S2D Stretch Cluster no Windows Server 2026: A Realidade da Latência e Alta Disponibilidade

Não acredite apenas no marketing de 'Zero RPO'. Entenda a arquitetura de Campus Cluster no S2D, o impacto da replicação síncrona na performance e como configurar Fault Domains corretamente no Windows Server 2026.
O marketing de Disaster Recovery (DR) adora vender o conceito de "Zero RPO/RTO" e "Disponibilidade Contínua" como se fosse apenas uma caixa de seleção na instalação do Windows Server. Eles mostram diagramas bonitos com dois datacenters, uma linha conectando-os e a promessa de que, se um prédio pegar fogo, o outro assume instantaneamente sem que o usuário perceba.
Como sysadmin veterano, meu trabalho é dizer: os slides de marketing não obedecem às leis da física.
O Storage Spaces Direct (S2D) em modo Stretch Cluster (Cluster Estendido) é uma ferramenta poderosa no Windows Server 2026, mas é impiedosa. Se você não respeitar a latência da luz na fibra ótica e a sobrecarga do stack de rede, você transformará seu array de NVMe ultra-rápido em um array de disquetes glorificado. Vamos dissecar a realidade operacional, os limites físicos e como configurar isso sem destruir a performance da sua produção.
O que é um S2D Stretch Cluster? Um Stretch Cluster no Windows Server utiliza o Storage Spaces Direct para espelhar dados sincronamente entre dois locais físicos distintos (Site A e Site B). Ele garante consistência de dados (RPO Zero) ao exigir que cada operação de gravação seja confirmada em ambos os sites antes de ser considerada concluída, permitindo failover automático de máquinas virtuais em caso de desastre físico.
A Física do Stretch Cluster e o Custo da Replicação Síncrona
O erro número um ao projetar um Stretch Cluster é tratar a conexão entre sites como se fosse um cabo de rede dentro do rack. Não é.
No S2D local, uma gravação é confirmada quando atinge a persistência em nós locais. No Stretch Cluster com replicação síncrona (o padrão para alta disponibilidade real), o processo muda drasticamente. O Windows Server 2026 não inventou uma nova física; ele ainda precisa esperar o "ack" do outro lado da cidade (ou do estado).
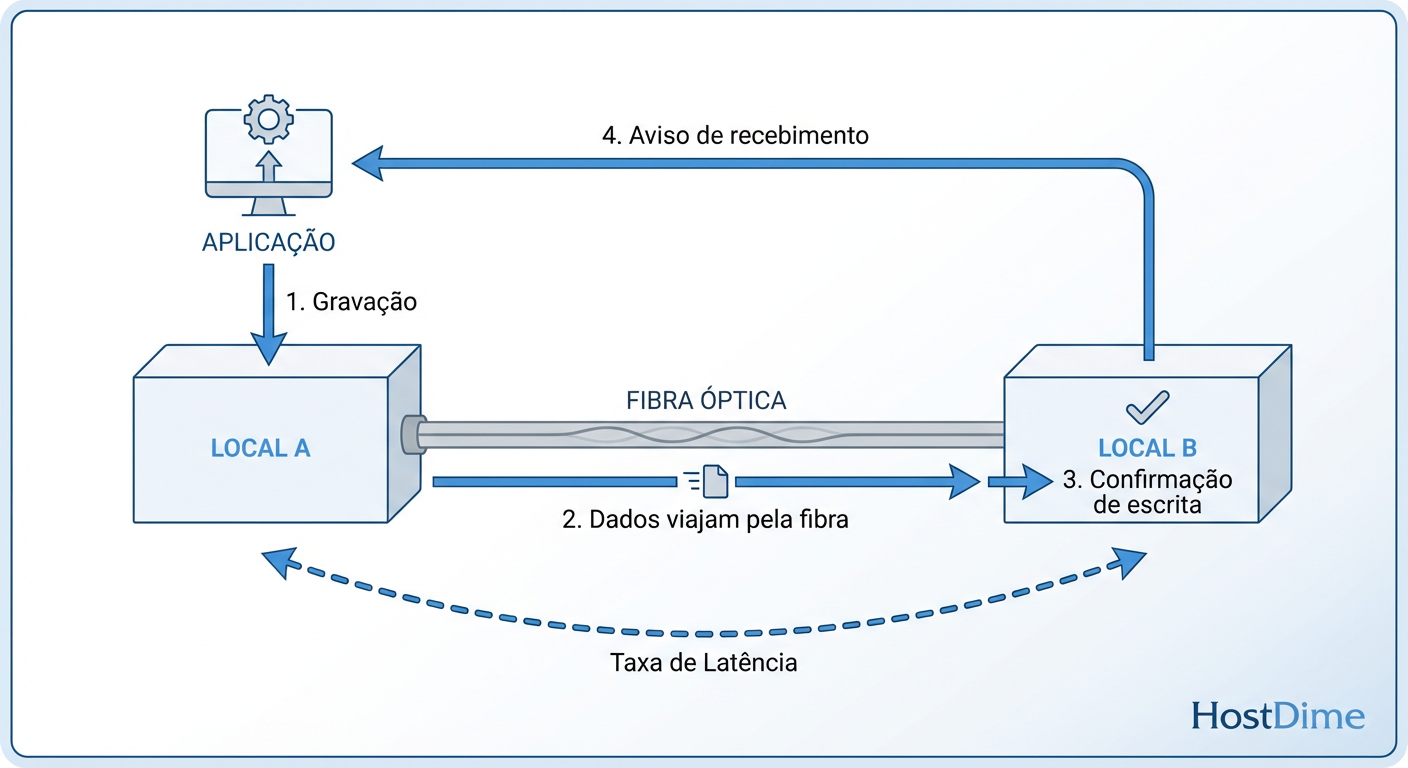 Figura: O ciclo de vida de uma gravação síncrona: A aplicação espera a luz viajar até o outro site e voltar.
Figura: O ciclo de vida de uma gravação síncrona: A aplicação espera a luz viajar até o outro site e voltar.
O Ciclo da Morte do IOPS
Entenda o fluxo de uma única gravação de 4k:
A VM no Site A envia a gravação.
O S2D grava no log local (Site A).
O S2D envia o dado pela WAN para o Site B.
O Site B recebe, grava no log local.
O Site B envia a confirmação (Ack) de volta para o Site A.
O Site A confirma para a VM que a gravação terminou.
Se a latência de ida e volta (RTT - Round Trip Time) entre seus sites for de 5ms (o que parece rápido para navegação web), sua latência de disco base será de, no mínimo, 5ms.
Matemática de Padaria: Em um cenário perfeito sem fila, 5ms de latência significa que você está limitado a 200 IOPS (1000ms / 5ms) por thread serializada (Single Queue Depth). Você pode ter SSDs NVMe capazes de 500.000 IOPS, mas a física da rede limitará a velocidade de gravação de uma thread única à velocidade de um HDD mecânico de 1995.
Callout de Risco: Se sua aplicação é sensível à latência de gravação (ex: bancos de dados transacionais como SQL Server ou SAP HANA), um Stretch Cluster mal planejado vai travar a aplicação. A replicação síncrona exige latência de rede sub-milissegundo para performance de "flash".
Planejamento de Rede para S2D: Largura de Banda vs. Latência
Muitos administradores compram links de 100Gbps e acham que o problema está resolvido. Largura de banda (throughput) é o tamanho do cano; latência é a velocidade da água. Para S2D Stretch, a latência manda.
Tabela Comparativa: Expectativa vs. Realidade de Rede
| Característica | Cluster S2D Local | Stretch Cluster (Metro) | Stretch Cluster (Campus) |
|---|---|---|---|
| Distância Típica | Mesmo Rack/Sala | < 10 km | > 10 km |
| Latência Alvo (RTT) | < 0.1 ms | < 1 ms | < 5 ms (Perigoso) |
| Tipo de Replicação | Espelhamento 3-Way | Síncrona | Assíncrona (Recomendado) |
| Impacto na Escrita | Quase nulo | Baixo/Médio | Alto (Severo com Sync) |
| Protocolo Ideal | RDMA (RoCE v2 / iWARP) | RDMA Roteável | TCP (Sem RDMA geralmente) |
No Windows Server 2026, a pilha de rede foi otimizada para lidar melhor com RDMA Roteável. Se você está planejando um Stretch Cluster "Metro" (entre prédios na mesma cidade), o uso de hardware que suporte RoCE v2 ou iWARP através de roteadores L3 é mandatório para manter a sanidade da CPU e a latência baixa.
O Terceiro Voto: Configurando o Quorum para Evitar Split-Brain
Em um cluster estendido, o cenário de pesadelo é o "Split-Brain". O link entre o Site A e o Site B cai. Ambos os sites acham que o outro morreu. Ambos tentam subir as mesmas VMs. Resultado: corrupção de dados catastrófica.
Para evitar isso, precisamos de um número ímpar de votos. Como temos dois sites (número par), precisamos de um Witness (Testemunha).
Por que o Cloud Witness é superior no WS2026
Antigamente, usávamos um File Share Witness em um "terceiro site físico". Isso é caro e logisticamente chato. O Cloud Witness (uma conta de armazenamento no Azure) é a escolha pragmática para 99% dos casos no Windows Server 2026:
Independência: Se o Site A cair, o Site B ainda vê a nuvem e ganha o quorum.
Custo: É irrisório (alguns centavos por mês), pois trafega apenas metadados de "heartbeat", não dados reais.
Simplicidade: Não requer VPN complexa, apenas HTTPS (porta 443) de saída dos nós de gerenciamento.
Regra de Ouro: Nunca coloque o Witness dentro de um dos sites do cluster. Se aquele site cair, você perde os nós e o voto de desempate, derrubando o cluster inteiro.
Definindo Fault Domains e Afinidade de Site via PowerShell
O S2D não é mágico; ele não sabe que o "Servidor-01" está em São Paulo e o "Servidor-05" está no Rio de Janeiro, a menos que você diga a ele. Se você não configurar os Fault Domains (Domínios de Falha), o S2D pode tentar colocar duas cópias dos dados no mesmo site, anulando o propósito do DR.
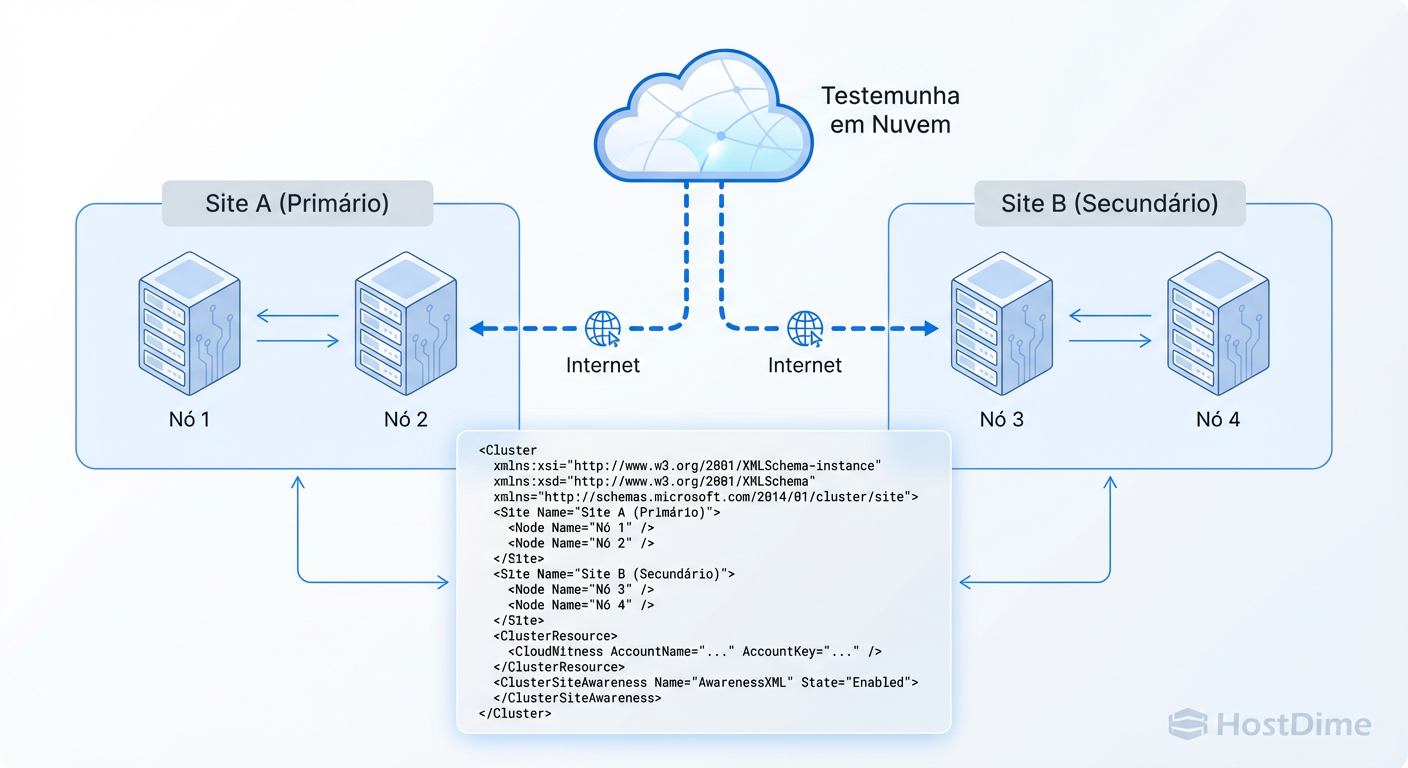 Figura: Topologia de Fault Domains: Ensinando o cluster onde os servidores estão fisicamente para garantir a colocação correta das cópias de dados.
Figura: Topologia de Fault Domains: Ensinando o cluster onde os servidores estão fisicamente para garantir a colocação correta das cópias de dados.
No Windows Server 2026, o conceito de "Site" é mais rigoroso. Você deve agrupar seus nós logicamente.
Procedimento de Configuração de Topologia
Não clique na GUI para isso. Use o PowerShell para garantir precisão. O script abaixo define a topologia física para o cluster entender onde colocar as cópias dos dados.
# 1. Criar os Sites (Fault Domains)
New-ClusterFaultDomain -Name "Site-SaoPaulo" -Type Site -Description "Datacenter Principal"
New-ClusterFaultDomain -Name "Site-Rio" -Type Site -Description "Datacenter DR"
# 2. Mover os nós para seus respectivos sites
# Assumindo um cluster de 4 nós: SP-01, SP-02 e RIO-01, RIO-02
Get-ClusterFaultDomain -Name "SP-01", "SP-02" | Set-ClusterFaultDomain -Parent "Site-SaoPaulo"
Get-ClusterFaultDomain -Name "RIO-01", "RIO-02" | Set-ClusterFaultDomain -Parent "Site-Rio"
# 3. Validar a topologia
Get-ClusterFaultDomain -Type Site | Format-Table Name, Children
Uma vez configurado, o S2D no Windows Server 2026 utilizará automaticamente essa informação para garantir que, em um espelhamento de 4 vias (4-way mirror) ou espelhamento aninhado, cópias suficientes residam em ambos os sites.
Novidades do Windows Server 2026 para Cenários Metro
O Windows Server 2026 traz refinamentos sutis, mas vitais para quem opera "no limite":
Compressão de Replicação SMB Adaptativa: O WS2026 agora avalia a carga da CPU e a largura de banda disponível em tempo real. Se o link entre sites estiver congestionado, ele comprime agressivamente os dados de replicação antes de enviar. Isso reduz a latência efetiva em links de 10GbE saturados.
Resync Site-Aware: Se um disco falha no Site A, as versões anteriores do S2D poderiam tentar reconstruir os dados puxando bits do Site B, saturando o link WAN. O WS2026 prioriza a reconstrução usando dados de outros nós dentro do mesmo Site A, se disponíveis, economizando a preciosa banda entre sites.
Stretch Cluster Assimétrico: Agora há melhor suporte para configurações onde o Site B tem hardware ligeiramente diferente (ex: menos CPU), tratando-o oficialmente como um site de "repouso" e ajustando as filas de IO para não sobrecarregar o site secundário durante a replicação.
Procedimentos de Failover: A Realidade Operacional
O que acontece quando o Site A cai?
O "Brownout": Não é instantâneo. O cluster precisa detectar a perda de heartbeat (geralmente 5 a 10 segundos, configurável), arbitrar o quorum com o Cloud Witness e reiniciar os serviços no Site B. O armazenamento não para, mas as VMs precisam reiniciar (Cold Boot) no outro lado se não houver Live Migration estendida (que exige latência baixíssima).
O Perigo do Failback: Quando o Site A volta, não configure o failback automático.
- O Site A voltará desatualizado.
- O S2D precisará ressincronizar os dados alterados enquanto o Site B estava no comando.
- Mover a carga de volta para o Site A durante a ressincronização vai matar a performance de disco (IOPS de contenção).
Recomendação Pragmática: Opere no Site B até que a ressincronização do storage esteja 100% concluída e o tráfego de rede estabilizado. Só então agende uma janela de manutenção para mover as VMs de volta para o Site A via Live Migration.
Veredito Técnico: Use, mas meça
O S2D Stretch Cluster no Windows Server 2026 é uma solução robusta que democratiza o DR síncrono, eliminando a necessidade de SANs proprietárias de milhões de dólares. No entanto, ele remove a "mágica" do hardware dedicado e coloca o ônus da performance na sua rede e no seu planejamento.
Se você tiver latência sub-milissegundo e fibra escura entre os prédios, vá em frente. Se você tem um link VPN de 100Mb e 20ms de latência, use o Hyper-V Replica (assíncrono) e durma tranquilo sabendo que seu RPO é de 5 minutos, mas seu servidor não está travado esperando a luz viajar.
Referências & Leitura Complementar
Microsoft Docs: "Storage Spaces Direct overview and planning" (Atualizado para WS2026).
RFC 5040: "A Remote Direct Memory Access Protocol Specification (RDMAP)" – Entenda o que faz o RDMA funcionar.
Whitepaper: "Performance Tuning for Storage Spaces Direct" – Foco na seção de Network Latency.

Elena Kovacs
Arquiteta de Cloud Infrastructure
Focada em NVMe-oF e storage definido por software. Projeta clusters de petabytes para grandes provedores de nuvem.