SLOG e Sync Writes: O acelerador que você provavelmente não precisa (ou está usando errado)
Pare de tratar SLOG como 'cache de escrita'. Entenda o ciclo de vida do ZFS, diagnostique gargalos de latência e escolha o hardware certo (PLP) sem queimar dinheiro.
Você chega na cena do crime: um servidor de arquivos ZFS rastejando. As reclamações dos usuários se acumulam na sua caixa de entrada como logs de erro. O administrador anterior, em pânico, jogou dinheiro no problema: comprou o SSD NVMe mais rápido que encontrou na Amazon e o adicionou como um dispositivo de Log (SLOG) ao pool.
O resultado? Nada. Zero melhoria. O servidor continua lento, e agora você tem um SSD caro desgastando células de memória inutilmente.
Como investigador forense de sistemas, meu trabalho não é vender hardware, é isolar a variável que está matando sua performance. E quando se trata de ZFS e SLOG, a quantidade de desinformação é alarmante. Vamos dissecar esse cadáver e entender por que adicionar um SLOG muitas vezes é o remédio errado para a doença errada.
A Anatomia da Escrita: O Mito do "Write Cache"
Primeiro, vamos limpar o quadro de evidências. Existe uma crença popular de que o SLOG (Separate ZFS Intent Log) é um "cache de escrita" geral. Isso está errado. Se você tratar o SLOG como um buffer mágico que acelera todas as gravações, você vai falhar.
O ZFS, por natureza, é um sistema de arquivos transacional. Ele agrupa gravações na memória RAM (no ARC) e as descarrega para o disco em intervalos regulares (geralmente a cada 5 segundos). Esses grupos são chamados de Transaction Groups (TXGs). Essa escrita assíncrona é incrivelmente eficiente e transforma I/O aleatório em sequencial.
O problema surge quando uma aplicação — digamos, um banco de dados PostgreSQL ou um servidor NFS exportando para VMware — grita: "Pare tudo! Eu preciso da confirmação de que esse dado está fisicamente no disco AGORA, antes de eu continuar."
Isso é uma Sync Write (Escrita Síncrona).
O ZFS não pode esperar 5 segundos pelo próximo TXG. Ele precisa gravar imediatamente para garantir a integridade (ACID). Sem um SLOG, o ZFS grava esse pequeno pedaço de dados diretamente no pool principal (ZIL on-pool), competindo com outras operações e forçando as cabeças de leitura dos HDDs a dançarem, o que destrói a latência.
O SLOG entra aqui: ele é um local dedicado apenas para anotar essa "intenção" de gravação rapidamente.
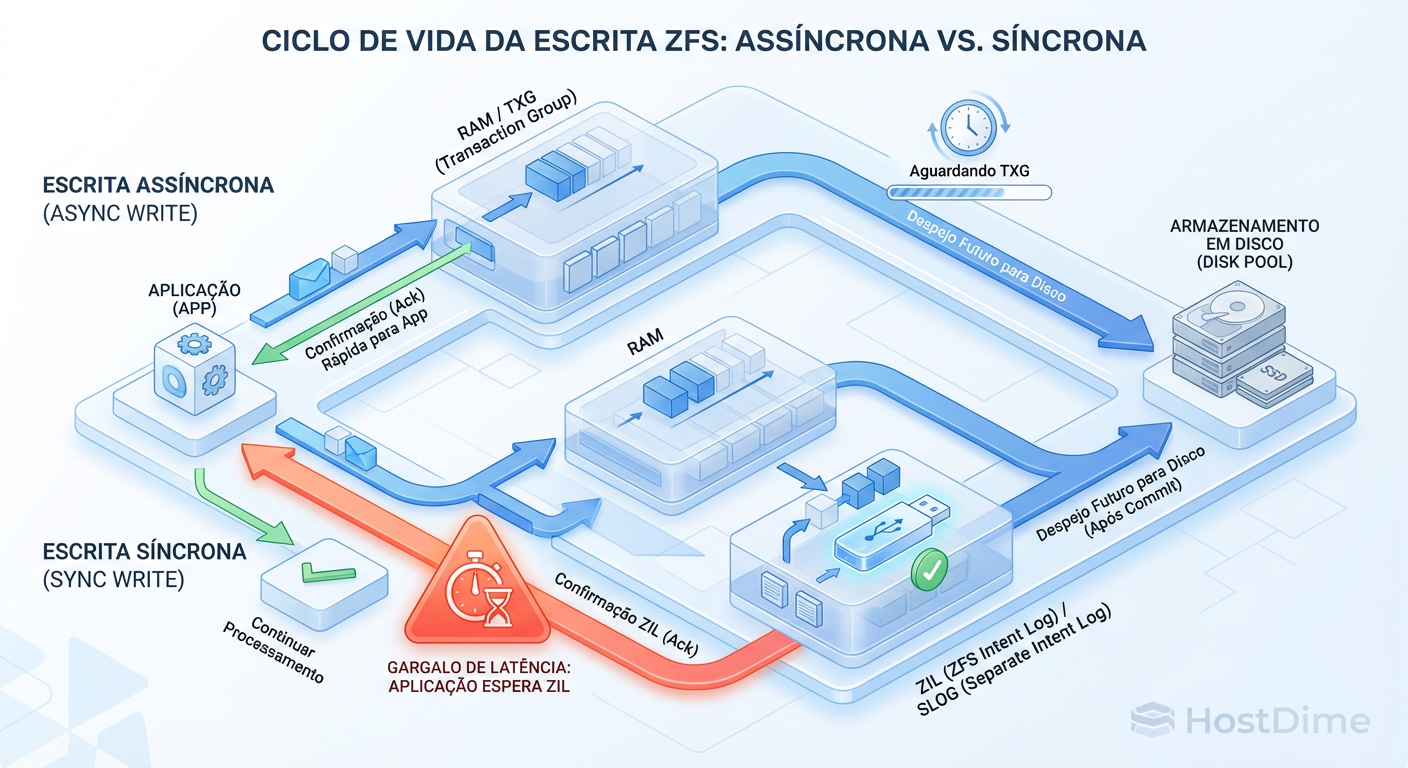 Figura: O Ciclo de Vida da Escrita: O SLOG apenas encurta o tempo de 'Ack' para escritas síncronas. Ele não aumenta a banda total do pool.
Figura: O Ciclo de Vida da Escrita: O SLOG apenas encurta o tempo de 'Ack' para escritas síncronas. Ele não aumenta a banda total do pool.
O ponto crucial que muitos ignoram: O SLOG nunca é lido, exceto se o servidor travar e precisar recuperar dados após um reboot. Ele é um diário de bordo descartável. O dado real ainda vai para o pool principal via TXG. O SLOG apenas permite que o ZFS envie o "Ack" (confirmação) para a aplicação mais rápido.
Sync vs. Async: Identificando o Suspeito
Antes de comprar hardware, você precisa interrogar suas aplicações. Quem está segurando a performance?
Se o seu workload é composto por compartilhamento de arquivos SMB (Windows), cópia de arquivos grandes, ou compilação de código, a vasta maioria dessas operações é Assíncrona. O sistema operacional cliente diz "grave isso", o ZFS coloca na RAM, diz "ok, gravei" (mentira branca) e o cliente segue a vida.
Nesse cenário, um SLOG tem impacto zero. Ele ficará ocioso, enquanto você reclama da lentidão.
A Lista de Suspeitos Habituais (Sync Writes)
NFS (Network File System): O vilão clássico. Por padrão (RFC compliance), o NFS exige que toda gravação seja estável no disco antes de responder. É aqui que o SLOG brilha.
iSCSI / Block Storage: Depende da configuração, mas frequentemente usado por virtualizadores que exigem sync writes.
Bancos de Dados (MySQL, PostgreSQL): Os logs de transação (WAL/Redo Logs) exigem sync writes para garantir consistência.
Se você não está rodando um desses protocolos ou aplicações configuradas especificamente para fsync ou O_DSYNC, você não tem um problema de SLOG. Você tem um problema de largura de banda ou IOPS do pool principal.
Investigação Forense: Métricas, não Suposições
Como provamos que o gargalo é o Sync Write? Não olhe para a CPU. Olhe para a latência de operação e o tipo de solicitação.
Se você tem acesso ao comando zilstat (comum em sistemas baseados em Illumos ou BSD, mais raro em Linux), ele é a arma fumegante. Mas no ZFS on Linux (ZoL), podemos usar o zpool iostat para inferir o problema.
Execute o seguinte comando durante um momento de lentidão:
# Monitorar latência de IO com detalhamento de filas
zpool iostat -r 5
Observe as colunas de Sync Read e Sync Write. Se a latência de Sync Write estiver alta (acima de 10ms é preocupante para flash, acima de 50ms é trágico), você tem um problema.
Mas a prova definitiva vem ao verificar se o ZIL está sendo pressionado. Se você já tem um SLOG (log device), verifique se ele está recebendo tráfego:
zpool iostat -v 2
Se a linha do seu dispositivo de log mostrar 0 ou poucos KB/s de escrita enquanto o servidor está "lento", o SLOG não é o seu gargalo e nem a sua solução. O tráfego está passando direto para o pool principal (assíncrono) ou você está limitado por leitura.
O Teste do "sync=disabled" (Apenas para Diagnóstico)
Existe uma maneira brutalmente eficaz de confirmar se o SLOG resolveria seu problema sem gastar um centavo. Aviso: Não faça isso em produção com dados críticos sem backup.
Você pode dizer ao ZFS para ignorar os pedidos de segurança das aplicações e tratar tudo como assíncrono:
zfs set sync=disabled tank/dataset
Se a performance do seu banco de dados ou VM disparar instantaneamente após esse comando, parabéns: você confirmou a necessidade de um dispositivo de Log rápido. Agora, reverta a configuração (zfs set sync=standard) e vá comprar o hardware certo.
O Cemitério de SSDs: Por que drives de consumo são inúteis
Aqui é onde a maioria dos administradores falha. Eles confirmam a necessidade de um SLOG e compram um SSD Samsung EVO ou similar, focado em "consumidor gamer".
Isso é um erro fatal.
Para que o ZFS confie no SLOG, ele envia um comando de Flush para o drive. Ele diz: "Esvazie seu cache DRAM interno e escreva na memória NAND agora".
SSDs de consumo odeiam isso. Eles dependem do cache DRAM para mascarar a lentidão da memória NAND. Quando forçados a fazer flush a cada milissegundo (como em um workload de banco de dados), a performance deles cai para níveis de um HDD mecânico, ou pior.
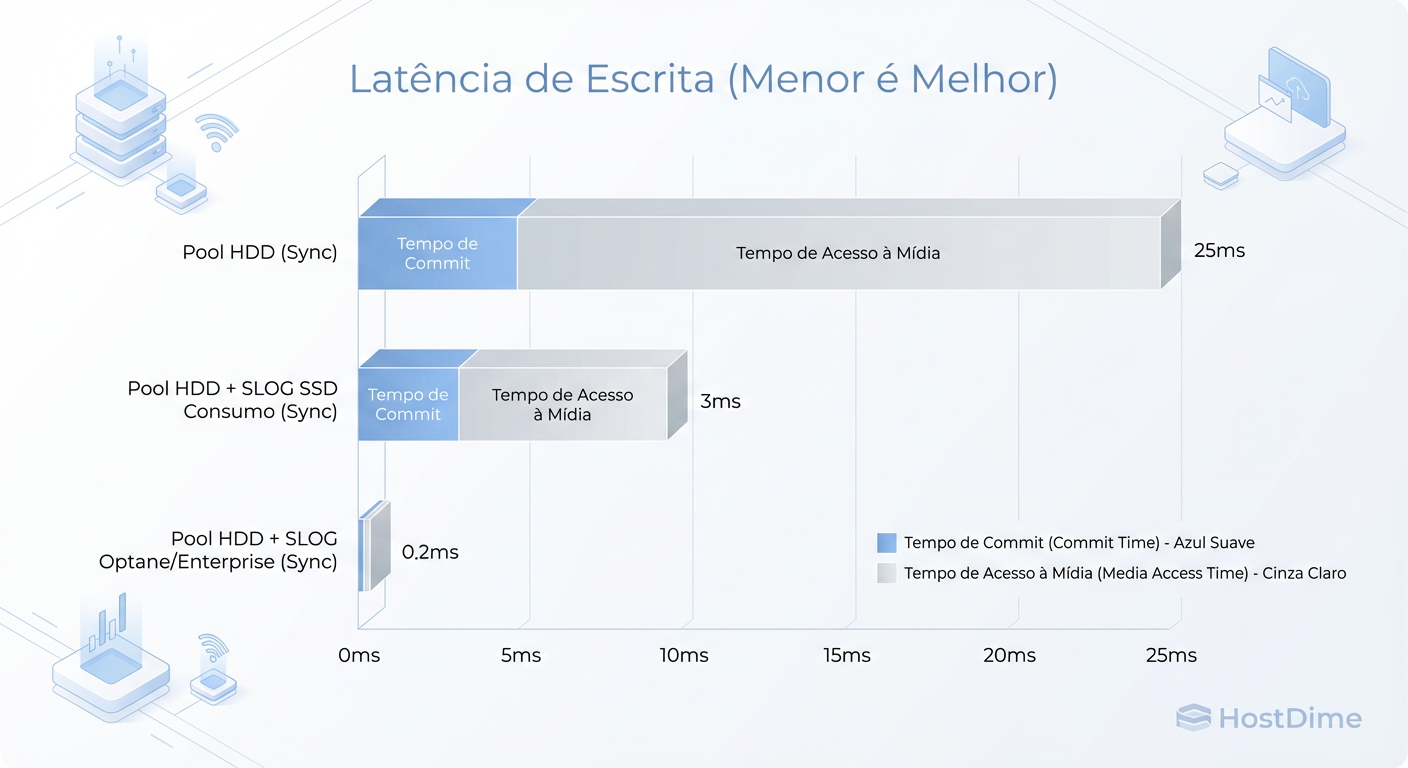 Figura: A Ilusão do SSD Barato: Sem PLP (Power Loss Protection), um SSD comum pode ser tão lento quanto um HDD para sync writes devido ao flush de cache forçado.
Figura: A Ilusão do SSD Barato: Sem PLP (Power Loss Protection), um SSD comum pode ser tão lento quanto um HDD para sync writes devido ao flush de cache forçado.
O Requisito Obrigatório: PLP (Power Loss Protection)
Para um SLOG, você precisa de um drive com PLP. São capacitores visíveis na placa do SSD.
Eles permitem que o drive minta para o ZFS: "Sim, gravei no disco", enquanto o dado ainda está na DRAM rápida do SSD. Se a energia cair, os capacitores mantêm o drive vivo por tempo suficiente para salvar a DRAM na NAND.
Sem PLP, o drive tem que escrever na NAND de verdade antes de responder. Com PLP, ele responde na velocidade da DRAM. A diferença de performance para Sync Writes pode ser de 10x a 100x.
Dica de Perito: Drives Intel Optane (3D XPoint) eram o "padrão ouro" para SLOG porque a mídia em si é rápida e não volátil, dispensando o ciclo complexo de flush da NAND. Mesmo descontinuados, ainda são imbatíveis para essa função.
Veredito e Trade-offs
Você isolou a variável, mediu a latência e entendeu o hardware. Agora, qual é a decisão operacional?
| Cenário | Sintoma | Ação Recomendada | Risco |
|---|---|---|---|
| Home Lab / Mídia | Lento em cópias SMB | Não use SLOG. Adicione mais RAM (ARC) ou mais vdevs. | Baixo. O gargalo não é sync. |
| VMware / NFS | VMs travando, latência alta | SLOG Corporativo (PLP). Optane ou NVMe Enterprise. | Nenhum, é a solução correta. |
| Banco de Dados Crítico | Commit lento, iowait alto |
SLOG Corporativo. Essencial para reduzir latência de commit. | Nenhum. |
| Ambiente de Teste/Dev | Lento, dados descartáveis | zfs set sync=disabled |
Alto. Se a luz piscar, o banco de dados corrompe. |
Veredito Técnico do Investigador
O SLOG não é um turbo para seu carro; é um freio ABS de alta performance. Ele não faz você ir mais rápido na reta (throughput máximo), mas permite que você faça curvas perigosas (sync writes) sem perder o controle (latência).
Não adicione complexidade ao seu pool sem evidência. Use zpool iostat. Verifique se o gargalo é síncrono. E se for comprar um SLOG, compre um que tenha capacitores, ou você estará apenas adicionando mais um ponto de falha inútil ao seu sistema.

Priya Patel
Data Center Operations Lead
Gerencia milhares de discos físicos. Sabe exatamente qual modelo de HDD vibra mais e qual SSD morre primeiro.