Storage como Estado Global: Por que o Modelo de Blocos Falha em Escala

Abandone a ilusão do disco local. Entenda por que arquiteturas modernas tratam storage como API de estado global, os riscos do POSIX distribuído e como projetar para consistência eventual.
Quando projetamos arquiteturas de armazenamento em escala enterprise, frequentemente caímos na armadilha de tratar o storage distribuído como se fosse apenas um disco rígido muito grande e muito rápido. Essa é a zona de conforto do SysAdmin clássico: montar um volume, formatar com XFS ou EXT4 e esperar que o POSIX garanta a integridade dos dados.
No entanto, à medida que escalamos horizontalmente — saindo de um único rack para múltiplos datacenters ou zonas de disponibilidade na nuvem — a física começa a cobrar seu preço. O modelo de blocos, que depende de uma visão consistente e imediata do estado do disco, colapsa sob a latência da rede.
Para construir sistemas resilientes em escala, precisamos parar de pensar em armazenamento como um "local" onde guardamos bytes e começar a tratá-lo como um Estado Global Distribuído.
O que é Storage como Estado Global?
Storage como Estado Global é a transição arquitetural onde o armazenamento deixa de ser tratado como um dispositivo de bloco endereçável por hardware (setor/cilindro) para se tornar um sistema distribuído acessado via API (Identidade/Objeto). Neste modelo, a consistência imediata é frequentemente sacrificada em favor da disponibilidade e tolerância a falhas (Teorema CAP), utilizando imutabilidade e versionamento em vez de bloqueios de arquivo (locks) para gerenciar concorrência.
A Ilusão da Localidade e o Limite do /dev/sda
O maior truque que o kernel do Linux prega em você é a existência do /dev/sda. Quando você roda um lsblk, o sistema operacional apresenta uma abstração reconfortante: "Aqui está um dispositivo de bloco, ele é seu, e você tem acesso exclusivo a ele".
Em um ambiente local, isso é verdade. O barramento PCIe/NVMe é rápido o suficiente para que a CPU trate a gravação como síncrona. Mas em uma SAN (Storage Area Network) ou em um volume EBS na nuvem, essa "localidade" é uma mentira. O /dev/sda é, na verdade, um protocolo de rede complexo (iSCSI, NVMe-oF) disfarçado de dispositivo local.
O problema surge quando tentamos esticar essa ilusão. Protocolos de bloco são "conversadores" (chatty). Eles exigem confirmações constantes de baixo nível. Quando você tenta escalar um sistema de arquivos tradicional (como um Cluster File System) através de uma WAN, a latência da luz na fibra óptica destrói a performance. O SO espera uma resposta em microssegundos, mas a rede entrega em milissegundos. O resultado é um I/O Wait que trava toda a aplicação.
O Colapso do POSIX em Sistemas Distribuídos e a Mutabilidade
O padrão POSIX foi desenhado nos anos 80, assumindo que operações de arquivo (open, read, write, close) são atômicas e sequenciais. Para garantir isso em um sistema distribuído, você precisa de Locks (bloqueios).
Se dois servidores tentam escrever no mesmo bloco de um volume compartilhado ao mesmo tempo, um mecanismo de Distributed Lock Manager (DLM) precisa arbitrar. "Servidor A, espere. Servidor B está escrevendo".
O custo desse arbitramento cresce exponencialmente com a distância e o número de nós. Em escala, os locks tornam-se o gargalo, não a velocidade do disco. Você não está limitado pelos IOPS do SSD, mas pela velocidade com que os nós conseguem concordar sobre quem tem a permissão de escrever.
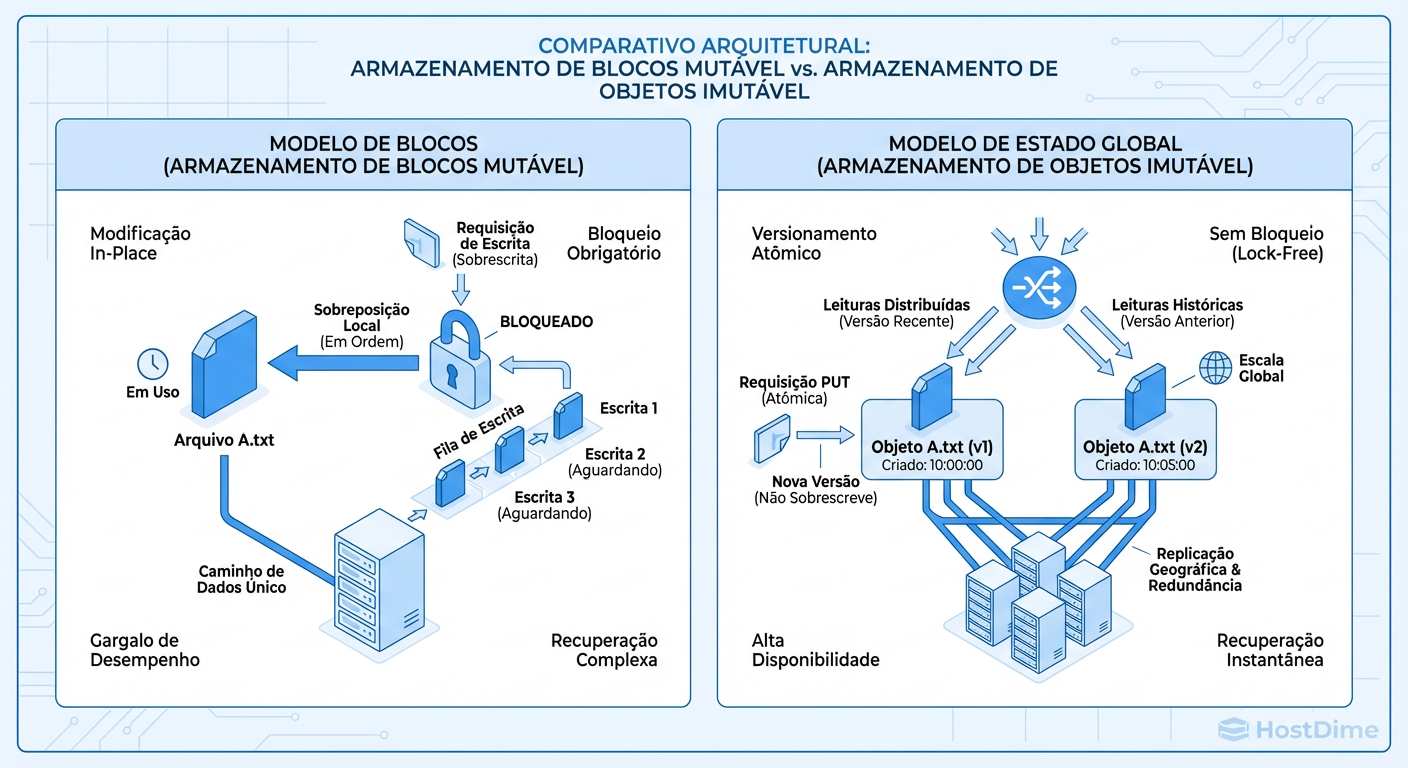 Figura: Mutabilidade vs. Imutabilidade: Por que locks matam a performance em escala distribuída.
Figura: Mutabilidade vs. Imutabilidade: Por que locks matam a performance em escala distribuída.
A imagem acima ilustra exatamente este ponto: tentar manter a mutabilidade (alterar um arquivo existente) exige coordenação pesada. É por isso que bancos de dados relacionais (que dependem de consistência forte e mutabilidade) são notoriamente difíceis de escalar em multi-master geográfico.
De Blocos para Objetos: Mudando de Lugar para Identidade
Para resolver o problema de escala, a indústria moveu-se do modelo de Lugar (Bloco) para o modelo de Identidade (Objeto).
Bloco (SAN/Local): "Grave estes bytes no setor 4096 do disco 1." Se você mudar o disco, o endereço quebra.
Objeto (S3/Swift): "Armazene este conteúdo e me dê um ID único (Key)." Você não sabe em qual disco, rack ou cidade o dado está. Você apenas pede pelo ID via API HTTP.
Essa mudança desacopla a aplicação da infraestrutura física. O protocolo deixa de ser SCSI (focado em hardware) e passa a ser REST (focado em recursos). Isso remove a necessidade do SO manter um mapa de blocos em tempo real, transferindo a responsabilidade da localização dos dados para o software de storage (o Gateway de Objetos).
Tabela Comparativa: Bloco vs. Arquivo vs. Objeto
| Característica | Block Storage (SAN/EBS) | File Storage (NAS/NFS) | Object Storage (S3/Blob) |
|---|---|---|---|
| Unidade Base | Bloco de Bytes (4KB) | Arquivo & Pasta | Objeto (Dados + Metadados) |
| Interface | Protocolo de Disco (iSCSI, NVMe) | Protocolo de Rede (NFS, SMB) | API REST (HTTP GET/PUT) |
| Latência | Baixíssima (<1ms) | Baixa a Média | Média a Alta (TTFB*) |
| Consistência | Forte (Imediata) | Forte (Geralmente) | Eventual (Geralmente) |
| Escalabilidade | Limitada (Petabytes são difíceis) | Média | Infinita (Exabytes) |
| Custo TCO | Alto | Médio | Baixo |
| Uso Ideal | Boot, DBs (MySQL, PostgreSQL) | Home Dirs, Code Repos | Mídia, Backups, Data Lakes |
*TTFB: Time To First Byte
Consistência Forte vs. Eventual: O Trade-off da Latência
Aqui entra a decisão arquitetural mais dolorosa. Se você quer escala global, você precisa aceitar a Consistência Eventual.
No modelo de Consistência Forte, quando você grava um dado, o sistema só retorna "OK" (ACK) quando todas as réplicas confirmam a gravação. Isso garante que ninguém lerá um dado velho. O preço? A latência de escrita é igual à latência do nó mais lento ou mais distante.
No modelo de Consistência Eventual, o sistema retorna "OK" assim que uma réplica grava (ou um quórum mínimo). A replicação para os outros nós acontece em background. A escrita é rápida, mas existe o risco de uma leitura subsequente retornar o dado antigo por alguns milissegundos.
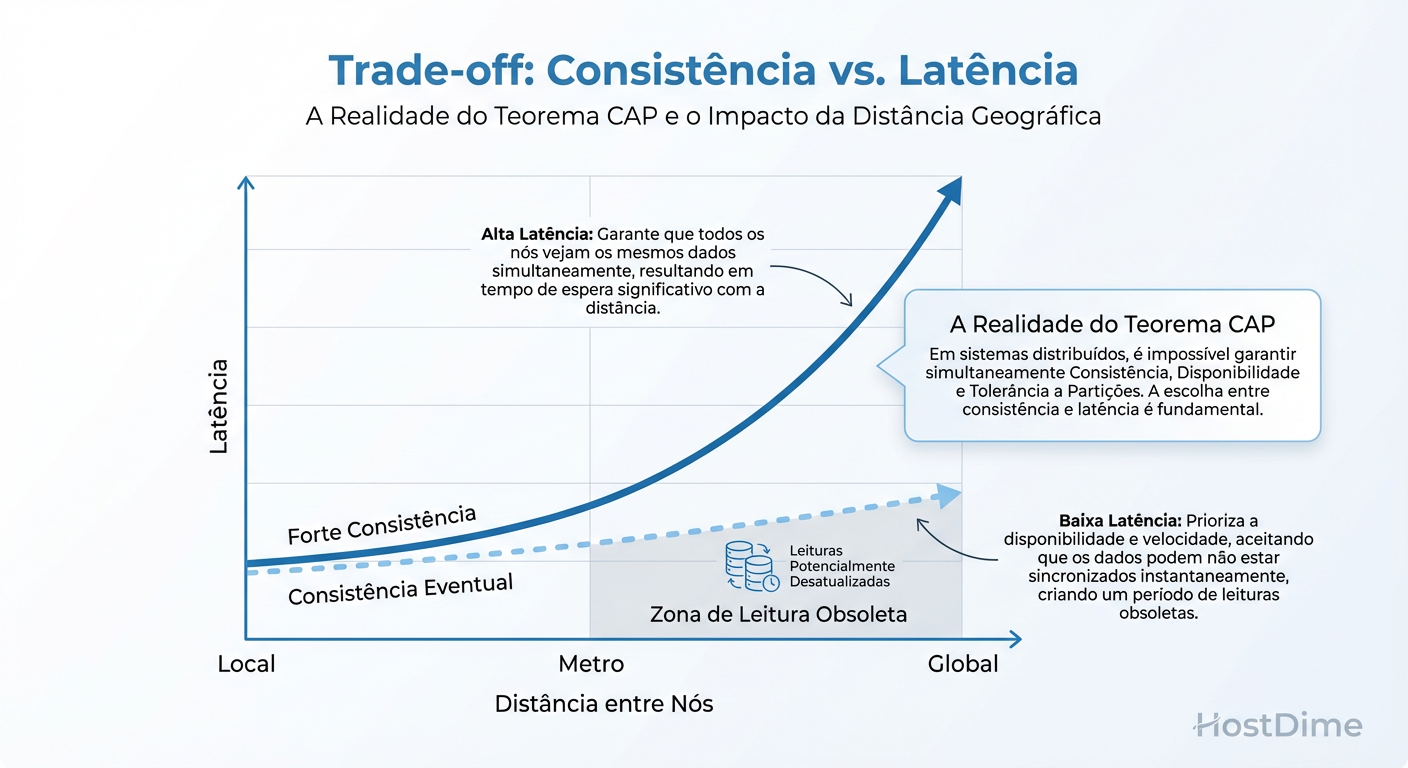 Figura: O Custo da Verdade: A relação inevitável entre consistência forte e latência de rede.
Figura: O Custo da Verdade: A relação inevitável entre consistência forte e latência de rede.
Como mostrado na imagem, a "verdade" tem um custo de tempo. Em sistemas distribuídos, não existe "agora". Existe "o que este nó sabe agora".
Storage como Log Imutável: Resolvendo Concorrência sem Locks
Como evitamos a corrupção de dados sem usar locks pesados? Adotando a Imutabilidade.
Em vez de modificar um arquivo (ex: abrir planilha.xlsx, mudar uma célula e salvar), o Object Storage trata cada gravação como um novo objeto ou uma nova versão.
Se você precisa atualizar um dado, você não sobrescreve os bits no disco. Você grava uma nova versão do objeto atomicamente. Isso elimina a necessidade de bloquear leitura enquanto se escreve. Leitores veem a versão V1 enquanto a V2 está sendo escrita. Assim que a V2 é finalizada, o ponteiro "Head" muda.
Isso transforma o storage em um Append-Only Log. É a mesma lógica que permite que bancos de dados modernos (LSM-Trees) e sistemas como Kafka tenham throughput massivo.
Métricas de Storage que Importam em Escala
Esqueça o "Average Latency". Em sistemas distribuídos, a média esconde os problemas. Se a média é 5ms, mas 1% das requisições leva 2 segundos, sua aplicação vai falhar para esses usuários e causar timeouts em cascata.
1. Tail Latency (Latência de Cauda - p99/p99.9)
Meça o percentil 99. Qual é a latência que os 1% dos usuários mais lentos experimentam? Em storage distribuído, o "Jitter" (variação) é o inimigo.
2. Time-to-Consistency
Em sistemas de consistência eventual, quanto tempo leva entre eu escrever um objeto no "Nó A" e ele estar disponível para leitura no "Nó B"?
Para testar isso, não use dd. Use ferramentas que entendam objetos e APIs. Um script simples para validar consistência pode ser mais valioso que um benchmark de throughput:
# Não use isso para benchmark de performance, apenas lógica.
write_timestamp=$(date +%s%N)
aws s3 cp test-file s3://bucket/test-file
read_timestamp=$(date +%s%N)
# Em outro terminal/nó imediatamente:
aws s3 ls s3://bucket/test-file
# Se falhar ou retornar 404, calcule o delta de tempo até aparecer.
Decisão Arquitetural: Quando manter o Bloco e quando abraçar o Estado Global
Não existe bala de prata, existe o trade-off correto para o seu requisito de negócio.
Mantenha Storage de Bloco (Estado Local/Forte) quando:
Você precisa de latência de sub-milissegundos (Bancos de dados transacionais OLTP).
A aplicação é legada e exige conformidade POSIX estrita (locks, appends parciais).
O escopo dos dados é confinado a uma única zona ou rack.
Abrace o Storage de Objeto (Estado Global/Eventual) quando:
A aplicação precisa ser stateless. O estado deve viver fora dos servidores de aplicação.
Você precisa servir conteúdo estático (imagens, vídeos, backups) para múltiplos locais geográficos.
A escalabilidade de capacidade (Petabytes) é mais crítica que a latência de operação individual.
Você está desenhando arquiteturas modernas (Cloud-Native) que suportam retentativas e consistência eventual.
A falha do modelo de blocos em escala não é um defeito de design, é uma limitação física. Aceitar que o armazenamento em nuvem é um sistema distribuído de passagem de mensagens (API), e não um disco rígido mágico, é o primeiro passo para construir arquiteturas que não acordam você às 3 da manhã.
Referências & Leitura Complementar
Brewer, E. A. (2000). Towards robust distributed systems (CAP Theorem). PODC. Define os limites teóricos entre Consistência, Disponibilidade e Partição.
Amazon Web Services. Amazon S3 Strong Consistency. Whitepaper técnico detalhando como o S3 alcançou consistência forte mantendo alta disponibilidade (uma exceção notável à regra geral).
RFC 3720. Internet Small Computer Systems Interface (iSCSI). Para entender a complexidade de encapsular comandos SCSI em TCP/IP.
Ceph Documentation. CRUSH Map algorithms. Entendimento de como dados são distribuídos deterministicamente sem uma tabela de alocação central.

Thiago Moreira
High-Performance Computing Researcher
Trabalha com supercomputadores. Para ele, velocidade é tudo, e redundância é problema do software.