Snapshots O Que Sao E Como Proteger Contra Erro Humano

Snapshots não são cópias físicas de dados, são tabelas de ponteiros congeladas no tempo. Enquanto o método legado *Copy-on-Write* (CoW) penaliza a escrita ao mover dados antigos antes de sobrescrever, o moderno *Redirect-on-Write* (RoW) elimina essa latência escrevendo novos dados em blocos livres. Eles são sua defesa primária contra `rm -rf` e erros lógicos, permitindo RPOs de segundos, mas lembre-se: se o storage array falhar, seus snapshots morrem junto — eles nunca substituem um backup real. --- Se você já sentiu o sangue gelar após digitar um `DROP TABLE` ou um `rm -rf` no diretório errado, você entende o valor do tempo. Nesses momentos, restaurar de um backup (que pode ter horas de idade e levar horas para ser copiado) é inaceitável. É aqui que entra o snapshot. Muitos administradores tratam snapshots como "mágica", mas entender a mecânica de I/O por trás deles — especificamente a diferença entre **Copy-on-Write (CoW)** e **Redirect-on-Write (RoW)** — é o que separa quem recupera o ambiente em 30 segundos de quem derruba a performance do storage inteiro tentando salvar o dia. ## O que é um Snapshot (Nível de Bloco) No nível mais fundamental, em um ambiente de [Block, File e Object Storage](/articles/tipos-de-armazenamento-block-file-object), um snapshot **não é uma cópia dos dados**. É uma cópia dos **metadados** (ponteiros) que mapeiam onde os dados residem fisicamente no disco naquele exato momento. Quando você tira um snapshot, o sistema congela o mapa de blocos. O volume continua operando, mas o comportamento de escrita muda drasticamente dependendo da tecnologia subjacente. ## Copy-on-Write (CoW): O Modelo Tradicional O método CoW (usado classicamente pelo LVM no Linux e snapshots antigos de SANs) é robusto, mas introduz uma penalidade de escrita severa. **O fluxo de uma escrita em um volume com Snapshot CoW:** 1. A aplicação envia uma solicitação de escrita para o Bloco A. 2. O storage detecta que o Bloco A é protegido por um snapshot e ainda não foi modificado. 3. **Leitura:** O storage lê o conteúdo original do Bloco A. 4. **Cópia:** O storage escreve esse conteúdo original em uma área reservada (Snapshot Reserve). 5. **Escrita:** O storage finalmente sobrescreve o Bloco A com o novo dado da aplicação. Isso transforma 1 I/O de escrita lógico em **3 operações físicas de I/O** (1 Leitura + 2 Escritas). Isso é conhecido como "Write Penalty". 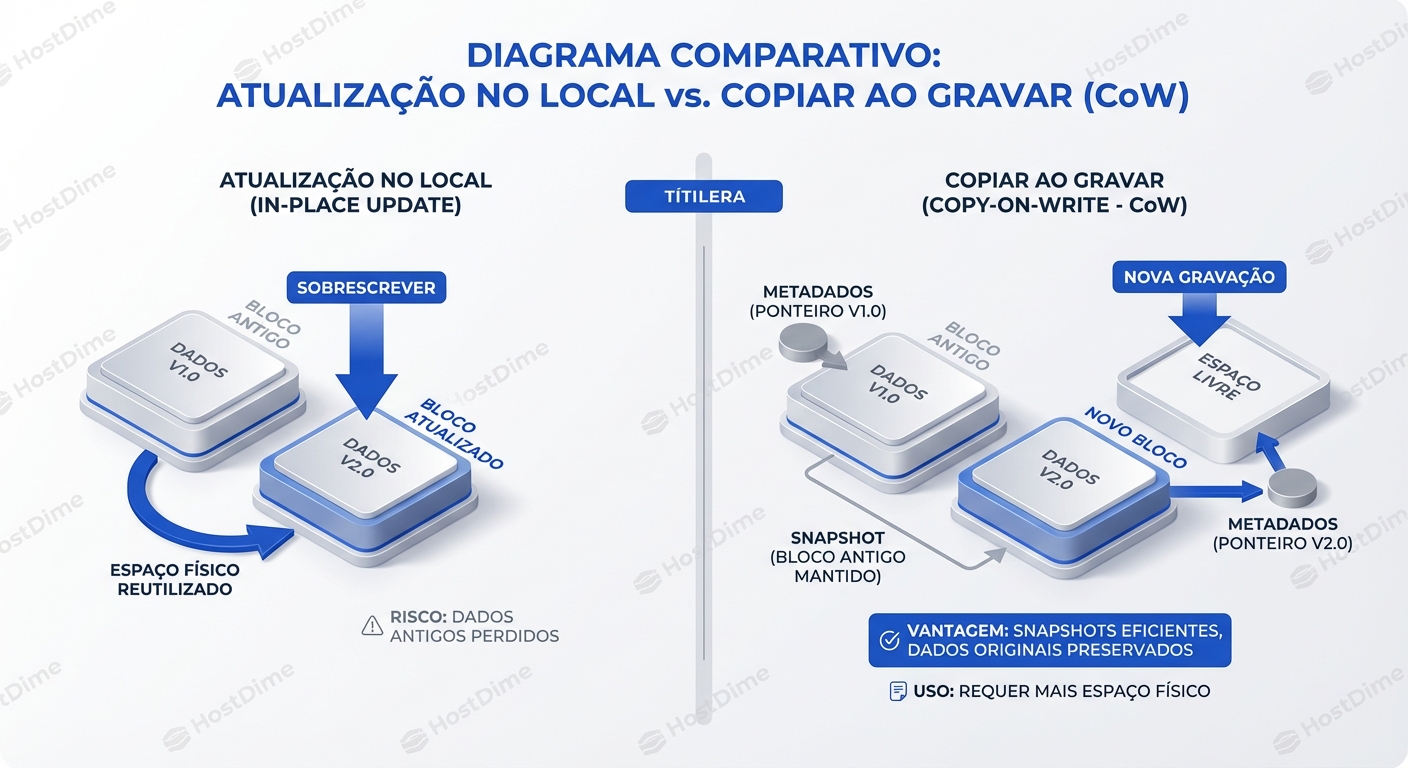 ### Exemplo Prático: LVM (Linux) No Linux, o LVM usa CoW. Se você criar um snapshot muito pequeno para um volume com alta taxa de alteração, o snapshot ficará inválido (corrompido) assim que a área reservada encher. ```bash # CUIDADO: Se as alterações no original excederem 1GB, o snapshot morre. lvcreate -L 1G -s -n lv_dados_snap /dev/vg01/lv_dados # Verificando o estado e preenchimento do snapshot lvs -o lv_name,snap_percent,origin ``` ## Redirect-on-Write (RoW): A Abordagem Moderna O RoW (usado por ZFS, NetApp WAFL, e storages modernos all-flash) resolve o problema da penalidade de escrita. **O fluxo de uma escrita em um volume com Snapshot RoW:** 1. A aplicação envia uma solicitação de escrita para o Bloco A. 2. O storage **não toca** no Bloco A original (ele permanece onde está, apontado pelo snapshot). 3. **Redirecionamento:** O storage escreve o novo dado em um **novo bloco livre** (Bloco B). 4. O ponteiro do volume ativo é atualizado para apontar para o Bloco B. Resultado: 1 I/O lógico = 1 I/O físico. Não há penalidade de leitura antes da escrita. A desvantagem histórica do RoW era a fragmentação (os dados ficam espalhados pelo disco), mas com a latência de busca quase nula dos SSDs/NVMe, isso se tornou irrelevante. ## Comparativo Técnico: CoW vs. RoW | Característica | Copy-on-Write (CoW) | Redirect-on-Write (RoW) | | :--- | :--- | :--- | | **Penalidade de Escrita** | Alta (3 I/Os por escrita). | Nula ou Mínima (1 I/O por escrita). | | **Performance de Leitura** | Alta no volume original (dados contíguos). | Pode degradar com o tempo (fragmentação), mitigado por SSDs. | | **Uso de Espaço** | Cresce conforme dados originais são alterados. | Cresce conforme novos dados são escritos. | | **Rollback (Reversão)** | Lento (precisa copiar dados de volta). | Instantâneo (apenas reverte ponteiros). | | **Exemplos** | LVM (Linux), VMware (VMFS), SANs Legadas. | ZFS, Btrfs, NetApp, Pure Storage, Ceph. | Como discutimos em [IOPS, Throughput e Latência: O Triângulo Mágico do Storage](/articles/iops-throughput-latencia-guia-completo), entender essas penalidades é vital para não saturar suas controladoras durante o horário de pico. ## A Mecânica do Rollback: Defesa Contra Erro Humano A principal função do snapshot para o Sysadmin é a reversão rápida. Diferente de um restore de backup que move terabytes de dados, o rollback de snapshot é uma operação de metadados. 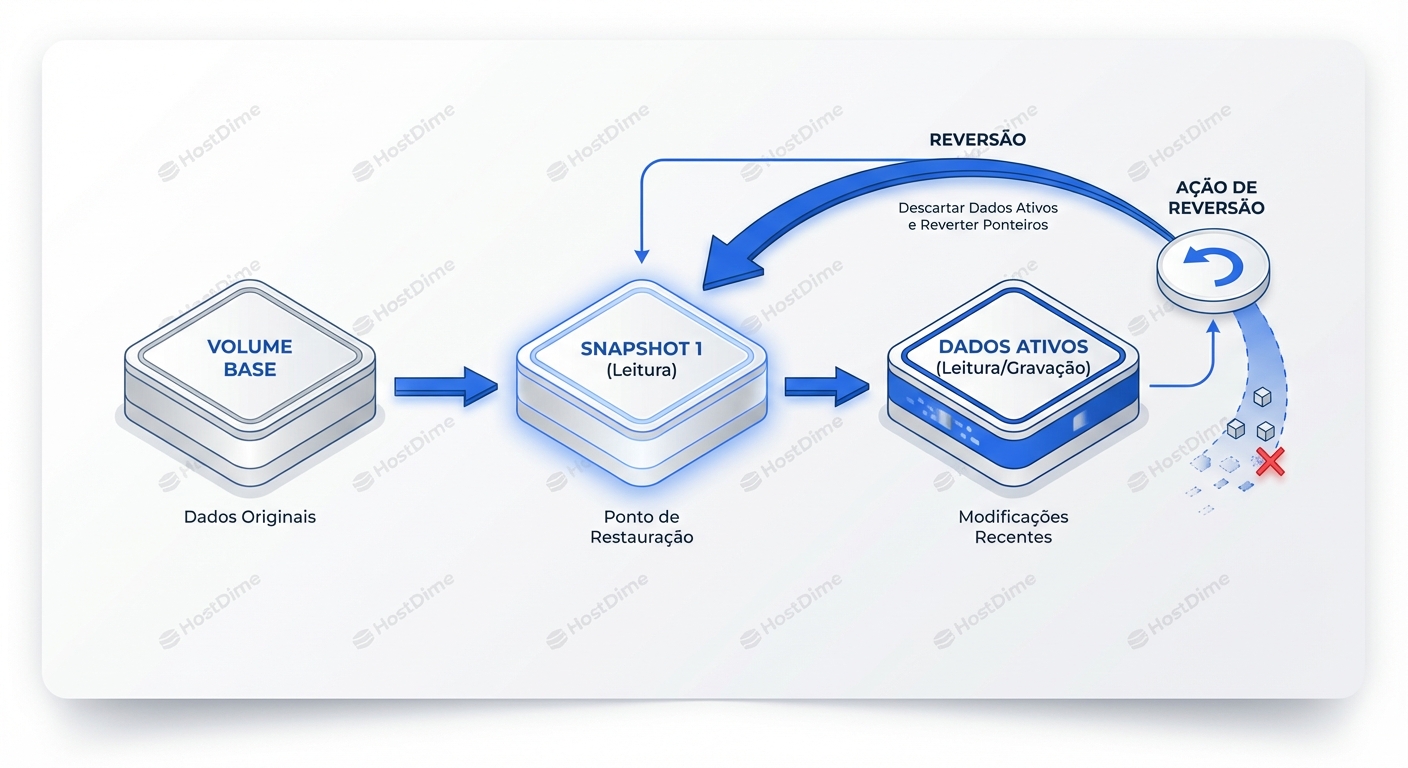 Quando você executa um rollback, você está dizendo ao sistema de arquivos: "Descarte todos os blocos escritos após o Timestamp X e faça o ponteiro mestre apontar para a árvore de blocos do Timestamp X". ### Cenário Real: ZFS Rollback Imagine que um desenvolvedor rodou uma migração de banco de dados que corrompeu dados críticos. Se você usa ZFS: ```bash # 1. Listar snapshots disponíveis zfs list -t snapshot # Saída: # NAME USED AVAIL REFER MOUNTPOINT # tank/db@2023-10-27-0800 150M - 100G - # tank/db@2023-10-27-0900 50M - 101G - # 2. O desastre ocorreu às 09:15. Revertendo para as 09:00. # AVISO: Isso destrói qualquer dado criado APÓS as 09:00. zfs rollback -r tank/db@2023-10-27-0900 ``` Essa operação leva menos de 1 segundo, independentemente se o volume tem 100GB ou 10TB. Isso permite definir [RPO e RTO](/articles/rpo-e-rto-como-definir-metas-realistas) extremamente agressivos para falhas lógicas. ## O Perigo: Snapshots não são Backup Este é o erro mais comum que vejo juniores cometerem. **Snapshots dependem da integridade dos blocos originais no storage.** Se você tem um storage com RAID 5 e perde 2 discos (falha catastrófica do array), você perdeu o volume **E** os snapshots. O snapshot reside na mesma estrutura física. Além disso, cadeias longas de snapshots (especialmente em modelos CoW como VMware) degradam a performance. Cada leitura de um bloco não modificado pode ter que percorrer uma cadeia de "delta files" para encontrar o dado correto. **Regra de Ouro:** Use snapshots para proteção operacional de curto prazo (horas/dias) e recuperação de erros lógicos. Use backups (em outro media/location) para proteção contra desastres e retenção de longo prazo. Veja mais sobre isso em [RAID não é backup: cenários reais de perda de dados](/articles/raid-nao-e-backup-cenarios-reais-de-perda-de-dados). ## Conclusão Para o Sysadmin Sênior, snapshots são ferramentas de precisão. 1. Prefira tecnologias **RoW** (como ZFS ou arrays modernos) para evitar impacto em produção. 2. Monitore o **consumo de espaço** (snapshots de volumes com alta taxa de escrita enchem o disco rapidamente). 3. Nunca confie neles como sua única cópia dos dados. Dominar essa mecânica permite que você ofereça à sua empresa uma "máquina do tempo" rápida e eficiente, transformando crises potenciais em meros inconvenientes de alguns minutos.
Snapshots O Que Sao E Como Proteger Contra Erro Humano
Resumo Executivo (TL;DR): Snapshots não são cópias físicas de dados, são tabelas de ponteiros congeladas no tempo. Enquanto o método legado Copy-on-Write (CoW) penaliza a escrita ao mover dados antigos antes de sobrescrever, o moderno Redirect-on-Write (RoW) elimina essa latência escrevendo novos dados em blocos livres. Eles são sua defesa primária contra
rm -rfe erros lógicos, permitindo RPOs de segundos, mas lembre-se: se o storage array falhar, seus snapshots morrem junto — eles nunca substituem um backup real.
Se você já sentiu o sangue gelar após digitar um DROP TABLE ou um rm -rf no diretório errado, você entende o valor do tempo. Nesses momentos, restaurar de um backup (que pode ter horas de idade e levar horas para ser copiado) é inaceitável. É aqui que entra o snapshot.
Muitos administradores tratam snapshots como "mágica", mas entender a mecânica de I/O por trás deles — especificamente a diferença entre Copy-on-Write (CoW) e Redirect-on-Write (RoW) — é o que separa quem recupera o ambiente em 30 segundos de quem derruba a performance do storage inteiro tentando salvar o dia.
O que é um Snapshot (Nível de Bloco)
No nível mais fundamental, em um ambiente de Block, File e Object Storage, um snapshot não é uma cópia dos dados. É uma cópia dos metadados (ponteiros) que mapeiam onde os dados residem fisicamente no disco naquele exato momento.
Quando você tira um snapshot, o sistema congela o mapa de blocos. O volume continua operando, mas o comportamento de escrita muda drasticamente dependendo da tecnologia subjacente.
Copy-on-Write (CoW): O Modelo Tradicional
O método CoW (usado classicamente pelo LVM no Linux e snapshots antigos de SANs) é robusto, mas introduz uma penalidade de escrita severa.
O fluxo de uma escrita em um volume com Snapshot CoW:
- A aplicação envia uma solicitação de escrita para o Bloco A.
- O storage detecta que o Bloco A é protegido por um snapshot e ainda não foi modificado.
- Leitura: O storage lê o conteúdo original do Bloco A.
- Cópia: O storage escreve esse conteúdo original em uma área reservada (Snapshot Reserve).
- Escrita: O storage finalmente sobrescreve o Bloco A com o novo dado da aplicação.
Isso transforma 1 I/O de escrita lógico em 3 operações físicas de I/O (1 Leitura + 2 Escritas). Isso é conhecido como "Write Penalty".

Exemplo Prático: LVM (Linux)
No Linux, o LVM usa CoW. Se você criar um snapshot muito pequeno para um volume com alta taxa de alteração, o snapshot ficará inválido (corrompido) assim que a área reservada encher.
# CUIDADO: Se as alterações no original excederem 1GB, o snapshot morre.
lvcreate -L 1G -s -n lv_dados_snap /dev/vg01/lv_dados
# Verificando o estado e preenchimento do snapshot
lvs -o lv_name,snap_percent,origin
Redirect-on-Write (RoW): A Abordagem Moderna
O RoW (usado por ZFS, NetApp WAFL, e storages modernos all-flash) resolve o problema da penalidade de escrita.
O fluxo de uma escrita em um volume com Snapshot RoW:
- A aplicação envia uma solicitação de escrita para o Bloco A.
- O storage não toca no Bloco A original (ele permanece onde está, apontado pelo snapshot).
- Redirecionamento: O storage escreve o novo dado em um novo bloco livre (Bloco B).
- O ponteiro do volume ativo é atualizado para apontar para o Bloco B.
Resultado: 1 I/O lógico = 1 I/O físico. Não há penalidade de leitura antes da escrita.
A desvantagem histórica do RoW era a fragmentação (os dados ficam espalhados pelo disco), mas com a latência de busca quase nula dos SSDs/NVMe, isso se tornou irrelevante.
Comparativo Técnico: CoW vs. RoW
| Característica | Copy-on-Write (CoW) | Redirect-on-Write (RoW) |
|---|---|---|
| Penalidade de Escrita | Alta (3 I/Os por escrita). | Nula ou Mínima (1 I/O por escrita). |
| Performance de Leitura | Alta no volume original (dados contíguos). | Pode degradar com o tempo (fragmentação), mitigado por SSDs. |
| Uso de Espaço | Cresce conforme dados originais são alterados. | Cresce conforme novos dados são escritos. |
| Rollback (Reversão) | Lento (precisa copiar dados de volta). | Instantâneo (apenas reverte ponteiros). |
| Exemplos | LVM (Linux), VMware (VMFS), SANs Legadas. | ZFS, Btrfs, NetApp, Pure Storage, Ceph. |
Como discutimos em IOPS, Throughput e Latência: O Triângulo Mágico do Storage, entender essas penalidades é vital para não saturar suas controladoras durante o horário de pico.
A Mecânica do Rollback: Defesa Contra Erro Humano
A principal função do snapshot para o Sysadmin é a reversão rápida. Diferente de um restore de backup que move terabytes de dados, o rollback de snapshot é uma operação de metadados.

Quando você executa um rollback, você está dizendo ao sistema de arquivos: "Descarte todos os blocos escritos após o Timestamp X e faça o ponteiro mestre apontar para a árvore de blocos do Timestamp X".
Cenário Real: ZFS Rollback
Imagine que um desenvolvedor rodou uma migração de banco de dados que corrompeu dados críticos. Se você usa ZFS:
# 1. Listar snapshots disponíveis
zfs list -t snapshot
# Saída:
# NAME USED AVAIL REFER MOUNTPOINT
# tank/db@2023-10-27-0800 150M - 100G -
# tank/db@2023-10-27-0900 50M - 101G -
# 2. O desastre ocorreu às 09:15. Revertendo para as 09:00.
# AVISO: Isso destrói qualquer dado criado APÓS as 09:00.
zfs rollback -r tank/db@2023-10-27-0900
Essa operação leva menos de 1 segundo, independentemente se o volume tem 100GB ou 10TB. Isso permite definir RPO e RTO extremamente agressivos para falhas lógicas.
O Perigo: Snapshots não são Backup
Este é o erro mais comum que vejo juniores cometerem. Snapshots dependem da integridade dos blocos originais no storage.
Se você tem um storage com RAID 5 e perde 2 discos (falha catastrófica do array), você perdeu o volume E os snapshots. O snapshot reside na mesma estrutura física.
Além disso, cadeias longas de snapshots (especialmente em modelos CoW como VMware) degradam a performance. Cada leitura de um bloco não modificado pode ter que percorrer uma cadeia de "delta files" para encontrar o dado correto.
Regra de Ouro: Use snapshots para proteção operacional de curto prazo (horas/dias) e recuperação de erros lógicos. Use backups (em outro media/location) para proteção contra desastres e retenção de longo prazo. Veja mais sobre isso em RAID não é backup: cenários reais de perda de dados.
Conclusão
Para o Sysadmin Sênior, snapshots são ferramentas de precisão.
- Prefira tecnologias RoW (como ZFS ou arrays modernos) para evitar impacto em produção.
- Monitore o consumo de espaço (snapshots de volumes com alta taxa de escrita enchem o disco rapidamente).
- Nunca confie neles como sua única cópia dos dados.
Dominar essa mecânica permite que você ofereça à sua empresa uma "máquina do tempo" rápida e eficiente, transformando crises potenciais em meros inconvenientes de alguns minutos.

Kenji Tanaka
Especialista em Performance de I/O
Obscecado por latência zero. Analisa traces de kernel e otimiza drivers de storage para bancos de dados de alta frequência.