Scrub vs. Resilver: O Preço Oculto da Integridade de Dados

Integridade não é mágica, é I/O. Entenda a diferença mecânica entre Scrub e Resilver, o impacto na latência e como tunar o ZFS para não derrubar a produção.
O chamado chega sempre com a mesma descrição vaga: "O banco de dados está lento", "A aplicação está engasgando" ou "O I/O wait está no teto". Você loga no servidor. CPU está ociosa. Memória livre. Rede tranquila.
Mas quando você olha para o subsistema de disco, é uma cena de crime. Latências de milissegundos saltaram para segundos. A fila de disco está enorme. E lá, escondido na saída de um zpool status, você encontra o culpado: uma barra de progresso.
Seja um Scrub (limpeza/verificação) ou um Resilver (reconstrução), o ZFS está cobrando seu preço. A integridade dos dados não é gratuita; ela é paga em IOPS. Para um investigador forense de sistemas, a questão não é "o que está rodando", mas sim "por que essa manutenção está matando minha produção?".
Vamos dissecar essas duas operações, entender por que elas competem violentamente com sua aplicação e como provar isso com métricas, não palpites.
A Mentira do "Background Process"
A primeira coisa que precisamos desmantelar é o termo "processo em segundo plano". Em armazenamento mecânico (HDDs) e, em menor grau, em SSDs saturados, não existe segundo plano.
Existe apenas um canal de comunicação (o cabo SAS/SATA) e, no caso de discos rotativos, um braço mecânico que obedece às leis da física. Se o ZFS precisa ler um bloco para verificar sua integridade (Scrub), a cabeça de leitura deve mover-se até lá. Se sua aplicação precisa ler um registro do banco de dados no mesmo instante, ela entra na fila.
O disco não sabe o que é "manutenção" e o que é "cliente pagante". Ele vê apenas requisições de I/O. O ZFS tenta ser educado e ceder a vez, mas a física do movimento da cabeça do disco cria o que chamamos de "seek penalty".
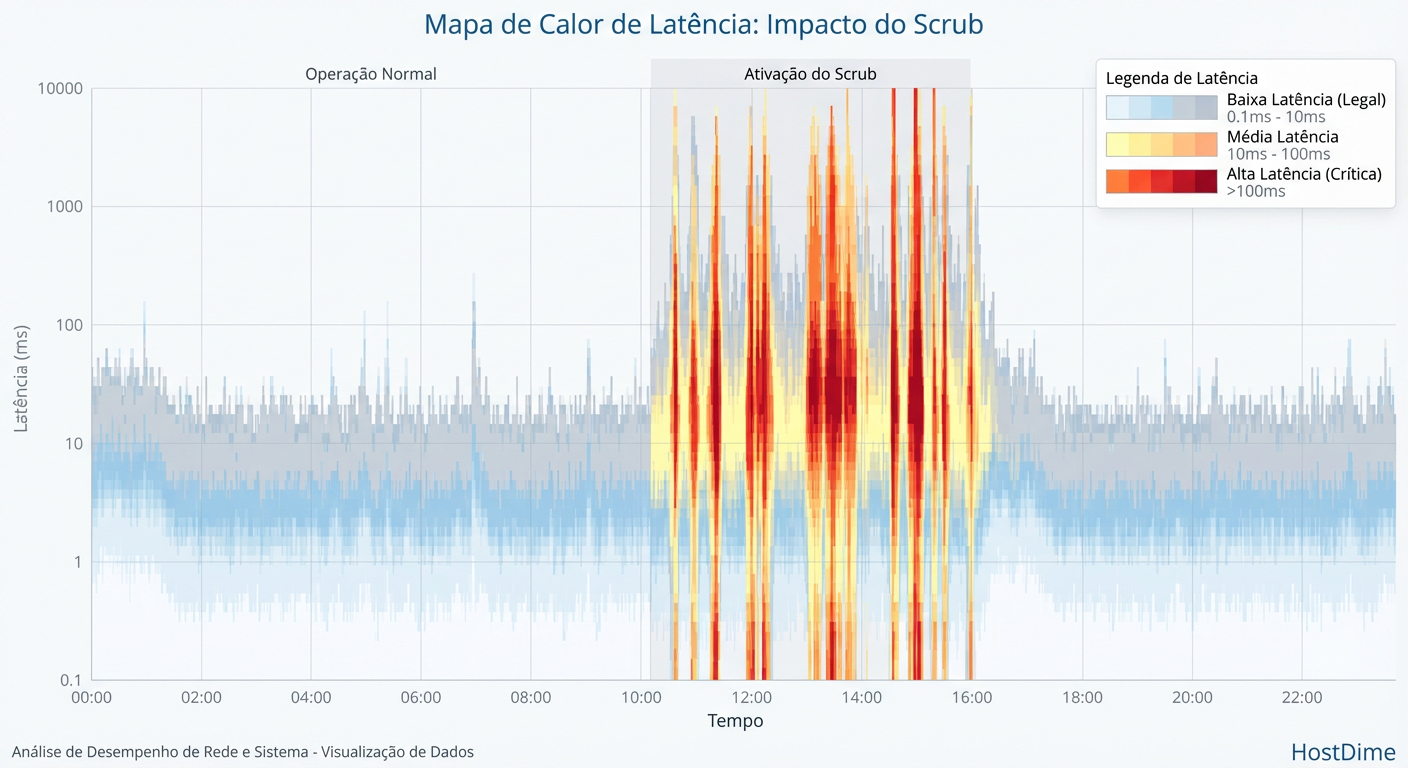 Figura: Figura 2: O Custo Operacional. Heatmap mostrando como um Scrub não tunado introduz picos de latência que competem diretamente com a aplicação.
Figura: Figura 2: O Custo Operacional. Heatmap mostrando como um Scrub não tunado introduz picos de latência que competem diretamente com a aplicação.
Como visto acima, quando o processo de verificação começa, ele injeta latência. O sistema tenta intercalar leituras de manutenção com leituras de produção, mas o simples ato de alternar entre elas destrói a performance sequencial e satura a capacidade de IOPS aleatórios.
Anatomia do Scrub: A Validação da Árvore de Merkle
Muitos administradores tratam o Scrub como um fsck antigo ou uma verificação de superfície de disco linear. Isso é um erro fundamental.
O ZFS é um sistema de arquivos transacional baseado em Copy-on-Write e estruturado como uma Árvore de Merkle. Cada bloco de dados tem um checksum, que é armazenado no bloco pai (ponteiro), e assim sucessivamente até o uberblock.
Quando você inicia um Scrub, o ZFS não lê o disco do setor 0 ao setor N. Ele caminha pela árvore de metadados.
Ele lê o uberblock.
Ele segue os ponteiros para os metadados de nível superior.
Ele desce para os dados.
Ele calcula o checksum do dado lido e compara com o checksum armazenado no pai.
O Impacto Forense: Se o seu pool estiver fragmentado (comum em servidores de arquivos antigos ou bancos de dados), os metadados e os dados estão espalhados fisicamente pelo disco. O Scrub, portanto, gera uma tempestade de I/O Aleatório.
Ele está testando a validade lógica dos dados, não apenas a superfície física. Isso significa que um Scrub em um pool vazio é instantâneo, mas em um pool cheio e fragmentado é uma tortura para os atuadores dos HDDs.
Callout: O Risco da Fragmentação Se o seu Scrub costumava levar 4 horas e agora leva 12, não culpe apenas o volume de dados. Culpe a entropia. A fragmentação transforma leituras que deveriam ser sequenciais em buscas aleatórias, competindo diretamente com as transações do seu banco de dados.
Anatomia do Resilver: A Corrida Contra o Tempo
O Resilver é o irmão mais feio e desesperado do Scrub. Ele ocorre quando um disco falha e é substituído. O objetivo não é apenas verificar; é reconstruir.
Aqui, a dinâmica muda. O Scrub é uma leitura distribuída (lê de todos, verifica tudo). O Resilver é um funil.
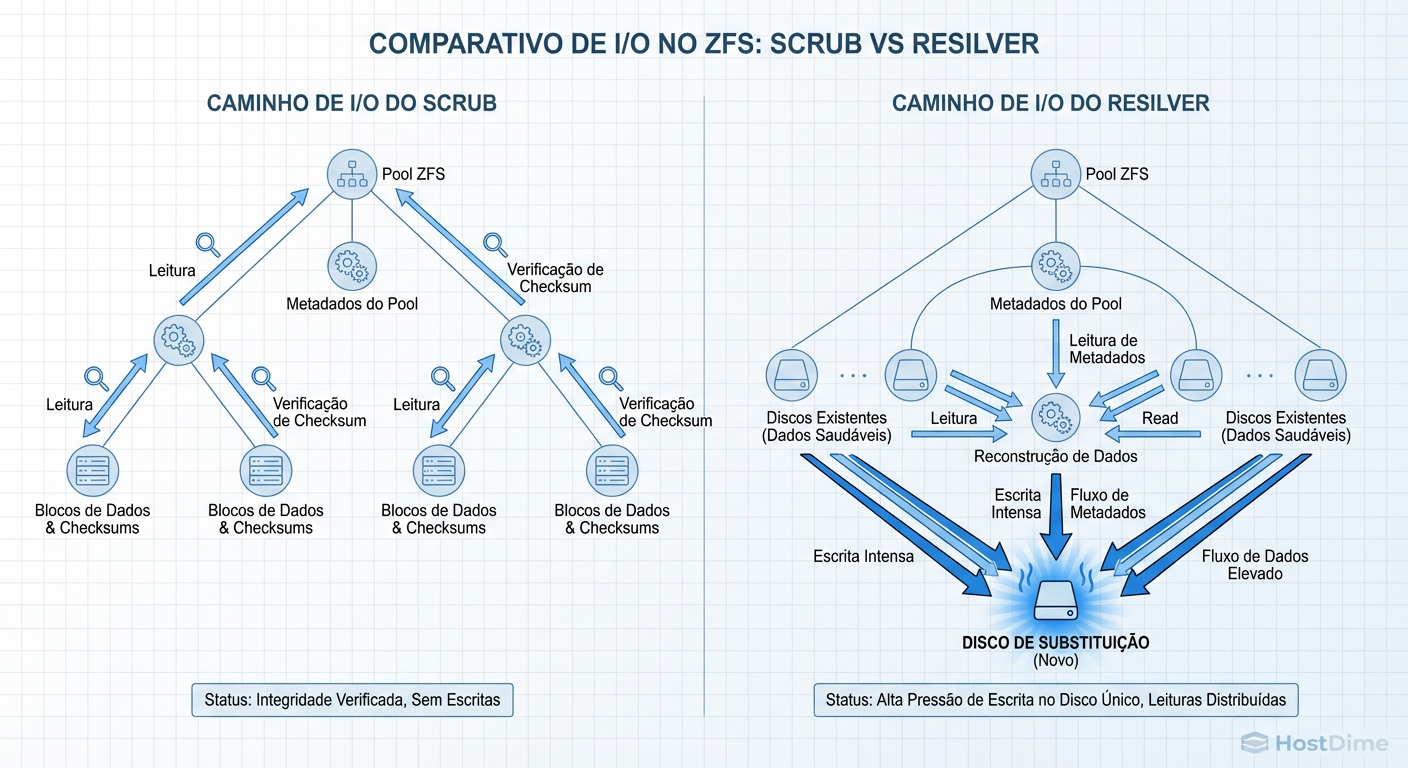 Figura: Figura 1: A diferença mecânica. Enquanto o Scrub é uma leitura distribuída para verificação, o Resilver é um funil de escrita focado no disco novo.
Figura: Figura 1: A diferença mecânica. Enquanto o Scrub é uma leitura distribuída para verificação, o Resilver é um funil de escrita focado no disco novo.
No Resilver tradicional (antes do recurso Sequential Resilver), o ZFS também caminha pela árvore de metadados. Para cada bloco que deveria estar no disco morto, ele:
Lê os dados/paridade dos discos sobreviventes.
Recalcula os dados perdidos.
Grava no novo disco.
O Gargalo do Disco Novo: O disco novo torna-se o gargalo imediato. Ele está recebendo um fluxo contínuo de escritas. Enquanto isso, os discos velhos (sobreviventes) estão sendo lidos intensamente. Se você usa RAIDZ1 (paridade única) e outro disco falhar durante esse processo devido ao estresse mecânico, você perdeu o pool.
O Resilver é uma operação de prioridade crítica, mas paradoxalmente, ele precisa ser throttled (limitado) para que a aplicação continue funcionando.
Métricas Forenses: A Prova do Crime
Você suspeita que o Scrub ou Resilver está matando a performance. Como provar? O top ou htop não vão te mostrar isso claramente, pois o trabalho acontece no kernel (ZFS ARC e threads de I/O).
Use as ferramentas nativas do ZFS para isolar a variável.
1. Latência por Tipo de I/O
O comando zpool iostat com as flags -r (request size) e -w (wait/latency histogram) é seu melhor amigo.
# Monitore a latência com histogramas para ver a distribuição
zpool iostat -w 5
Se você vir a coluna de latência de leitura (Read) disparar nos discos físicos enquanto um Scrub está rodando, você tem sua correlação. Se a coluna de escrita (Write) estiver alta apenas no disco novo durante uma reconstrução, é o gargalo do Resilver.
2. A Fila de Scan
O ZFS expõe quanto trabalho de "scan" (a engine por trás do Scrub e Resilver) está pendente.
# Verifique o status detalhado do processo de scan
zpool status -v
Observe o campo "scan". Se a velocidade de processamento cair drasticamente quando sua aplicação inicia um backup ou job pesado, você confirmou a contenção de recursos.
3. Biolatency (eBPF)
Se você precisa ir mais fundo e provar que o sistema operacional está esperando pelo disco, use ferramentas baseadas em eBPF (do pacote bcc-tools):
# Mostra a latência de I/O de bloco em um histograma
biolatency -D 10
Se você ver picos multimodais (dois grupos de latência, um rápido e um muito lento), o grupo lento geralmente é o I/O de manutenção que ficou preso na fila atrás de uma requisição prioritária (ou vice-versa).
O Dilema da Prioridade: Tunables e Sobrevivência
O ZFS permite ajustar a agressividade dessas operações. Não existe "melhor prática", existe apenas o trade-off que seu negócio suporta.
O Mecanismo de Pausa
O ZFS moderno tenta não ser rude. Ele usa uma lógica de "scan idle". Se houver I/O de produção, ele pausa o Scrub/Resilver.
O Parâmetro Chave: zfs_scan_idle
Define quanto tempo (em milissegundos) o sistema deve estar ocioso antes que o ZFS retome o Scrub/Resilver.
Se sua aplicação é sensível à latência, aumente este valor. O ZFS ficará mais "tímido".
O Risco: Se o seu servidor nunca fica ocioso (ex: um DB 24/7), o Scrub nunca terminará. Eu já vi Scrubs que duraram 3 semanas porque o tunning estava passivo demais.
A Força Bruta (Legado e Atual)
Antigamente, usávamos zfs_resilver_delay para injetar "pausas" artificiais no processo de reconstrução. Hoje, o foco é limitar o tamanho das transações de sync.
Para forçar um Resilver a terminar mais rápido (arriscando travar a aplicação), você reduz os delays e aumenta o limite de I/O assíncrono.
# Apenas em emergências onde o risco de perder outro disco é maior
# do que o risco de parar a aplicação:
# Reduz o tempo que o ZFS espera para retomar o scan
echo 0 > /sys/module/zfs/parameters/zfs_scan_idle
Tabela de Decisão: O que priorizar?
| Cenário | Risco Principal | Estratégia Recomendada |
|---|---|---|
| Banco de Dados OLTP | Latência de transação | Aumentar zfs_scan_idle. Agendar Scrubs para janelas de manutenção reais. |
| Storage de Backup | Throughput de gravação | Padrão (default). O ZFS gerencia bem cargas sequenciais. |
| RAIDZ1 com Disco Falho | Perda Total de Dados | Prioridade máxima ao Resilver. Dane-se a performance da aplicação. Se outro disco falhar, acabou. |
O Futuro: Sequential Resilver e dRAID
A engenharia do OpenZFS reconheceu que o modelo tradicional de "caminhar na árvore" é ineficiente para reconstruções em discos grandes (16TB+).
Sequential Resilver: Em vez de caminhar na árvore e reconstruir bloco a bloco aleatoriamente, o recurso (disponível nas versões mais novas do OpenZFS) primeiro mapeia onde tudo está e depois reconstrói o disco novo de forma sequencial. Isso transforma o pesadelo de IOPS aleatórios em um fluxo contínuo de gravação, reduzindo o tempo de reconstrução de dias para horas.
dRAID (Distributed RAID): O dRAID elimina o conceito de "disco de hotspare ocioso". A capacidade de reserva é distribuída em todos os discos. Quando um disco falha, todos os discos participam da reconstrução para o espaço reservado. O gargalo do "funil de um disco" desaparece. A largura de banda de reconstrução torna-se a soma da largura de banda de todos os discos.
Veredito Forense
Scrub e Resilver não são processos mágicos que rodam no vácuo. Eles são consumidores vorazes de IOPS e largura de banda.
Quando o sistema ficar lento durante essas operações, não procure por erros de configuração esotéricos. A causa raiz física é a competição pelo braço do disco.
Meça: Use
zpool iostat -wpara confirmar a latência.Entenda: Diferencie verificação (Scrub) de reconstrução (Resilver).
Decida: Se é um Scrub, você pode pausar (
zpool scrub -s poolname) e retomar na madrugada. Se é um Resilver de um RAIDZ degradado, prepare o café e avise os usuários: a lentidão é o preço de não perder os dados.

Thomas 'Raid0' Wright
High-Performance Computing Researcher
Trabalha com supercomputadores. Para ele, velocidade é tudo, e redundância é problema do software.