Tcp Tuning Para Iscsinvme Tcp O Que Ajustar

Antes de tocar em qualquer `sysctl`, você precisa visualizar o que acontece quando um bloco de dados sai da placa de rede (NIC) e tenta chegar ao disco virtual....
Tcp Tuning Para Iscsinvme Tcp O Que Ajustar
O Gargalo Invisível: Interrupções e Troca de Contexto
Antes de tocar em qualquer sysctl, você precisa visualizar o que acontece quando um bloco de dados sai da placa de rede (NIC) e tenta chegar ao disco virtual.
O maior inimigo do armazenamento de alto desempenho não é a largura de banda; é a CPU. Mais especificamente, o custo de processar pacotes. Em um fluxo iSCSI padrão de 4KB (tamanho de bloco comum em bancos de dados), um link de 10Gbps saturado exige processar cerca de 300.000 pacotes por segundo.
Se o seu kernel disparar uma interrupção de hardware para cada pacote recebido, sua CPU passará 100% do tempo atendendo a NIC e 0% do tempo gravando dados no disco. O Linux tenta mitigar isso com NAPI (New API) e interrupt coalescing, mas para storage, a latência introduzida por essa pilha de processamento é fatal.
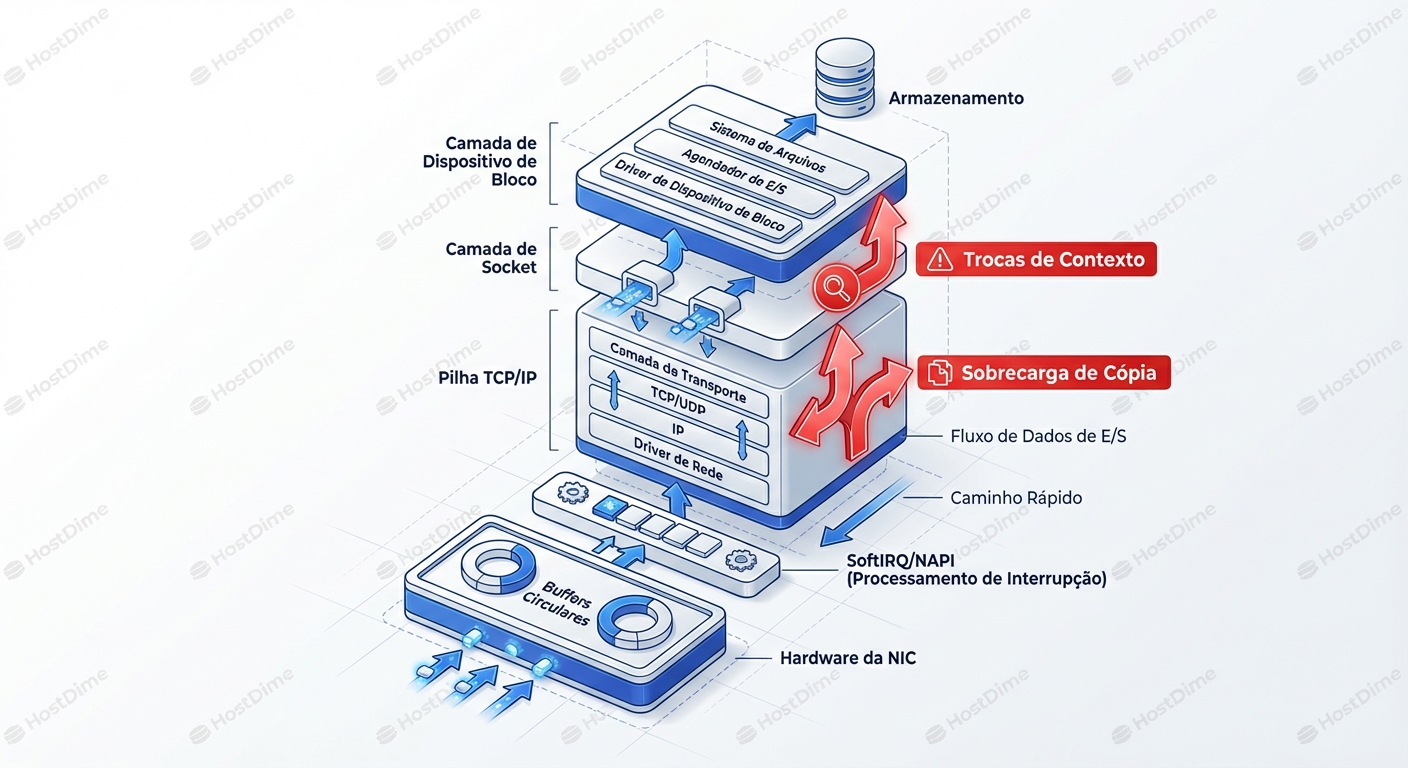
O diagrama acima ilustra o caminho da dor. Cada seta vermelha é um ponto onde a CPU precisa parar o que está fazendo, salvar o estado atual (context switch), tratar o pacote, copiar dados da memória do kernel para o espaço do usuário (ou vice-versa) e retomar.
Para iSCSI e NVMe-TCP, o objetivo do tuning é duplo:
- Reduzir a frequência de interrupções (fazer mais com menos chamadas).
- Manter o tubo cheio (evitar que o TCP pare para esperar confirmação).
A Primeira Vitória Fácil: Jumbo Frames (MTU)
Começamos pelo óbvio, mas é vital entender a matemática, não apenas a "boa prática". O padrão Ethernet é 1500 bytes. Um comando SCSI ou NVMe + payload geralmente é 4KB, 8KB ou muito maior.
Se você envia um bloco de 8KB com MTU 1500:
- O dado é fatiado em 6 pacotes.
- São 6 cabeçalhos IP/TCP (overhead de bytes).
- São 6 decisões de roteamento/processamento no kernel.
- São 6 interrupções potenciais (ou eventos de poll).
Se você usa Jumbo Frames (MTU 9000):
- O dado cabe em 1 pacote.
- 1 cabeçalho.
- 1 decisão.
- 1 interrupção.
A redução na carga da CPU é drástica. Você libera ciclos de processamento para que a aplicação (o banco de dados) realmente funcione.
A Armadilha: O MTU deve ser consistente de ponta a ponta (Host -> Switch -> Storage Array). Se um único switch no meio do caminho estiver com MTU 1500, você terá fragmentação (o que destrói a performance) ou, pior, "Black Hole Routing", onde a negociação TCP (3-way handshake) funciona porque os pacotes SYN são pequenos, mas o tráfego de dados real é descartado silenciosamente.
Diagnóstico de MTU Real:
Não confie no ifconfig. Teste o caminho.
# 8972 = 9000 - 20 (IP Header) - 8 (ICMP Header)
ping -M do -s 8972 <IP_DO_STORAGE>
Se receber "Message too long", seu caminho não está limpo.
O Mito do Auto-Tuning e o "Window Scaling"
O Linux moderno tem um excelente TCP Auto-Tuning. Ele ajusta dinamicamente o tamanho das janelas de recepção e envio. No entanto, o algoritmo padrão é conservador. Ele assume que a memória RAM é um recurso escasso que deve ser protegido.
Em um servidor de Storage/DB com 512GB de RAM, proteger 20MB de buffer de rede é ridículo.
O conceito aqui é o BDP (Bandwidth-Delay Product). Para encher um link de 25Gbps, quantos dados precisam estar "em voo" (enviados mas ainda não confirmados/ACKed)?
BDP = Largura de Banda (bytes/s) * Latência (segundos)
Se o seu buffer TCP máximo for menor que o BDP, seu throughput será limitado artificialmente, não importa a velocidade da placa de rede. O TCP vai parar de enviar e esperar o ACK, deixando o link ocioso por microssegundos preciosos.
Ajustando os Buffers (O "Martelo")
Você precisa aumentar os limites máximos para permitir que o TCP escale a janela o suficiente para redes de 25/40/100GbE.
# /etc/sysctl.conf
# Aumentar o buffer de recepção (rmem) e envio (wmem)
# Valores: min, default, max
# Max em ~16MB ou 32MB é comum para 10GbE. Para 100GbE, pense em 64MB+.
net.ipv4.tcp_rmem = 4096 87380 33554432
net.ipv4.tcp_wmem = 4096 65536 33554432
# Habilitar Window Scaling (Crucial - deve ser 1)
net.ipv4.tcp_window_scaling = 1
# O backlog da interface. Se o kernel receber pacotes mais rápido do que processa,
# ele os coloca aqui. Se encher, drop. Aumente isso.
net.core.netdev_max_backlog = 250000
Como saber se está funcionando?
Use o ss (Socket Statistics) em vez do netstat. Observe o parâmetro wscale e o rtt.
# -i mostra informações internas do TCP
ss -nmoti dst <IP_DO_STORAGE>
Procure por:
wscale:7: Indica que o window scaling está ativo (fator 2^7 = 128x).cwnd: Congestion Window. Se estiver baixo e não subir durante carga, seus buffers estão limitando.
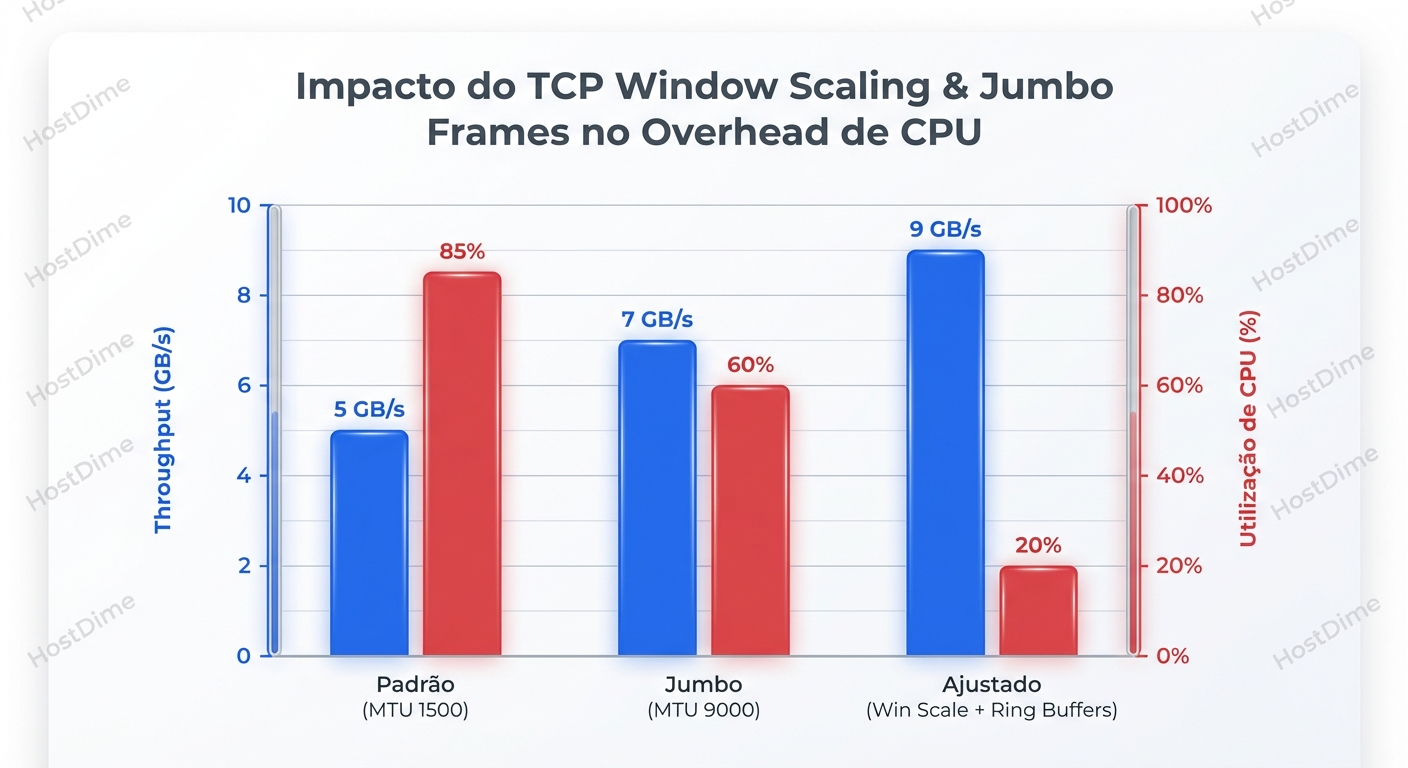
O gráfico acima deve ser seu modelo mental. Note como a categoria "Tuned" não apenas aumenta o throughput, mas derruba o uso de CPU. Isso é eficiência.
Offloading: O Bom, o Mau e o Perigoso (LRO vs GRO)
As placas de rede modernas são computadores por si só. Elas podem assumir tarefas que o kernel faria. Isso se chama Offloading.
Para Storage, a regra de ouro é: Cuidado com a Recepção.
- TSO (TCP Segmentation Offload) - Envio: Geralmente BOM. O kernel envia um bloco gigante (64KB) para a NIC, e a NIC fatia em pacotes MTU. Economiza CPU.
- GRO (Generic Receive Offload) - Recepção: Geralmente OK. O kernel agrupa pacotes recebidos logicamente antes de passar para a camada de socket.
- LRO (Large Receive Offload) - Recepção: Frequentemente PERIGOSO para iSCSI/Roteamento.
Por que o LRO é perigoso? O LRO é agressivo. Ele funde pacotes no hardware/driver e descarta cabeçalhos TCP/IP para apresentar um único "pacotão" ao sistema operacional. O problema: O iSCSI depende de limites de mensagem precisos. Implementações agressivas de LRO podem corromper o fluxo de dados ou confundir o CRC do iSCSI, levando a retransmissões massivas ou corrupção de dados silenciosa.
Recomendação de SRE: Desative LRO para interfaces iSCSI, use GRO.
# Verificar status
ethtool -k eth0 | grep large-receive
# Desativar LRO
ethtool -K eth0 lro off
Congestion Control: A Falácia da Justiça
O algoritmo de controle de congestionamento padrão do Linux geralmente é o CUBIC. O CUBIC é ótimo para a internet. Se ele detecta perda de pacote, ele assume que o roteador está congestionado e corta a janela de transmissão drasticamente (multiplicative decrease).
Em uma SAN (Storage Area Network) dedicada:
- Não deve haver tráfego concorrente (YouTube, Web, etc).
- A perda de pacotes deve ser zero.
- Se houver perda, geralmente é um cabo ruim ou buffer de switch estourado, não "congestionamento" clássico.
O comportamento do CUBIC de "cortar pela metade" a velocidade ao menor sinal de problema causa dentes de serra no gráfico de throughput.
Alternativa: DCTCP (Data Center TCP) Se seus switches suportam ECN (Explicit Congestion Notification), use DCTCP. Em vez de esperar o pacote cair, o switch marca o pacote com "estou ficando cheio". O DCTCP reduz a velocidade graciosamente, mantendo a latência baixa e o throughput estável.
Alternativa: BBR (Bottleneck Bandwidth and RTT) O BBR (do Google) não se baseia em perda de pacotes, mas sim em modelar a largura de banda e o RTT. Ele tenta empurrar dados até o limite real do cano, sem encher os buffers (bufferbloat). Para links de longa distância ou redes com leve perda, o BBR brilha. Para SAN local, ele é excelente em manter latência baixa.
| Algoritmo | Comportamento em Perda | Cenário Ideal | Veredito para Storage |
|---|---|---|---|
| Cubic | Redução Agressiva | Internet/WAN | Padrão aceitável, mas instável em carga máxima. |
| Reno | Arcaico | Legado | Nunca use. |
| DCTCP | Redução Graciosa (via ECN) | Data Center Moderno | O Melhor (se o switch suportar ECN). |
| BBR | Baseado em Modelo (ignora perda leve) | Redes mistas/rápidas | Excelente alternativa ao DCTCP. |
Para mudar (exemplo para BBR):
sysctl -w net.core.default_qdisc=fq
sysctl -w net.ipv4.tcp_congestion_control=bbr
NVMe-TCP: O Novo Paradigma (Polling vs Interrupts)
Aqui a coisa muda de figura. O NVMe-TCP foi desenhado para ser mais eficiente que o iSCSI. Ele tira proveito de filas múltiplas (multi-queue) de forma muito mais nativa.
O grande segredo do tuning para NVMe-TCP não é apenas buffer, é o Polling.
No modelo tradicional (interrupção), a CPU dorme até a NIC avisar "chegou dado". O tempo de "acordar" (wake-up latency) é de alguns microssegundos. Em discos NVMe que respondem em 80us, perder 5us acordando a CPU é um desperdício de 6%.
Com o io_uring e drivers modernos, podemos configurar o sistema para Polling. A CPU fica girando num loop ativo perguntando "chegou? chegou? chegou?".
- Custo: Uso de CPU sobe para 100% em um núcleo.
- Ganho: Latência cai drasticamente e IOPS sobe.
Para ativar isso no lado do host (Initiator), muitas vezes é um parâmetro de módulo ou configuração na conexão nvme connect.
Exemplo de conceito (varia por driver/distro): Ao conectar, você pode especificar filas dedicadas para polling. Isso garante que o driver NVMe não espere por interrupções do TCP stack tradicional para o caminho de dados críticos.
Diagnóstico de Batalha: O que procurar
Quando a performance estiver ruim, não adivinhe. Olhe os contadores de erro.
1. Pacotes Descartados na NIC (Ring Buffer Overflow) O kernel não conseguiu tirar os pacotes da placa rápido o suficiente.
ethtool -S eth0 | grep -E 'drop|miss|error'
Se rx_missed_errors estiver subindo: Aumente o Ring Buffer (ethtool -G eth0 rx 4096) ou verifique se a CPU está colada em 100% (softirq).
2. Retransmissões TCP O assassino do IOPS. Uma retransmissão significa que o dado teve que esperar um timeout (RTO) e ser enviado de novo. A latência desse I/O específico vai para o teto.
netstat -s | grep -i retrans
# Ou monitoramento em tempo real
sar -n ETCP 1
Causa: Cabo ruim, porta de switch com CRC errors, ou buffer do switch estourando (microbursts).
3. Colapso de Janela (Zero Window)
O storage array diz "Pare! Não tenho buffer".
Use o tcpdump e analise no Wireshark. Procure por "TCP ZeroWindow" ou "Window Update".
Isso indica que o Storage é o gargalo (CPU ou Disco), não a rede. O tuning do host não resolverá isso.
Check-list de Otimização (O "Cheat Sheet")
Se você vai configurar um host para iSCSI/NVMe-TCP pesado hoje, aqui está seu ponto de partida seguro:
- BIOS: Desative C-States (economia de energia). Você quer a CPU acordada.
- MTU: 9000 em tudo (NIC, Switch, Storage).
- Ring Buffers: Maximize via
ethtool -G. - Sysctl:
net.ipv4.tcp_window_scaling = 1net.ipv4.tcp_timestamps = 1(Útil para medição precisa de RTT e proteção, baixo overhead hoje em dia).net.ipv4.tcp_sack = 1(Selective ACK - essencial para recuperação rápida de perda).net.core.rmem_max/wmem_maxajustados para BDP.
- Offload: LRO OFF, TSO ON, GRO ON.
- Algoritmo: BBR ou DCTCP (se tiver switches enterprise configurados).
Quando o TCP não é suficiente
Há um limite físico. O TCP sempre terá o overhead da cópia de memória (Kernel space -> User space) e do processamento de cabeçalhos. Se você tunou tudo, seu link é 100GbE, e sua CPU ainda é o gargalo, o TCP chegou ao fim da linha.
A resposta então não é mais tuning, é trocar de protocolo. É aqui que entra o RDMA (RoCEv2 ou iWARP). O RDMA permite que a placa de rede coloque dados diretamente na memória da aplicação, ignorando a CPU e o Kernel completamente (Zero Copy, Kernel Bypass).
Mas o RDMA é complexo, chato de configurar e exige switches com "Lossless Ethernet" (PFC/ETS). Para 95% dos casos, um TCP bem tunado (especialmente NVMe-TCP) entrega latência indistinguível de Fibre Channel, rodando em infraestrutura Ethernet padrão.
O segredo não é magia negra; é alinhar a expectativa do protocolo (que quer ser gentil) com a realidade do storage (que precisa ser brutal). Ajuste seus buffers, aumente seus quadros e monitore suas retransmissões. Seu banco de dados agradecerá.

Elena Kovacs
Arquiteta de Cloud Infrastructure
Focada em NVMe-oF e storage definido por software. Projeta clusters de petabytes para grandes provedores de nuvem.