Storage para AI e RAG: A Verdade Sobre a Infraestrutura de GenAI em 2026
Seus GPUs estão ociosos esperando por dados? Analisamos o perfil de I/O de cargas de trabalho RAG, o fim do POSIX para AI e como arquitetar storage de alto desempenho para 2026.
Relatório de Investigação de Campo Status: Aberto Prioridade: Crítica (Gargalo de GPU)
Você comprou os clusters de H100s. Você tem a rede InfiniBand de 400Gbps. Você tem os engenheiros de ML mais caros do mercado. Mas seus dashboards de utilização da GPU mostram um padrão dente-de-serra horrível: picos de 100% seguidos por vales de 0% onde o processador gráfico — que custa mais que um carro popular — está apenas... esperando.
Como investigador forense de sistemas, eu vejo isso toda semana. O culpado raramente é o código Python do modelo. O culpado está escondido no porão da infraestrutura: o subsistema de armazenamento. Em 2026, tratar storage de AI como "apenas um lugar para guardar arquivos" é negligência técnica. O storage agora é parte da pipeline de computação.
Vamos dissecar a cena do crime, isolar as variáveis de I/O e entender por que arquiteturas legadas estão matando a performance da sua Inteligência Artificial Generativa.
O Paradoxo do Storage para AI A infraestrutura de armazenamento para GenAI exige a reconciliação de dois opostos físicos: Throughput Massivo (necessário para alimentar checkpoints e carregamento de datasets) e Latência Ultra-Baixa (necessária para inferência RAG e busca vetorial). Em 2026, a solução não é apenas "discos mais rápidos", mas a eliminação de intermediários na rota de dados (Bypass de Kernel/CPU) e a paralelização extrema de metadados via Object Storage de alta performance.
O Perfil de I/O do RAG: A mistura tóxica de latência e throughput
A maioria dos administradores de storage tenta otimizar para leitura sequencial (throughput) ou aleatória (IOPS). O problema do RAG (Retrieval-Augmented Generation) é que ele é um liquidificador que exige os dois simultaneamente.
Quando um usuário faz uma pergunta ao seu modelo, o sistema não vai apenas ler um arquivo grande. O fluxo forense é o seguinte:
Vector Search (Busca de Similaridade): O sistema consulta um Vector DB. Isso gera milhares de leituras aleatórias minúsculas (4KB ou menos) para encontrar os vetores mais próximos. Aqui, IOPS e Latência são reis. Se o storage engasgar aqui, o "Time to First Token" (TTFT) explode.
Chunk Retrieval (Recuperação de Contexto): Uma vez identificados os documentos relevantes, o sistema precisa puxar os chunks de texto (blobs de JSON, PDF, TXT). Isso é leitura sequencial de médio porte.
Ingestão Contínua: Enquanto isso acontece, novos dados estão sendo indexados e escritos no storage.
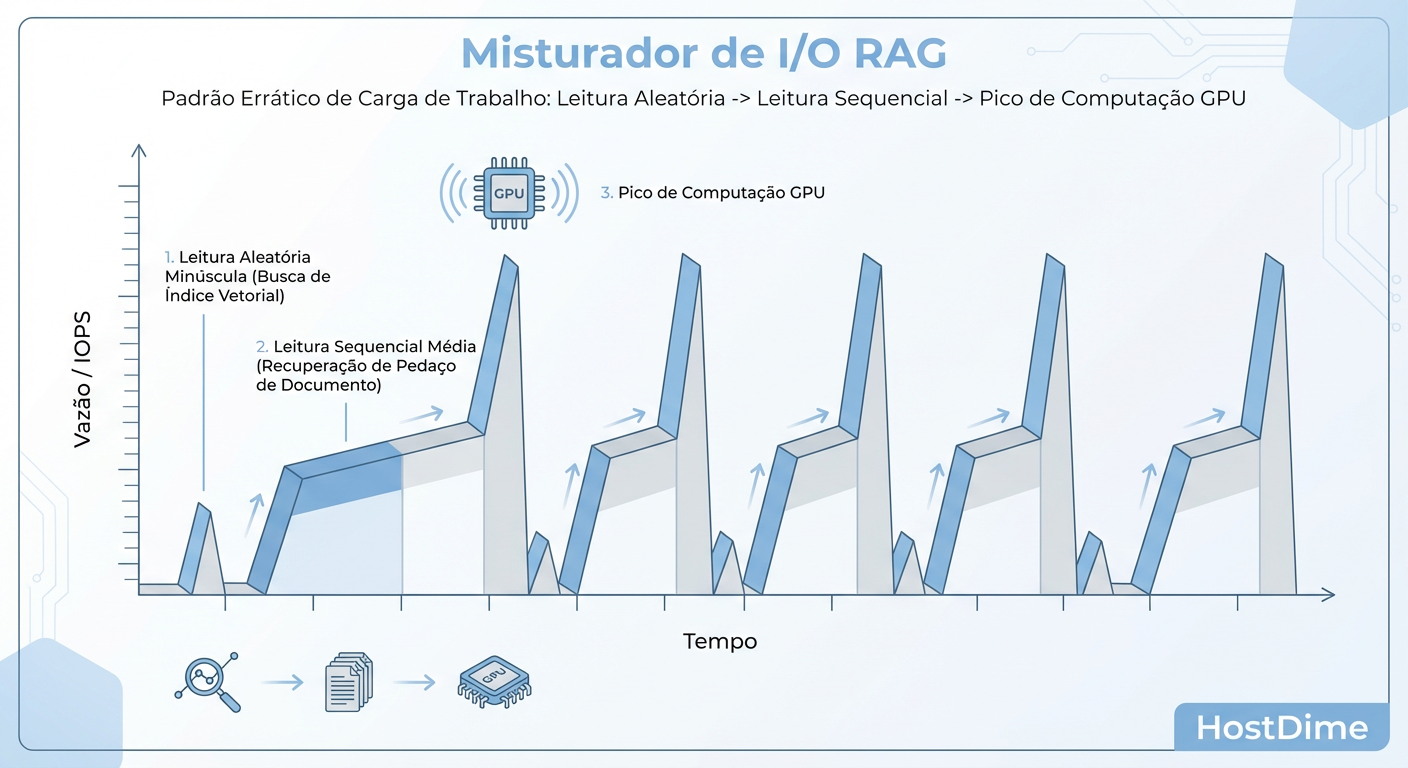 Figura: O padrão 'Blender' do RAG: A alternância brutal entre IOPS aleatórios e throughput sequencial exige storage versátil.
Figura: O padrão 'Blender' do RAG: A alternância brutal entre IOPS aleatórios e throughput sequencial exige storage versátil.
Essa alternância brutal cria o que chamamos de "I/O Blender". Discos rígidos (HDDs) são inúteis aqui — a latência mecânica destrói a experiência. Mas mesmo SSDs NVMe empresariais podem falhar se a controladora ou o sistema de arquivos não lidar bem com a profundidade de fila (Queue Depth) mista.
Se você está vendo alta latência no TTFT, pare de culpar o LLM. Verifique o iowait durante a fase de retrieval. É provável que seu storage esteja engasgado tentando servir IOPS aleatórios enquanto tenta manter um stream de throughput.
Por que o POSIX está morrendo no Datacenter de AI e a ascensão do Object Storage
Durante décadas, veneramos o POSIX. A ideia de que tudo é um arquivo, com permissões, access times e hierarquias de diretórios, funcionou bem para servidores web e bancos de dados relacionais. Para AI em escala, o POSIX é um fardo burocrático.
O problema é a tempestade de metadados. Datasets de treinamento modernos contêm bilhões de pequenos arquivos (imagens, clipes de áudio, tokens). Um sistema de arquivos tradicional (como NFS ou ext4 sobre montagens de rede) precisa fazer "lock" e atualizar metadados a cada acesso.
Em 2026, a indústria moveu-se agressivamente para o Object Storage de Alta Performance (Fast Object). Diferente do S3 antigo (pensado para arquivamento "frio"), o Fast Object roda sobre NVMe-oF (NVMe over Fabrics), eliminando a hierarquia de pastas. O acesso é via API (GET/PUT) direta pelo ID do objeto.
Comparativo: File System vs. Fast Object para AI
| Característica | POSIX (NFS/Parallel FS tradicional) | Fast Object Storage (S3 API sobre NVMe) | Veredito Forense |
|---|---|---|---|
| Gerenciamento de Metadados | Centralizado ou Distribuído (Gargalo em bilhões de arquivos) | Flat Namespace (Escala linearmente) | Object vence em escala massiva. |
| Overhead de Protocolo | Alto ("Chatty" - muitos round-trips) | Baixo (RESTful simplificado ou binário otimizado) | Object reduz latência de rede. |
| Semântica de Bloqueio | Complexa (Locks de arquivo matam performance paralela) | Consistência Eventual ou Forte sem Locks complexos | Object permite paralelismo massivo de GPU. |
| Custo por TB | Alto (Geralmente All-Flash Tier 1) | Médio/Baixo (Erasure Coding eficiente) | Object é mais econômico para Petabytes. |
O Sinal de Alerta: Se o seu treinamento demora 40 minutos apenas para "listar" os arquivos antes de começar a primeira época, seu sistema de arquivos POSIX é a causa raiz.
A Via Expressa: GPUDirect Storage e a eliminação do gargalo da CPU
Aqui está a evidência mais condenatória em sistemas legados: a CPU está exausta fazendo trabalho de entregador.
No modelo tradicional, para carregar dados do SSD para a GPU, os dados fazem uma viagem turística desnecessária:
SSD -> Memória RAM do Sistema (Bounce Buffer da CPU).
CPU gerencia a cópia.
Memória RAM -> PCIe Bus -> Memória da GPU (VRAM).
Isso causa dois problemas: latência extra e, pior, poluição do cache da CPU e consumo de largura de banda de memória que deveria estar servindo à lógica da aplicação, não à movimentação de bytes.
A tecnologia GPUDirect Storage (GDS) (e equivalentes de outros vendors) cria um caminho DMA (Direct Memory Access) direto entre o Storage e a GPU.
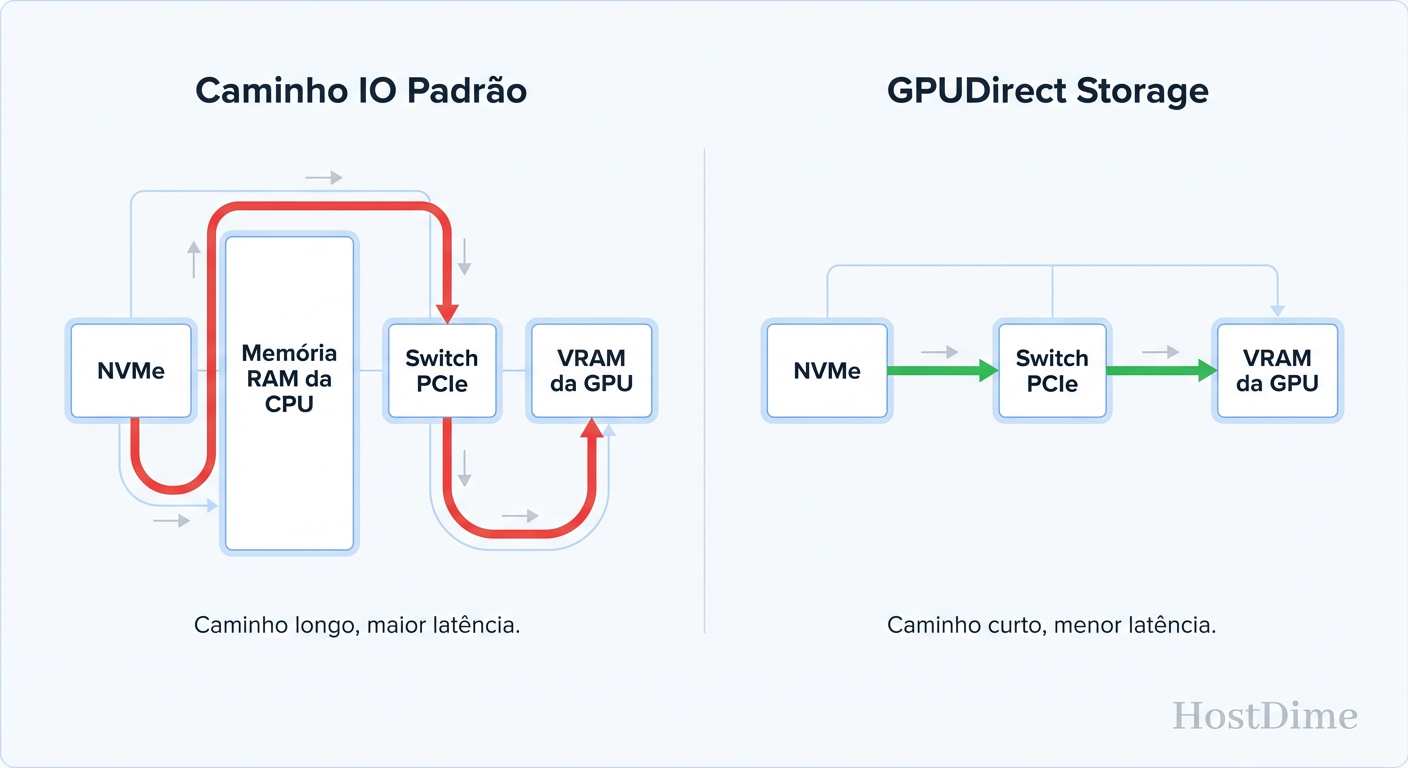 Figura: GPUDirect Storage: Eliminando o 'Bounce Buffer' da CPU para reduzir a latência e a carga do processador.
Figura: GPUDirect Storage: Eliminando o 'Bounce Buffer' da CPU para reduzir a latência e a carga do processador.
Ao eliminar o "Bounce Buffer", reduzimos a latência de carga, mas o ganho crítico é liberar a CPU. Em clusters de treinamento densos, onde a CPU já luta para manter o agendamento de kernels da GPU, remover a carga de I/O da CPU é a diferença entre 80% e 99% de utilização da GPU.
Callout de Investigação: Se você usa NVIDIA e seus logs mostram alta utilização de "System Memory" mas baixo I/O throughput durante o carregamento de dados, você está sofrendo do efeito Bounce Buffer. Habilite o GDS e verifique se o driver do filesystem suporta essa via expressa.
Computational Storage em 2026: Movendo a busca vetorial para o SSD
Estamos vendo uma mudança de paradigma: em vez de mover dados até a computação, movemos a computação até os dados.
Em 2026, SSDs com capacidades de Computational Storage (CSD) estão se tornando padrão para grandes Vector DBs. Imagine ter que escanear 100 Terabytes de vetores para encontrar uma similaridade. Puxar 100TB para a DRAM do servidor é inviável e caro.
Com CSD, o comando de busca é enviado para o SSD. O processador ARM ou FPGA dentro do drive executa a filtragem e retorna apenas os resultados (alguns Kilobytes).
Isso resolve o problema da largura de banda. Não estamos mais entupindo o barramento PCIe com dados que serão descartados. Estamos usando o SSD como um coprocessador de inferência. Se você está arquitetando RAG para datasets de escala de Petabytes, procure por drives que suportem push-down predicates ou execução vetorial in-situ.
Checkpoints de Treinamento: O pesadelo de escrita que ninguém planeja
Todo mundo foca na leitura (alimentar a GPU). Mas a investigação de falhas em longos treinamentos revela um vilão diferente: o Checkpointing.
Modelos LLM grandes precisam salvar seu estado (pesos, gradientes, estados do otimizador) frequentemente para evitar perder dias de trabalho em caso de falha. Esses dumps são massivos. Estamos falando de escrever terabytes de dados para o disco o mais rápido possível.
Durante o checkpoint, o treinamento para. As GPUs ficam ociosas. É o "Stop-the-World" do AI.
Se o seu storage tem excelente performance de leitura (para RAG) mas péssima performance de escrita sequencial (comum em alguns arrays QLC mal configurados ou Object Storage com gateways lentos), seus checkpoints vão demorar minutos em vez de segundos.
O Teste de Fogo: Não confie na folha de especificações do fabricante ("Até 10GB/s"). A realidade sob carga é diferente. O cache de escrita do storage enche, e a performance cai para a velocidade nativa da NAND. Você precisa dimensionar o throughput de escrita sustentada para ser capaz de drenar a VRAM de todas as suas GPUs em menos de 60 segundos.
Métricas Reais: Como medir o impacto do storage no 'Time to First Token' (TTFT)
Como investigador, não aceito "o sistema parece lento". Precisamos de evidência. Métricas médias mentem. A média esconde os picos de latência que causam jitter na geração de texto.
Para validar sua infraestrutura de Storage para AI, você precisa medir o seguinte:
Tail Latency (p99 e p99.9): No RAG, se 1 em cada 100 requisições de storage demora 500ms, a experiência do usuário é quebrada. Meça a latência de cauda.
GPU Starvation Time: Use ferramentas de perfilamento (como Nsight Systems) para medir quanto tempo a GPU passa no estado de espera por dados.
Throughput de Checkpoint: Cronometre o tempo exato de pausa durante um
torch.save().
Simulando a Carga (Não use dd)
O comando dd é inútil para simular carga de AI. Use fio com um perfil misto que imite o "Liquidificador RAG".
# Exemplo de teste de estresse simulando RAG (Conceitual)
# Mistura de leitura aleatória (Vector lookup) e sequencial (Chunk retrieval)
fio --name=rag_simulation \
--ioengine=libaio --direct=1 \
--bs=4k,128k \
--ba=4k,128k \
--rw=randread \
--iodepth=64 --numjobs=16 \
--rwmixread=100 \
--percentage_random=80 \
--filename=/mnt/ai_data/testfile \
--size=100G
Nota: Este comando gera 80% de tráfego aleatório (simulando busca de índice) e mistura tamanhos de bloco. Ajuste --bs (block size) para refletir o tamanho real dos seus chunks de texto.
Veredito
Em 2026, o gargalo da AI mudou. Não é mais apenas "comprar mais GPUs". Se o seu storage não fala a língua do paralelismo massivo, se ele depende de protocolos POSIX dos anos 90, e se ele obriga a CPU a copiar dados manualmente, você está queimando dinheiro.
A infraestrutura ideal de GenAI hoje é híbrida na lógica, mas unificada na performance: Object Storage rápido sobre NVMe para o dataset principal, GPUDirect para alimentar as feras, e uma obsessão saudável por latência de cauda, não apenas por throughput de marketing.
Caso encerrado.
Referências & Leitura Complementar
NVIDIA GPUDirect Storage Design Guide: Documentação técnica sobre a arquitetura de bypass de CPU e requisitos de DMA.
SNIA Computational Storage Architecture: Especificações sobre como mover funções de computação para dispositivos de armazenamento (NVMe).
The Case for Object Storage in AI: Whitepapers comparando overhead de metadados entre POSIX e S3-compatible APIs em datasets de bilhões de objetos.
eBPF for Storage Observability: Técnicas avançadas de rastreamento de latência de I/O no kernel Linux.

Alexei Volkov
Ceph Cluster Administrator
Escala clusters Ceph para o infinito. Mestre em CRUSH maps e recuperação de placement groups.