Storage Spaces Direct vs. Hardware RAID: Performance, Riscos e Arquitetura
Pare de adivinhar entre S2D e RAID tradicional. Uma análise profunda de engenharia sobre latência, overhead de CPU, resiliência e quando o Software-Defined Storage mata o Hardware RAID (e vice-versa).
Há uma década, a indústria declarou prematuramente a morte das controladoras RAID dedicadas. A promessa do Software Defined Storage (SDS) era sedutora: hardware commodity, independência de vendor e inteligência movida para o sistema operacional. No ecossistema Microsoft, o Storage Spaces Direct (S2D) é o campeão dessa filosofia.
No entanto, como engenheiro de performance, aprendi a ser cético quanto a abstrações que prometem "custo zero". A física do movimento de dados não perdoa. A escolha entre S2D e Hardware RAID não é uma questão de modernidade versus legado, mas sim de onde você escolhe pagar a conta computacional: em ciclos de CPU da sua aplicação ou em silício dedicado (ASIC).
Este artigo disseca a arquitetura de I/O, os custos ocultos de latência e como validar qual abordagem sustenta melhor o seu workload.
O que é a diferença fundamental entre S2D e RAID?
Storage Spaces Direct (S2D) é uma arquitetura de armazenamento definido por software que utiliza a CPU do host e a rede para agrupar discos locais em um pool resiliente, distribuindo dados entre múltiplos servidores (nós). Hardware RAID, por outro lado, utiliza uma controladora com processador dedicado (ASIC) e cache protegido por bateria para gerenciar a redundância e paridade dos discos dentro de um único chassi, isolando essa carga do sistema operacional.
A Arquitetura de I/O: HBA Pass-through vs. Abstração Lógica
Para entender a performance, precisamos primeiro entender como o sistema operacional "vê" o disco.
No modelo de Hardware RAID, o Windows Server é enganado. Ele vê um único volume lógico (ex: LUN 0). A complexidade da paridade, o striping e a verificação de erros são invisíveis para o kernel. Se um disco falha, a controladora lida com isso internamente. O OS apenas percebe uma leve degradação na latência.
No Storage Spaces Direct, a camada de abstração sobe para o OS. Para que o S2D funcione, as controladoras de disco devem estar em modo HBA (Host Bus Adapter) ou "Pass-through". O Windows vê cada disco físico individualmente (NVMe, SSD, HDD). O Software Storage Bus intercepta cada operação de I/O, calcula onde aquele bloco deve ser gravado (qual disco, em qual servidor) e executa a operação.
Isso nos leva ao primeiro grande trade-off: Visibilidade vs. Overhead. O S2D tem visibilidade total da saúde de cada drive (permitindo métricas SMART granulares), mas paga o preço de gerenciar cada transação na CPU principal.
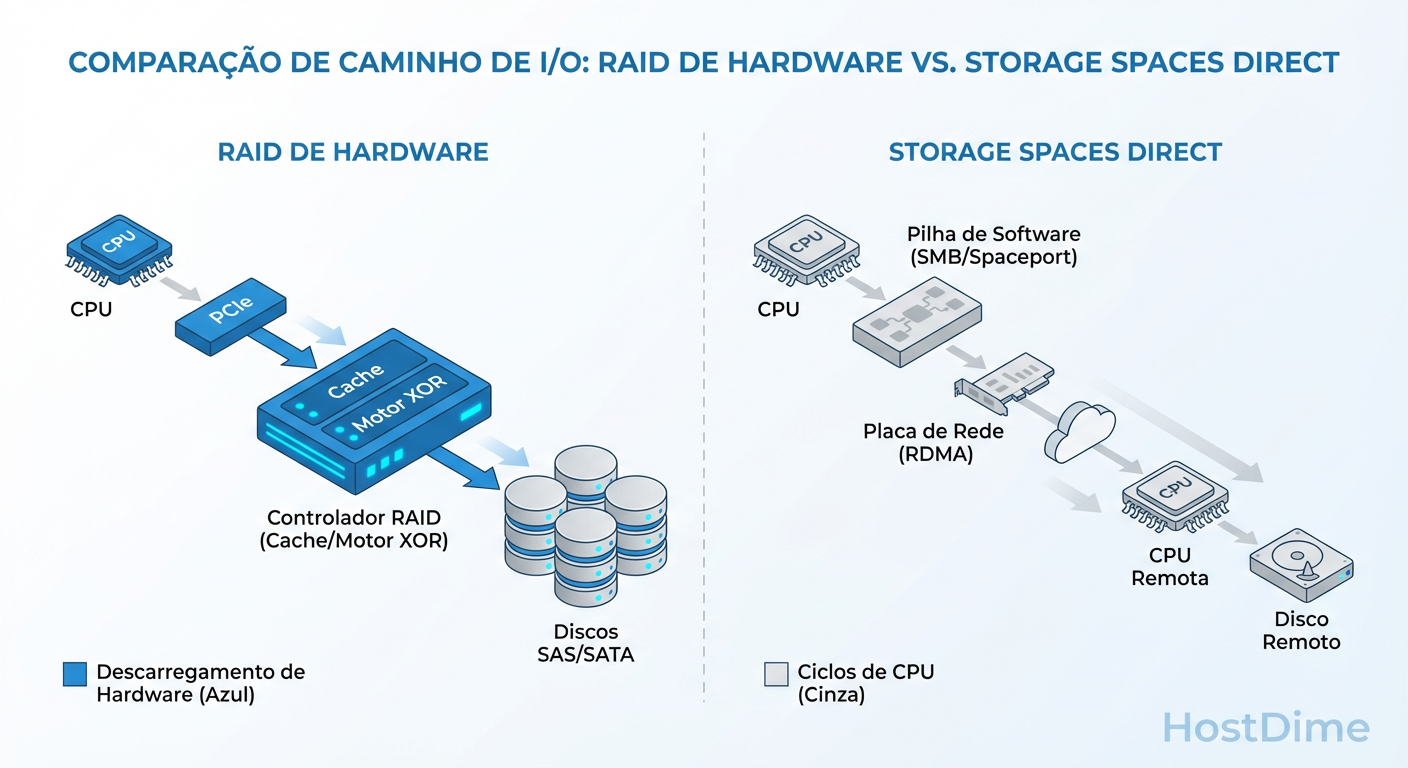 Figura: Diagrama do Caminho de I/O: Hardware RAID (Offload) vs. S2D (CPU + Network Latency)
Figura: Diagrama do Caminho de I/O: Hardware RAID (Offload) vs. S2D (CPU + Network Latency)
Latência e Processamento: Onde o Cálculo Acontece
A imagem acima ilustra o caminho crítico. Quando você grava um bloco de dados em um RAID 5 ou 6 via hardware, o cálculo de paridade (XOR ou Reed-Solomon) é feito por um chip dedicado (ROC - RAID on Chip). Isso é "Offload". Sua CPU Xeon ou EPYC fica livre para rodar SQL Server ou VMs.
O Custo da CPU no Storage Spaces Direct
No S2D, especialmente ao usar Mirroring de três vias ou Parity (Erasure Coding), é a CPU do host que faz a matemática.
Mirroring: Baixo custo de CPU, mas alto custo de I/O de rede (tráfego Leste-Oeste).
Parity/Erasure Coding: Alto custo de CPU. O cálculo de paridade compete diretamente com suas aplicações.
Se você dimensionou seu cluster S2D com pouca margem de CPU, durante picos de gravação, você verá um aumento na métrica % Processor Time e, consequentemente, um aumento na latência do disco (Avg. Disk sec/Write).
O Fator RDMA
É impossível discutir performance de S2D sem mencionar RDMA (Remote Direct Memory Access). Como o S2D precisa replicar dados entre nós síncronamente, a latência da rede torna-se latência de disco. Sem RDMA (RoCE ou iWARP), cada pacote de storage passa pela pilha TCP/IP do kernel, consumindo ainda mais CPU e adicionando microssegundos preciosos. Em Hardware RAID local, a latência de rede é zero.
Cache e Tiering: A Batalha dos Buffers
A gestão de cache é onde muitos administradores falham na configuração.
Hardware RAID: O Cache Protegido (BBWC)
Controladoras RAID Enterprise (PERC, SmartArray, MegaRAID) possuem de 2GB a 8GB de cache DRAM protegido por bateria ou supercapacitor. O superpoder: Quando o OS envia um Write, a controladora joga no cache DRAM, diz ao OS "Gravação Concluída" (ACK) instantaneamente e, depois, grava no disco lento (HDD). Isso transforma escritas aleatórias em sequenciais e mascara a latência física do disco.
S2D Storage Bus Cache
O S2D não tem bateria. Ele usa drives rápidos (NVMe ou SSD) como cache de leitura e escrita para drives lentos (HDD).
Mecanismo: Todo write vai primeiro para a camada de cache (NVMe/SSD). Depois, é destageado para a camada de capacidade.
O Risco: Se o cache encher (ex: um restore de backup massivo), a performance cai para a velocidade nativa dos HDDs, o que pode ser catastrófico ("write cliff"). Além disso, para garantir consistência, o S2D precisa confirmar a gravação em nós remotos antes de dar o ACK, o que, novamente, traz a latência de rede para a equação.
Callout de Risco: Sync Writes Em bancos de dados (SQL, Oracle), as gravações de log são síncronas (
FILE_FLAG_WRITE_THROUGH). Controladoras RAID lidam com isso excepcionalmente bem devido à NVRAM. No S2D, a latência dessas gravações depende da velocidade da rede e dos drives de cache. Se sua rede não for 25GbE+ com RDMA, bancos de dados OLTP sofrerão no S2D.
Resiliência e Rebuild: O Impacto na Produção
Discos falham. A métrica que separa a teoria da prática é: o quão degradada fica minha produção durante a reconstrução?
Hardware RAID: A Reconstrução Cega
O Hardware RAID é "burro" quanto aos dados. Se você tem um disco de 10TB num RAID 5, mas apenas 100GB ocupados, a controladora vai reconstruir todos os 10TB, bit a bit. Isso leva dias em HDDs modernos. Durante esse tempo, a performance de leitura sofre penalidade severa devido aos cálculos de XOR em tempo real para servir os dados que faltam.
S2D: A Reconstrução Inteligente (mas pesada)
O S2D reconstrói dados, não discos. Se o disco de 10TB tem 100GB de dados, ele só recopia 100GB. Além disso, ele lê as cópias dos outros nós do cluster. O perigo: O rebuild do S2D gera um tráfego massivo na rede de storage. Se não houver QoS (Quality of Service) configurado, o tráfego de rebuild pode saturar o link, derrubando a latência das VMs ativas.
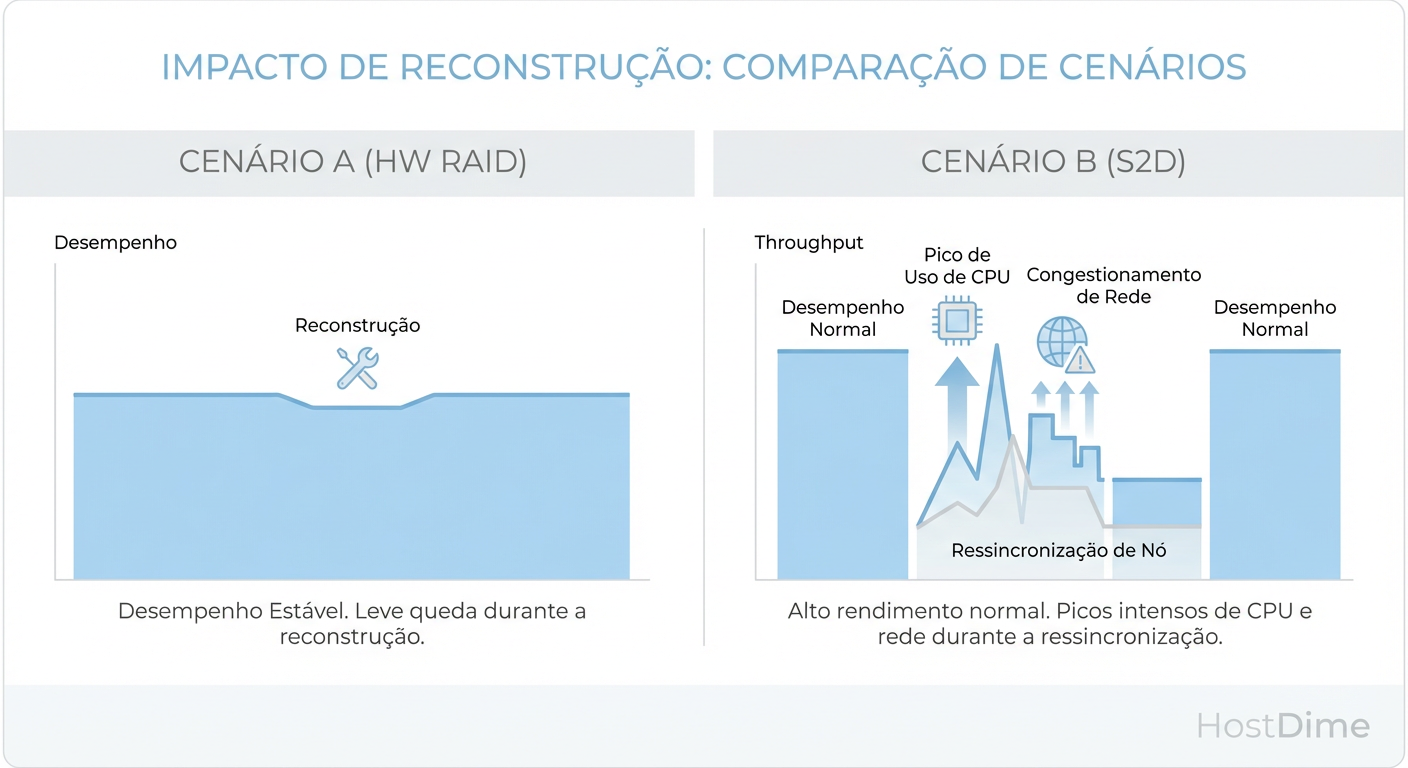 Figura: Impacto de Reconstrução (Rebuild) na Performance do Windows Server
Figura: Impacto de Reconstrução (Rebuild) na Performance do Windows Server
Como Medir a Verdade: Benchmarking com Diskspd
Não confie na folha de especificações. Você deve testar o subsistema de I/O simulando seu workload real. A ferramenta padrão ouro no Windows é o diskspd.
Para validar S2D vs RAID, você precisa isolar as variáveis. Não teste apenas "velocidade máxima". Teste latência sob carga.
Protocolo de Teste Sugerido
Workload Sintético de Banco de Dados (OLTP): 8K block size, 70% Read / 30% Write, Random.
Workload de Backup/Streaming: 64K ou 512K block size, 100% Write, Sequential.
Pre-conditioning: Se usar SSD/NVMe, encha o disco antes de testar para forçar o Garbage Collection.
Comando para teste de Latência (OLTP Simulation):
# -b8K: Bloco de 8KB (padrão SQL)
# -d60: Duração de 60 segundos
# -o4: 4 I/Os pendentes (Queue Depth)
# -t4: 4 threads
# -r: Random I/O
# -w30: 30% de escrita
# -L: Capturar estatísticas de latência
# -h: Desabilitar cache de software e hardware (Write Through) - CRÍTICO para teste real
diskspd.exe -b8K -d60 -o4 -t4 -r -w30 -L -h -D -c10G C:\ClusterStorage\Volume1\testfile.dat
O que analisar na saída:
Não olhe apenas para IOPS.
Olhe para a tabela de latência percentil. Quanto é o 99th percentile? Se for > 20ms, seu banco de dados vai reclamar.
No S2D, monitore o contador de performance
RDMA Activitydurante o teste.
Tabela Comparativa: Hardware RAID vs. Storage Spaces Direct
Abaixo, uma matriz para auxiliar na decisão arquitetural baseada em fatos técnicos, não em marketing.
| Característica | Hardware RAID | Storage Spaces Direct (S2D) |
|---|---|---|
| Custo Computacional | Baixo. Offload via ASIC dedicado. | Médio/Alto. Consome CPU do host (CRC, Paridade). |
| Dependência de Rede | Nenhuma (Local). | Crítica. Exige 10/25GbE+ RDMA para baixa latência. |
| Proteção de Cache | Bateria/Capacitor (NVRAM). Seguro contra power-loss. | Depende de PLP (Power Loss Protection) nos SSDs/NVMe físicos. |
| Escalabilidade | Limitada ao chassi do servidor. | Escala com adição de nós (Scale-out). |
| Tipo de Drive | Agnóstico (SAS/SATA). Mistura difícil. | Otimizado para NVMe. Exige HBA mode. |
| Rebuild | Lento e "cego" (disco inteiro). | Rápido e inteligente (apenas dados), mas usa rede. |
| Custo de Licença | Incluso no Hardware. | Exige Windows Server Datacenter Edition. |
Veredito Técnico: Quando o Hardware RAID ainda é Superior
O S2D é uma tecnologia fantástica para hiperconvergência (HCI) onde a escalabilidade horizontal é prioritária e se dispõe de hardware de rede adequado (RDMA).
Entretanto, o Hardware RAID continua superior (e a escolha correta) quando:
Servidores Standalone: Se você tem um servidor isolado (ex: um host de backup ou um servidor de arquivos de filial), S2D é complexidade desnecessária.
Workloads Sensíveis à CPU: Se cada ciclo de CPU conta para o licenciamento da sua aplicação (ex: Oracle), não desperdice ciclos calculando paridade de disco.
Boot Volumes: RAID 1 via hardware para o sistema operacional é imbatível em simplicidade e confiabilidade.
Orçamento de Rede Limitado: Se você não pode pagar switches 25GbE de baixa latência, o S2D terá performance medíocre.
A abstração é útil, mas nunca é gratuita. Meça, teste e decida onde você quer pagar o preço.
Referências & Leitura Complementar
Microsoft Docs: Storage Spaces Direct hardware requirements - Especificações críticas de rede e drives.
RFC 5040: A Remote Direct Memory Access Protocol Specification - Para entender a base do RDMA/iWARP.
Diskspd Documentation: GitHub Repository - A ferramenta oficial de engenharia de workload.
JEDEC Standard: Solid State Drive (SSD) Requirements and Endurance Test Method (JESD218) - Sobre a importância de PLP e endurance em SSDs usados para cache.

Thomas 'Raid0' Wright
High-Performance Computing Researcher
Trabalha com supercomputadores. Para ele, velocidade é tudo, e redundância é problema do software.