Redes Para Storage L2 Dedicado Vs Roteado L3

Você já esteve naquela situação às 3 da manhã de um sábado? O cluster de Ceph ou vSAN decide iniciar um *rebalance* massivo após a falha de um disco de 18TB. De...
Redes Para Storage L2 Dedicado Vs Roteado L3
Você já esteve naquela situação às 3 da manhã de um sábado? O cluster de Ceph ou vSAN decide iniciar um rebalance massivo após a falha de um disco de 18TB. De repente, latências que eram de sub-milissegundos saltam para 200ms. O switch de core está gritando com alertas de CPU. O console do vCenter desconecta.
O diagnóstico inicial aponta para "rede lenta". Mas quando você olha os gráficos de interface, os links de 25Gbps ou 100Gbps estão apenas 40% utilizados.
Se isso soa familiar, você provavelmente foi vítima da "Ilusão do L2". Durante anos, tratamos redes de storage como grandes estacionamentos planos: uma VLAN gigante, uma sub-rede /24 (ou pior, /16), e cabos cruzando switches em uma topologia de árvore tradicional. Funcionava bem para iSCSI de 1Gbps. Mas na era do NVMe-oF (NVMe over Fabrics) e clusters distribuídos de petabytes, a camada 2 deixou de ser uma conveniência para se tornar um passivo técnico perigoso.
Vamos dissecar por que a indústria está migrando agressivamente para arquiteturas L3 Leaf-Spine (roteadas) para tráfego de armazenamento, e como você deve ajustar seu modelo mental para operar nesse novo mundo.
A Armadilha da Simplicidade: O Custo Oculto do L2
A premissa do L2 é sedutora: "Se estiver na mesma VLAN, eles se enxergam". Não há tabelas de roteamento complexas, não há BGP, apenas ARP e endereços MAC. Para um sysadmin focado em manter os dados íntegros, a rede deveria ser apenas um tubo invisível.
O problema é como esse "tubo" se comporta sob estresse.
O A Lógica por Trás: O Corredor vs. O GPS
Imagine um escritório gigante (sua VLAN de storage).
- No modelo L2 (Switching): Se eu quero falar com o João, eu grito (ARP Broadcast): "Onde está o João?". Todo mundo no escritório para o que está fazendo para ouvir meu grito. Se o escritório for pequeno, tudo bem. Se o escritório tem 5.000 pessoas (milhares de OSDs ou targets NVMe), o barulho de fundo torna impossível trabalhar. Além disso, existe apenas um corredor principal seguro. Se houver dois corredores, o gerente de segurança (Spanning Tree Protocol) fecha um deles com fita amarela para evitar que as pessoas andem em círculos infinitos.
- No modelo L3 (Routing): O escritório é dividido em salas (Racks). Cada sala tem um número. Eu não grito. Eu olho no mapa (Tabela de Roteamento), vejo que o João está na Sala 4, e caminho diretamente para lá. Se houver 10 corredores para a Sala 4, eu posso usar qualquer um deles que esteja livre.
O Inimigo Silencioso: Spanning Tree (STP)
Em uma rede L2 redundante, loops são fatais. O STP previne isso bloqueando caminhos redundantes.
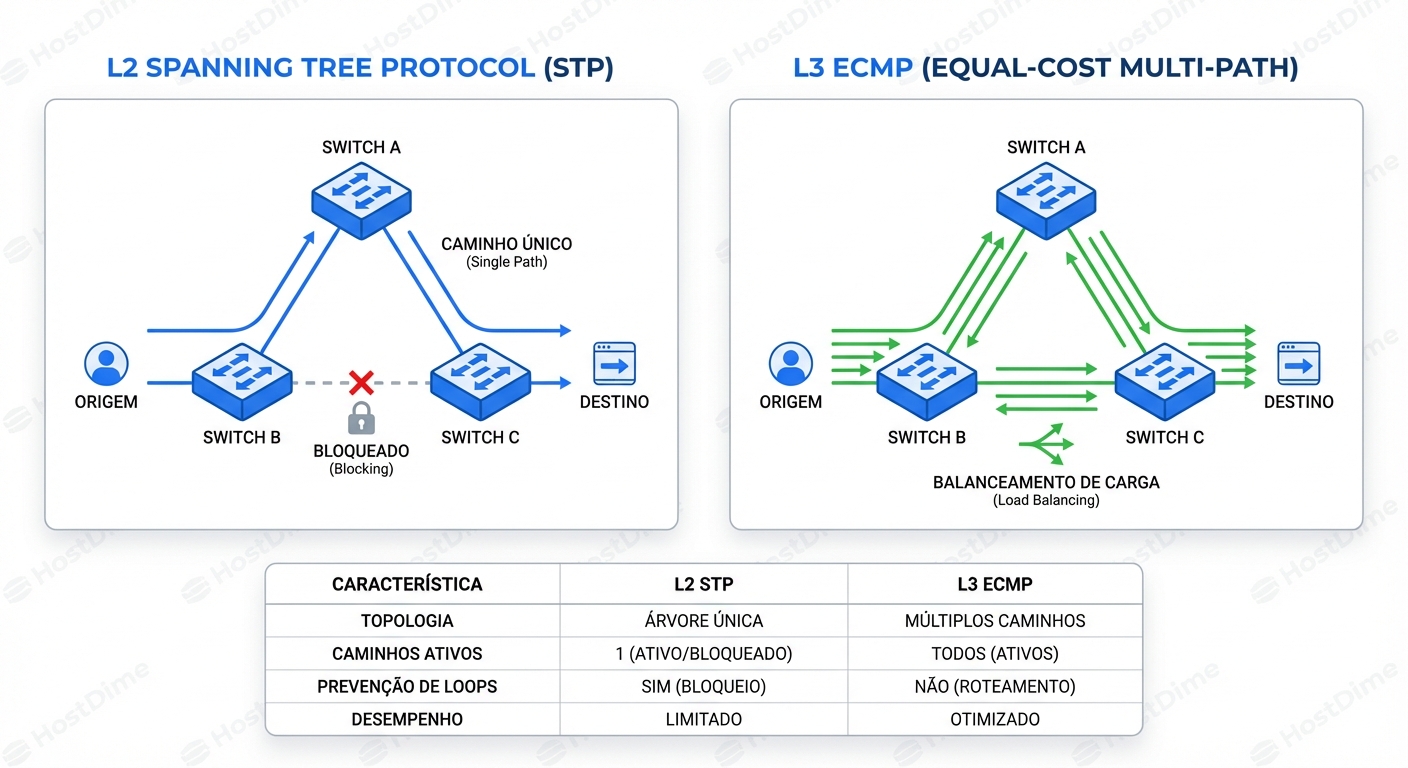
Olhe para a imagem acima (lado esquerdo). Você pagou por dois links de 100Gbps para redundância. O STP, por design, desativa um deles (estado Blocking ou Discarding) para evitar loops. Você está efetivamente jogando fora 50% da sua capacidade de largura de banda agregada. Em um cenário de falha, o STP precisa recalcular a topologia. Mesmo com RSTP (Rapid STP), há uma pausa no tráfego. Para um banco de dados transacional ou um cluster de armazenamento síncrono, alguns segundos de silêncio na rede podem causar uma eleição de líder, split-brain ou corrupção de I/O em voo.
O Domínio de Falha (Blast Radius)
O maior perigo do L2 estendido é o raio de explosão. Uma placa de rede com defeito em um servidor obscuro enviando frames de broadcast corrompidos pode derrubar toda a VLAN de storage. Um loop criado acidentalmente por um técnico de datacenter cabeando o switch errado propaga-se por todo o domínio L2, derrubando todo o cluster de storage, não apenas aquele rack.
A Arquitetura Leaf-Spine Roteada (L3)
A solução moderna é empurrar o roteamento (Layer 3) o mais para baixo possível, idealmente até o switch Top-of-Rack (ToR), que chamamos de Leaf.
Nesta arquitetura:
- Cada rack (Leaf) é sua própria sub-rede L3 (ex: 10.10.1.0/24).
- Os switches de núcleo (Spine) não fazem nada além de rotear pacotes entre os Leafs. Eles não rodam STP.
- Todo link entre Leaf e Spine é um link roteado ponto-a-ponto.
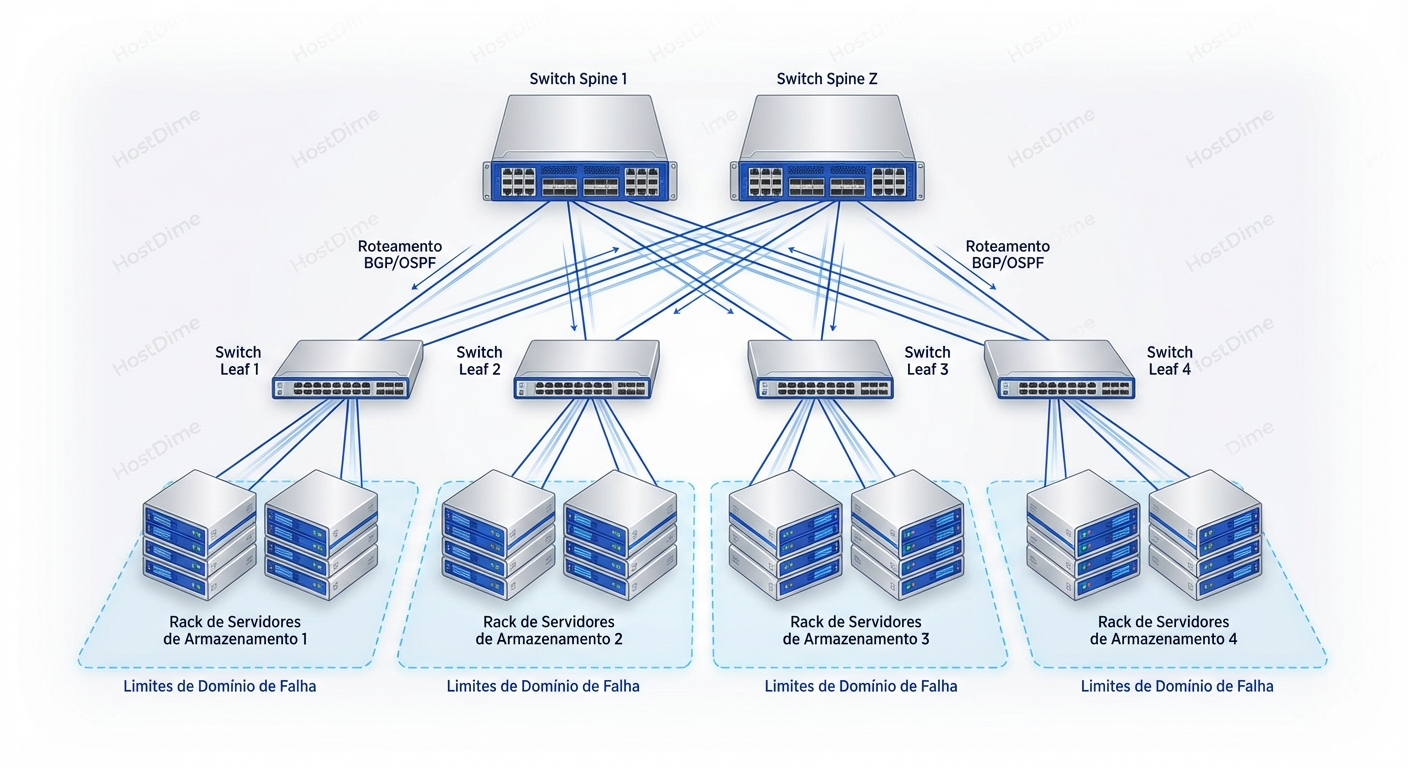
Por que isso muda o jogo para Storage?
1. ECMP: A Mágica da Multipath
A grande vitória técnica aqui é o Equal-Cost Multi-Path (ECMP). Ao contrário do STP que bloqueia links, o roteamento L3 permite que o switch olhe para a tabela de rotas e veja: "Tenho 4 caminhos diferentes para chegar ao destino 10.20.20.5, e todos têm o mesmo 'custo'".
O switch então distribui os pacotes entre todos os 4 links simultaneamente. Se você tem 4 spines conectados a cada leaf com links de 100Gbps, você tem efetivamente 400Gbps de largura de banda utilizável. Se um link falha, o protocolo de roteamento remove aquele caminho em milissegundos e o tráfego é rebalanceado nos 3 links restantes. Sem bloqueios, sem desperdício.
Para storage distribuído (como Ceph ou MinIO), onde muitos nós falam com muitos nós (tráfego Any-to-Any), o ECMP é vital para garantir que a bisseção de largura de banda da rede seja utilizada integralmente.
2. Isolamento de Falhas
Se o Rack A sofrer uma tempestade de broadcast ou um loop físico, o roteador no Leaf (ToR) não propagará esse lixo L2 para os Spines. O problema morre no rack. O resto do cluster continua operando. Você perdeu um rack de capacidade, não o datacenter inteiro.
Sob o Capô: BGP no Datacenter?
Muitos sysadmins tremem ao ouvir "BGP". "Isso não é o que segura a internet? É complexo demais para meu cluster de storage."
Na verdade, o BGP (especificamente eBGP - External BGP) tornou-se o padrão de facto para redes de datacenter modernas (DC Fabric). O motivo não é a capacidade de lidar com a tabela de rotas da internet, mas suas políticas de controle e confiabilidade.
Em um design Leaf-Spine para storage:
- ASN (Autonomous System Number): Cada switch Leaf tem seu próprio número de AS privado.
- Anúncio de Rotas: O Leaf diz aos Spines: "Eu sou o dono da sub-rede 10.1.1.0/24".
- Spines: Eles apenas repassam essa informação para os outros Leafs. "Para chegar em 10.1.1.0/24, vá para o Leaf 1".
Isso elimina a necessidade de protocolos de descoberta de vizinhança L2 instáveis em larga escala. É determinístico.
BGP no Host (Routing on the Host)
A fronteira final, e onde a performance extrema reside, é rodar BGP no próprio servidor de storage. Em vez de configurar um LACP (Bonding 802.3ad) nas interfaces do servidor – que usa algoritmos de hash limitados para balanceamento – você roda um daemon de roteamento (como FRRouting) no Linux.
O servidor anuncia seu IP (/32) diretamente para o switch Leaf via BGP. Isso permite:
- Failover em sub-segundos: O BGP detecta a queda do link mais rápido que muitos mecanismos de LACP.
- ECMP até o Host: O switch pode enviar tráfego para o servidor usando múltiplos links físicos de forma ativa-ativa real, baseada em roteamento L3.
Diagnóstico e Observabilidade: Como "Ver" a Rede L3
Quando algo quebra em L2, você procura por erros de CRC, status de STP ou usa tcpdump esperando ver o problema passar. Em L3, o diagnóstico é mais estruturado, mas requer ferramentas diferentes.
Cenário: Latência Alta em um Nó de Storage
O usuário reclama que o volume montado no servidor X está lento. O volume reside no storage array Y.
1. Verificando a Rota e o Caminho (Linux)
O velho traceroute é lento e muitas vezes bloqueado. Use mtr ou tracepath para ver o caminho e a perda de pacotes por salto.
# Não use apenas ping. Use mtr para ver jitter e perda por hop.
mtr -r -c 100 --no-dns 10.20.5.50
Se você vir perda de pacotes apenas em um dos "hops" intermediários (um dos Spines), você isolou um switch ou cabo defeituoso que o ECMP ainda está tentando usar.
2. Validando ECMP (Linux & Switch)
Você quer confirmar se o tráfego está realmente sendo balanceado.
No Linux (se o host estiver roteando):
ip route show 10.20.5.0/24
# Saída esperada (exemplo):
# 10.20.5.0/24 proto bgp metric 20
# nexthop via 169.254.0.1 dev enp3s0 weight 1
# nexthop via 169.254.0.2 dev enp3s0d1 weight 1
Se você vir apenas um nexthop, não está tendo redundância ou balanceamento.
No Switch (exemplo genérico estilo Cisco/Arista):
show ip route 10.20.5.50 detail
! Procure por "Multipath" e múltiplos next-hops com asteriscos (*) ou flags de ativo.
3. O Problema do Hash (Polarization)
Às vezes, o ECMP falha não por erro, mas por azar matemático. O switch decide qual link usar baseando-se num hash do cabeçalho do pacote (Source IP, Dest IP, Source Port, Dest Port, Protocol).
Se você tem um fluxo massivo de dados (ex: uma migração de VM única) entre um IP de origem e um IP de destino, todos os pacotes terão o mesmo hash. Eles irão todos pelo mesmo link. Um link estará a 100% e os outros 3 a 0%. Isso é chamado de "Elephant Flow".
Como detectar: Verifique os contadores das interfaces físicas no switch Spine.
show interfaces counters rate | nz
! Se Eth1/1 está a 99Gbps e Eth1/2, Eth1/3, Eth1/4 estão a 1Gbps,
! você tem uma colisão de hash ou um fluxo elefante único.
Solução: Para storage moderno (RoCEv2, NVMe/TCP), o protocolo tenta usar múltiplas conexões ou portas de origem variáveis para aumentar a entropia e permitir que o ECMP funcione. Certifique-se de que sua aplicação de storage está configurada para usar múltiplas conexões TCP/QP.
RoCEv2, ECN e o Controle de Congestionamento
Aqui é onde o L3 brilha para NVMe-oF. O protocolo RoCEv2 (RDMA over Converged Ethernet v2) encapsula RDMA em UDP/IP. Ele precisa de roteamento.
Mas o RDMA odeia perda de pacotes. Em L2, usamos Flow Control (PFC - Priority Flow Control) para pausar o tráfego e evitar perdas. O PFC em L2 é perigoso; pode causar "Head-of-Line Blocking" onde um receptor lento trava a rede inteira.
Em uma rede L3 bem projetada, usamos ECN (Explicit Congestion Notification).
- Quando um buffer de switch Spine começa a encher, ele não descarta o pacote. Ele marca um bit no cabeçalho IP (ECN bit).
- O destino recebe o pacote marcado e avisa o remetente: "A rede está ficando cheia, diminua a velocidade".
- O remetente reduz a taxa de transmissão antes que ocorra perda de pacotes.
Configurar ECN (WRED - Weighted Random Early Detection) é muito mais granular e seguro em switches L3 do que gerenciar tempestades de PFC em uma VLAN estendida.
Tabela de Decisão: Quando migrar?
| Característica | L2 Dedicado (VLAN Estendida) | L3 Leaf-Spine (Roteado) |
|---|---|---|
| Escala | Até ~32 Racks (com risco crescente) | Centenas de Racks |
| Uso de Banda | 50% (STP bloqueia links) | 100% (ECMP ativo-ativo) |
| Domínio de Falha | Todo o Cluster | Rack Individual |
| Complexidade | Baixa (Plug & Play) | Média/Alta (Requer planejamento de IP e BGP) |
| Mobilidade de IP | Alta (VMs mantêm IP em qualquer lugar) | Baixa (IP atrelado ao Rack - requer Overlay/VXLAN para VMs, mas OK para Storage Backend) |
| Ideal para | Clusters pequenos, iSCSI 10G, VMware vMotion simples | Ceph, NVMe-oF, AI/ML Clusters, Cloud Privada em escala |
A Realidade Operacional: Não é tudo perfeito
Sejamos honestos sobre as dores dessa transição. O L3 não é mágica, é uma troca de problemas.
- Gerenciamento de IP: Você não pode mais jogar tudo num
/24. Você precisa de um plano de endereçamento IP hierárquico (IPAM). Cada rack precisa de sua sub-rede. Se você mover um servidor físico de um rack para outro, o IP dele tem que mudar. Scripts de automação que dependem de IPs fixos vão quebrar. - Overlays para Compute: Se seus servidores de computação (Hypervisors) precisam mover VMs entre racks sem mudar o IP da VM, você precisará implementar uma rede Overlay (VXLAN/EVPN) sobre essa estrutura L3. Isso adiciona uma camada de encapsulamento e complexidade (MTU settings, VTEPs). Nota: Para a rede de backend de storage (replicação), geralmente evitamos Overlays e usamos L3 puro para performance máxima.
- MTU: O roteamento L3 fragmenta se não configurado corretamente. Garanta Jumbo Frames (MTU 9000 ou 9216) consistentemente em toda a malha (Leafs, Spines e Hosts). Um erro de MTU em L3 resulta em pacotes descartados silenciosamente ou ICMP "Fragmentation Needed" que firewalls adoram bloquear.
Veredito: O Caminho Sem Volta
A transição de L2 para L3 em redes de storage não é uma "tendência", é uma resposta necessária à física dos hardwares modernos. Quando um único servidor NVMe pode saturar 200Gbps, confiar no Spanning Tree para gerenciar sua topologia é negligência arquitetural.
O modelo mental que você deve adotar é: O switch é parte da aplicação de storage. Ele não é mais infraestrutura passiva.
Se você está planejando seu próximo cluster de Ceph ou refresh de infraestrutura de alta performance:
- Mate as VLANs estendidas entre racks.
- Adote BGP no ToR.
- Estude ECMP e hashing.
- Configure ECN para fluxos RDMA.
A complexidade inicial de configurar o BGP paga-se na primeira vez que um rack falhar e seu telefone não tocar porque o resto do cluster nem percebeu.
Para Aprofundamento
- RFC 7938 (Use of BGP for Routing in Large-Scale Data Centers): A bíblia do design Leaf-Spine.
- FRRouting (FRR): Como transformar seus servidores Linux em roteadores BGP.
- RoCEv2 Congestion Control: Aprofunde-se em DCQCN e ECN se estiver usando NVMe-oF.

Sarah 'The Backup' Connor
Gerente de Recuperação de Desastres
Seus dados não estão seguros até que ela diga que estão. Especialista em estratégias de backup imutável e RPO/RTO.