Storage Enterprise na Era AI: Estratégias de Mitigação para Escassez e Latência

Seus arrays estão cheios e a latência alta? Aprenda a mitigar a escassez de storage em ambientes de IA, otimizando tiering, formatos de dados e arquitetura sem compras de pânico.
O mercado de tecnologia vive um momento de histeria coletiva em torno das GPUs. No entanto, para o Arquiteto de Soluções que precisa desenhar a infraestrutura real por trás do hype, o gargalo raramente é o silício de processamento. O verdadeiro assassino de performance em projetos de Inteligência Artificial (IA) e Machine Learning (ML) é o subsistema de armazenamento.
Seus H100s de meio milhão de dólares não processam dados que não conseguem ler. Se o storage não entregar os batches de dados na velocidade que a VRAM da GPU esvazia, você criou o sistema de aquecimento mais caro do mundo, não um cluster de treinamento.
O desafio central do Storage para IA não é apenas capacidade (onde guardar), mas a velocidade de alimentação (throughput sustentado) e a latência da primeira leitura. Diferente de bancos de dados transacionais que exigem IOPS aleatórios minúsculos, a IA exige uma mangueira de incêndio de dados sequenciais e, simultaneamente, acesso aleatório massivo para inferência. A solução envolve abandonar a deduplicação tradicional, adotar formatos de dados colunares e implementar um tiering de dados impiedoso entre NVMe e Object Storage.
O Paradoxo do Storage na Era AI: Volume vs. Throughput
No design de storage enterprise tradicional (virtualização, VDI, bancos de dados SQL), fomos treinados a otimizar para IOPS (Input/Output Operations Per Second) e latência de pequenos blocos (4k ou 8k). O "modelo mental" clássico é: "Se o IOPS é alto e a latência é baixa (<1ms), o storage é bom".
Em cargas de trabalho de IA, esse modelo quebra.
O treinamento de Modelos de Linguagem Grande (LLMs) ou Visão Computacional opera sob um paradigma diferente. O processo de leitura de dados (Data Loading) compete diretamente com o tempo de computação. Se o seu storage entrega 1 milhão de IOPS, mas o throughput (largura de banda total) é limitado a 2GB/s, suas GPUs vão passar fome.
Aqui reside o paradoxo: Você precisa de um sistema de arquivos que se comporte como um HPC (High Performance Computing) para o treinamento, mas que tenha a durabilidade e a facilidade de gestão de um NAS Enterprise.
Para mitigar a escassez de hardware e o custo proibitivo de arrays All-Flash Puros (AFA) para petabytes de dados, a primeira decisão arquitetural é entender o fluxo de I/O:
Ingestão/ETL: Escrita sequencial pesada.
Treinamento: Leitura aleatória massiva (se houver shuffling de dados) ou leitura sequencial (streaming).
Checkpointing: Escrita explosiva e periódica (o estado da memória da GPU é despejado no disco).
Se você otimizar apenas para leitura, o checkpointing vai travar seu treinamento por minutos a cada hora. Se otimizar apenas para escrita, o data loader será o gargalo.
Por que a Deduplicação e Compressão Tradicionais Falham em Workloads de IA
Vendedores de storage adoram vender "capacidade efetiva". Eles prometem que 100TB de flash físico viram 500TB efetivos graças a taxas de redução de dados de 5:1. Em ambientes de VDI ou backups, isso é verdade. Em IA, isso é uma armadilha orçamentária.
Dados de treinamento de IA — imagens, áudio, vídeo e, crucialmente, embeddings vetoriais — possuem altíssima entropia.
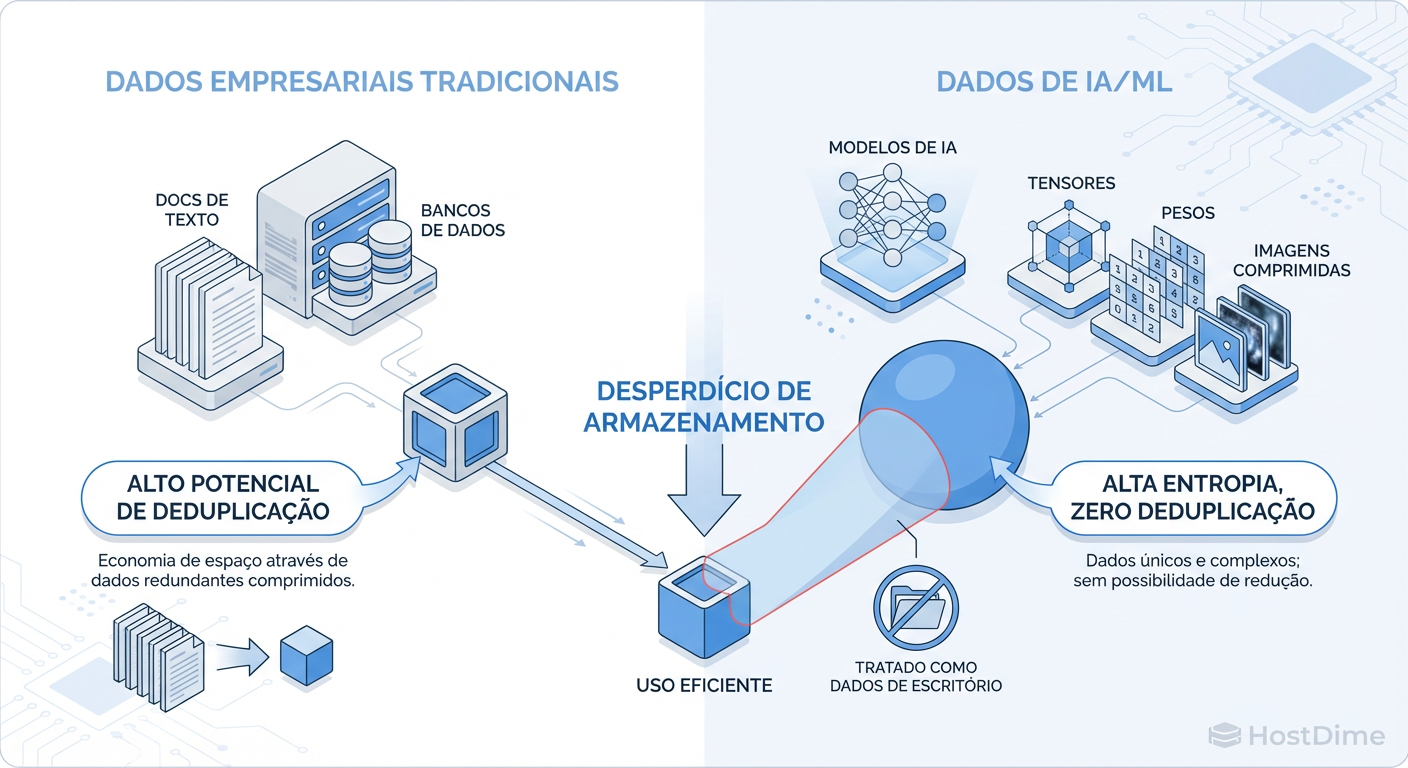 Figura: Comparativo de Entropia: Por que algoritmos de redução de dados falham em workloads de IA
Figura: Comparativo de Entropia: Por que algoritmos de redução de dados falham em workloads de IA
Como ilustrado acima, algoritmos de compressão (como LZ4 ou Zstd) e deduplicação buscam padrões repetitivos. Um dataset de imagens JPEG ou PNG já é comprimido. Um arquivo de áudio MP3 já removeu redundâncias. E vetores (arrays de números de ponto flutuante) são, para o controlador de storage, indistinguíveis de ruído aleatório.
O Impacto no TCO e Performance:
Overhead de CPU: O controlador do storage gasta ciclos preciosos de CPU tentando (e falhando) deduplicar dados únicos. Isso aumenta a latência de gravação.
Custo Real: Se você dimensionou seu array contando com uma redução de 4:1 e obteve 1.1:1, seu custo por TB útil acabou de quadruplicar.
Ação Prática: Ao provisionar volumes para datasets de IA (especialmente imagens e vídeos comprimidos), desative a deduplicação e a compressão no nível do array. Você ganhará performance de latência e terá uma visão honesta da capacidade consumida.
Auditoria de Calor: Identificando Dados 'Frios' em Arrays NVMe Caros
O erro mais comum em arquiteturas de IA "on-prem" é tratar todos os dados como cidadãos de primeira classe. Manter o dataset bruto (Raw Data), os dados processados, os checkpoints de modelos antigos e os logs de experimentos em um tier NVMe de alto desempenho é financeiramente insustentável.
Você precisa de uma estratégia de Auditoria de Calor.
O ciclo de vida do dado em IA é agressivamente efêmero em termos de "temperatura":
Hot (Quente): O dataset da epoch atual e o último checkpoint. Exige NVMe.
Warm (Morno): Datasets processados que serão usados na próxima semana. Podem viver em SSDs SAS/SATA (QLC).
Cold (Frio): Dados brutos originais e modelos de meses atrás. Devem estar em Object Storage (S3 on-prem) ou HDD denso.
Tabela Comparativa de Tiers de Storage para IA
| Atributo | Tier 0: NVMe (Local/Fabric) | Tier 1: All-Flash NAS | Tier 2: Object Storage (S3) |
|---|---|---|---|
| Custo ($/TB) | $$$$ (Muito Alto) | $$$ (Alto) | $ (Baixo) |
| Throughput | > 100 GB/s | 10 - 40 GB/s | Variável (Network Bound) |
| Latência | Microsegundos (<100µs) | Milisegundos (<1ms) | Milisegundos a Segundos |
| Caso de Uso | Cache local, Scratch space | Datasets ativos, Home dirs | Lakehouse, Arquivo Morto |
| Risco | Volatilidade (se local) | Gargalo de Rede | Latência de "First Byte" |
Estratégias de Tiering Agressivo e Arquitetura de Fluxo
A solução para o custo não é comprar menos storage, é mover os dados com inteligência. O conceito aqui não é o tiering automático "preguiçoso" de storage arrays tradicionais (que movem blocos frios à noite), mas sim um orquestrador de dados consciente da aplicação.
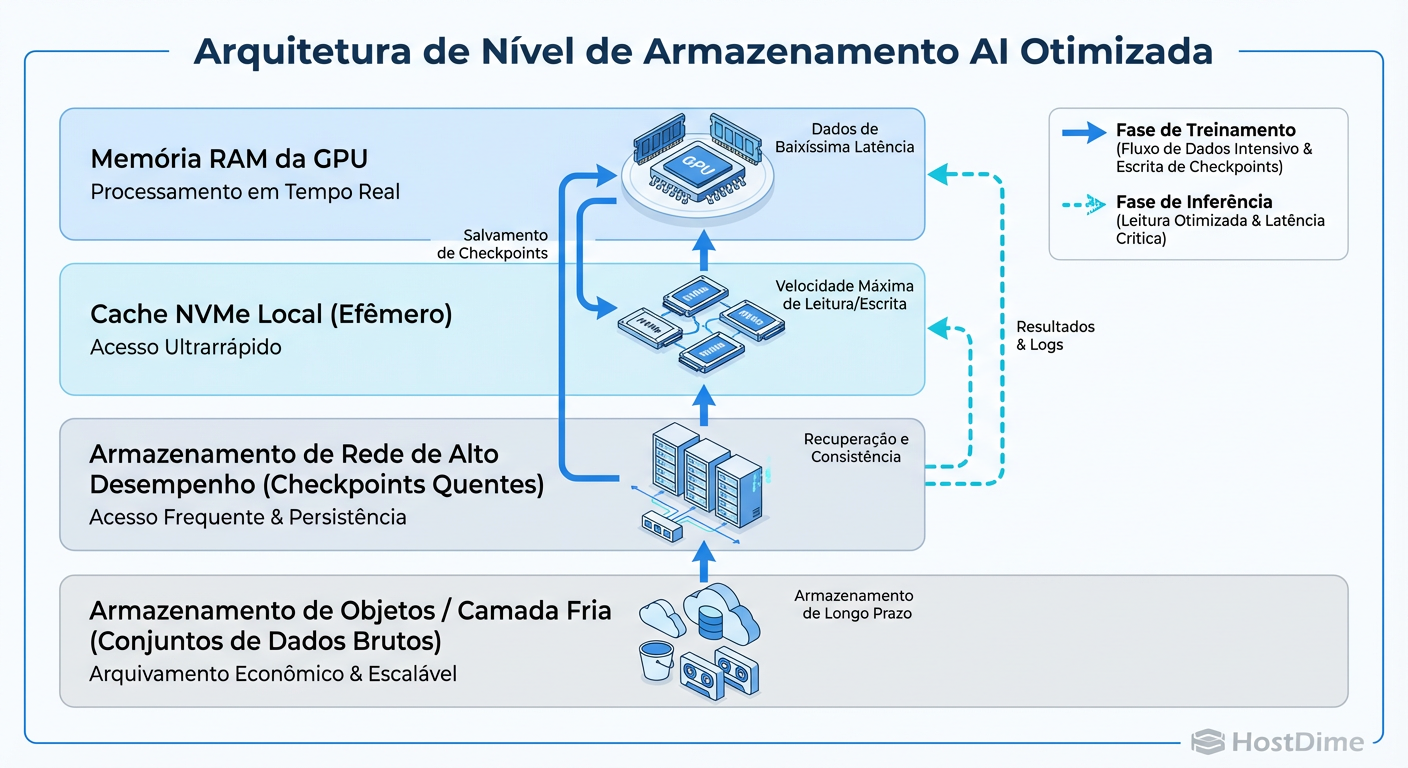 Figura: Arquitetura de Tiering para IA: O fluxo ideal de dados do Object Storage até a VRAM
Figura: Arquitetura de Tiering para IA: O fluxo ideal de dados do Object Storage até a VRAM
A arquitetura ideal, conforme o diagrama, utiliza o Object Storage como a "Fonte da Verdade". O tier de alta performance (NVMe) atua apenas como um burst buffer ou cache gigante.
Como implementar isso sem matar a performance:
Prefetching Inteligente: Ferramentas de MLOps devem pré-carregar os dados do Object Storage para o NVMe antes do início do job de treinamento. Não espere a GPU pedir o dado.
Checkpoint Assíncrono: Configure sua biblioteca de treinamento (PyTorch/TensorFlow) para salvar checkpoints localmente no NVMe e, em uma thread separada, mover esse arquivo para o Object Storage. Isso libera a aplicação para continuar treinando imediatamente.
Otimização no Nível da Aplicação: Formatos de Arquivo (Parquet vs. Filesystem)
Muitas vezes, culpamos o storage ("O NAS está lento!") quando o problema é o formato do dado.
Se o seu time de Data Science está treinando modelos lendo milhões de pequenos arquivos .json, .xml ou imagens soltas (.jpg) diretamente do filesystem, nenhum array do mundo vai salvar sua performance. Isso gera o "Small File Problem". O overhead de metadados (abrir, ler, fechar arquivo, atualizar atime) satura o servidor de metadados do storage muito antes de saturar a banda.
A Solução Colunar
A mitigação aqui é converter dados soltos em formatos de arquivamento otimizados para leitura, como Apache Parquet, Arrow ou TFRecord.
Por que funciona: Esses formatos agrupam milhares de pequenos registros em blocos maiores e contíguos. O storage realiza uma leitura sequencial grande (onde ele é eficiente) em vez de milhares de leituras aleatórias pequenas.
Memory Mapping: Formatos modernos permitem mapear o arquivo diretamente na memória (mmap), reduzindo cópias de buffer e uso de CPU.
A Ilusão do Cache Local: Quando usar Ephemeral Storage
Existe uma tendência de equipar nós de computação (como servidores DGX ou instâncias p4d na AWS) com terabytes de NVMe local. A ideia é: "Copio o dataset para o disco local e elimino a latência da rede".
Isso funciona, mas tem um custo oculto de Tempo de Inicialização (Cold Start).
Se o seu dataset tem 10TB e sua rede é de 100Gbps (teóricos, digamos 8GB/s reais), você levará mais de 20 minutos apenas copiando dados antes de a primeira época começar. Se o treinamento dura 1 hora, você desperdiçou 25% do tempo de GPU (e do custo da instância) movendo arquivos.
Quando usar Cache Local (Ephemeral):
O dataset cabe inteiro no disco local.
O tempo de treinamento é longo (dias ou semanas), diluindo o tempo de cópia inicial.
O algoritmo requer múltiplas passadas (epochs) sobre os mesmos dados (o cache paga o investimento na 2ª passada).
Quando usar Storage em Rede Direto:
O dataset é maior que o disco local.
Treinamentos curtos ou iterativos.
Inferência em tempo real.
Para testar se o seu disco local é realmente mais rápido que sua rede para o seu padrão de I/O, não confie no datasheet. Use o fio para simular a carga real:
# Exemplo de teste de Leitura Aleatória (Simulando Dataloader)
# Blocksize 128k é comum para imagens médias
fio --name=ai_test --ioengine=libaio --rw=randread --bs=128k \
--numjobs=16 --size=10G --iodepth=32 --runtime=60 \
--time_based --end_fsync=1 --group_reporting
Compare o resultado desse comando rodando no volume montado via rede (NFS/GPUDirect) versus o NVMe local. Se a diferença for menor que 20%, a complexidade de gerenciar cópias locais não vale a pena.
Métricas que Importam: Monitorando IOPS por Watt e Custo por Terabyte Útil
Para fechar a estratégia, precisamos medir o sucesso. Esqueça as métricas de vaidade.
GPU Wait Time (I/O Wait): A única métrica que realmente importa. Quanto tempo a GPU passa esperando dados? Se for > 5%, você tem um problema de storage ou de pipeline de dados.
IOPS por Watt: Em data centers com restrição de energia (o novo normal na era AI), storage ineficiente rouba energia que poderia alimentar GPUs. HDDs e SSDs antigos consomem muito para o pouco que entregam.
Custo por TB Útil para AI: Calcule o custo dividindo o preço total não pela capacidade bruta, mas pela capacidade após desligar a deduplicação (como discutido acima). Isso ajusta a expectativa da diretoria financeira.
Veredito Técnico
Arquitetar storage para IA é um exercício de equilíbrio entre a física dos discos e a voracidade dos processadores. Não existe "bala de prata". A mitigação da escassez e latência vem de um design híbrido: Object Storage barato para volume, NVMe sem deduplicação para velocidade, e formatos de arquivo inteligentes para conectar os dois mundos.
O "melhor" storage não é o mais rápido no papel, é aquele que mantém suas GPUs trabalhando 100% do tempo pelo menor custo possível.
Referências & Leitura Complementar
NVIDIA GPUDirect Storage: Documentação técnica sobre como bypassar a CPU para acesso direto do Storage à GPU.
Apache Arrow Project: Whitepapers sobre a eficiência de formatos colunares em memória e disco.
SNIA (Storage Networking Industry Association): "AI & Machine Learning Storage Performance Benchmarks".
RFC 3720 (iSCSI) & NVMe-oF Specs: Para entendimento profundo dos protocolos de transporte de bloco sobre Ethernet/Fabric.

Priya Patel
Data Center Operations Lead
Gerencia milhares de discos físicos. Sabe exatamente qual modelo de HDD vibra mais e qual SSD morre primeiro.