Storage Tiering Híbrido: Otimizando Ceph, vSAN e Storage Spaces na Escassez
Não compre Flash às cegas. Aprenda a arquitetar Tiering Inteligente e Caching em Ceph, vSAN e S2D para equilibrar IOPS e custo sem sacrificar a integridade dos dados.
O cenário é clássico: o sistema de monitoramento acende em vermelho às 10:00 da manhã. A latência de disco, que deveria estar em confortáveis 2ms, saltou para 400ms. O throughput caiu. As VMs estão travando. Quando chegamos para a autópsia do incidente, a causa raiz raramente é um disco queimado. O "crime" foi cometido meses antes, na arquitetura.
Alguém tentou economizar misturando SSDs de consumo (ou poucos NVMes) com uma montanha de HDDs lentos, esperando que o software fizesse mágica. O buffer encheu, e o sistema colidiu com a realidade física do disco rotacional.
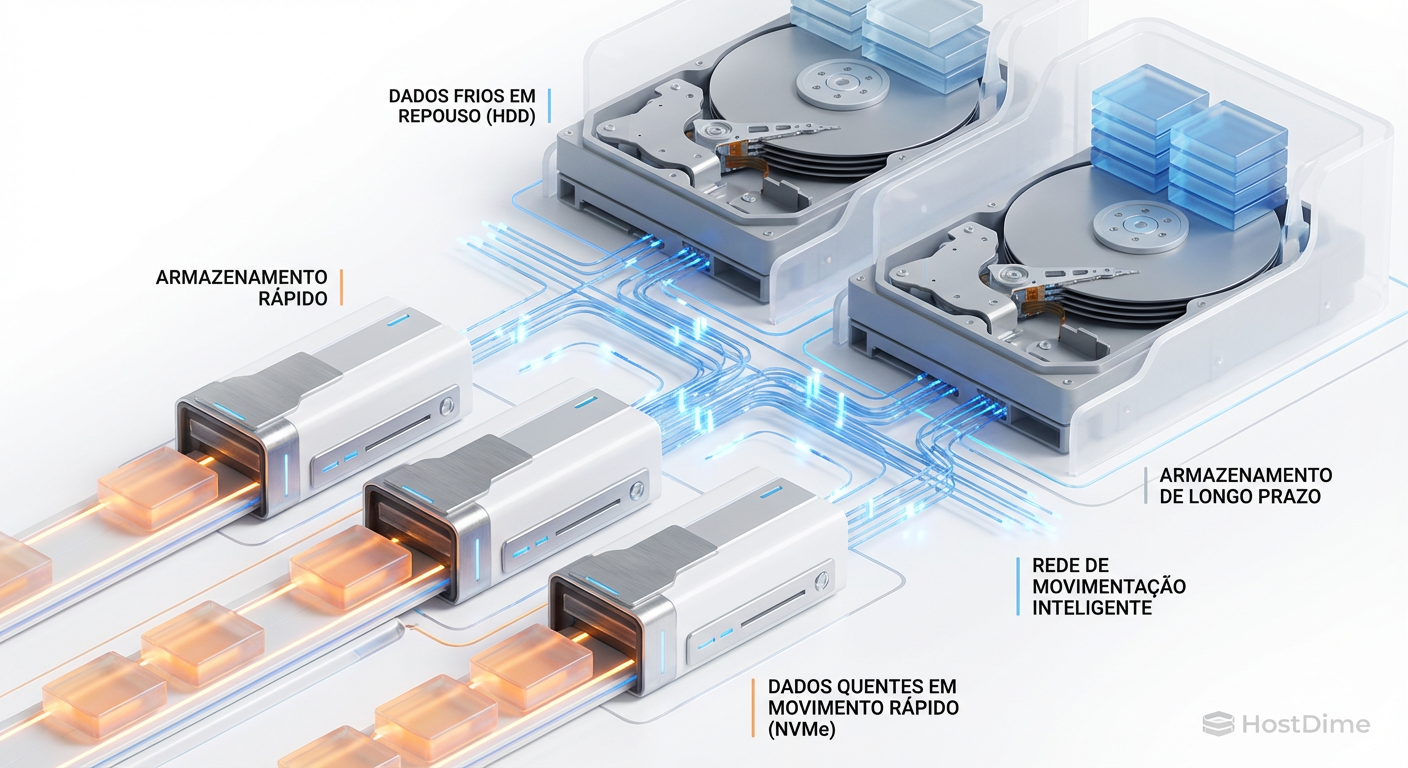
Storage Tiering Híbrido é a prática de combinar mídias de diferentes desempenhos (NVMe, SSD, HDD) em um único pool lógico para equilibrar custo e velocidade. Diferente do Caching (onde a mídia rápida é apenas uma cópia temporária), no Tiering o dado reside fisicamente na camada que corresponde à sua frequência de acesso, movendo-se entre camadas (Hot/Cold) conforme a demanda.
A Física da Escassez e a Mistura de Mídias
Vamos estabelecer a primeira regra da forense de storage: você não pode enganar a física. A mistura de mídias é um mal necessário impulsionado pelo orçamento, não uma virtude técnica. Se tivéssemos orçamento infinito, tudo seria NVMe ou Optane.
O problema central ao misturar SSDs e HDDs não é apenas a velocidade, é a natureza do I/O.
Flash (NVMe/SSD): Excelente em operações aleatórias (IOPS) e paralelas.
Magnético (HDD): Aceitável em operações sequenciais (Throughput), mas abismal em aleatórias.
Quando você desenha uma solução híbrida, você está apostando que seu algoritmo (seja Ceph, vSAN ou S2D) conseguirá serializar as escritas aleatórias na camada rápida antes de descarregá-las (destage) para a camada lenta. Se a entrada de dados (ingest) for mais rápida que a capacidade de drenagem da camada lenta, o sistema engasga.
Tiering vs. Caching: O Grande Mal-Entendido
Na análise de falhas catastróficas de dados, a confusão entre esses dois conceitos é a causa número um de perda de dados inesperada.
Caching (Write-Back/Read-Cache): A camada rápida atua como um buffer. O dado "quente" é uma cópia. Se for cache de leitura e o SSD morrer, nada acontece (basta ler do HDD). Se for cache de escrita, você tem risco até o dado ser gravado no HDD.
Tiering: O dado vive na camada. Se um bloco de dados é promovido para o Tier de Performance (SSD), ele sai do Tier de Capacidade (HDD).
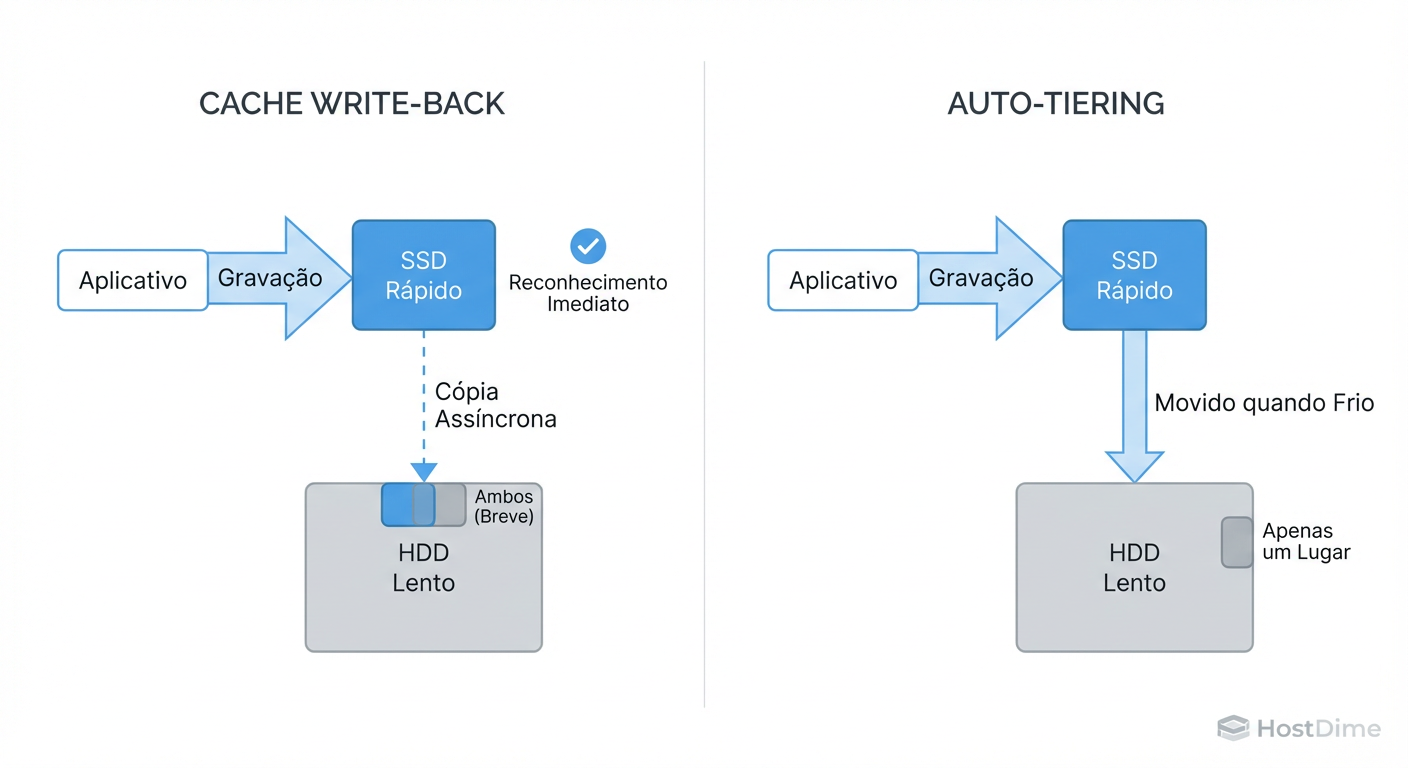 Figura: Diferença Arquitetural: No Caching (esquerda), a mídia lenta é a autoridade final. No Tiering (direita), o dado vive onde a performance dita.
Figura: Diferença Arquitetural: No Caching (esquerda), a mídia lenta é a autoridade final. No Tiering (direita), o dado vive onde a performance dita.
O Risco Forense: No Tiering, se você perder o drive de SSD e não tiver redundância dentro dessa camada, você perdeu o dado. Não há cópia no HDD. Arquiteturas que tratam Tiering como Caching acabam com backups inconsistentes ou perda de dados em falhas de hardware.
Ceph e a Ilusão do "Cache Tiering" Nativo
Muitos administradores caem na armadilha do recurso nativo de "Cache Tiering" do Ceph. No papel, parece perfeito: um pool de NVMe na frente de um pool de HDD. Na prática, é um pesadelo operacional.
O agente de tiering do Ceph precisa decidir constantemente o que promover (subir) e rebaixar (descer). Esse processo de decisão consome CPU e gera I/O extra. Frequentemente, vemos clusters onde o tráfego de rebalanceamento entre tiers é maior que o tráfego real do cliente. O resultado? O desempenho piora com o tiering ativado.
A Solução: CRUSH Rules e Classes de Dispositivo
Em vez de tiering automático, a abordagem forense correta é a segregação determinística. Use CRUSH Rules para criar pools dedicados.
Pool Gold (NVMe): Para bancos de dados e logs de transação.
Pool Silver (HDD): Para object storage, backups e arquivos frios.
Você configura isso no nível da aplicação (ex: Kubernetes StorageClass) ou do volume, não deixando o Ceph "adivinhar" onde o dado deve ficar.
# Exemplo: Criando uma regra CRUSH que força o uso APENAS de SSDs
ceph osd crush rule create-replicated rule-ssd default host ssd
ceph osd pool create pool-fast 32 32 rule-ssd
Isso elimina a latência de "cache miss" e o overhead de promoção. Você garante performance onde paga por ela.
Otimizando vSAN: Write Buffer e Storage Policies
No ecossistema VMware vSAN (especificamente na arquitetura OSA - Original Storage Architecture), o conceito de híbrido é rígido: cada Disk Group tem 1 SSD de Cache e até 7 HDDs de Capacidade.
O SSD de cache é dividido:
70% Read Cache (apenas para híbrido, All-Flash não usa read cache).
30% Write Buffer.
O problema investigativo surge no Destaging. O vSAN precisa esvaziar os 30% de buffer para os HDDs. Se seus HDDs são lentos (ex: 7.2k RPM NL-SAS) e sua carga de escrita é contínua, o buffer enche.
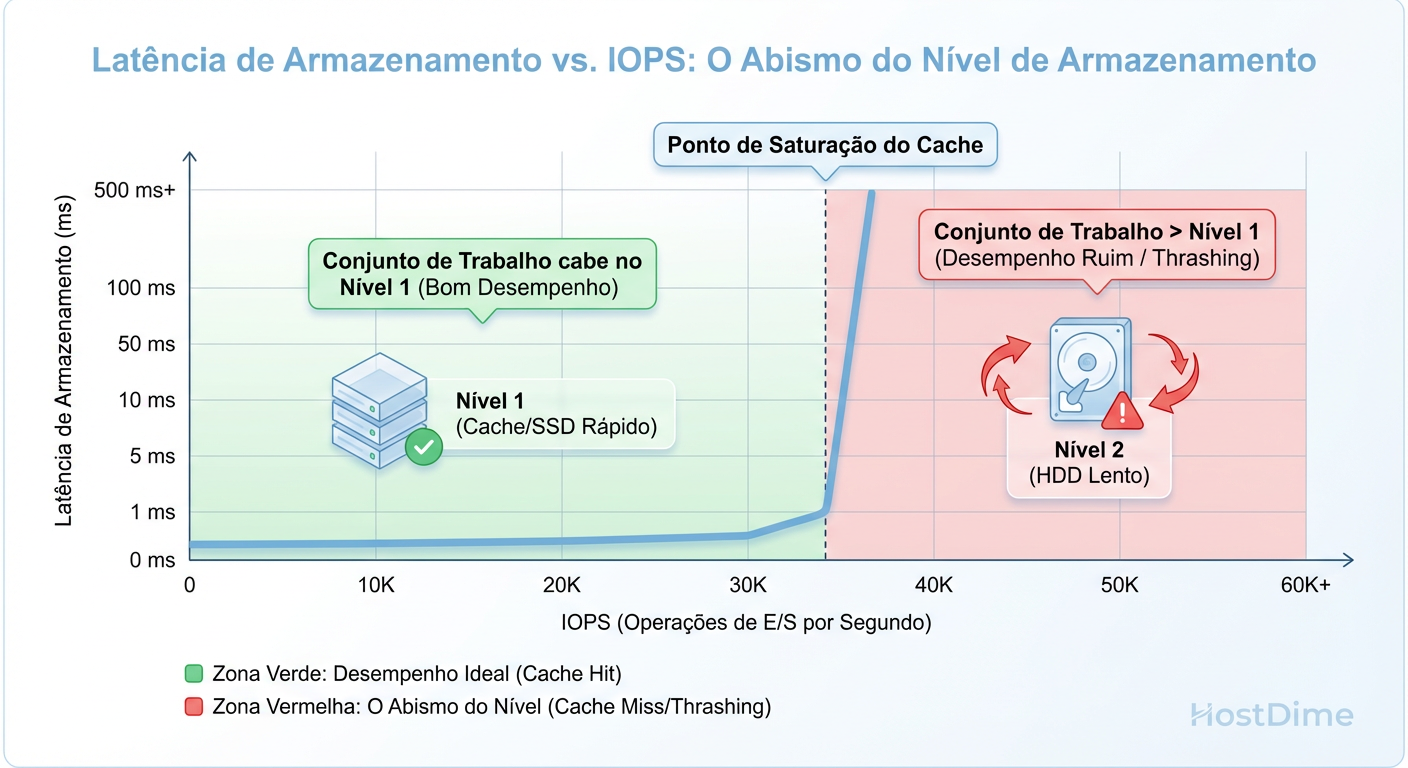 Figura: O Abismo do Tiering: O que acontece com a latência quando seu Working Set excede a capacidade da camada rápida.
Figura: O Abismo do Tiering: O que acontece com a latência quando seu Working Set excede a capacidade da camada rápida.
Quando o buffer atinge limites críticos, o vSAN aplica "back pressure", introduzindo latência artificial nas VMs para frear a escrita.
Tática de Sobrevivência no vSAN
Não confie no padrão. Use Storage Policies para mitigar o impacto:
Stripe Width: Aumente o número de stripes para forçar a escrita em múltiplos discos de capacidade simultaneamente (paralelismo), acelerando o destaging.
Object Space Reservation: Em cenários de extrema escassez, reservar espaço não ajuda na performance, mas garante que você não terá falhas de "out of space" durante movimentações de tier.
Storage Spaces Direct (S2D) e o Mirror-Accelerated Parity
A Microsoft tem uma abordagem fascinante e pragmática com o S2D no Windows Server e Azure Stack HCI. Eles criaram o Mirror-accelerated Parity (MAP).
Em vez de ter um drive de cache dedicado e drives de dados separados, o MAP cria um volume lógico que é uma quimera:
Parte do volume é Mirror (RAID-1): Rápido, escrita em 3 vias.
Parte do volume é Parity (Erasure Coding): Eficiente em espaço (como RAID-5/6).
As escritas caem na zona de Mirror (rápida). Quando essa zona enche ou o sistema fica ocioso, o S2D rotaciona os dados, compactando-os e movendo-os para a zona de Parity no mesmo volume.
 Figura: Anatomia do S2D: O volume híbrido que combina a velocidade de escrita do espelhamento com a eficiência de espaço da paridade.
Figura: Anatomia do S2D: O volume híbrido que combina a velocidade de escrita do espelhamento com a eficiência de espaço da paridade.
Configurando MAP para Performance
O erro comum é deixar o padrão de 10-20% de Mirror. Se seu Working Set diário for maior que a zona de Mirror, o desempenho despenca para a velocidade da paridade (que é computacionalmente pesada).
Para verificar e ajustar, você precisa ir além da GUI:
# Verificar a proporção atual das camadas
Get-StorageTier | Select FriendlyName, MediaType, ResiliencySettingName, Size
# Ao criar um volume, defina explicitamente o tamanho do tier de performance
New-Volume -FriendlyName "DataVol01" -FileSystem CSVFS_ReFS `
-StoragePoolFriendlyName "S2D Pool" -Size 10TB `
-StorageTierFriendlyNames Performance, Capacity `
-StorageTierSizes 2TB, 8TB
Neste exemplo, garantimos 2TB de "pista de pouso" rápida. Se seus usuários gravam 3TB por dia, você terá problemas.
Matemática de Sobrevivência: Calculando o Working Set Size (WSS)
A maioria dos incidentes de performance em storage híbrido ocorre porque o arquiteto dimensionou o cache baseando-se em uma porcentagem arbitrária (ex: "10% da capacidade total"). Isso é errado. O cache deve ser dimensionado pelo Working Set Size (WSS).
WSS = A quantidade de dados únicos acessados/gravados em um intervalo de tempo crítico.
Se você tem 100TB de dados, mas apenas 500GB são acessados diariamente ("hot data"), seu cache precisa cobrir esses 500GB confortavelmente, mais uma margem para picos de destaging.
Tabela Comparativa de Expectativa de Realidade
| Métrica | Flash (NVMe/SSD) | HDD (Mecânico) | O que acontece no Híbrido mal dimensionado |
|---|---|---|---|
| Latência | 0.1ms - 0.5ms | 5ms - 15ms | Picos de 100ms+ (Thrashing) |
| IOPS | 10k - 500k+ | 80 - 150 | Cai para a velocidade do HDD quando o cache enche |
| Falha | Bloco morre, realocação | Falha mecânica total | Rebuild demora dias, degradando todo o cluster |
| Custo/GB | Alto | Baixo | Economia ilusória se a operação parar |
Veredito Operacional
Como investigador, minha conclusão ao analisar sistemas híbridos colapsados é quase sempre a mesma: complexidade excessiva para economia marginal.
Use este checklist antes de optar por Tiering Híbrido:
Conheço meu WSS? (Se você não sabe quanto dado quente tem, não pode dimensionar o tier rápido).
A carga é previsível? (Tiering funciona bem para file servers, mal para VDI ou DBs transacionais pesados).
O software é inteligente? (Prefira S2D MAP ou vSAN ESA; evite Ceph Cache Tiering legado).
Posso isolar cargas? (Se puder, faça pools All-Flash pequenos para o que importa e deixe o híbrido para o resto).
Na dúvida, simplifique. O armazenamento All-Flash SATA barato muitas vezes supera uma arquitetura híbrida NVMe+HDD complexa e mal configurada, simplesmente porque elimina a variável mais lenta da equação: o braço mecânico do disco e a necessidade de mover dados entre camadas.
Referências & Leitura Complementar
Ceph Documentation: "CRUSH Maps and Rules" - Entendendo como isolar pools fisicamente.
VMware Docs: "vSAN Design Guide - Write Buffer Sizing" - Detalhes sobre a regra dos 30% e políticas de stripe.
Microsoft TechCommunity: "Storage Spaces Direct - Understanding the Cache and Tiering" - Aprofundamento no MAP.
Gregg, Brendan: "Systems Performance: Enterprise and the Cloud" - Bíblia para entender latência de disco e metodologias de análise.

Priya Patel
Data Center Operations Lead
Gerencia milhares de discos físicos. Sabe exatamente qual modelo de HDD vibra mais e qual SSD morre primeiro.