Storage AI e TCO: Quando a Escassez de IOPS Mata o ROI das GPUs
Descubra como a escassez de componentes e gargalos de performance no storage impactam o TCO de projetos de IA. Aprenda a calcular o custo real de GPUs ociosas.
Você já viu essa cena: um cluster de GPUs H100 recém-adquirido, custando centenas de milhares de dólares, operando a 40% de utilização. O culpado raramente é o código CUDA mal otimizado ou a largura de banda de rede. O gargalo silencioso, quase sempre, é um subsistema de armazenamento subdimensionado que não consegue alimentar a "besta" rápido o suficiente.
No design de infraestrutura para Inteligência Artificial, existe uma assimetria brutal. A velocidade de processamento das GPUs evoluiu exponencialmente, enquanto a latência de acesso ao dado físico (mesmo em NVMe) não acompanhou na mesma proporção. O resultado é o que chamamos de GPU Starvation (inanição da GPU).
Para o engenheiro de performance, Storage para AI não é sobre "guardar arquivos". É sobre manter um pipeline de dados saturado. Se o seu storage não entrega o batch de dados antes que a GPU termine o cálculo anterior, você não economizou dinheiro comprando discos mais baratos; você transformou um supercomputador em um aquecedor de ambiente muito caro.
O que é Storage-Induced GPU Starvation?
Storage-Induced GPU Starvation ocorre quando a taxa de transferência (throughput) ou a capacidade de operações por segundo (IOPS) do subsistema de armazenamento é inferior à velocidade de consumo de dados da GPU durante o treinamento ou inferência. Isso força a GPU a entrar em ciclos de espera (IDLE), reduzindo drasticamente o ROI da infraestrutura, pois o tempo de treinamento se estende desnecessariamente enquanto o hardware mais caro do data center permanece ocioso esperando por I/O.
O Paradoxo da IA e o Fluxo de Dados no Storage
O modelo mental ingênuo sugere que basta ter espaço em disco. A realidade física é que o treinamento de IA é um problema de vazão (throughput) e latência.
O fluxo de dados em um pipeline de Deep Learning moderno (como PyTorch ou TensorFlow) geralmente segue o padrão: Leitura do Disco -> Decodificação/Augmentation na CPU -> Transferência para VRAM da GPU via PCIe/NVLink -> Computação Matricial.
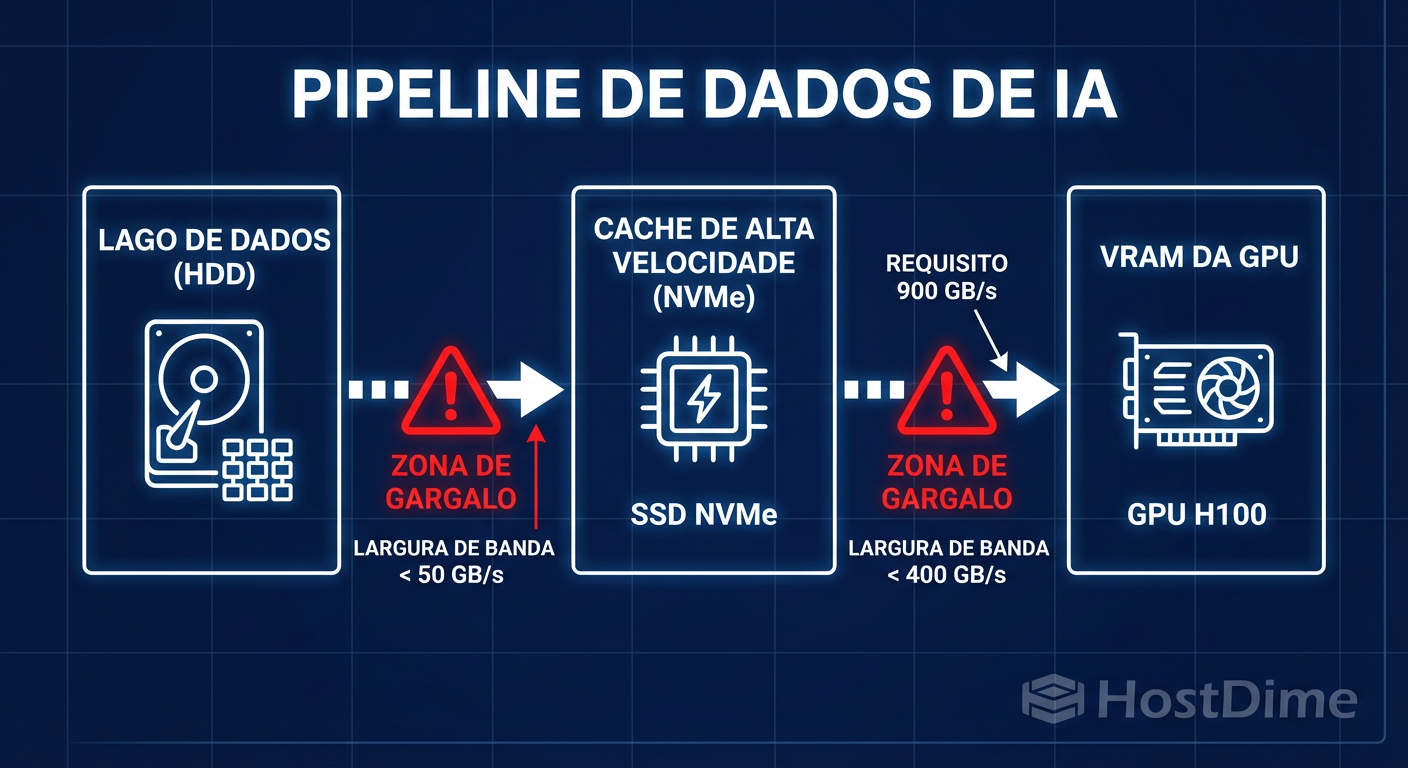 Figura: Fluxo de Dados em Infraestrutura de IA: Identificando onde a escassez de largura de banda cria gargalos reais no pipeline de treinamento.
Figura: Fluxo de Dados em Infraestrutura de IA: Identificando onde a escassez de largura de banda cria gargalos reais no pipeline de treinamento.
Se o primeiro passo (Leitura do Disco) for lento, todo o resto para. O paradoxo é que, para economizar 10% no orçamento total (CapEx) escolhendo SSDs de entrada ou NAS genéricos, as empresas aceitam uma degradação de 30-50% na eficiência operacional (OpEx/Tempo).
Diagnosticando Gargalos Reais
Não confie na folha de especificações do fabricante. O que importa é como o storage se comporta sob a carga específica do seu dataset. Um dataset de Visão Computacional (milhões de arquivos JPG pequenos de 50KB) gera um padrão de I/O aleatório brutal (Random Read), exigindo IOPS massivos. Um LLM (Large Language Model) lê arquivos binários gigantescos sequencialmente, exigindo Throughput (GB/s).
Para verificar se o storage é o culpado pela baixa utilização da GPU, pare de olhar para o nvidia-smi isoladamente. Olhe para o iostat em correlação com a GPU.
# Foco na coluna %iowait (CPU esperando disco) e aqu-sz (tamanho da fila).
iostat -xz 1 | grep nvme0n1
Se o aqu-sz (average queue size) estiver consistentemente alto e a utilização da GPU baixa, você tem evidência empírica de escassez de IOPS.
A Matemática do Desperdício no TCO de Storage
O Custo Total de Propriedade (TCO) em IA não pode ser calculado como Custo do Hardware / TB. Ele deve ser calculado como Custo da Solução / Unidade de Treinamento Concluída.
Vamos a um cenário hipotético, mas realista:
Custo da hora de GPU (Cluster): $500/hora.
Tempo de treinamento estimado (Storage Ideal): 100 horas ($50.000).
Tempo real devido à latência de I/O (Storage Lento): 140 horas ($70.000).
Neste cenário, um storage inadequado gerou um prejuízo direto de $20.000 em um único ciclo de treinamento. Se você "economizou" $15.000 comprando SSDs QLC sem DRAM cache em vez de Enterprise NVMe, você já está no prejuízo na primeira semana.
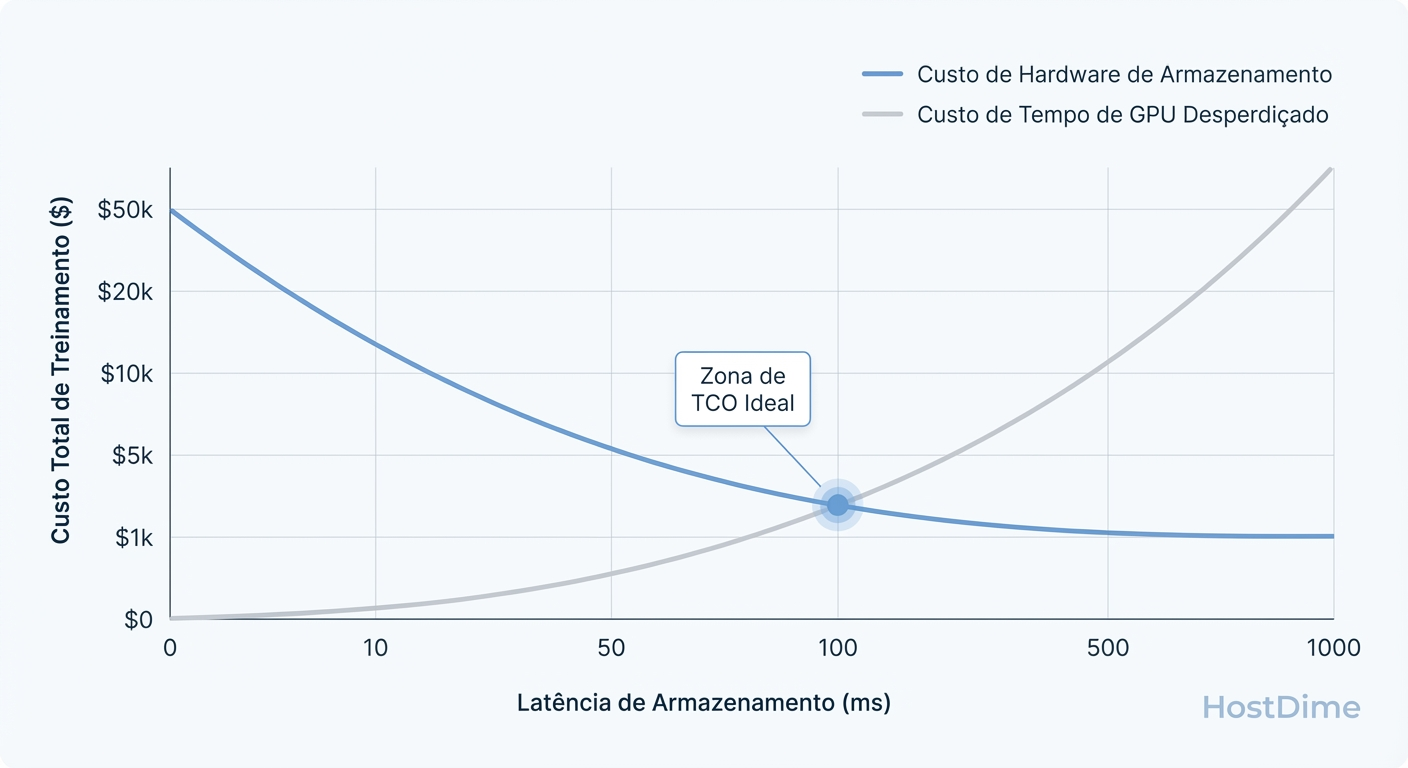 Figura: Gráfico de Trade-off no TCO de Storage AI: O ponto onde a economia em discos baratos é superada pelo custo de horas de GPU desperdiçadas.
Figura: Gráfico de Trade-off no TCO de Storage AI: O ponto onde a economia em discos baratos é superada pelo custo de horas de GPU desperdiçadas.
A escassez de IOPS não é apenas um problema técnico; é um vazamento financeiro. A latência é o imposto invisível que você paga em cada epoch.
Definindo Escassez: Disponibilidade de Mercado vs. Recursos Técnicos
Quando falamos de "Escassez" em Storage para AI, existem duas dimensões que afetam sua decisão de compra e arquitetura:
1. Escassez de Mercado (Ciclos de NAND)
O mercado de memória Flash (NAND) é cíclico. Em momentos de escassez de produção, o preço do TB dispara. O erro comum é reagir a essa escassez comprando mídia de pior qualidade (ex: QLC de consumo) para manter o orçamento.
- O Risco: SSDs de consumo não sustentam performance de escrita contínua. Eles possuem um cache SLC pequeno; quando esse cache enche (comum em checkpointing de modelos grandes), a velocidade cai de 3GB/s para 100MB/s, travando o cluster.
2. Escassez de Recursos (IOPS por TB)
Conforme a densidade dos SSDs aumenta (30TB, 60TB em um único drive), a performance por Terabyte tende a cair se o controlador não escalar junto. Um drive de 30TB tem a mesma interface PCIe x4 que um drive de 4TB.
- O Risco: Você compra Petabytes de capacidade, mas tem "poucos canais" para extrair esses dados. Para AI, muitas vezes é melhor ter 10 drives de 4TB (mais faixas de PCIe, mais controladores paralelos) do que 1 drive de 40TB, mesmo que o custo seja similar.
Escassez de Energia e Densidade no Data Center
O TCO moderno de AI esbarra em um limite físico: energia e refrigeração. Racks de GPU consomem 40kW, 60kW ou mais. Sobra pouca energia para o Storage.
Aqui, a densidade joga a favor do Flash, mas contra o HDD.
HDD: Para obter 10GB/s de throughput com HDDs, você precisa de centenas de discos (spindles), ocupando múltiplos racks e consumindo muita energia mecânica.
NVMe: Você consegue 10GB/s com um ou dois drives NVMe Gen4/5.
Se o seu data center cobra caro pelo espaço de rack ou pela energia, o "disco barato" (HDD) torna-se caro operacionalmente.
Comparativo de Mídias para Workloads de IA
| Atributo Técnico | NVMe Enterprise (TLC) | SSD SATA / Low-End NVMe (QLC) | HDD (Nearline SAS) |
|---|---|---|---|
| Latência (Acesso) | < 100 µs (Consistente) | 200 µs - 5 ms (Variável) | 5 ms - 15 ms |
| Throughput Sustentado | Altíssimo (não degrada) | Alto (até estourar o cache SLC) | Baixo (precisa de paralelismo massivo) |
| IOPS (Random Read) | > 800k | 50k - 200k | ~150 - 300 |
| Caso de Uso Ideal em IA | Hot Tier: Treinamento ativo, Scratch space. | Warm Tier: Inferência leve, Datasets pouco usados. | Cold Tier: Archival, Raw Data Lake, Checkpoints antigos. |
| Risco Principal | Custo inicial elevado (CapEx). | Write Cliff (queda brusca de performance). | Latência mata o pipeline de treinamento. |
Estratégias de Mitigação: Tiering e Caching Inteligente
Como resolver a equação de TCO sem falir comprando All-Flash para tudo? A resposta está na arquitetura de dados inteligente, não na força bruta.
1. Tiering Rigoroso
Não mantenha o Data Lake inteiro no tier de performance.
Tier 0 (NVMe Local/Fabric): Apenas o dataset do epoch atual e checkpoints imediatos.
Tier 1 (Object Storage/HDD): O repositório completo.
Use ferramentas de orquestração para "hidratar" o Tier 0 antes do início do job. O tempo de cópia do HDD para o NVMe é negligenciável comparado ao tempo de treinamento com I/O lento.
2. GPUDirect Storage (GDS)
Sempre que possível, utilize tecnologias como NVIDIA GPUDirect Storage. Isso permite que o storage NVMe envie dados diretamente para a memória da GPU, ignorando a CPU e a memória do sistema (bounce buffers). Isso reduz a latência e libera a CPU para tarefas de pré-processamento.
3. Quando o HDD ainda faz sentido
Não descarte os discos rotacionais. Eles são inviáveis para alimentar diretamente uma H100 com imagens pequenas, mas são excelentes para:
Armazenar checkpoints de modelos (escrita sequencial).
Armazenar datasets brutos antes do pré-processamento.
Backup e compliance.
Veredito Técnico: Decidindo com Métricas, não com Hype
A escassez de IOPS mata o ROI das GPUs porque transforma um ativo de alta performance em um ativo de espera. Ao projetar sua infraestrutura de AI:
Meça a demanda de I/O do seu modelo (IOPS para visão, Throughput para LLMs).
Calcule o custo da ociosidade da GPU.
Projete o storage para saturar o barramento PCIe, não apenas para guardar bits.
O storage mais caro é aquele que faz sua GPU esperar.
Referências & Leitura Complementar
NVIDIA GPUDirect Storage Design Guide: Documentação técnica sobre o bypass de CPU para acesso direto ao storage.
SNIA (Storage Networking Industry Association): Especificações sobre métricas de performance de estado sólido (PTS - Solid State Storage Performance Test Specification).
FIO (Flexible I/O Tester): A ferramenta padrão-ouro para benchmarking de storage antes de colocar em produção. Verifique a documentação
man fiopara simular workloads de IA (ex: blocksize variável, random read vs sequential).NVMe Specification (NVM Express): Detalhes sobre filas de comando (Queues) e paralelismo em SSDs modernos.

Priya Patel
Data Center Operations Lead
Gerencia milhares de discos físicos. Sabe exatamente qual modelo de HDD vibra mais e qual SSD morre primeiro.