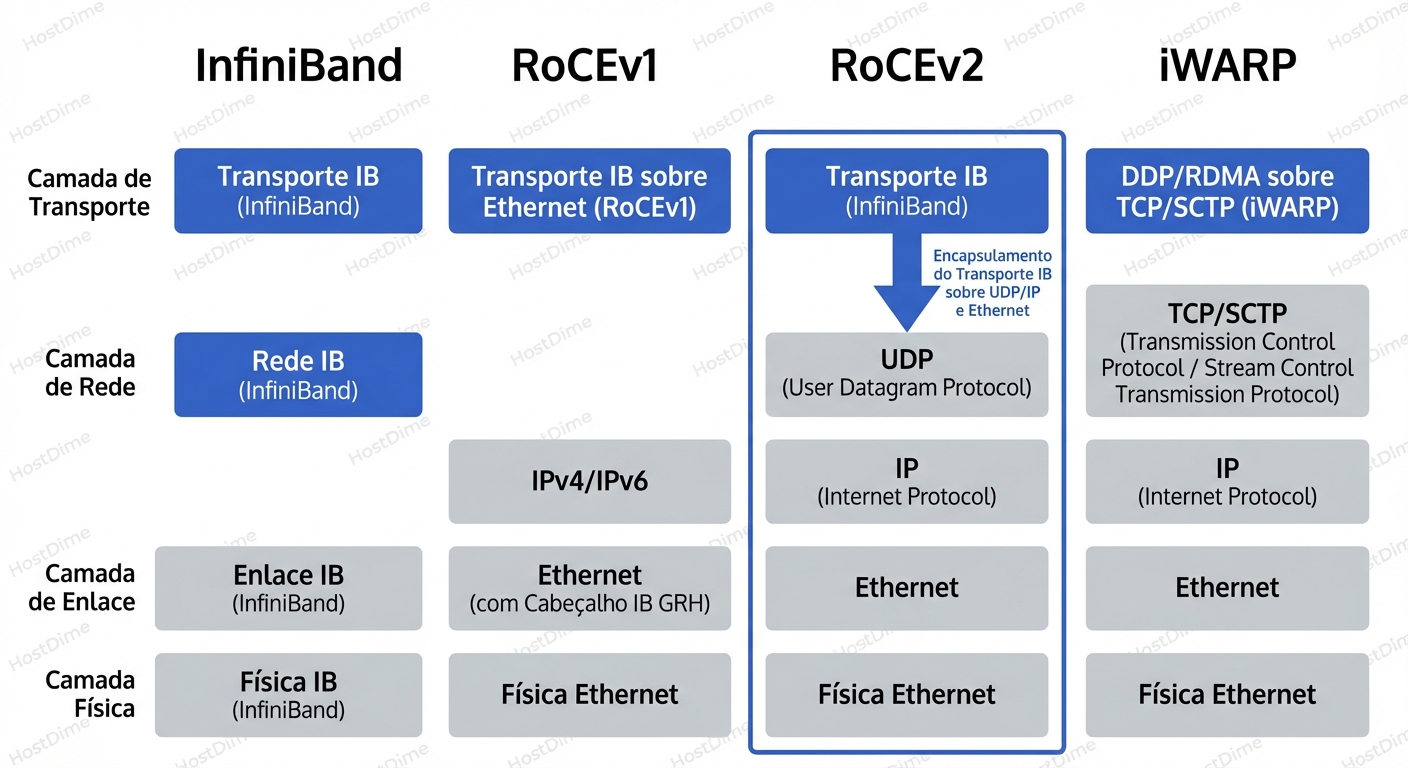
RoCEv1 vs. RoCEv2
- RoCEv1: Era apenas um protocolo de Camada 2 (Ethernet). Os pacotes não tinham cabeçalho IP. Isso significava que você não podia rotear o tráfego. O servidor de envio e o de recebimento precisavam estar na mesma VLAN/Subnet. Limitado e praticamente obsoleto.
- RoCEv2 (O Padrão de Ouro Atual): Encapsula o pacote InfiniBand dentro de um cabeçalho UDP/IP.
- Isso torna o pacote roteável (Layer 3). Você pode fazer RDMA entre racks diferentes, passando por roteadores Spine/Leaf.
- Usa a porta UDP de destino 4791.
- O cabeçalho UDP é usado para hash de ECMP (Equal-Cost Multi-Path), permitindo balanceamento de carga eficiente nos switches.
A Pegadinha: Lossless Ethernet e a Complexidade Operacional
Se o RDMA é tão incrível, por que não o usamos para tudo, desde HTTP até SSH?
Porque o RDMA (especificamente a camada de transporte InfiniBand que vive dentro do RoCE) é intolerante à perda de pacotes.
No TCP, se um pacote se perde, o protocolo diz: "Tudo bem, vamos esperar um pouco e retransmitir. Reduza a velocidade." No RDMA, se um pacote se perde, o impacto na performance é catastrófico. O hardware precisa parar, voltar atrás (Go-Back-N) e retransmitir. O throughput despenca.
Para o RoCEv2 funcionar bem, precisamos transformar nossa rede Ethernet "best-effort" (onde perder pacotes é normal) em uma rede Lossless. Isso exige configurar três coisas no seu switch e nos hosts:
PFC (Priority Flow Control - 802.1Qbb): Imagine que o buffer do switch está enchendo. Em vez de descartar o pacote (drop), o switch envia um sinal de "PAUSE" para o remetente, especificamente para aquela classe de tráfego. "Pare de enviar dados da fila RDMA por X microssegundos, mas continue enviando o tráfego SSH/Web."
- O Perigo: Se mal configurado, isso pode gerar o temido "PFC Storm" ou "Head-of-Line Blocking", onde um servidor lento trava a rede inteira propagando pausas para trás até a fonte.
ECN (Explicit Congestion Notification): Antes de chegar ao ponto de precisar pausar (PFC), usamos o ECN. O switch marca os pacotes IP com um bit de "Congestion Experienced" (CE) quando os buffers começam a encher. A NIC receptora vê isso e avisa a NIC remetente para reduzir a taxa de transmissão proativamente. É a maneira "educada" de evitar congestionamento.
DCB (Data Center Bridging): É o protocolo de negociação que garante que switches e placas de rede concordem sobre quais filas são prioritárias e lossless.
A Realidade do Sysadmin: Configurar RoCEv2 não é apenas instalar um driver. É garantir que o mapeamento de prioridades (CoS/DSCP) esteja alinhado end-to-end: Aplicação -> Driver -> NIC -> Cabo -> Switch Port -> Switch Buffer -> Switch Uplink -> ... -> Destino. Se um elo falhar, você terá performance pior que o TCP.
Diagnosticando e Observando: O Que Procurar
Como saber se o RDMA está funcionando ou se você apenas tem uma placa cara rodando em modo de compatibilidade?
1. Verificando a Camada Física e Link
No Linux, as interfaces RDMA vivem separadas das interfaces de rede normais (eth0). Elas geralmente são mlx5_0, hfi1_0, etc.
$ ibdev2netdev
mlx5_0 port 1 ==> ens785f0 (Up)
mlx5_1 port 1 ==> ens785f1 (Up)
# Verifique o estado do link RDMA
$ ibv_devinfo -d mlx5_0
hca_id: mlx5_0
transport: InfiniBand (0)
fw_ver: 16.32.1010
node_guid: e41d:2d03:00c5:xxxx
sys_image_guid: e41d:2d03:00c5:xxxx
vendor_id: 0x02c9
vendor_part_id: 4123
hw_ver: 0x0
phys_port_cnt: 1
port: 1
state: PORT_ACTIVE (4)
max_mtu: 4096 (5)
active_mtu: 4096 (5)
sm_lid: 0
port_lid: 0
port_lmc: 0x00
link_layer: Ethernet
O que olhar: state: PORT_ACTIVE e link_layer: Ethernet (para RoCE). Se o MTU estiver baixo (ex: 1024), sua performance será sofrível. O ideal para RoCE é MTU 4200 ou Jumbo Frames (9000).
2. Teste de Fogo: Bandwidth e Latência
Não use iperf para testar RDMA. O iperf testa TCP/IP (a menos que use forks específicos). Use a suite perftest (pacote perftest ou infiniband-diags).
No servidor (Receiver):
ib_write_bw -d mlx5_0
No cliente (Sender):
ib_write_bw -d mlx5_0 <IP_DO_SERVER>
O que interpretar:
- Olhe a linha de
BW average. Está próxima da velocidade da linha (ex: 96Gbps em um link de 100Gbps)? - Olhe
MsgRate(Mensagens por segundo). RDMA brilha em pacotes pequenos. - Para latência, use
ib_write_lat. Você deve ver números em microssegundos (us). Se vir milissegundos, algo está errado (provavelmente fallback para TCP ou congestionamento).
3. O Diagnóstico de "Perigo": Contadores de Erro
Aqui é onde separamos os amadores dos profissionais. Use ethtool -S na interface Ethernet subjacente para ver o que está acontecendo no nível do RoCE.
ethtool -S ens785f0 | grep -E "prio[0-9]_pause|discard|drop"
| Contador | O que significa | Veredito |
|---|---|---|
rx_discards_phy |
O buffer da NIC encheu e ela dropou pacotes físicos. | CRÍTICO. Seu Flow Control (PFC) não está funcionando ou a CPU/PCIe não consegue drenar os dados rápido o suficiente. |
rx_prio3_pause_frames |
Número de vezes que a NIC pediu para o switch parar (recebeu pause). | Atenção. Um pouco é normal. Se incrementar milhões por segundo, você tem um gargalo downstream. |
tx_prio3_pause_frames |
Número de vezes que o switch mandou a NIC parar. | Atenção. A rede está congestionada. O ECN deveria estar atuando antes disso. |
rx_out_of_buffer |
Sem buffers de software para receber. | Geralmente indica que a aplicação não está postando buffers de recepção rápido o suficiente na fila (Receive Queue). |
Casos de Uso Reais: Onde o Esforço Paga a Conta
Configurar PFC/ECN é doloroso. Quando vale a pena?
1. Clusters de Treinamento de IA (GPU-Direct RDMA)
Em deep learning distribuído, as GPUs precisam trocar gradientes (gigabytes de dados) a cada iteração. Sem RDMA: GPU -> RAM do Host -> CPU -> NIC -> Rede -> NIC -> CPU -> RAM do Host -> GPU. Com GPUDirect RDMA: GPU -> NIC -> Rede -> NIC -> GPU. A latência cai drasticamente. Se você está construindo um cluster com H100s ou A100s, RoCEv2 não é opcional, é mandatório. O gargalo do treinamento é a rede.
2. NVMe over Fabrics (NVMe-oF)
Discos NVMe locais são rápidos (latência de ~80us). Acessar disco via rede (iSCSI tradicional) adiciona milissegundos. NVMe-oF via RDMA permite acessar um disco remoto com uma penalidade de latência de apenas ~10us adicionais. Isso permite a desagregação do storage: você pode ter um rack só de CPU/RAM e um rack só de Flash, e eles conversam como se estivessem conectados localmente via PCIe.
3. VMware vSAN / Microsoft Storage Spaces Direct (S2D)
Ambos dependem pesadamente de baixa latência para sincronização de metadados e escrita de dados. Habilitar RDMA nessas plataformas geralmente resulta em uma redução de 50% na utilização de CPU e um aumento de 2x nos IOPS.
O "Verbs" e a Programação (Para quem codifica)
Para o Sysadmin, é importante saber que a API não é socket(). A API é chamada de Verbs (libibverbs).
A lógica é baseada em Queue Pairs (QPs):
- Send Queue (SQ): Onde você coloca comandos de envio.
- Receive Queue (RQ): Onde você posta buffers vazios esperando dados chegarem.
- Completion Queue (CQ): Onde o hardware escreve "Terminei o trabalho X".
A aplicação não fica bloqueada esperando (blocking I/O). Ela posta trabalho na fila e vai fazer outra coisa, verificando a Completion Queue (polling) ou recebendo uma notificação (event) quando terminar. É assíncrono por natureza.
Veredito: A Complexidade Necessária
RDMA não é uma bala de prata para "acelerar a internet". Ele não vai fazer seu Nginx servir páginas estáticas mais rápido para usuários na WAN (a latência da internet mascara qualquer ganho).
O RDMA e o RoCE são tecnologias de Intra-Data Center (East-West traffic). Eles fazem sentido quando você controla as duas pontas da conexão e a infraestrutura de rede no meio.
Se você gerencia clusters de Kubernetes de alta performance, bancos de dados distribuídos (como ScyllaDB ou CockroachDB que suportam ou se beneficiam de baixa latência), Storage Ceph/MinIO, ou cargas de trabalho de IA, o RDMA é o caminho para desbloquear o desempenho pelo qual você pagou no hardware.
A troca é clara: você economiza CPU e ganha latência, mas paga com complexidade de configuração de rede. A rede deixa de ser um "tubo burro" e passa a ser parte integrante da coerência de memória do seu cluster.
Para aprofundar:
- Como configurar ECN e PFC em switches Arista/Mellanox/Cisco (cada vendor tem sua receita de bolo, e elas raramente são compatíveis por padrão).
- A diferença profunda entre RC (Reliable Connected) e UD (Unreliable Datagram) no nível dos Queue Pairs.
- Soft-RoCE (RXE): Como testar RDMA em VMs sem hardware dedicado (útil para dev/test, mas não para produção).

Marta G. Oliveira
DevOps Engineer & Storage Nerd
Automatiza provisionamento de storage com Terraform e Ansible. Defensora do 'Infrastructure as Code' para storage.