Spanning Tree E Storage Armadilhas Em L2

Para entender o problema, precisamos alinhar nosso modelo mental sobre como um switch funciona versus como o Spanning Tree *pensa* que ele deve funcionar....
Spanning Tree E Storage Armadilhas Em L2
A Amnésia Programada: O Modelo Mental do TCN
Para entender o problema, precisamos alinhar nosso modelo mental sobre como um switch funciona versus como o Spanning Tree pensa que ele deve funcionar.
Um switch L2 opera baseando-se em aprendizado. Ele escuta o tráfego de entrada, olha o endereço MAC de origem e anota na sua tabela CAM (Content Addressable Memory): "O servidor DB-01 está na porta 5". Quando chega um pacote destinado ao DB-01, o switch consulta essa tabela e envia o pacote apenas para a porta 5. Isso é Unicast. É eficiente, seguro e silencioso.
O Spanning Tree Protocol (STP) tem um objetivo primário: evitar loops. Se houver dois caminhos para o mesmo lugar, ele bloqueia um. Até aí, tudo bem. O problema surge quando algo na rede muda.
Se uma porta muda de estado (Up para Down, ou Down para Up), o STP assume o pior cenário: a topologia da rede foi alterada, e os caminhos que ele conhecia podem não ser mais válidos. Para evitar enviar tráfego para um "buraco negro" ou criar um loop em um novo caminho, o STP decide que a informação antiga não é confiável.
O mecanismo de defesa é brutal: O Flush da Tabela MAC.
Quando um switch detecta uma mudança, ele envia um BPDU (Bridge Protocol Data Unit) com a flag TCN setada em direção ao Root Bridge. O Root Bridge então envia um BPDU de volta com a flag TC (Topology Change) setada, instruindo todos os switches no domínio de broadcast a reduzirem o tempo de vida (aging time) de suas entradas na tabela MAC.
Normalmente, um endereço MAC fica na tabela por 300 segundos (5 minutos). Durante um evento TCN, esse tempo cai para o tempo de Forward Delay (geralmente 15 segundos).
O resultado prático? As entradas expiram quase instantaneamente. O switch "esquece" onde o seu Storage Array e seus servidores estão conectados.
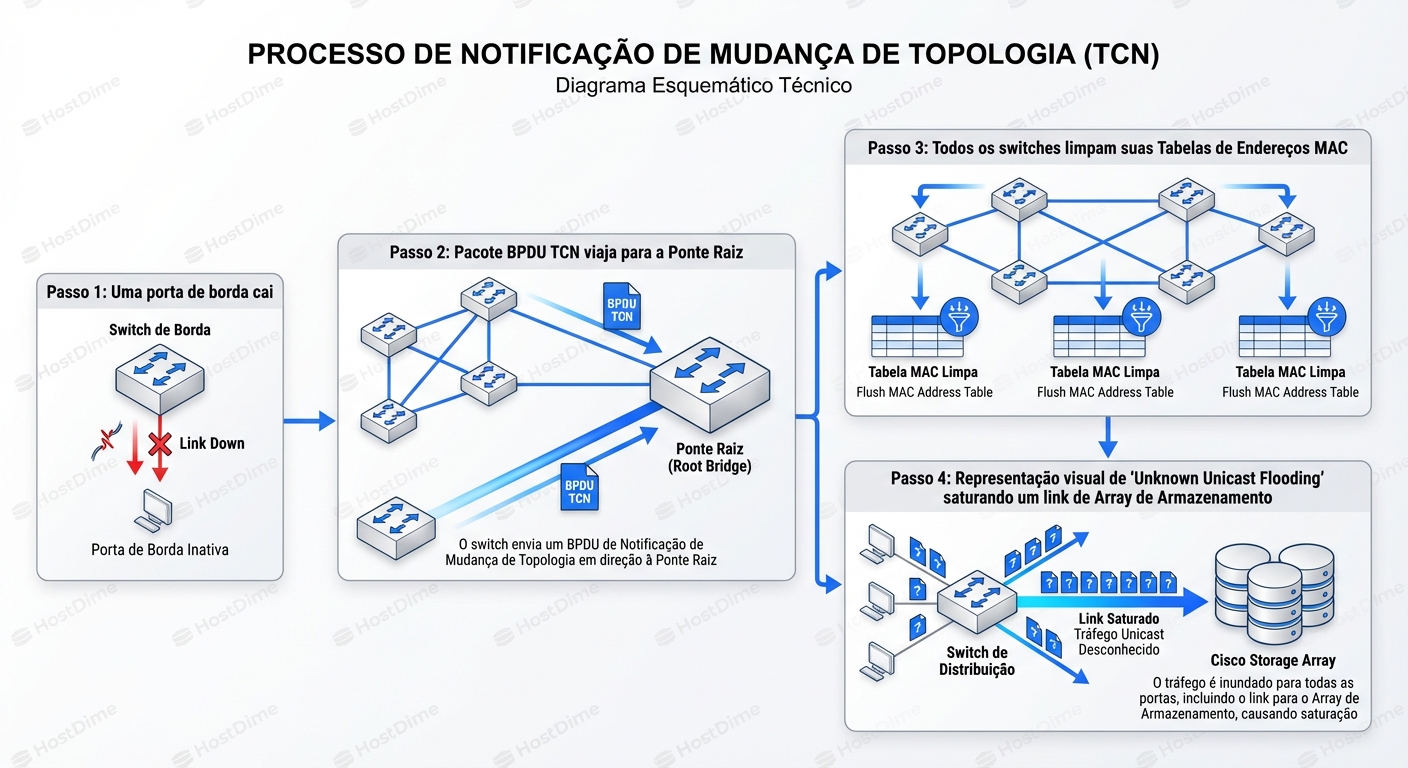
Quando o switch não sabe onde está o destino (MAC desconhecido), ele não tem escolha: ele deve fazer flooding. Ele copia o frame recebido para todas as portas ativas na mesma VLAN, exceto a porta de origem.
Imagine o tráfego de um backup ou de uma transação pesada de banco de dados via iSCSI. São gigabits de dados por segundo. De repente, esse tráfego, que deveria ser um fluxo direto ponto-a-ponto entre o Servidor e o Storage, é replicado para todas as portas do switch.
Isso causa três efeitos devastadores:
- Saturação de Links: Portas conectadas a dispositivos lentos (impressoras, desktops, interfaces de gerenciamento) ficam saturadas com lixo.
- Sobrecarga de CPU no Destino: Todas as placas de rede (NICs) na VLAN recebem esses pacotes e têm que processá-los até a camada 2 para descartá-los ("Isso não é para mim"). Isso rouba ciclos de CPU.
- Latência no Storage: O switch agora está agindo como um Hub. O backplane e os buffers do switch ficam congestionados. O tráfego legítimo de armazenamento entra na fila atrás do tráfego inundado. O iSCSI, que depende de baixa latência, começa a sofrer.
Anatomia do Desastre: Por que o iSCSI Quebra Primeiro?
Você pode se perguntar: "Ok, há um pouco de flooding, mas é TCP/IP, ele não deveria lidar com isso?"
O problema é a sensibilidade. O tráfego de rede "comum" (usuários acessando web, e-mail) é resiliente a variações de latência. O tráfego de bloco (SCSI sobre IP) não é.
Quando ocorre o Unknown Unicast Flooding:
- Perda de Pacotes: Os buffers das portas de switch enchem rapidamente. Pacotes iSCSI são descartados (dropped).
- TCP Retransmission: O host iniciador iSCSI percebe que o pacote não chegou. Ele espera o timeout (RTO) e retransmite. Isso adiciona latência massiva.
- Congestion Window Collapse: O protocolo TCP interpreta a perda de pacotes como congestionamento da rede (o que é verdade, neste caso). Ele reduz drasticamente a janela de transmissão (Congestion Window). O throughput despenca.
- SCSI Timeout: O sistema operacional (Linux/Windows) acima da camada TCP tem seus próprios temporizadores para operações de disco. Se a resposta de leitura/escrita demorar mais que o limite (ex: 30 ou 60 segundos), o OS assume que o disco morreu.
- Filesystem Read-Only: Para evitar corrupção de dados em um disco "falho", o kernel do Linux remonta o sistema de arquivos como somente leitura. O Windows pode gerar uma Tela Azul (BSOD) ou travar serviços críticos.
Tudo isso porque uma porta em um switch de acesso mudou de estado e ninguém configurou o STP corretamente.
Investigação Forense: Caçando o TCN
Como você prova que isso está acontecendo? A maioria dos sysadmins olha para logs de erro, mas o STP não gera "erros" por design; ele gera notificações. Você precisa saber onde olhar.
1. No Switch (Exemplo Cisco/Arista)
O comando mais valioso não é show spanning-tree, é show spanning-tree detail.
Switch# show spanning-tree vlan 10 detail
VLAN0010 is executing the rstp compatible Spanning Tree protocol
Bridge Identifier has priority 32768, sysid 10, address 001c.7300.1234
Configured hello time 2, max age 20, forward delay 15, transmit hold-count 6
We are the root of the spanning tree
Topology change flag not set, detected flag not set
Number of topology changes 5432 last change occurred 00:02:15 ago
from GigabitEthernet0/48
Como interpretar:
- Number of topology changes: Se este número estiver aumentando constantemente durante o dia, você tem um problema. Um ambiente estável deve ter esse contador quase estático.
- Last change occurred: Isso é a "arma do crime". Se a última mudança foi há 2 minutos e seus alertas de latência começaram há 2 minutos, você encontrou a causa.
- From [Interface]: Isso aponta de onde veio o TCN. Siga o cabo. Se vier de outro switch (uplink), logue naquele switch e repita o comando até encontrar a porta de acesso culpada.
2. No Linux (Host)
No lado do servidor, você não verá o TCN diretamente, mas verá as cicatrizes do flooding e da perda de pacotes.
Use o netstat ou nstat para verificar retransmissões TCP.
watch -n 1 "netstat -s | grep -i 'retrans'"
Se o contador segments retransmited saltar drasticamente em blocos (centenas ou milhares por segundo) ao mesmo tempo que a latência de disco sobe, é um forte indicador de problemas na camada de rede (L1/L2).
Para ver se a sua interface está recebendo lixo (flooding), você pode usar o tcpdump filtrando o que não é destinado ao seu MAC:
# e NÃO são destinados ao MAC da própria eth0.
tcpdump -i eth0 -n -e 'not ether dst [SEU_MAC_ADDRESS] and not ether broadcast and not ether multicast'
Em uma rede switchada saudável, esse comando deve retornar quase nada. Se você ver tráfego unicast destinado a outros servidores passando pela sua interface, você está testemunhando o Unknown Unicast Flooding em tempo real. O switch esqueceu os endereços e está gritando para todos.
A Vacina: PortFast e BPDU Guard
A solução não é desativar o STP (isso seria suicídio). A solução é dizer ao STP quais portas são seguras e não devem gerar TCNs.
PortFast (ou Edge Port)
O comando spanning-tree portfast (Cisco) ou spanning-tree port-type edge (Arista/outros) faz duas coisas críticas:
- Pula os estados de Listening e Learning: A porta vai direto para Forwarding. Isso é ótimo para DHCP, mas o foco aqui é o segundo ponto.
- Suprime TCNs: Quando uma porta configurada como "Edge" sobe ou desce, o switch NÃO gera um TCN. A topologia do resto da rede não é afetada.
Regra de Ouro: Toda porta que conecta a um dispositivo final (Servidor, Storage, Impressora, PC) deve ter PortFast habilitado. Sem exceções.
A Armadilha do PortFast e o BPDU Guard
"Mas e se um usuário trouxer um switch de casa e plugá-lo na tomada de parede com PortFast, criando um loop?"
Se você habilitou PortFast, o STP não está escutando loops antes de abrir a porta. O loop se formará instantaneamente. Para mitigar isso, usamos BPDU Guard.
O BPDU Guard diz: "Esta porta é para dispositivos finais. Dispositivos finais (PCs, Servidores) nunca enviam BPDUs (pacotes de STP). Se eu receber um BPDU nesta porta, alguém está mentindo ou cometeu um erro. Desligue a porta imediatamente (Error-Disable)."
Configuração típica de uma porta de acesso segura:
interface GigabitEthernet0/1
description Servidor-ESXi-iSCSI
switchport mode access
switchport access vlan 100
spanning-tree portfast
spanning-tree bpduguard enable
Arquitetura Moderna: Matando o Bloqueio
O Spanning Tree é um protocolo de prevenção de loop baseado em bloqueio. Em um cenário de storage, ter links redundantes parados (Blocking State) é um desperdício de dinheiro e largura de banda.
A abordagem moderna para redes de Storage e Datacenter é eliminar a dependência do STP para a topologia ativa, movendo-se para tecnologias de agregação de chassi, como MC-LAG (Multi-Chassis Link Aggregation), vPC (Cisco) ou MLAG (Arista).
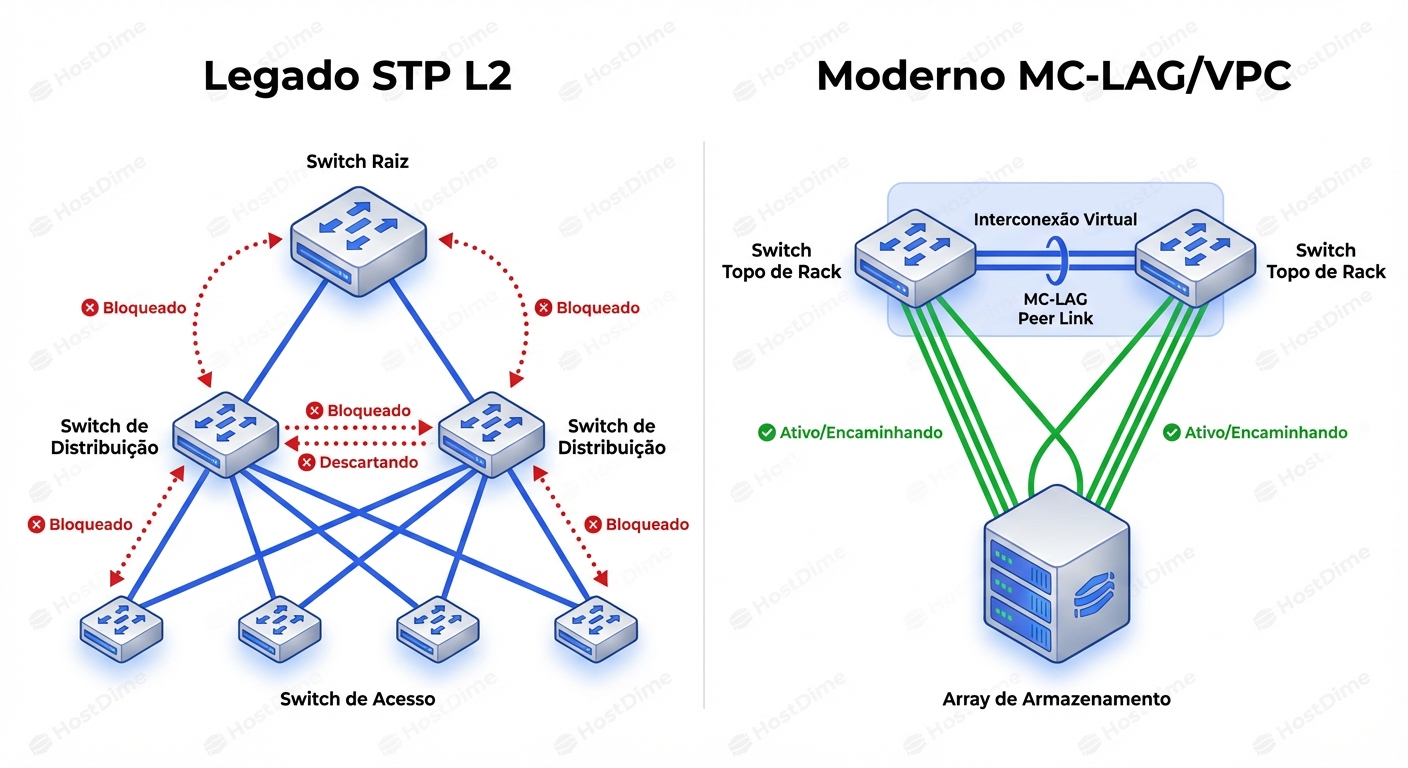
No modelo MC-LAG:
- Dois switches físicos conversam entre si e "fingem" ser um único switch lógico para os dispositivos conectados.
- O servidor ou storage conecta um cabo em cada switch usando LACP (Link Aggregation Control Protocol / 802.3ad).
- Não há portas bloqueadas. Ambos os links transmitem dados (Active/Active).
- O STP ainda roda como uma "rede de segurança" de último recurso, mas não gerencia os caminhos ativos do storage.
Isso elimina o problema do TCN? Em grande parte, sim. Como os switches coordenam as tabelas MAC entre si via um link peer-link dedicado, a falha de um link membro do LAG geralmente não propaga um TCN global da mesma forma destrutiva que uma porta STP pura faria, pois a "interface lógica" (Port-Channel) permanece UP.
Tabela de Impacto: STP vs. Realidade
Vamos comparar o comportamento esperado versus o comportamento real em diferentes cenários de configuração.
| Cenário | Configuração da Porta | Evento | Reação do Switch | Impacto no Storage |
|---|---|---|---|---|
| Padrão (Perigoso) | STP Normal (Sem PortFast) | Link Flap (Up/Down) | Gera TCN, envia para Root, Flush global de MACs. | Alto. Flooding massivo, latência, timeouts iSCSI. |
| Correto (Legado) | PortFast + BPDU Guard | Link Flap | Porta muda estado, mas NÃO gera TCN. | Nulo. O tráfego continua fluindo nos outros links sem flooding. |
| Acidental | PortFast (Sem BPDU Guard) | Switch não autorizado conectado | Loop L2 imediato. Tempestade de Broadcast. | Catastrófico. A rede inteira cai até o link ser removido. |
| Moderno | MC-LAG / vPC | Falha de um Uplink | Tráfego move para o link remanescente (hashing LACP). | Mínimo. Redução de banda, mas sem perda de conectividade ou flush global. |
O Fator Humano e a Disciplina Operacional
Muitas vezes, culpamos a tecnologia ("O iSCSI é instável"), quando a culpa é da implementação.
Se você gerencia uma rede convergente (onde tráfego de Storage e tráfego de Usuário compartilham os mesmos switches físicos, apenas separados por VLANs), o risco de TCNs é exponencial. Aquele switch de acesso no refeitório está no mesmo domínio de Spanning Tree que o seu Storage Array de missão crítica.
Se você não pode separar fisicamente os switches (Air-Gap), você deve:
- Usar MSTP (Multiple Spanning Tree Protocol): Criar instâncias de STP separadas. Uma instância para a VLAN de dados/usuários e outra para a VLAN de iSCSI. Assim, um TCN na VLAN de usuários não causa flush na tabela MAC da instância iSCSI.
- Root Guard: Proteger suas portas de Core para que switches de acesso mal configurados não tentem se tornar o Root Bridge e bagunçar toda a topologia.
Quando o L2 não é suficiente
O problema fundamental aqui é o tamanho do domínio de broadcast e a fragilidade do Ethernet L2. É por isso que os hyperscalers (Google, Facebook, AWS) praticamente abandonaram o L2 em grande escala.
Eles empurram o Roteamento (Layer 3) até o Top-of-Rack (ToR) ou até mesmo para dentro do host. Onde há roteamento, não há Spanning Tree, não há TCNs e não há flooding de unicast desconhecido. O protocolo de roteamento (OSPF, BGP) lida com a falha de link recalculando rotas, o que é muito mais gracioso que o "pânico e esquecimento" do STP.
Para a maioria das empresas, reestruturar tudo para L3 não é viável hoje. Mas entender que o iSCSI é um inquilino exigente é obrigatório.
Da próxima vez que você ver latência no storage sem motivo aparente nos discos, não olhe para o array. Olhe para os contadores de TCN no seu switch. Pergunte-se: "Quem acabou de plugar um cabo?". A estabilidade dos seus dados pode depender de uma configuração de porta que você ignorou anos atrás.
A rede não é apenas canos; é um sistema vivo que reage a estímulos. E o Spanning Tree é um sistema nervoso muito, muito ansioso. Trate-o com cuidado.

Thomas 'Raid0' Wright
High-Performance Computing Researcher
Trabalha com supercomputadores. Para ele, velocidade é tudo, e redundância é problema do software.