Storage Compartilhado no Proxmox: Ceph, NFS ou ZFS over iSCSI? Arquitetura para HA Real
Não escolha seu storage no cara ou coroa. Compare arquitetura, latência e complexidade entre Ceph, ZFS over iSCSI e NFS para clusters Proxmox HA de alta performance.
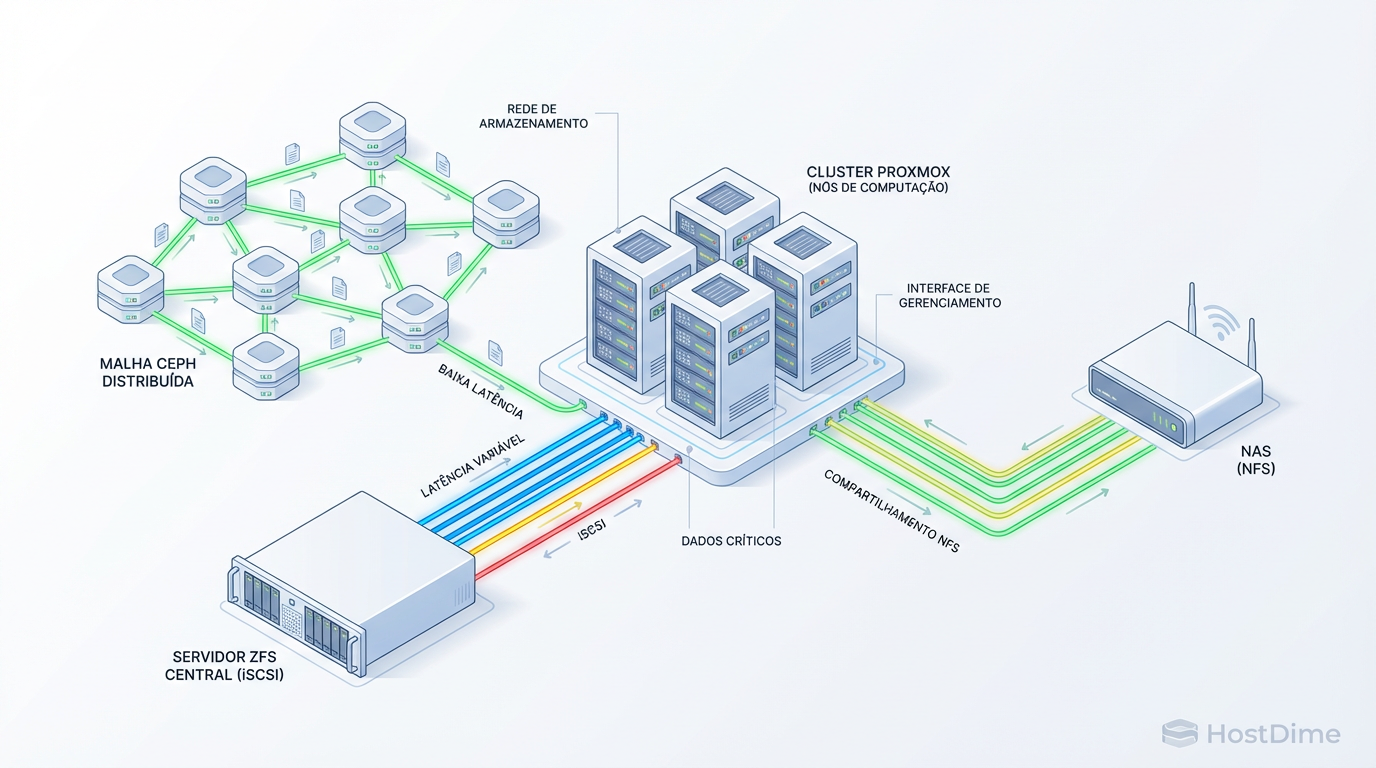
Se você está desenhando um cluster Proxmox VE com Alta Disponibilidade (HA), você já descobriu a verdade inconveniente: o "HA" é fácil de clicar na interface, mas difícil de arquitetar no backend. O coração do problema não é a CPU ou a RAM; é a gravidade dos dados. Mover uma VM de um nó para outro é trivial se ambos enxergam o mesmo disco. Se não enxergam, você não tem HA, tem apenas migração fria e lenta.
A escolha do storage compartilhado define o TCO (Custo Total de Propriedade), a latência que seus bancos de dados sofrerão e, crucialmente, se você dormirá tranquilo ou será acordado por um split-brain na madrugada. Não existe "o melhor storage". Existe aquele que mitiga os riscos que o seu negócio pode tolerar.
O que é Storage Compartilhado para HA? Storage compartilhado é uma arquitetura onde múltiplos nós de computação (hypervisors) acessam simultaneamente o mesmo repositório de dados (seja via bloco, arquivo ou objeto). No contexto do Proxmox, é o requisito obrigatório para live migration e failover automático: se um nó físico falha, as VMs reiniciam em outro nó instantaneamente porque seus discos virtuais permanecem acessíveis no storage central ou distribuído.
O Teorema da Escolha: Latência, Complexidade e Custo em Clusters HA
Em arquitetura de sistemas, operamos sob restrições físicas. O dado precisa viajar pela rede, ser processado pelo controlador de storage, gravado na mídia física e confirmado (ACK) de volta ao sistema operacional da VM. Cada etapa adiciona latência.
Quando escolhemos entre NFS, iSCSI ou Ceph, estamos essencialmente escolhendo onde queremos pagar a "taxa" da complexidade.
NFS: Paga na latência de rede e overhead de protocolo de arquivo.
iSCSI: Paga na complexidade de configuração de rede (MTU, Multipath).
Ceph: Paga em recursos de hardware (CPU/RAM) e complexidade operacional.
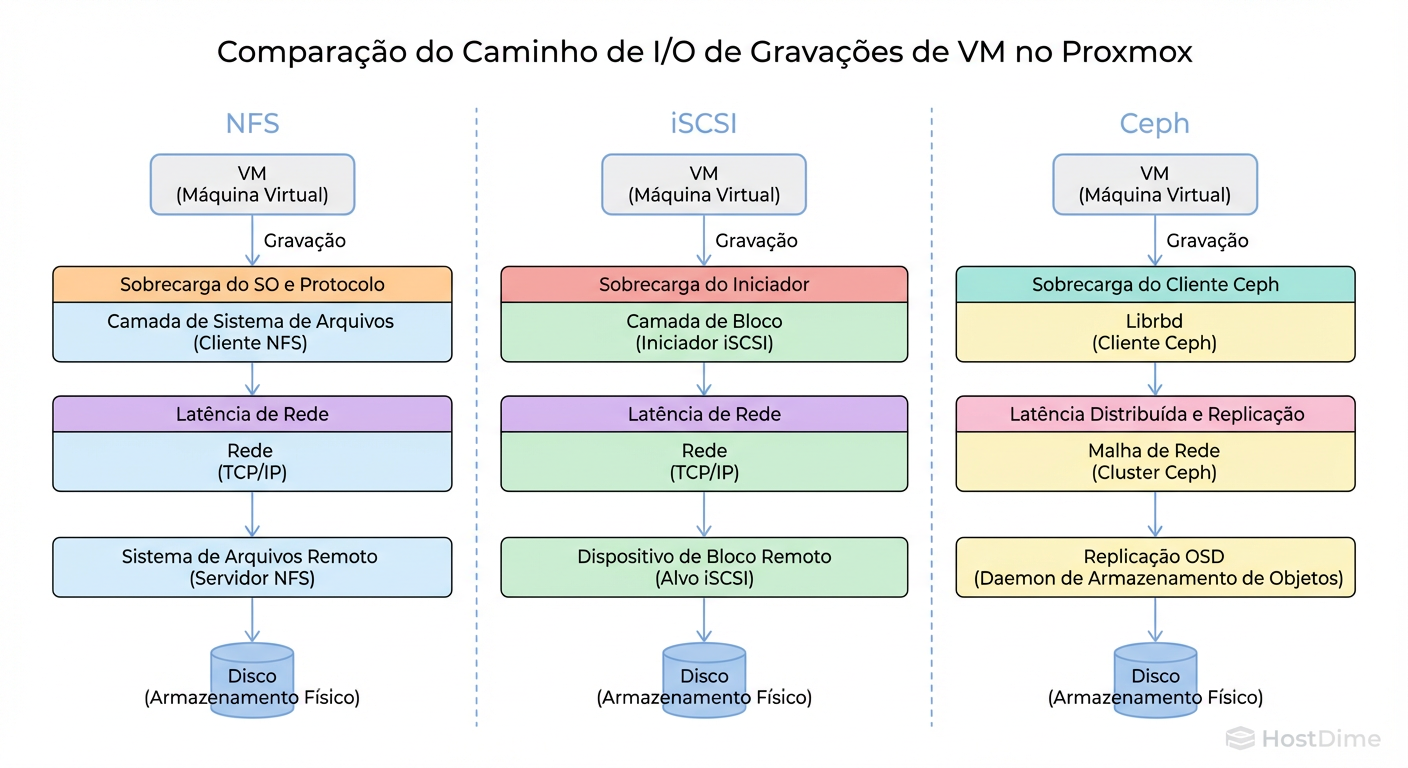 Figura: O Caminho do I/O: Compare as camadas de sobrecarga (overhead) entre Arquivo (NFS), Bloco (iSCSI) e Objeto Distribuído (Ceph).
Figura: O Caminho do I/O: Compare as camadas de sobrecarga (overhead) entre Arquivo (NFS), Bloco (iSCSI) e Objeto Distribuído (Ceph).
Visualizar o caminho do I/O é vital. Enquanto o iSCSI fala quase diretamente com os blocos do disco, o NFS precisa atravessar a stack de sistema de arquivos do servidor remoto. O Ceph, por sua vez, introduz algoritmos de consenso distribuído (Paxos/CRUSH) antes de confirmar uma gravação.
Desempenho do NFS no Proxmox e o Perigo do "Sync Write"
O NFS (Network File System) é o caminho de menor resistência. Qualquer administrador Linux sobe um export NFS em 5 minutos. Ele é flexível, permite armazenar ISOs, backups (VZDump) e imagens de disco (qcow2) no mesmo lugar.
No entanto, o NFS esconde uma armadilha mortal para performance de virtualização: a gravação síncrona (sync write).
Quando uma VM executa um banco de dados (PostgreSQL, MySQL), ela exige que o dado seja garantidamente gravado no disco antes de prosseguir. O Proxmox respeita isso. O fluxo é:
VM envia escrita.
Proxmox repassa ao cliente NFS.
Cliente NFS envia pela rede.
Servidor NFS recebe, grava no disco, espera o disco confirmar (fsync).
Servidor NFS devolve o ACK.
Se sua rede tem latência ou se o storage backend não tem um cache de escrita rápido (como um SSD NVMe para SLOG/ZIL ou uma controladora RAID com bateria), seu banco de dados vai rastejar.
O Veredito do Arquiteto: Use NFS para ISOs, Backups e cargas de trabalho que leem muito e escrevem pouco (Web Servers estáticos). Para bancos de dados transacionais, o overhead do protocolo de arquivo geralmente não compensa a facilidade de uso, a menos que você tenha um storage Enterprise (NetApp, TrueNAS com SLOG dedicado).
ZFS over iSCSI: Performance de Bloco sem Hiperconvergência
O iSCSI é o padrão ouro para storage compartilhado tradicional (SAN). Ele entrega blocos brutos (/dev/sdX) pela rede. O protocolo é "magro", com menos overhead que o NFS.
O Proxmox possui uma integração brilhante chamada ZFS over iSCSI. Diferente do iSCSI comum (onde o Proxmox vê um LUN gigante e cria um sistema de arquivos LVM em cima), o ZFS over iSCSI conversa diretamente com a API do storage (geralmente um Linux com target LIO ou um TrueNAS/FreeNAS).
Como funciona a mágica: Quando você cria um disco de VM no Proxmox:
O Proxmox conecta via SSH no storage.
Executa
zfs createpara criar um ZVol (volume de bloco).Exporta esse ZVol via iSCSI Target apenas para o nó necessário.
A vantagem tática: Você ganha a velocidade de bloco do iSCSI mais os recursos do ZFS (snapshots instantâneos, thin provisioning real).
O Risco: Geralmente, isso implica em um "Storage Central" (um servidor TrueNAS ou similar). Se esse servidor cair, todo o cluster para. Isso é um Ponto Único de Falha (SPOF), a menos que você tenha um storage com controladora dupla (Dual Controller), o que eleva drasticamente o custo.
Arquitetura Ceph no Proxmox: Quando o Software vira Hardware
O Ceph é a antítese do Storage Central. É uma solução Hiperconvergente (HCI). Aqui, não existe "o servidor de storage". Cada nó do Proxmox contribui com seus discos locais (OSD) para formar um pool de armazenamento distribuído e resiliente.
Se um nó morre, o Ceph percebe, recalcula o mapa de dados e começa a replicar os dados faltantes para os nós sobreviventes. É a definição de "Self-Healing".
Mas o Ceph não é mágica, é matemática pesada.
O Preço da Hiperconvergência
Para rodar Ceph bem, você precisa seguir regras rígidas. O Ceph é faminto.
Rede: Esqueça 1GbE. O Ceph precisa de uma rede dedicada para replicação (Cluster Network) de no mínimo 10GbE. A latência de rede mata o Ceph mais rápido que discos lentos.
CPU e RAM: O Ceph consome cerca de 1GB de RAM por TiB de dados brutos (regra prática, varia com a configuração) e ciclos de CPU para calcular o algoritmo CRUSH a cada leitura/escrita.
Quantidade de Nós: Um cluster de 2 nós com Ceph é perigoso (problemas de quórum). O ideal começa em 3 nós, e a performance escala horizontalmente: quanto mais nós, mais rápido fica.
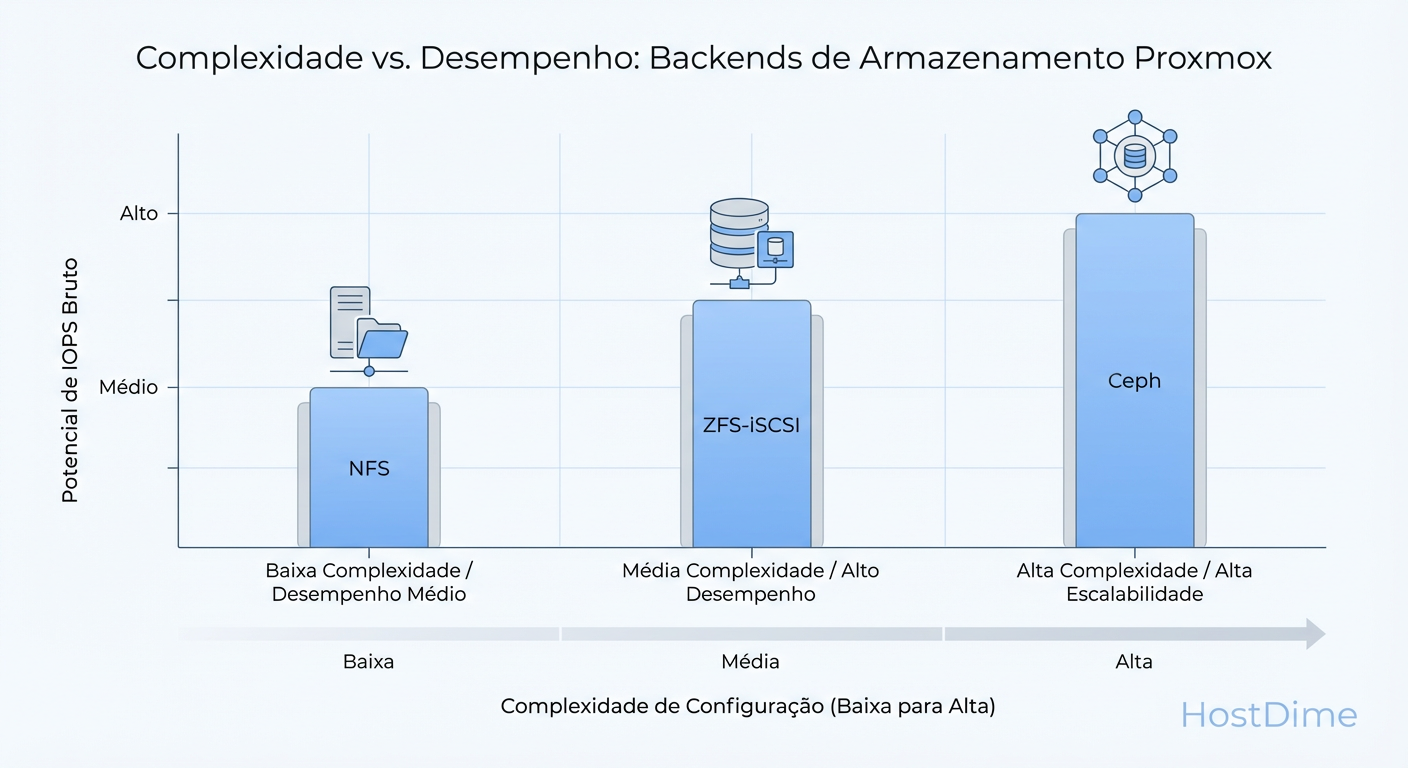 Figura: Trade-offs Reais: Onde sua equipe deve investir tempo de engenharia versus o retorno em performance.
Figura: Trade-offs Reais: Onde sua equipe deve investir tempo de engenharia versus o retorno em performance.
Trade-off Real: O Ceph elimina o SPOF do storage central, mas transfere a complexidade para a camada de software e rede. Sua equipe precisa saber operar Ceph. Debugar um Placement Group (PG) inconsistente é mais difícil do que trocar um disco em um RAID.
Matriz de Decisão: Escolhendo o Protocolo por Workload
Não tome decisões baseadas em "o que é mais moderno". Use a matriz abaixo para alinhar a tecnologia ao requisito de negócio.
| Característica | NFS (Geral) | ZFS over iSCSI | Ceph (RBD) |
|---|---|---|---|
| Tipo de Acesso | Arquivo (File) | Bloco (Block) | Objeto/Bloco Distribuído |
| Latência Típica | Média/Alta (Overhead) | Baixa (Direto ao bloco) | Variável (Depende da Rede) |
| Complexidade Setup | Baixa | Média | Alta |
| Resiliência (HA) | Depende do Servidor NFS | Depende do Servidor iSCSI | Nativa (Distribuída) |
| Requisito de Rede | 1GbE aceitável | 1GbE (com MPIO) ou 10GbE | 10GbE+ Obrigatório |
| Uso de CPU (Host) | Baixo | Baixo | Alto (Cálculo CRUSH) |
| Snapshots | Lento (qcow2) | Instantâneo (ZFS) | Instantâneo (RBD) |
| Melhor Uso | Backups, ISOs, Web Servers | DBs, ERPs (com SAN dedicada) | Cloud Privada, Escala |
Validando Storage com Fio: Medindo IOPS e Latência
Antes de migrar a produção, você deve validar se o storage aguenta o tranco. Não confie em benchmarks de cópia de arquivo (dd), pois eles são sequenciais e não representam o caos de uma VM real.
Use o fio (Flexible I/O Tester). O comando abaixo simula uma carga de trabalho mista (padrão de banco de dados ou SO virtualizado): leitura/escrita aleatória, blocos de 4k, forçando sincronização.
Atenção: Execute isso em um disco de teste, nunca em produção ativa.
apt install fio
# Teste de Random Read/Write 4k (Simulação de VM/DB)
# --fsync=1 obriga o disco a confirmar cada gravação (o teste mais cruel)
fio --randrepeat=1 \
--ioengine=libaio \
--direct=1 \
--gtod_reduce=1 \
--name=test \
--filename=teste_fio_temp \
--bs=4k \
--iodepth=64 \
--size=4G \
--readwrite=randrw \
--rwmixread=75 \
--fsync=1
O que analisar na saída:
iops: Se der menos de 500 em random write 4k com fsync, seus bancos de dados vão sofrer.
lat (ms): Latência de gravação acima de 10-20ms constante indica gargalo (rede ou disco lento).
clat (completion latency): O tempo real desde a submissão até o retorno.
Se o seu NFS der 100 IOPS e o Ceph der 2000 IOPS nesse teste, você tem dados empíricos para justificar o investimento em hardware para o Ceph.
Veredito Técnico Arquitetural
Não existe almoço grátis em storage distribuído.
Escolha NFS se a simplicidade operacional for mais importante que a performance bruta de IOPS.
Escolha ZFS over iSCSI se você tem um orçamento para um storage central robusto e precisa de performance máxima de bloco com recursos de snapshot.
Escolha Ceph se você precisa de escalabilidade infinita e resiliência total contra falha de hardware, e está disposto a pagar o preço em hardware de rede e curva de aprendizado.
O melhor storage é aquele que você sabe consertar quando quebra. Comece simples, meça com evidência, e escale conforme a dor aparecer.
Referências & Leitura Complementar
RFC 3720: Internet Small Computer Systems Interface (iSCSI) - A base do protocolo de bloco sobre IP.
Proxmox VE Storage Docs: Documentação oficial sobre os tipos de storage suportados e suas limitações (qcow2 vs raw).
Ceph: The CRUSH Algorithm: Whitepaper original sobre como o Ceph distribui dados sem uma tabela central de alocação.
ZFS On Linux (OpenZFS): Documentação sobre ZVols e propriedades como
sync=standardvssync=disabled.

Dr. Marcus 'Bitrot' Silva
Engenheiro Sênior de Armazenamento
20 anos recuperando RAIDs quebrados. Especialista em ZFS e sistemas de arquivos distribuídos. Já viu mais falhas de disco do que gostaria.