Roce Vs Iwarp Conceitos E Riscos

Antes de entrarmos na briga dos protocolos, precisamos alinhar o modelo mental sobre por que estamos usando RDMA (Remote Direct Memory Access) em primeiro lugar...
Roce Vs Iwarp Conceitos E Riscos
Antes de entrarmos na briga dos protocolos, precisamos alinhar o modelo mental sobre por que estamos usando RDMA (Remote Direct Memory Access) em primeiro lugar.
Imagine o fluxo tradicional de um pacote de dados chegando ao seu servidor via TCP/IP padrão:
- O pacote chega na NIC.
- A NIC gera uma interrupção na CPU.
- O Kernel acorda, copia os dados do buffer da NIC para o buffer do Kernel.
- O Kernel inspeciona os cabeçalhos (TCP/IP), verifica checksums.
- O Kernel copia os dados novamente, do espaço do Kernel para o buffer da Aplicação (User Space).
- A Aplicação finalmente lê os dados.
Isso é o equivalente a receber uma encomenda na portaria da empresa, onde o porteiro abre a caixa, tira foto, coloca em outra caixa da empresa, e só então manda para a sua mesa. É seguro, mas é lento e gasta muito tempo do porteiro (CPU).
O RDMA propõe o Kernel Bypass e Zero Copy. A aplicação diz à NIC: "Aqui está o endereço de memória RAM onde quero os dados. Coloque direto lá." A NIC, usando DMA (Direct Memory Access), escreve diretamente na memória da aplicação, sem acordar o Kernel para cada pacote. É como se o entregador tivesse a chave da sua sala e deixasse o pacote na sua mesa enquanto você dorme.
O problema é: para isso funcionar, a NIC precisa de muito mais inteligência. E a forma como essa "inteligência" é transportada sobre a Ethernet define a guerra entre RoCE e iWARP.
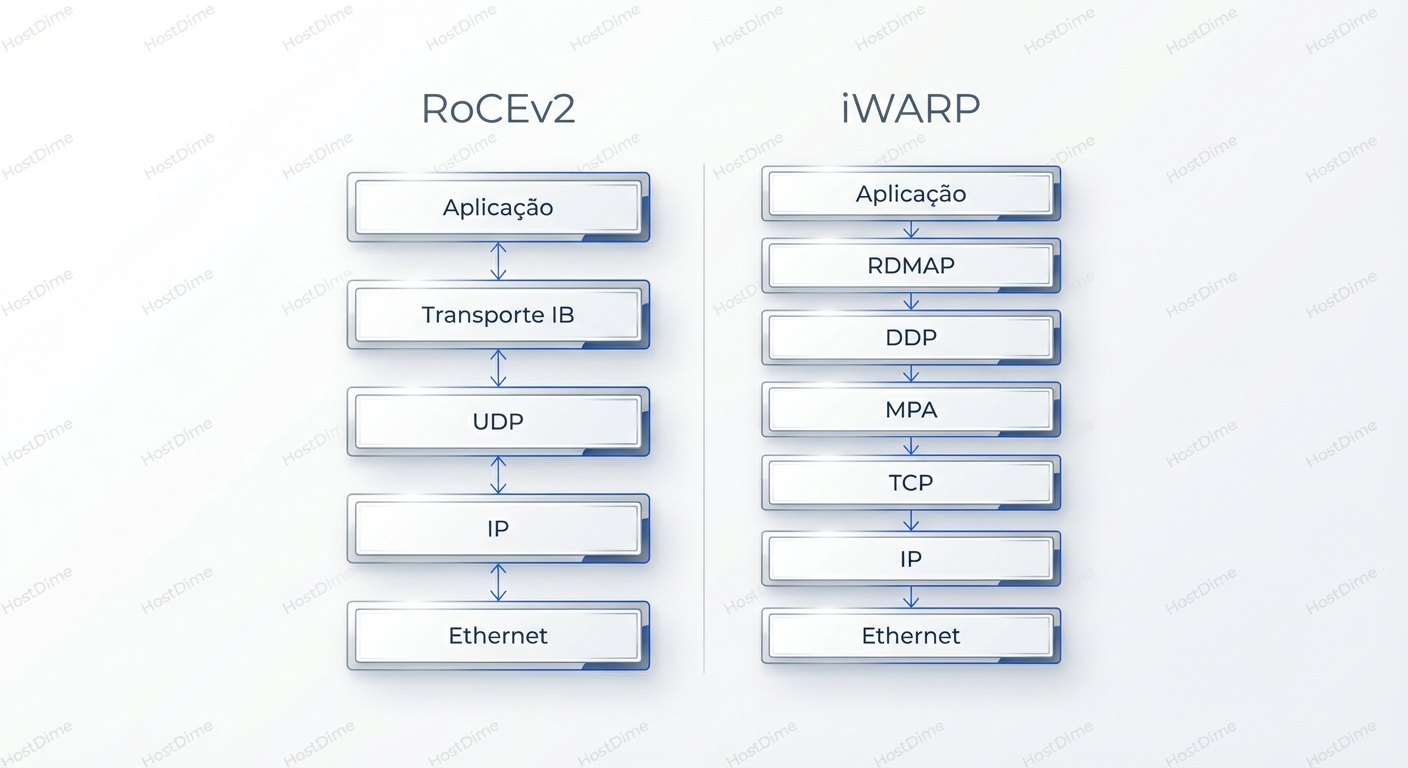
RoCEv2: O Velocista em Terreno Acidentado
O RoCE (RDMA over Converged Ethernet) versão 1 era uma gambiarra de camada 2, não roteável. Esqueça ele. O padrão de fato hoje é o RoCEv2.
Como funciona (Under the Hood)
O RoCEv2 pega o pacote de transporte do InfiniBand — que é extremamente eficiente — e o encapsula dentro de um pacote UDP/IP.
- Ethernet Header
- IP Header
- UDP Header (Porta 4791)
- InfiniBand Base Transport Header (BTH)
- Payload
O uso do UDP é crucial aqui. O UDP é leve, rápido e permite que roteadores ECMP (Equal-Cost Multi-Path) façam balanceamento de carga baseado no hash das portas de origem/destino. Isso torna o RoCEv2 roteável através de datacenters L3 (Spine-Leaf).
O Calcanhar de Aquiles: A Falácia da Perfeição
Aqui está o problema fundamental: O protocolo de transporte InfiniBand (que está dentro do UDP) foi desenhado para redes InfiniBand. Redes InfiniBand usam controle de fluxo crédito-a-crédito via hardware; elas não perdem pacotes por congestionamento.
Quando você coloca isso sobre Ethernet (que adora descartar pacotes quando o buffer enche), o RoCEv2 entra em pânico.
O mecanismo de retransmissão do RoCEv2 é, tradicionalmente, muito simples e punitivo, muitas vezes operando em um modelo Go-Back-N. Imagine que você está enviando os pacotes 1, 2, 3, 4 e 5. Se o pacote 2 é descartado no switch:
- O receptor recebe 1, 3, 4, 5.
- Ele percebe que o 2 falta e descarta 3, 4 e 5 (porque o InfiniBand espera ordem estrita).
- Ele pede para o emissor reenviar a partir do 2.
- O emissor reenvia 2, 3, 4, 5.
Em links de alta velocidade (100Gbps+), o tempo que leva para perceber a perda e reenviar tudo desperdiça uma largura de banda colossal. O throughput efetivo não cai linearmente; ele despenca de um penhasco.
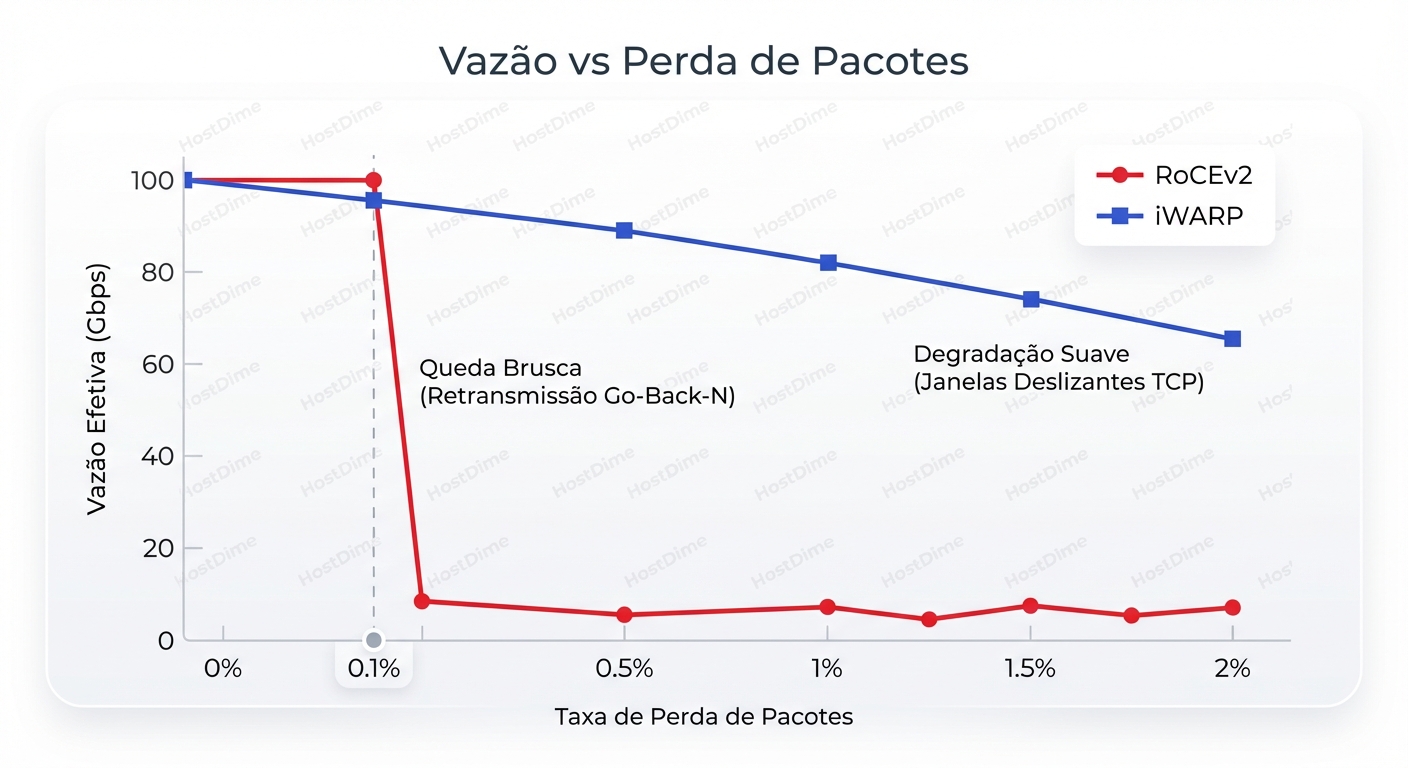
Para que o RoCEv2 funcione em produção, você não pode perder pacotes. Você precisa transformar sua Ethernet "best effort" em uma Ethernet "Lossless". E é aqui que sua vida de Sysadmin fica complicada.
iWARP: O Tanque de Guerra
Enquanto o RoCE tenta adaptar a Ethernet ao RDMA, o iWARP (Internet Wide Area RDMA Protocol) adapta o RDMA à Ethernet.
Como funciona (Under the Hood)
O iWARP não confia na rede. Ele constrói o RDMA sobre o protocolo mais testado da história: o TCP.
- Ethernet Header
- IP Header
- TCP Header
- iWARP Headers (DDP - Direct Data Placement / RDMAP)
- Payload
A Vantagem da Robustez
Como o iWARP roda sobre TCP, ele herda toda a resiliência do TCP:
- Selective Acknowledgement (SACK): Se o pacote 2 for perdido, o TCP retransmite apenas o 2, não a sequência inteira.
- Controle de Congestionamento: O TCP lida nativamente com janelas deslizantes, Jitter e reordenamento de pacotes.
- Tolerância a Lossy Networks: Você pode rodar iWARP sobre uma WAN, através da internet, ou em uma rede LAN congestionada sem configuração especial nos switches.
O Custo da Latência
Não existe almoço grátis. Para fazer RDMA sobre TCP, a NIC precisa implementar a pilha TCP inteira em hardware (TCP Offload Engine - TOE). Isso é complexo. O handshake do TCP, o gerenciamento de estado e os headers maiores adicionam latência. Enquanto um "ping" RDMA (write/read) em RoCEv2 pode levar 1-2 microssegundos, no iWARP isso pode subir para 5-10 microssegundos ou mais, dependendo da implementação da NIC. Para High Frequency Trading (HFT), isso é uma eternidade. Para um banco de dados SQL ou migração de VM, é irrelevante.
A Engenharia do Caos: Configurando "Lossless Ethernet" para RoCE
Se você escolheu RoCEv2 (ou foi forçado a isso pelo vendor do seu storage), você não pode simplesmente plugar os cabos. Você precisa configurar PFC (Priority Flow Control) e ECN (Explicit Congestion Notification). É vital entender como isso falha.
Priority Flow Control (PFC): O "Pause" Perigoso
O Ethernet padrão tem o mecanismo "PAUSE frames" (802.3x), que para todo o tráfego em um link. Isso é inaceitável. O PFC (802.1Qbb) permite pausar apenas classes de tráfego específicas.
O Modelo Mental do PFC: Imagine uma esteira de fábrica. Se a caixa de coleta no final enche, o operador aperta um botão que para a esteira apenas para aquele tipo de produto. A NIC diz ao Switch: "Estou cheia na fila de prioridade 3 (RDMA). Pare de mandar tráfego de prioridade 3". O Switch para de enviar para a NIC. Mas agora o buffer do Switch para aquela porta enche. O Switch então diz para o Switch anterior (Spine): "Pare de mandar tráfego de prioridade 3". Essa "backpressure" se propaga até a fonte.
O Risco de Produção:
- Head-of-Line Blocking: Se o tráfego RDMA compartilha a mesma fila que outro tráfego crítico, ambos param.
- PFC Storms: Uma NIC mal comportada ou travada pode emitir frames PFC continuamente, congelando uma parte inteira da rede.
- Deadlocks: Em topologias complexas com loops (mesmo com STP), é possível criar um ciclo onde Switch A espera B, B espera C, e C espera A para liberar buffer. A rede trava e só volta com reboot.
Explicit Congestion Notification (ECN): A Diplomacia
Para evitar o uso bruto do PFC, usamos o ECN (dentro do cabeçalho IP). Em vez de mandar parar (PFC), o switch marca um bit no pacote dizendo "Estou ficando cheio". Quando o receptor vê esse bit, ele avisa o emissor (via um pacote CNP - Congestion Notification Packet) para reduzir a velocidade de transmissão. É mais elegante, mas requer sintonia fina. Se o limiar do ECN for muito alto, o PFC entra em ação antes (travamento). Se for muito baixo, você perde throughput desnecessariamente.
Observabilidade: Diferenciando Saúde de Perigo
Como saber se sua implementação RoCEv2 está saudável ou se está à beira de um colapso por PFC storm? Não olhe apenas para o throughput. Olhe para os contadores de erro e controle de fluxo.
1. No Servidor (Linux)
A ferramenta ethtool é sua melhor amiga, mas você precisa olhar as estatísticas estendidas.
# Liste todas as estatísticas da interface (ex: eth1)
ethtool -S eth1 | grep -E "prio|pause|discard|drop"
O que procurar (Sinais de Perigo):
rx_pause_frames/tx_pause_frames: Se esses números estiverem incrementando rapidamente, sua rede está congestionada e o mecanismo de pausa está ativo. Um incremento lento é aceitável. Um incremento explosivo indica gargalo.rx_prio3_pause(ou similar): Confirme se os pauses estão acontecendo na classe de serviço (CoS) correta do RDMA.rx_discards_phy: Isso é ruim. Significa que o buffer da NIC encheu e ela dropou pacotes antes de processar. O RoCE vai sofrer muito aqui.
Para diagnósticos específicos de RDMA (Mellanox/NVIDIA ConnectX):
# Verifique contadores específicos do protocolo IB/RoCE
perf query -x
# OU
ibv_devinfo -v
Procure por port_rcv_switch_relay_errors ou contadores de retransmissão. Se o contador de retransmissão estiver subindo, seu "Lossless Ethernet" não está lossless.
2. No Switch (Exemplo Genérico Arista/Cisco/SONiC)
Você precisa monitorar as "Priority Flow Control frames".
- Ingress PFC frames: O switch recebeu um pedido de pausa de um vizinho (provavelmente o servidor). Significa que o servidor não está dando conta de processar os dados.
- Egress PFC frames: O switch enviou um pedido de pausa para o vizinho (provavelmente o Spine ou outro servidor). Significa que o buffer do switch está cheio.
Cenário de Diagnóstico: Se você vê muitos Ingress PFC na porta do servidor de Storage, o Storage é o gargalo (CPU ou Disco lento). Se você vê muitos Egress PFC na porta do servidor de Aplicação, a rede está congestionada e o switch está pedindo para o servidor "calar a boca".
Análise Comparativa: O Trade-off Real
Vamos colocar as cartas na mesa. Quando usar qual?
| Característica | RoCEv2 | iWARP |
|---|---|---|
| Pilha de Protocolo | UDP/IP (InfiniBand Transport) | TCP/IP |
| Dependência da Rede | Alta. Exige Lossless Ethernet (PFC/ECN). | Baixa. Funciona em Ethernet padrão (Lossy). |
| Configuração de Switch | Complexa (DCB, ETS, PFC, ECN, WRED). | Simples (QoS padrão é suficiente). |
| Latência | Mínima (~1-2 µs). | Moderada (~5-15 µs). |
| Escalabilidade | Limitada ao domínio L2/L3 controlado (Pod/DC). | Alta. Roteável via WAN/Internet. |
| Custo de CPU (Host) | Quase Zero. | Quase Zero (se NIC tiver TOE completo). |
| Custo de Hardware (NIC) | Disponível na maioria das NICs modernas. | Menos comum, hardware muitas vezes mais caro/específico (ex: Chelsio, Marvell). |
| Resiliência a Falhas | Frágil. Packet loss = Performance crash. | Robusto. Packet loss = Degradação linear. |
O Veredito Operacional
A indústria (liderada pela NVIDIA/Mellanox) empurrou o RoCEv2 para se tornar o padrão de fato para AI, HPC e Storage de alta performance. A promessa de latência do InfiniBand com o custo da Ethernet é sedutora demais.
No entanto, para o Sysadmin/SRE, o RoCEv2 é uma dívida técnica recorrente. Ele exige que você se torne um engenheiro de tráfego de rede. Você não pode simplesmente adicionar switches ao seu fabric; você precisa garantir que os buffers, as configurações de DCB (Data Center Bridging) e os mapeamentos DSCP/CoS sejam idênticos em toda a cadeia. Um switch mal configurado pode causar packet loss silencioso que destrói a performance do cluster inteiro.
O iWARP, por outro lado, é o herói injustiçado. Para 95% das cargas de trabalho corporativas (bancos de dados, virtualização, file servers), a latência extra de 5-10 microssegundos é imperceptível, mas a estabilidade operacional do TCP é inestimável. Infelizmente, o suporte de hardware para iWARP é mais restrito (Intel e Chelsio foram grandes defensores, mas o mercado pendeu para RoCE).
O Futuro é "Lossy"?
Estamos vendo uma nova tendência com protocolos de congestionamento avançados (como DCQCN e TIMELY) e SmartNICs/DPUs (BlueField, Pensando) que tentam mitigar os problemas do RoCEv2. Algumas hyperscalers estão até experimentando relaxar as exigências de "Lossless" usando algoritmos de retransmissão seletiva no nível do RoCE, tentando imitar o SACK do TCP.
Mas hoje, se você precisa implementar RDMA:
- Se você controla toda a rede (switches e hosts) e precisa de performance absoluta: Vá de RoCEv2, mas invista pesado em monitoramento de PFC/ECN.
- Se você não controla a rede, precisa atravessar roteadores legados, ou prefere dormir à noite sem receber alertas de "Buffer Threshold Exceeded": Se o hardware permitir, iWARP é a escolha técnica sã.
A pergunta que você deve se fazer não é "qual é mais rápido?", mas sim "quanto tempo minha equipe pode dedicar para debugar controle de fluxo de switch Ethernet?".

Priya Patel
Data Center Operations Lead
Gerencia milhares de discos físicos. Sabe exatamente qual modelo de HDD vibra mais e qual SSD morre primeiro.