Recuperação de Dados em RAID Degradado: Estratégia Forense com ddrescue e TestDisk

Pare o rebuild agora. Aprenda a metodologia segura para clonar discos falhos com ddrescue e reconstruir arrays RAID logicamente antes de perder seus dados definitivamente.
O alarme soa às 03:00 da manhã. Não é um erro de log, é o LED laranja piscando no chassi do storage. O RAID está degradado. A reação instintiva do administrador de sistemas padrão é arrancar o disco morto, inserir um novo e rezar para o deus do rebuild.
Como investigador forense de sistemas, eu digo: pare. Essa reação é o equivalente digital a contaminar uma cena de crime. Se você iniciar um rebuild em um array que já demonstrou instabilidade, você não está consertando o problema; você está interrogando testemunhas hostis (os discos restantes) sob tortura.
Neste artigo, vamos dissecar a anatomia de um desastre de RAID e aplicar uma metodologia forense para extrair dados sem matar o paciente. Vamos trocar a esperança cega por ddrescue, losetup e TestDisk.
Recuperação forense em RAID degradado é o processo de clonar individualmente os discos membros para imagens bit-a-bit usando ferramentas tolerantes a falhas (ddrescue) antes de tentar qualquer reconstrução lógica, evitando assim o estresse mecânico que causaria a perda definitiva dos dados durante um rebuild automático.
Por que o Rebuild Automático em RAID Degradado é Perigoso
Existe um conceito fundamental que muitos ignoram: a correlação de falhas. Se você comprou seus discos no mesmo lote, eles têm a mesma idade, o mesmo firmware e sofreram a mesma vibração e temperatura por anos. Quando um falha, a probabilidade estatística de um segundo disco falhar nas próximas horas dispara.
O "Paradoxo do Rebuild" é simples: para reconstruir os dados de um disco perdido em um RAID 5 (ou um RAID 6 degradado), a controladora precisa ler cada setor de todos os discos restantes.
Se você tem discos de 4TB ou 8TB, estamos falando de horas ou dias de atividade de leitura a 100% de carga. É um teste de estresse brutal. Se um segundo disco encontrar um único setor ilegível (URE - Unrecoverable Read Error) durante esse processo, o rebuild falha. Se o disco morrer mecanicamente pelo esforço, seu array foi destruído.
A abordagem forense inverte a lógica: primeiro preservamos a evidência (os dados brutos), depois analisamos o caso.
Diagnóstico Forense: Diferenciando Erro Lógico de Falha Mecânica
Antes de digitar qualquer comando, precisamos de triage. O "corpo" (o disco) fala se você souber escutar.
Sintoma Auditivo: O disco faz cliques rítmicos, sons de raspagem ou gira e para (spin up/down)?
- Veredito: Falha Mecânica Catastrófica. Pare tudo. Nenhum software vai resolver isso. Desligue e envie para sala limpa (laboratório profissional).
Sintoma de I/O: O disco é reconhecido pela BIOS/OS, mas ejeta erros de I/O ao tentar ler certos blocos? O sistema fica lento ao acessar o dispositivo?
- Veredito: Bad Blocks ou degradação da superfície magnética. Este é o nosso cenário para recuperação via software.
Sintoma Lógico: O disco está saudável (SMART ok), mas o RAID sumiu ou a partição está inválida.
- Veredito: Corrupção de metadados ou tabela de partição. Cenário ideal para TestDisk.
Tabela de Risco: Rebuild vs. Clonagem Forense
| Característica | Rebuild Automático (RAID) | Clonagem Forense (ddrescue) |
|---|---|---|
| Carga de Trabalho | Leitura intensiva e aleatória em todos os discos. | Leitura sequencial, disco por disco. |
| Tratamento de Erros | Geralmente aborta o processo ou ejeta o disco. | Pula erros, tenta ler o resto, volta depois. |
| Resultado em Falha | Perda total do array (RAID hole). | Imagem parcial utilizável. |
| Tempo de Operação | Determinado pela controladora (lento). | Limitado apenas pela velocidade do barramento. |
| Segurança | Baixa (altera metadados no disco vivo). | Alta (trabalha apenas com leitura). |
Estratégia de Clonagem com ddrescue para Discos Danificados
Esqueça o comando dd padrão. O dd é burro; ao encontrar um erro de leitura, ele engasga ou preenche o resto do arquivo com lixo, dependendo das flags. Para fins forenses, precisamos do GNU ddrescue.
O ddrescue não tenta forçar a leitura de um setor ruim imediatamente. Ele mantém um "mapfile" (arquivo de log) que registra quais setores foram resgatados e quais falharam.
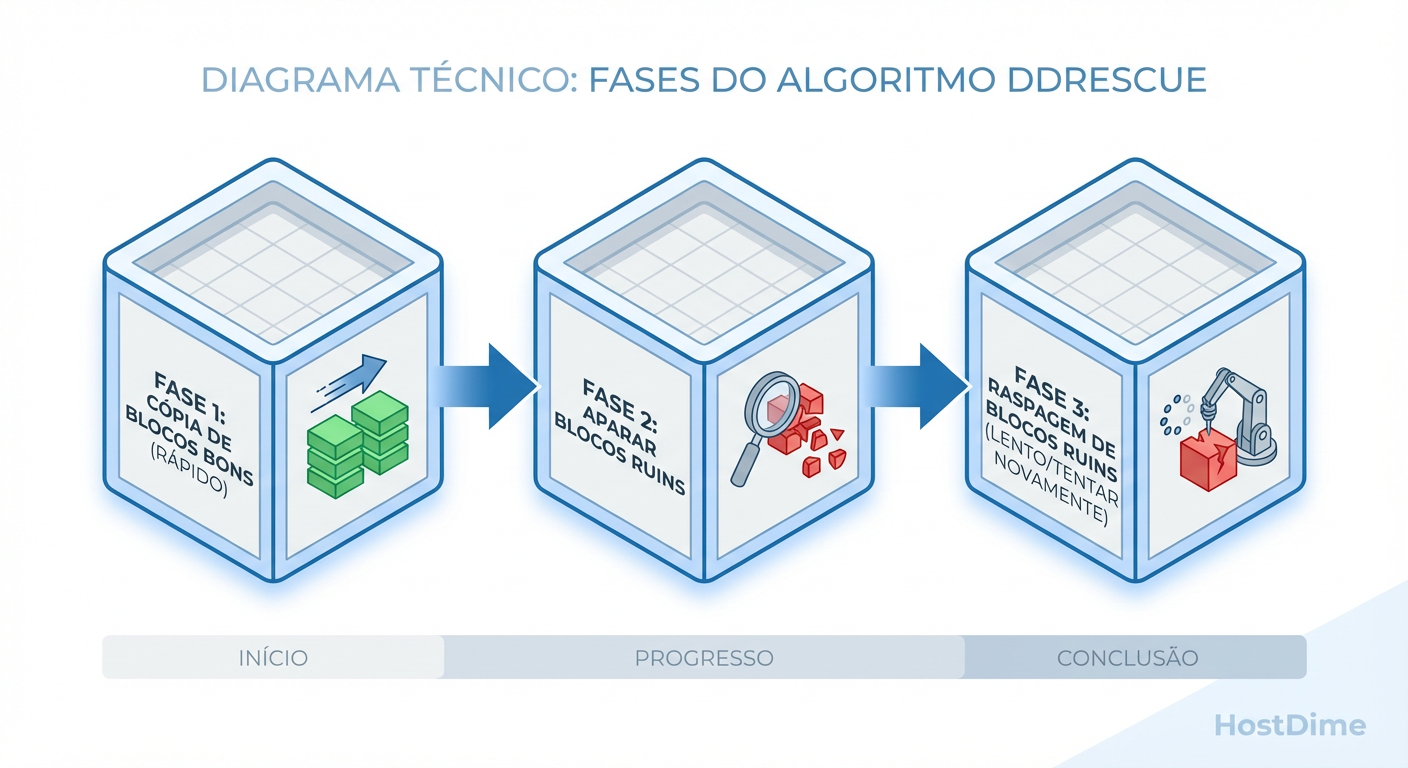 Figura: Fluxo de operação do ddrescue: Priorizando dados saudáveis antes de estressar setores danificados.
Figura: Fluxo de operação do ddrescue: Priorizando dados saudáveis antes de estressar setores danificados.
A estratégia é de "colheita seletiva". Primeiro pegamos as frutas baixas (dados fáceis), depois usamos uma escada para as difíceis, e só no final tentamos as que estão podres.
O Procedimento de Três Passos
Suponha que /dev/sdX é o disco falhando e /mnt/backup/image.img é onde salvaremos a imagem.
Passo 1: Leitura Rápida (Sem Scraping) O objetivo aqui é copiar a maior quantidade de dados saudáveis no menor tempo possível, pulando qualquer erro.
# -N: Não trunca o arquivo de saída (segurança)
# mapfile.log: O cérebro da operação. NUNCA esqueça isso.
ddrescue -n -N /dev/sdX /mnt/backup/image.img /mnt/backup/mapfile.log
Passo 2: Tentativa nos Setores Difíceis
Agora que temos 90-99% dos dados seguros, pedimos ao ddrescue para tentar ler apenas os blocos que foram pulados (baseado no mapfile).
# -d: Acesso direto ao disco (ignora cache do kernel)
# -r3: Tenta ler setores ruins 3 vezes antes de desistir
ddrescue -d -r3 /dev/sdX /mnt/backup/image.img /mnt/backup/mapfile.log
Passo 3: Opcional (Reverso) Às vezes, ler o disco de trás para frente ajuda a capturar dados próximos a uma falha mecânica sem acionar o erro imediatamente.
ddrescue -d -R -r3 /dev/sdX /mnt/backup/image.img /mnt/backup/mapfile.log
Ao final, você terá um arquivo image.img que é a melhor representação possível do disco original, sem ter matado o drive no processo. Repita isso para todos os discos do RAID, mesmo os "saudáveis", se possível. Trabalhe sempre nas cópias.
Montagem Virtual do RAID via Loop Devices no Linux
Agora que temos as imagens dos discos (ex: disk1.img, disk2.img, disk3.img), o hardware físico volta para a gaveta. A investigação acontece no ambiente virtual.
O Linux permite tratar arquivos como dispositivos de bloco usando loop devices. Isso nos permite enganar o mdadm (software de RAID do Linux) para montar o array usando os arquivos.
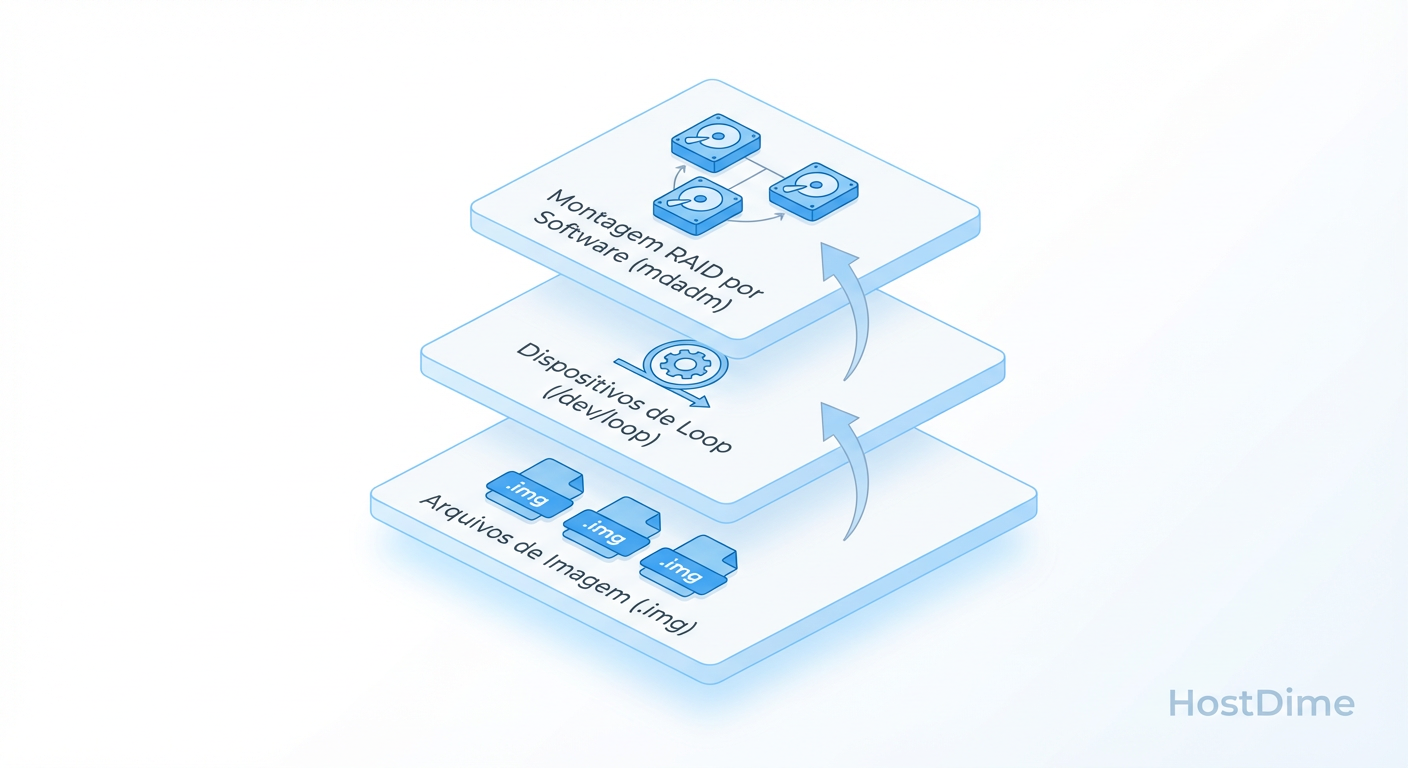 Figura: Arquitetura de Montagem Virtual: Reconstruindo o RAID usando arquivos de imagem para proteger o hardware original.
Figura: Arquitetura de Montagem Virtual: Reconstruindo o RAID usando arquivos de imagem para proteger o hardware original.
Configurando a Mesa de Cirurgia
Primeiro, associamos as imagens a dispositivos de loop:
losetup -fP disk1.img
losetup -fP disk2.img
losetup -fP disk3.img
# Verifique quais loops foram criados
losetup -a
# Saída esperada:
# /dev/loop0: [xxxx]:(disk1.img)
# /dev/loop1: [xxxx]:(disk2.img)
# ...
Agora, tentamos remontar o RAID em modo somente leitura (read-only). Isso é crucial. Se o mdadm tentar sincronizar ou escrever metadados nas imagens agora, podemos corromper a evidência.
# --assemble: Monta um array existente
# --readonly: Proteção contra escrita
# --run: Força a ativação mesmo se o array estiver degradado
mdadm --assemble --readonly --run /dev/md0 /dev/loop0 /dev/loop1 /dev/loop2
Se o comando funcionar, verifique o status com cat /proc/mdstat. Se você ver o RAID ativo, parabéns. Você pode montar o sistema de arquivos (mount -o ro /dev/md0 /mnt/recover) e copiar seus dados.
Mas e se o mdadm disser "no superblock found" ou o sistema de arquivos estiver irreconhecível? É hora de descer mais um nível.
Recuperando Partições e Geometria do RAID com TestDisk
Muitas vezes, a degradação do RAID corrompe a tabela de partições ou o superbloco do array. O array existe fisicamente (os dados estão lá), mas o sistema operacional não sabe onde começa e termina cada coisa.
O TestDisk é a ferramenta forense para reconstruir essa geometria lógica. Ele escaneia o dispositivo (neste caso, nosso /dev/md0 virtual ou até mesmo as imagens brutas) procurando por assinaturas de sistemas de arquivos (NTFS, EXT4, XFS).
Fluxo de Operação no TestDisk
Seleção de Mídia: Aponte para o dispositivo RAID montado (
/dev/md0). Não aponte para os loops individuais se você espera um RAID 5 stripado, pois os dados estão fragmentados entre eles.Tipo de Partição: Geralmente "Intel" (MBR) ou "EFI GPT". O TestDisk costuma adivinhar corretamente.
Análise (Analyze): Ele vai ler a estrutura atual. Se estiver vazia ou corrompida, selecione "Quick Search".
Interpretação: O TestDisk mostrará partições encontradas baseando-se em cabeçalhos residuais.
- Se você vir sua partição (ex: "Linux Filesystem" com o tamanho correto), pressione
Ppara listar os arquivos. - Se você consegue ver os arquivos, a geometria está correta. Você pode copiá-los diretamente dali ou pedir ao TestDisk para reescrever a tabela de partição (lembre-se: estamos trabalhando em imagens, então é seguro escrever).
- Se você vir sua partição (ex: "Linux Filesystem" com o tamanho correto), pressione
Atenção: Se o RAID não montou via mdadm porque os parâmetros de chunk size ou ordem dos discos estão errados, o TestDisk não fará milagres no /dev/md0. Nesse caso, você precisará descobrir a ordem correta dos discos e o tamanho do stripe. Ferramentas como o R-Studio (proprietário) ou scripts de análise de entropia podem ajudar a determinar a ordem correta dos loops antes de remontar o RAID.
Checklist de Decisão: Quando Contratar um Laboratório de Recuperação
Como investigador, você deve saber quando o caso excede sua jurisdição técnica. Insistir em software quando o problema é físico destruirá os dados permanentemente.
Use este checklist antes de continuar qualquer operação:
O disco é detectado na BIOS/OS com a capacidade correta?
- [NÃO] -> Laboratório. (Problema de firmware ou PCB).
- [SIM, mas capacidade 0MB ou errada] -> Laboratório. (Tradutor danificado ou cabeças fracas).
O
ddrescueestá avançando?- [SIM] -> Continue monitorando.
- [NÃO, velocidade cai para 0 B/s e erros disparam] -> Pare. As cabeças de leitura podem ter colapsado.
Ruídos anormais surgiram durante a clonagem?
- [SIM] -> Desligue imediatamente. O disco está riscando o prato magnético.
Valor dos Dados vs. Custo do Laboratório:
- Se os dados valem mais que R$ 2.000,00 e você não tem backup, o risco do "faça você mesmo" raramente compensa. Laboratórios têm salas limpas Classe 100 para abrir o disco e trocar componentes físicos. Você não.
Veredito Técnico
Recuperar um RAID degradado não é sobre ter sorte; é sobre controle de variáveis. Ao mover a batalha do hardware físico instável para imagens de disco controladas, você elimina o fator tempo e o estresse mecânico da equação.
O ddrescue preserva os bits que restam. Os Loop Devices permitem montagem segura. O TestDisk interpreta o caos lógico. Esta tríade é o kit básico de sobrevivência forense. Use-o com sabedoria, e jamais execute um comando de escrita (mkfs, fsck) sem ter certeza absoluta de que está trabalhando em uma cópia descartável.
Referências & Leitura Complementar
GNU ddrescue Manual - Antonio Diaz Diaz. Documentação oficial sobre algoritmos de recuperação de dados e uso de mapfiles.
Linux RAID Wiki (kernel.org) - Documentação técnica sobre a subsistema
md(multiple devices) e gerenciamento de superblocos.SMART Attribute Interpretation - Backblaze Hard Drive Stats. Análises estatísticas sobre correlação de falhas e atributos SMART críticos.
TestDisk Documentation - CGSecurity. Guia detalhado sobre estruturas de sistemas de arquivos e recuperação de tabelas de partição.

Marta G. Oliveira
DevOps Engineer & Storage Nerd
Automatiza provisionamento de storage com Terraform e Ansible. Defensora do 'Infrastructure as Code' para storage.