Testes de Stress em RAID: Como Simular Falhas e Validar Redundância Real

Não espere a produção cair. Aprenda a executar testes de stress em RAID, simular falhas de disco sob carga (fio/mdadm) e medir o impacto real na latência durante o rebuild.
A maioria dos administradores valida um array RAID da maneira errada: eles montam o servidor, deixam-no ocioso, puxam um disco físico e observam se o LED pisca. Se o sistema operacional continua de pé, eles declaram "sucesso" e vão para casa.
Isso não é um teste; é teatro.
No mundo real, discos raramente falham quando o sistema está dormindo. Eles falham sob carga máxima, durante um backup noturno ou no pico de acessos do banco de dados. Um teste de redundância sem carga de I/O (Input/Output) concomitante ignora completamente o impacto devastador da latência durante a reconstrução.
Este artigo trata da metodologia científica para validar se o seu storage aguenta o pior dia da vida dele, não o melhor.
O que é um Teste de Stress em RAID?
Testes de Stress em RAID são simulações controladas onde falhas de hardware (injeção de erros ou remoção de discos) são provocadas enquanto o subsistema de armazenamento está sob carga de trabalho intensa (saturação de IOPS e Throughput). O objetivo não é apenas verificar a integridade dos dados, mas medir a degradação de performance (latência) e o tempo real de reconstrução (rebuild/resilver) para garantir que a aplicação continue operável durante o desastre.
A Falácia da Redundância "Segura" e o Custo do Rebuild
A redundância (seja RAID via hardware, mdadm ou ZFS) promete disponibilidade, mas não promete performance constante. Quando um disco falha, o array entra em "modo degradado". Se você utiliza paridade (RAID 5, 6, RAIDZ), a CPU e os discos restantes precisam calcular os dados faltantes em tempo real para cada leitura.
Quando a reconstrução (rebuild ou resilver) começa, o problema se agrava. O sistema tenta ler todo o conteúdo dos discos sobreviventes para escrever no novo disco.
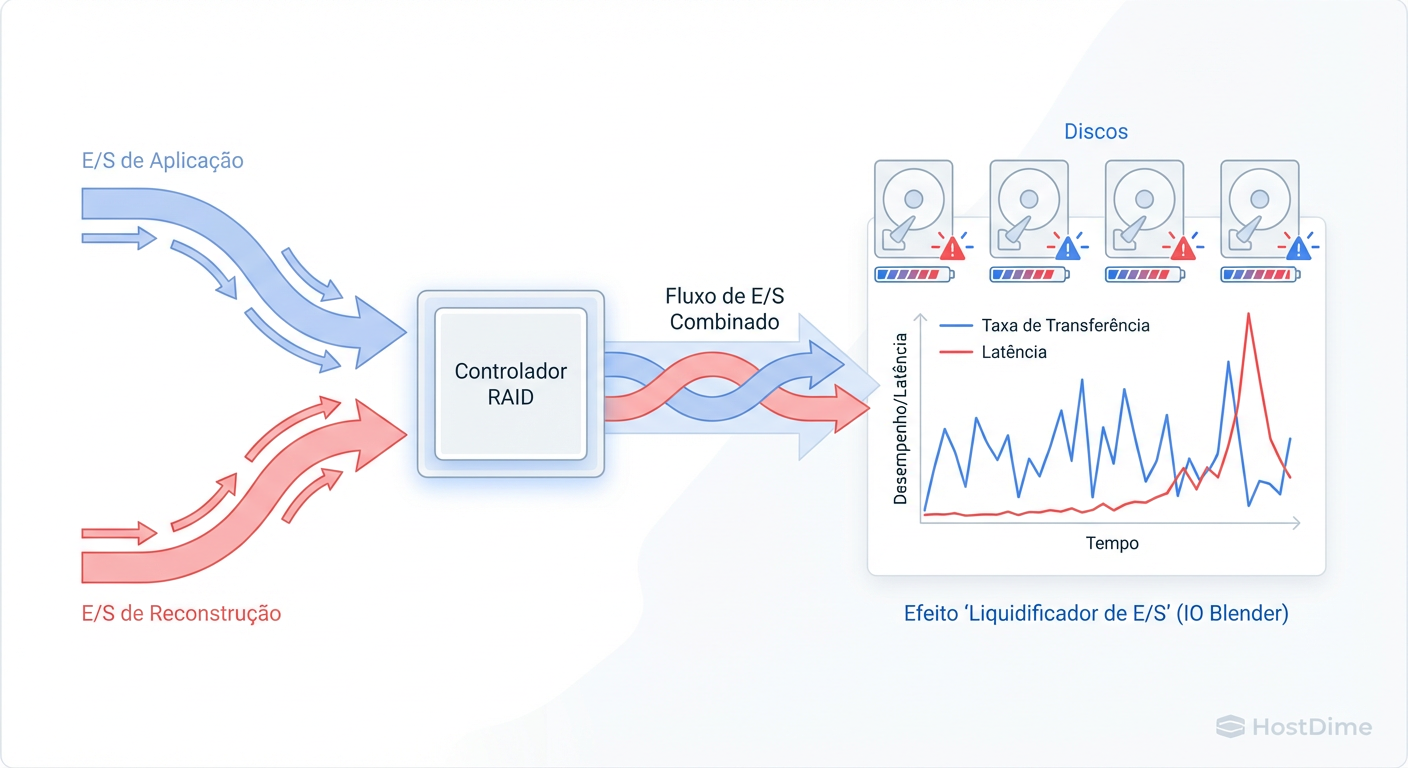 Figura: O Efeito Liquidificador: Como o IO de Reconstrução compete com a Aplicação, gerando latência.
Figura: O Efeito Liquidificador: Como o IO de Reconstrução compete com a Aplicação, gerando latência.
Se o seu storage já opera a 70% da capacidade de IOPS em produção, a carga adicional do rebuild vai saturar o barramento. O resultado não é perda de dados, é latência infinita. Para a aplicação na ponta (um ERP ou um site), uma resposta que demora 30 segundos é indistinguível de um servidor travado.
O Arsenal de Teste: Configurando FIO para Carga e Falhas Controladas
Para um teste científico, precisamos de reprodutibilidade. Não confie em cópias de arquivos manuais. Usaremos o FIO (Flexible I/O Tester) para gerar uma carga consistente e mensurável.
1. Definindo a Carga de Trabalho (Workload)
Antes de quebrar o array, você precisa simular a vida real. Um banco de dados transacional, por exemplo, faz muita leitura e escrita aleatória (Random R/W) em blocos pequenos (4k ou 8k).
Crie um arquivo de trabalho stress-raid.fio:
[global]
ioengine=libaio # Engine assíncrona padrão para Linux
direct=1 # Ignora o cache de RAM (teste de disco real)
bs=4k # Tamanho do bloco (simula DB)
rw=randrw # Leitura e escrita aleatória
rwmixread=70 # 70% leitura, 30% escrita
iodepth=32 # Fila de comandos para saturar o disco
time_based=1
runtime=3600 # Executa por 1 hora
group_reporting=1
[job1]
filename=/mnt/meu_raid/arquivo_teste.dat
size=50G # Tamanho do arquivo de teste
numjobs=4 # Número de threads concorrentes
2. A Ferramenta de Caos
Não puxe o disco físico imediatamente. O Linux pode reagir de forma imprevisível a remoções a quente se o controlador não for perfeito. Para validar a lógica do RAID primeiro, use comandos de falha de software.
Para mdadm:
mdadm --manage /dev/md0 --fail /dev/sdXPara ZFS:
zpool offline -t poolname diskname(O flag-tsimula uma falha temporária, ideal para testes).
Executando o Teste de Stress sob Saturação de IOPS
A metodologia correta segue três fases distintas. Pular qualquer uma invalida os dados coletados.
Fase 1: Precondicionamento e Baseline
Execute o FIO com o array saudável. Anote três números vitais:
IOPS Médio: Quantas operações por segundo o array entrega?
Latência p99: Qual o tempo máximo de resposta para 99% das requisições?
Throughput: Quantos MB/s sustentados?
Se sua latência p99 já estiver alta (acima de 20ms para SSDs ou 100ms para HDDs) sem falhas, seu projeto de storage já falhou antes mesmo de começar.
Fase 2: Injeção de Falha sob Carga
Com o FIO rodando em um terminal (gerando carga), provoque a falha em outro terminal.
# Exemplo em ZFS: Simulando morte do disco sdb
zpool offline tank /dev/sdb
O que observar imediatamente: Monitore a saída do FIO. Você verá uma queda abrupta nos IOPS e um pico na latência. Se a latência saltar de 5ms para 500ms, sua aplicação provavelmente sofrerá timeouts.
Fase 3: O Rebuild Competitivo
Adicione um disco de reposição (ou traga o antigo de volta) para iniciar a reconstrução enquanto o FIO continua rodando.
# Exemplo ZFS: Trazendo o disco de volta e iniciando resilver
zpool online tank /dev/sdb
Aqui reside a verdade sobre seu storage. O controlador precisa decidir o que é prioridade: atender o FIO (sua "aplicação") ou reconstruir a redundância.
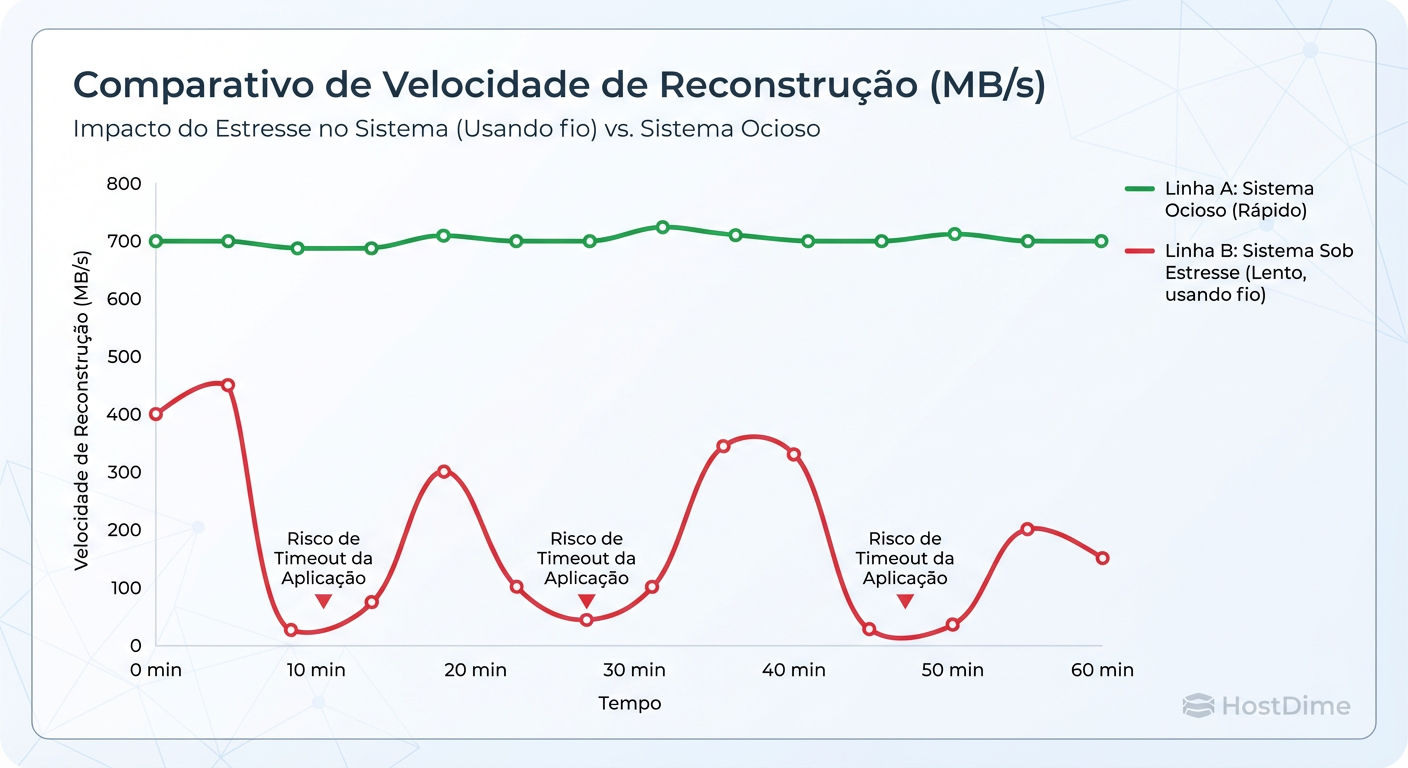 Figura: Comparativo de Tempo de Rebuild: Sistema Ocioso vs. Sistema sob Stress (Simulação FIO).
Figura: Comparativo de Tempo de Rebuild: Sistema Ocioso vs. Sistema sob Stress (Simulação FIO).
Aviso de Performance: Muitos controladores RAID de hardware priorizam o rebuild agressivamente, tornando o volume inutilizável até o fim do processo. No Linux (mdadm/ZFS), você pode ajustar essa prioridade (
/proc/sys/dev/raid/speed_limit_minouzfs_resilver_delay), mas isso prolonga o tempo em que você está vulnerável a uma segunda falha.
Métricas de Sobrevivência: O Que Monitorar
Durante o teste, esqueça o "load average" da CPU. Foque no que importa para o armazenamento.
Tabela Comparativa de Impacto no Rebuild
| Tecnologia / Nível | Impacto na CPU | Impacto na Latência de Leitura | Risco durante Rebuild |
|---|---|---|---|
| RAID 1 / 10 | Baixo | Baixo. Apenas cópia de blocos. | Baixo. Cópia rápida. |
| RAID 5 / RAIDZ1 | Médio | Alto. Cálculo de XOR necessário para cada bloco lido se houver degradação. | Médio. Leitura intensiva nos discos restantes. |
| RAID 6 / RAIDZ2 | Alto | Muito Alto. Duplo cálculo de paridade. | Baixo risco de perda de dados, mas risco alto de timeout da aplicação. |
| ZFS dRAID | Médio | Médio. Rebuild distribuído usa largura de banda de todos os discos. | Mínimo. Tempo de rebuild drasticamente reduzido. |
A Métrica Oculta: URE (Unrecoverable Read Error)
A métrica mais assustadora não é a velocidade, é a integridade. Discos SATA domésticos tipicamente têm uma taxa de erro de leitura não recuperável de 1 bit a cada $10^{14}$ bits lidos (aprox. 12TB).
Ao reconstruir um RAID 5 de 40TB, a probabilidade matemática de encontrar um erro de leitura em um dos discos "saudáveis" é estatisticamente alta. Se isso acontecer durante o rebuild:
RAID Hardware antigo: O rebuild falha e o array é desmontado. Perda total.
ZFS: Ele marca aquele arquivo como corrompido, mas continua o rebuild do resto.
Simulando o Pior Cenário: Checklist de Validação
Seu storage só está pronto para produção se passar por este checklist agressivo.
Teste de Saturação: O FIO rodou por 2 horas sem erros de I/O no log do kernel (
dmesg)?Teste de Latência Degradada: Durante a falha de um disco, a latência p99 permaneceu abaixo do timeout da sua aplicação (ex: 30s para web, 5s para DB)?
Teste de Rebuild sob Carga: O tempo de reconstrução estimado (ETA) é aceitável?
- Cálculo: Se o rebuild demora 24h sob carga, você aceita correr o risco de uma segunda falha durante um dia inteiro?
Scrubbing de Validação: Após o rebuild terminar e o teste de stress parar, execute uma verificação de integridade completa (
zpool scrubouecho check > /sys/block/md0/md/sync_action). Todos os checksums bateram?
Veredito Técnico Pragmática
Não confie nas especificações da caixa do controlador RAID. A única verdade está nos logs gerados sob stress. Se você não testar a falha, o universo testará por você em uma sexta-feira à noite — e o universo não se importa com seus SLAs.
Referências & Leitura Complementar
RFC 3552 - Guidelines for Writing RFC Text on Security Considerations (Aplicável a integridade de dados).
Gregg, Brendan. Systems Performance: Enterprise and the Cloud. (Capítulo sobre Disk I/O).
Manpages:
man fio,man mdadm,man zpool-offline.BAARF (Battle Against Any Raid Five) - Artigos históricos sobre os perigos matemáticos do RAID 5 em discos modernos de alta capacidade.

Marta G. Oliveira
DevOps Engineer & Storage Nerd
Automatiza provisionamento de storage com Terraform e Ansible. Defensora do 'Infrastructure as Code' para storage.