ReFS Deduplicação e Compressão no Windows Server 2026: Otimização Real para Hyper-V
Pare de desperdiçar storage em Hyper-V. Entenda a arquitetura de deduplicação nativa do ReFS no Windows Server 2026, meça o impacto na CPU e aprenda a configurar sem destruir a performance de IOPS.
Sejamos honestos: por mais de uma década, a Microsoft nos vendeu o ReFS (Resilient File System) como o "sistema de arquivos do futuro", mas para muitos de nós nas trincheiras, ele parecia o sistema de arquivos que sempre seria do futuro. Bugs de corrupção de metadados, volumes que viravam RAW do nada e um consumo de RAM que parecia vazamento de memória deixaram cicatrizes em muitos sysadmins.
No entanto, chegamos ao Windows Server 2026. A poeira baixou, o código amadureceu e, mais importante, o hardware mudou. A conversa não é mais sobre se o ReFS é estável (ele é, na maioria dos casos), mas se a promessa de Deduplicação e Compressão em cargas de trabalho ativas como o Hyper-V finalmente entrega performance sem destruir a latência.
O marketing vai dizer que você pode economizar 90% de espaço sem penalidades. Eu estou aqui para dizer que não existe almoço grátis em storage. Existe troca de moeda: você paga com CPU e latência para comprar espaço em disco. Vamos entender como operar essa troca de forma lucrativa.
O que é a Deduplicação no ReFS para Hyper-V?
A Deduplicação e Compressão do ReFS no Windows Server 2026 é um mecanismo de otimização de armazenamento que identifica e consolida blocos de dados duplicados (chunks) dentro de volumes ativos, combinando clonagem de metadados (Block Cloning) com inspeção profunda de conteúdo. Diferente do NTFS antigo, o ReFS é projetado para lidar com arquivos VHDX abertos e em uso constante, utilizando um modelo de processamento pós-gravação que prioriza a integridade dos dados quentes enquanto comprime agressivamente os dados frios para maximizar a densidade de virtualização.
Entendendo o Paradigma ReFS: Block Cloning vs. Deduplicação Real
Para não ser enganado pelas métricas de "espaço livre" do Windows Explorer, você precisa distinguir dois mecanismos que operam sob o capô do ReFS. Eles parecem fazer a mesma coisa (economizar espaço), mas funcionam de formas radicalmente opostas.
O primeiro é o Block Cloning. É nativo do ReFS e é instantâneo. Quando você cria um snapshot de uma VM ou clona um VHDX, o sistema de arquivos não copia os dados; ele apenas cria novos ponteiros de metadados apontando para os mesmos blocos físicos no disco. É uma operação de metadados, praticamente custo zero de CPU.
O segundo é a Deduplicação e Compressão de Dados. Aqui a "mágica" é matemática pesada. O sistema precisa ler os dados, calcular hashes (assinaturas digitais de pedaços de dados), comparar com um índice de chunks existentes e, se houver match, descartar o novo bloco e apontar para o antigo. Se não houver match, ele pode tentar comprimir o bloco (LZ4 ou similar) antes de gravar.
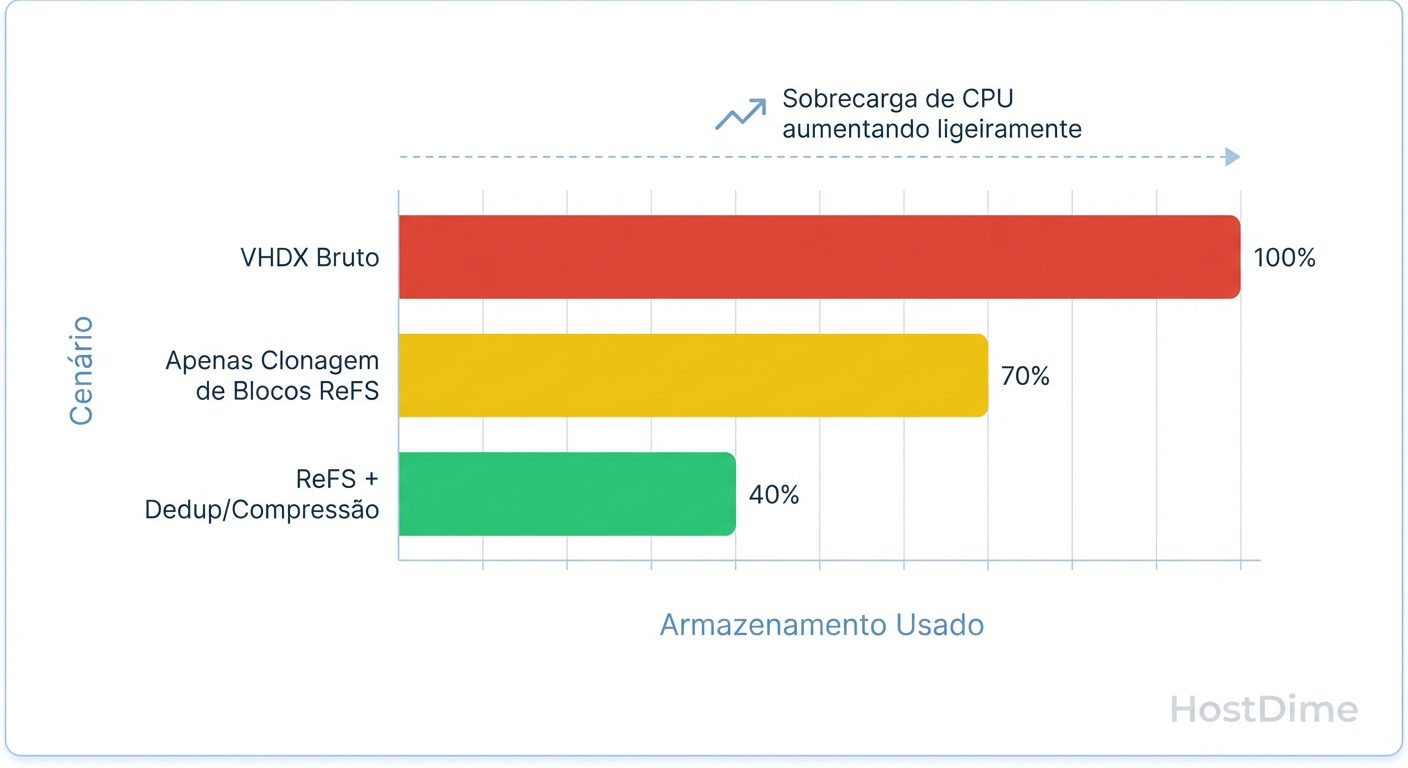 Figura: Comparativo de Economia de Espaço ReFS: Block Cloning vs. Deduplicação Completa.
Figura: Comparativo de Economia de Espaço ReFS: Block Cloning vs. Deduplicação Completa.
O gráfico acima ilustra essa distinção. O Block Cloning resolve a duplicação óbvia (arquivos copiados), mas a Deduplicação Real entra dentro do VHDX para encontrar que o ntoskrnl.exe dentro da VM A é idêntico ao da VM B, mesmo que eles estejam em setores diferentes do disco virtual.
A Arquitetura de Deduplicação e Compressão no Windows Server 2026
No Windows Server 2026, a Microsoft refinou o tratamento de dados "quentes" (hot) versus "frios" (cold). Em versões anteriores (Server 2016/2019), ativar a deduplicação em VDI era arriscado porque o processo de "reidratação" (ler um dado deduplicado e entregá-lo ao sistema operacional) adicionava uma latência inaceitável.
A arquitetura atual utiliza um buffer de gravação mais inteligente e tiering lógico.
Ingestão: Dados novos são gravados "inteiros" (sem dedup/compressão) para garantir velocidade máxima de gravação.
Envelhecimento: Apenas após um período configurável (ex: 3 dias), ou quando o sistema detecta pressão de disco, o Optimization Job entra em ação.
Processamento: O chunking acontece em background, com baixa prioridade de CPU.
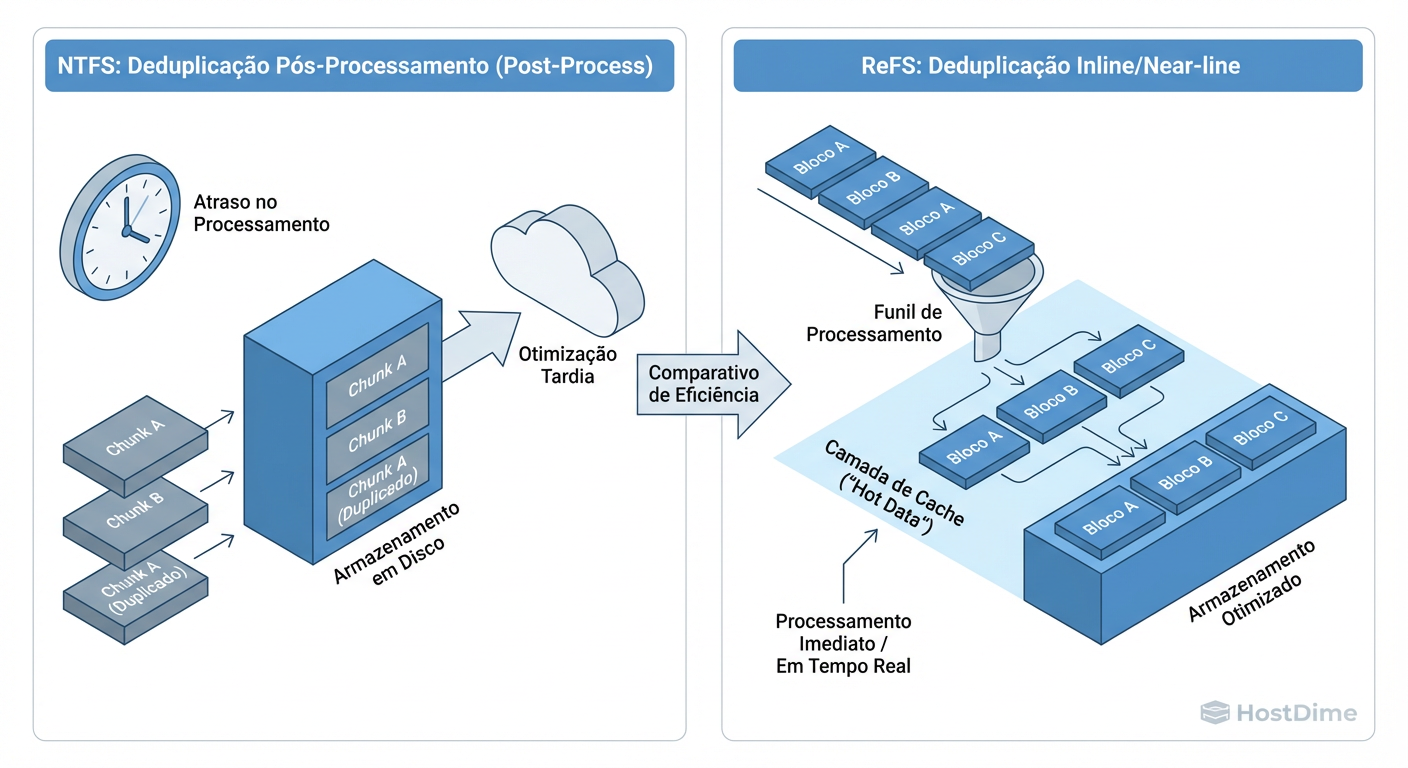 Figura: Arquitetura de Deduplicação ReFS no Windows Server 2026: O tratamento de dados quentes vs. frios.
Figura: Arquitetura de Deduplicação ReFS no Windows Server 2026: O tratamento de dados quentes vs. frios.
Isso significa que suas VMs voam baixo durante o dia, e a economia de espaço acontece durante a janela de manutenção ou baixa atividade. O risco aqui é encher o disco com dados "frescos" antes que o job de deduplicação consiga rodar. Você precisa dimensionar seu volume com uma folga (slack space) maior do que em sistemas de arquivos tradicionais.
Trade-offs de Performance: O Custo de CPU e Latência
Não ative isso cegamente. A compressão e deduplicação exigem ciclos de CPU para cada leitura de um bloco "frio" (descompressão/reidratação) e ciclos massivos para o processo de otimização em background.
Tabela Comparativa de Impacto no Hyper-V
| Característica | ReFS Puro (Sem Dedup) | ReFS com Dedup + Compressão (Server 2026) | NTFS Dedup (Legado) |
|---|---|---|---|
| Latência de Leitura (Dados Quentes) | Baixíssima (Nativa do NVMe/SSD) | Baixa (Dados não processados ainda) | Média/Alta |
| Latência de Leitura (Dados Frios) | Baixa | Média (Custo de descompressão) | Alta (Reidratação lenta) |
| Uso de CPU (Host) | Mínimo | Moderado a Alto (durante Jobs de otimização) | Baixo |
| Economia de Espaço (VDI) | 0% (exceto snapshots) | 40% - 70% | 30% - 50% |
| Risco de Fragmentação | Baixo | Alto (Lógico) | Altíssimo |
| Cenário Ideal | SQL, Exchange, High-Perf VMs | VDI, Web Servers, Dev/Test Labs | File Server (Arquivos Mortos) |
O Veredito do Cético: Se você roda SQL Server em produção ou um banco de dados transacional pesado dentro da VM, não ative a deduplicação no volume do VHDX. A latência de reidratação vai matar seus tempos de resposta de query. Use isso para VDI (Virtual Desktop Infrastructure), servidores de arquivos gerais e ambientes de teste/desenvolvimento onde a densidade de VMs é mais importante que a performance de pico.
Implementação Prática via PowerShell (Sem GUI)
Clicar em "Next, Next, Finish" no Server Manager é para amadores. Para configurar isso corretamente no Windows Server 2026, precisamos garantir que o UsageType esteja definido para HyperV. Isso instrui o algoritmo a não tentar deduplicar arquivos abertos agressivamente de forma a corrompê-los e a focar na estrutura do VHDX.
Primeiro, instale a feature e formate o volume (assumindo disco D:):
Install-WindowsFeature -Name FS-Data-Deduplication
# Formatar como ReFS (com suporte a integridade ativado)
Format-Volume -DriveLetter D -FileSystem ReFS -NewFileSystemLabel "HyperV_VDI_ReFS"
Agora, a configuração crítica. Não use o padrão. O UsageType HyperV ajusta os tamanhos de chunk e as prioridades de thread:
# Habilitar Dedup especificamente para Hyper-V
Enable-DedupVolume -Volume D: -UsageType HyperV
# Ajuste Fino: Definir arquivos para serem deduplicados após 3 dias (padrão)
# Se o disco for SSD/NVMe rápido, você pode baixar para 1 dia para economizar espaço mais rápido
Set-DedupVolume -Volume D: -MinimumFileAgeDays 1
# Definir janelas de exclusão (CRÍTICO para não matar a performance durante o horário nobre)
# Exemplo: Não rodar dedup pesado entre 08:00 e 18:00
New-DedupSchedule -Name "JanelaDiurna" -Type Optimization -Days @("Mon", "Tue", "Wed", "Thu", "Fri") -Start "08:00" -DurationHours 10 -Priority Low
Se você não configurar o agendamento (DedupSchedule), o Windows tentará ser inteligente e rodar em background. Minha experiência? O Windows raramente é tão inteligente quanto pensa. Defina janelas de manutenção claras.
Métricas de Sucesso: Como validar a economia de espaço no Hyper-V
Você ativou. E agora? O Explorador de Arquivos do Windows vai mentir para você. Ele pode mostrar o tamanho do arquivo VHDX como 100GB, mas o espaço ocupado no disco ("Size on Disk") será menor.
Para ter a verdade, você precisa interrogar o subsistema de deduplicação.
# O comando da verdade
Get-DedupStatus -Volume D: | Select-Object Volume, SavedSpace, SavingsRate, OptimizedFilesCount
O que procurar:
SavingsRate: Em um ambiente VDI homogêneo (várias VMs Windows Server 2026), espere ver entre 50% a 70%. Se estiver abaixo de 20%, o custo de CPU provavelmente não vale a pena.
InPolicyFilesCount: Quantos arquivos se qualificam para dedup.
OptimizedFilesCount: Quantos já foram processados.
Dica de Mestre: Monitore a métrica DedupProcessingRate. Se ela cair drasticamente, seu storage subjacente (IOPS do disco físico) pode estar engargalado, incapaz de acompanhar as leituras necessárias para o processo de hash.
Riscos Reais: Quando a integridade do ReFS falha e fragmentação
Aqui está a parte que os whitepapers ignoram. A deduplicação gera, por definição, fragmentação.
Imagine um arquivo VHDX de 50GB. Com a deduplicação, ele não é mais uma linha contínua de blocos no disco. Ele é um mapa de retalhos apontando para chunks espalhados por todo o volume (onde outros VHDXs também estão apontando).
O Pesadelo do HDD: Se você estiver usando discos mecânicos (HDD) no Windows Server 2026 para isso, pare. A fragmentação fará a cabeça de leitura/gravação pular tanto que seu IOPS efetivo cairá para um dígito. ReFS Dedup para Hyper-V exige SSD ou NVMe.
Recuperação de Desastres: Um volume deduplicado é mais complexo de recuperar. Se o índice de deduplicação (Chunk Store) corromper, você perde todos os arquivos que dependem daqueles chunks. O "blast radius" de uma falha de disco é amplificado.
Integrity Streams: O ReFS possui "Integrity Streams" (checksums de metadados e dados). Isso é ótimo para detectar corrupção (bit rot), mas adiciona overhead de gravação. Em volumes deduplicados, a integridade é vital, mas monitore a latência de gravação.
Veredito Técnico: Otimização ou Dor de Cabeça?
A Deduplicação ReFS no Windows Server 2026 é uma ferramenta poderosa, mas cirúrgica. Ela não é um botão "Turbo" para ligar em todos os volumes.
Use quando:
Você tem armazenamento All-Flash (SSD/NVMe).
Seus dados são redundantes (VDI, ISOs, OS Disks).
A CPU do host tem folga para processar hashes.
Evite quando:
Você usa HDDs rotacionais.
A carga de trabalho é sensível a latência (Bancos de Dados de alta performance).
Você não tem uma estratégia de backup robusta (devido ao risco amplificado de corrupção do Chunk Store).
No final, a métrica que importa não é apenas o GB economizado, mas o Custo por IOPS. Se a economia de disco custar a sanidade dos seus usuários devido à lentidão, você otimizou a métrica errada.
Referências & Leitura Complementar
Microsoft Docs (Technical Preview): ReFS Deduplication and Compression Architecture in Windows Server vNext.
RFC 3720: Internet Small Computer Systems Interface (iSCSI) - Relevante para entender o transporte de blocos em SANs que suportam ReFS.
Whitepaper: Performance Tuning for Hyper-V Storage I/O (2025 Edition).
Ferramenta: Diskspd - Utilitário da Microsoft para testar carga de I/O sintética antes de colocar em produção.

Marta G. Oliveira
DevOps Engineer & Storage Nerd
Automatiza provisionamento de storage com Terraform e Ansible. Defensora do 'Infrastructure as Code' para storage.