Block, File e Object Storage: Um Guia Definitivo para Sysadmins e Engenheiros de Infraestrutura

Entender as nuances entre Block Storage, File Storage e Object Storage é crucial para qualquer profissional de infraestrutura. A escolha inadequada pode levar a...
Block, File e Object Storage: Um Guia Definitivo para Sysadmins e Engenheiros de Infraestrutura
Entender as nuances entre Block Storage, File Storage e Object Storage é crucial para qualquer profissional de infraestrutura. A escolha inadequada pode levar a gargalos de performance, custos inflacionados e dores de cabeça na escalabilidade. Este guia desmistifica cada tipo de armazenamento, explorando seus modelos mentais, funcionamento interno, casos de uso ideais e como tomar a decisão certa para suas necessidades.
O Problema Real: Escolhendo a Ferramenta Certa para o Trabalho
A proliferação de opções de armazenamento pode ser paralisante. Não existe uma "bala de prata". Cada tipo de armazenamento foi projetado para resolver problemas específicos, com tradeoffs inerentes.
- Block Storage: Velocidade e controle bruto, ideal para aplicações que exigem acesso direto ao hardware.
- File Storage: Facilidade de uso e organização hierárquica, perfeito para compartilhamento de arquivos e ambientes tradicionais.
- Object Storage: Escalabilidade massiva e baixo custo, a escolha óbvia para dados não estruturados e armazenamento de longo prazo.
A chave é entender esses tradeoffs e alinhar a solução de armazenamento com os requisitos da sua aplicação e infraestrutura.
Block Storage: O Poder do Acesso Direto
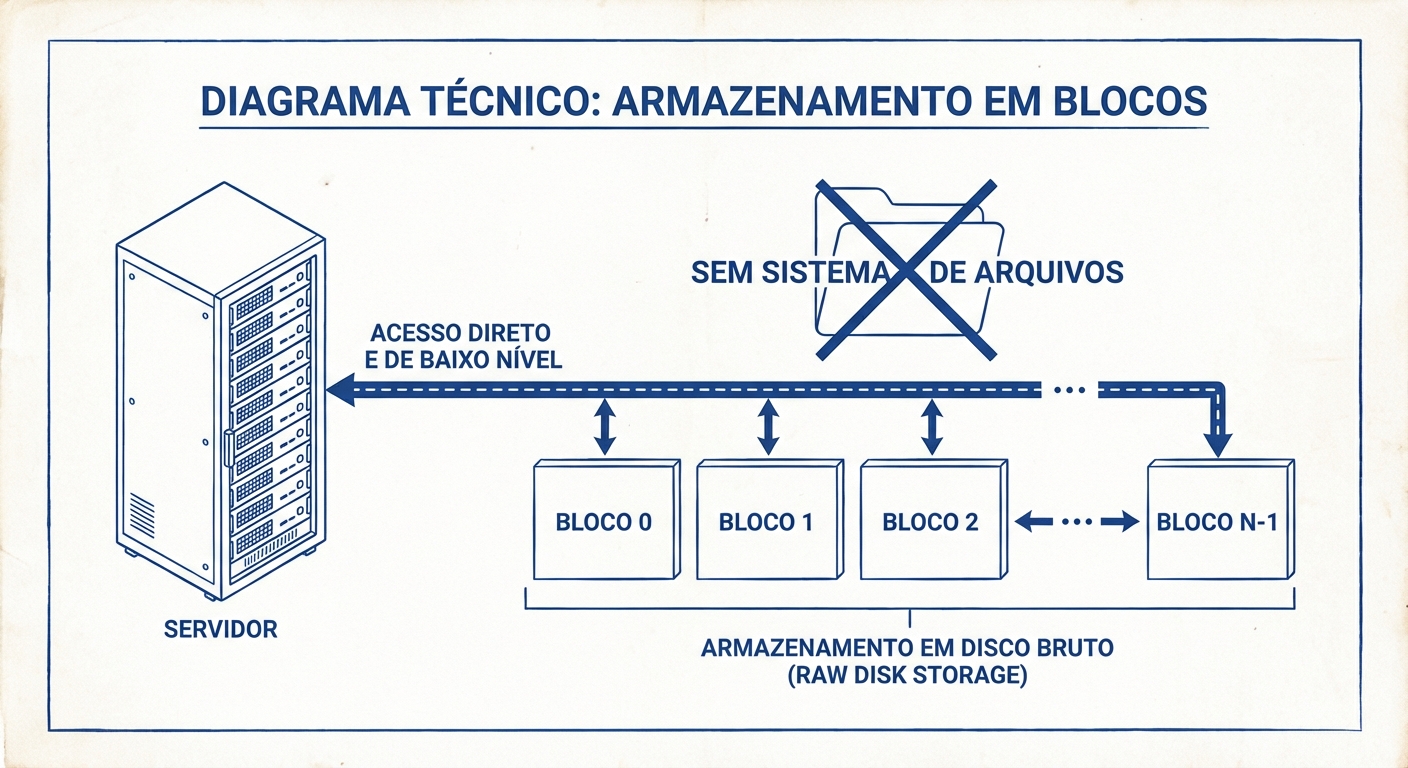
Imagine um disco rígido cru, sem sistema de arquivos. É essa a essência do Block Storage. Os dados são divididos em blocos de tamanho fixo (tipicamente 512 bytes a 4KB) e armazenados independentemente. O sistema operacional tem controle total sobre onde cada bloco é gravado e lido.
O Modelo Mental: Um espaço de armazenamento bruto, endereçado por blocos. Você é responsável por organizar e gerenciar os dados dentro desses blocos.
Por Baixo do Capô:
- LVM (Logical Volume Manager): Uma camada de abstração que permite criar volumes lógicos a partir de discos físicos, facilitando o redimensionamento e o gerenciamento do espaço. O LVM opera no nível do kernel, interceptando as solicitações de I/O e mapeando os blocos lógicos para os blocos físicos.
- iSCSI (Internet Small Computer System Interface): Um protocolo que permite transportar comandos SCSI (o protocolo usado para comunicação com discos) sobre uma rede IP. Isso permite que servidores acessem discos remotos como se fossem locais. Tecnicamente, o iSCSI encapsula comandos SCSI em pacotes TCP/IP.
- SAN (Storage Area Network): Uma rede dedicada de alta velocidade para interconectar servidores e dispositivos de armazenamento. As SANs tradicionalmente usam Fibre Channel, um protocolo de alta performance projetado especificamente para armazenamento. Mais recentemente, o iSCSI sobre Ethernet convergente (RoCE) tem ganhado popularidade.
- RAID (Redundant Array of Independent Disks): Uma técnica para combinar múltiplos discos físicos em um único volume lógico, aumentando a performance e/ou a redundância. Diferentes níveis de RAID oferecem diferentes tradeoffs entre performance, redundância e capacidade utilizável.
Cenários de Uso:
- Bancos de Dados: Bancos de dados como MySQL, PostgreSQL e Oracle se beneficiam do acesso direto e de baixa latência que o Block Storage oferece. Eles precisam de controle total sobre como os dados são gravados no disco para garantir a consistência e a durabilidade.
- Máquinas Virtuais (VMs): Cada VM recebe seu próprio volume de Block Storage, que é usado como disco rígido virtual. Isso permite que cada VM tenha seu próprio sistema de arquivos e aplicações, isoladas umas das outras.
- Aplicações de Alta Performance: Aplicações que exigem acesso rápido e consistente aos dados, como edição de vídeo e simulações científicas, podem se beneficiar do Block Storage.
Exemplo de Comando (LVM):
# Criar um volume group chamado "vgdata" usando o disco /dev/sdb
vgcreate vgdata /dev/sdb
# Criar um volume lógico de 100GB chamado "lvdata" dentro do vgdata
lvcreate -L 100G -n lvdata vgdata
# Formatar o volume lógico com ext4
mkfs.ext4 /dev/vgdata/lvdata
# Montar o volume lógico em /mnt/data
mount /dev/vgdata/lvdata /mnt/data
File Storage: A Familiaridade da Árvore de Diretórios
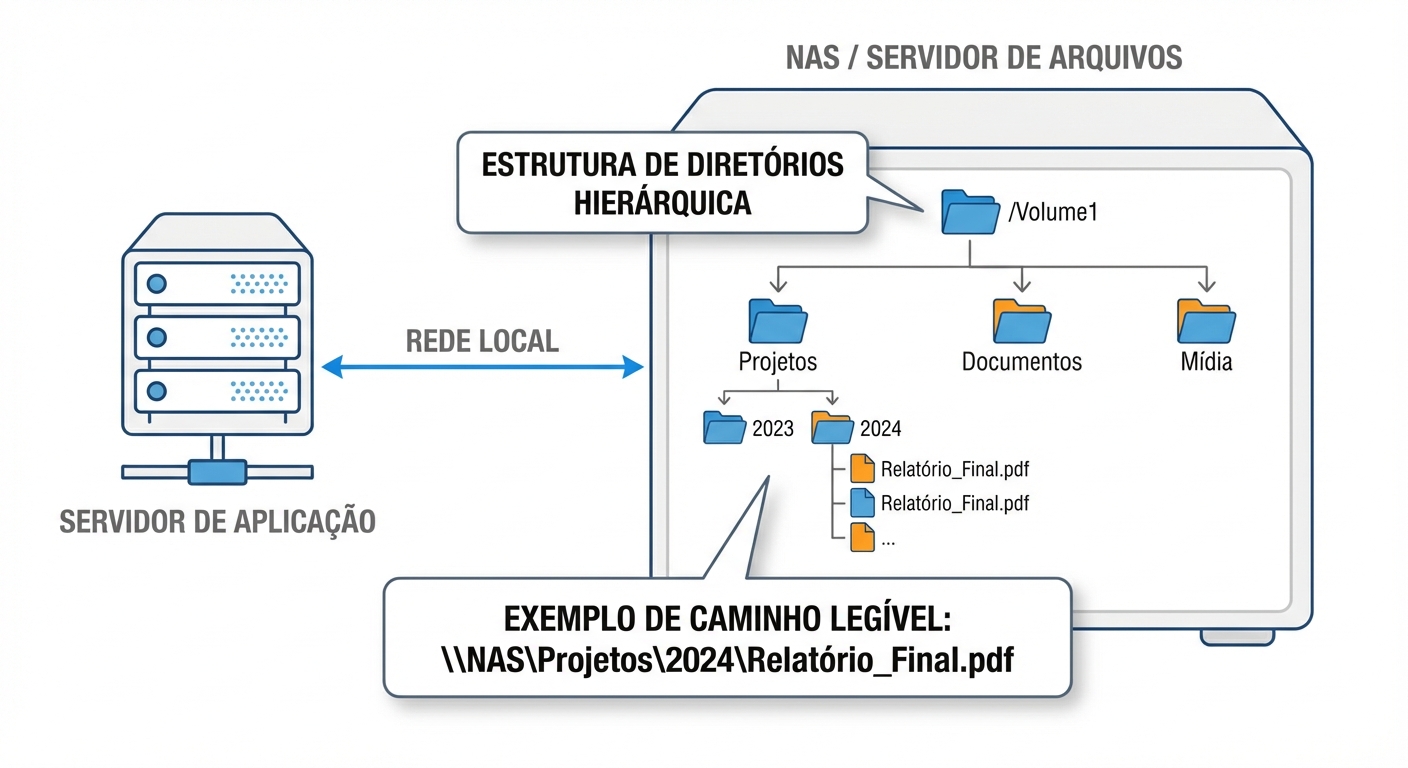
O File Storage organiza os dados em uma hierarquia de diretórios e arquivos, como um sistema de arquivos tradicional. Os arquivos são acessados por meio de nomes de arquivo e caminhos, e o sistema operacional gerencia a alocação de espaço em disco e o controle de acesso.
O Modelo Mental: Uma árvore de diretórios familiares, com arquivos organizados em pastas. Usuários e aplicações interagem com os arquivos usando operações como abrir, ler, escrever e fechar.
Por Baixo do Capô:
- NFS (Network File System): Um protocolo para compartilhar arquivos em uma rede. O NFS permite que clientes acessem arquivos em um servidor como se fossem locais. O NFS opera na camada de aplicação, usando RPC (Remote Procedure Call) para comunicar entre cliente e servidor.
- SMB/CIFS (Server Message Block/Common Internet File System): O protocolo de compartilhamento de arquivos padrão do Windows. O SMB permite que clientes Windows acessem arquivos em um servidor Windows ou em um servidor que suporte o protocolo SMB.
- NAS (Network Attached Storage): Um dispositivo dedicado ao armazenamento de arquivos que se conecta a uma rede. Um NAS geralmente executa um sistema operacional simplificado e oferece serviços de compartilhamento de arquivos por meio de NFS, SMB ou outros protocolos.
- Sistemas de Arquivos: Ext4, XFS, ZFS são exemplos de sistemas de arquivos que organizam os dados em disco. Eles são responsáveis por gerenciar o espaço em disco, o controle de acesso e a integridade dos dados.
Cenários de Uso:
- Servidores de Arquivos: Compartilhar arquivos entre usuários e aplicações, como documentos, planilhas e apresentações.
- Home Directories: Armazenar os arquivos pessoais dos usuários em um ambiente de rede.
- Compartilhamento de Código Fonte: Centralizar o código fonte de projetos de software para facilitar a colaboração entre desenvolvedores.
- Mídias: Armazenar arquivos de vídeo, áudio e imagem para edição, distribuição e arquivamento.
Exemplo de Comando (NFS):
# No servidor NFS:
# Instalar o servidor NFS
apt install nfs-kernel-server
# Editar /etc/exports para compartilhar o diretório /srv/nfs
echo "/srv/nfs *(rw,sync,no_subtree_check)" >> /etc/exports
# Exportar os diretórios compartilhados
exportfs -a
# No cliente NFS:
# Instalar o cliente NFS
apt install nfs-common
# Montar o diretório /srv/nfs do servidor no diretório /mnt/nfs do cliente
mount <ip_do_servidor>:/srv/nfs /mnt/nfs
Object Storage: A Escalabilidade Sem Limites
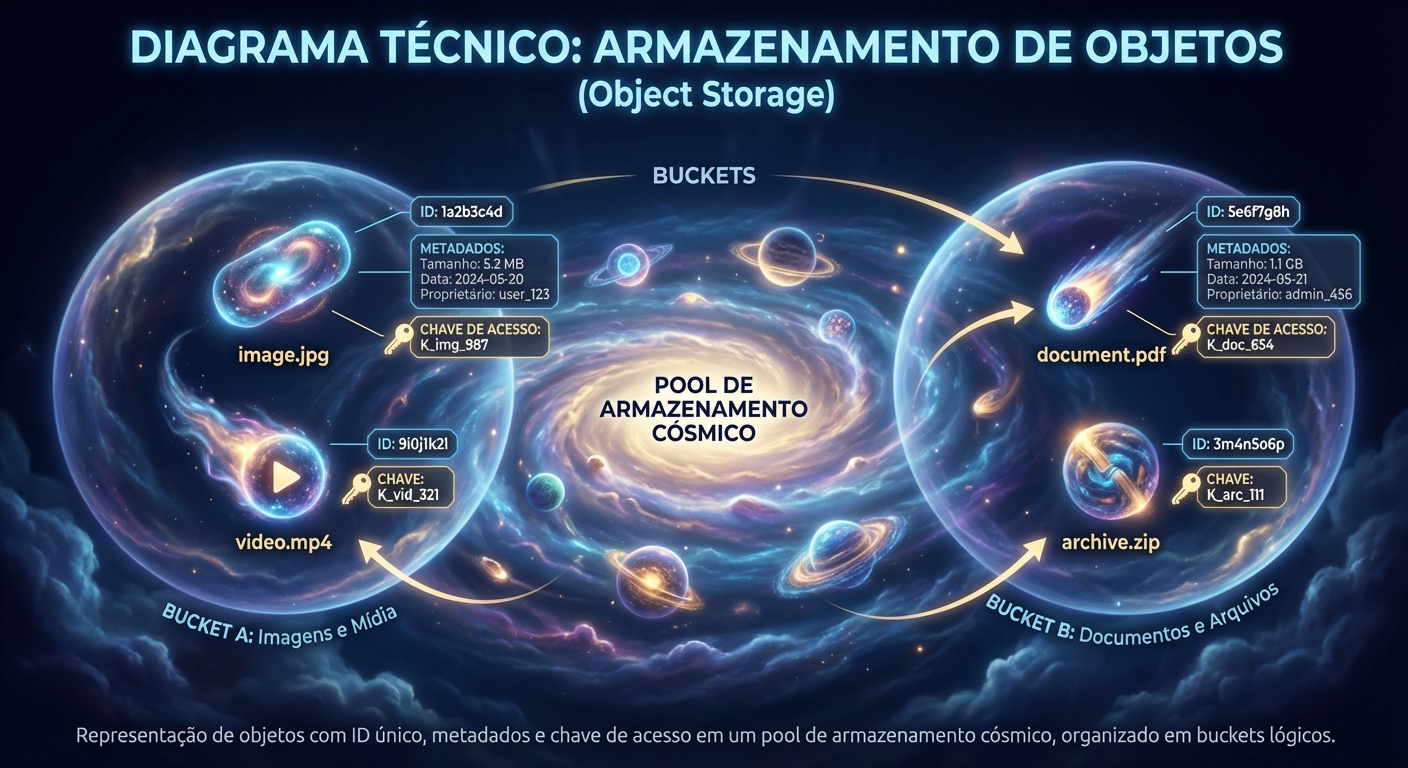
O Object Storage armazena os dados como objetos em um bucket (balde), sem uma hierarquia de diretórios. Cada objeto é identificado por uma chave única e contém os dados, metadados e um ID. O Object Storage é projetado para escalabilidade massiva e baixo custo, ideal para armazenar grandes quantidades de dados não estruturados.
O Modelo Mental: Um grande balde onde você joga objetos (arquivos). Cada objeto tem um nome (chave) e metadados associados. Não há hierarquia de diretórios.
Por Baixo do Capô:
- S3 (Simple Storage Service): O serviço de Object Storage da Amazon Web Services (AWS), que se tornou o padrão de facto para Object Storage.
- Swift: Um sistema de Object Storage open source desenvolvido pela OpenStack.
- MinIO: Um servidor de Object Storage open source compatível com a API S3, projetado para ser executado em hardware commodity.
- REST API: O Object Storage é acessado por meio de uma API REST, que permite criar, ler, atualizar e excluir objetos. A API REST permite que aplicações acessem o armazenamento de objetos de qualquer lugar, usando HTTP.
- Metadata: Cada objeto tem metadados associados, que podem incluir informações como o tipo de conteúdo, o tamanho do objeto e a data de criação. Os metadados podem ser usados para indexar e pesquisar os objetos.
- Distribuído e Escalável: O Object Storage é projetado para ser distribuído e escalável, permitindo que você armazene grandes quantidades de dados em vários servidores.
Cenários de Uso:
- Backups: Armazenar backups de dados de servidores, bancos de dados e aplicações.
- Data Lakes: Armazenar grandes quantidades de dados não estruturados para análise de dados e machine learning.
- CDNs (Content Delivery Networks): Armazenar conteúdo estático, como imagens, vídeos e arquivos CSS/JavaScript, para distribuição rápida e eficiente aos usuários.
- Arquivamento de Dados: Armazenar dados de longo prazo que não precisam ser acessados com frequência.
- Armazenamento de Mídia: Armazenar imagens, vídeos e áudios para aplicações web e móveis.
Exemplo de Comando (usando a AWS CLI):
# Configurar a AWS CLI com suas credenciais
aws configure
# Criar um bucket S3 chamado "meu-bucket"
aws s3 mb s3://meu-bucket
# Copiar o arquivo "meu-arquivo.txt" para o bucket S3
aws s3 cp meu-arquivo.txt s3://meu-bucket
# Listar os objetos no bucket S3
aws s3 ls s3://meu-bucket
Comparação Direta: Uma Visão Geral
| Característica | Block Storage | File Storage | Object Storage |
|---|---|---|---|
| Modelo Mental | Disco Cru | Árvore de Diretórios | Balde de Objetos |
| Acesso | Nível de Bloco | Nível de Arquivo | API REST (HTTP) |
| Latência | Muito Baixa | Baixa a Média | Média a Alta |
| Escalabilidade | Limitada (expansão complexa) | Moderada (depende do NAS) | Massiva (design) |
| Custo | Mais Caro | Moderado | Mais Barato |
| Uso Ideal | Bancos de Dados, VMs | Compartilhamento de Arquivos, Home Directories | Backups, Data Lakes, CDNs |
| Complexidade | Alta | Média | Baixa |
| Gerenciamento | Complexo | Moderado | Simples |
| Protocolos | iSCSI, Fibre Channel | NFS, SMB/CIFS | HTTP/HTTPS (REST) |
| Estrutura Dados | Não Estruturado | Hierárquico | Não Estruturado |
O Que Levar Disso: Escolhendo Sabiamente
A escolha entre Block Storage, File Storage e Object Storage depende dos requisitos específicos da sua aplicação e infraestrutura.
- Se você precisa de alta performance e controle total sobre o armazenamento, o Block Storage é a melhor opção. Ideal para bancos de dados, máquinas virtuais e aplicações que exigem acesso rápido e consistente aos dados.
- Se você precisa de compartilhamento de arquivos fácil e familiar, o File Storage é a escolha certa. Perfeito para servidores de arquivos, home directories e compartilhamento de código fonte.
- Se você precisa de escalabilidade massiva e baixo custo para armazenar grandes quantidades de dados não estruturados, o Object Storage é a solução ideal. A escolha óbvia para backups, data lakes, CDNs e arquivamento de dados.
Lembre-se que muitas vezes a melhor solução é uma combinação dos três tipos de armazenamento, cada um otimizado para sua respectiva função. Avalie cuidadosamente seus requisitos, faça testes e escolha a ferramenta certa para o trabalho.

Dr. Marcus 'Bitrot' Silva
Engenheiro Sênior de Armazenamento
20 anos recuperando RAIDs quebrados. Especialista em ZFS e sistemas de arquivos distribuídos. Já viu mais falhas de disco do que gostaria.