Thin Provisioning no Ceph RBD: Arquitetura, Riscos de Overcommit e TRIM

Entenda como o Thin Provisioning funciona no Ceph RBD, os perigos reais do overcommitment em ambientes multi-tenant e como gerenciar o TRIM sem derrubar a performance.
O Thin Provisioning é a mentira mais útil e perigosa no mundo do armazenamento corporativo. Como arquitetos, nós o vendemos como "eficiência de custos" e "otimização de recursos", mas, na prática, estamos operando um sistema de reserva fracionária bancária com dados. Prometemos 100 TB de armazenamento para as VMs quando, fisicamente, só compramos 50 TB de discos NVMe ou HDDs.
Enquanto a demanda não exceder a oferta física, somos gênios da economia (CapEx). No momento em que a "corrida aos bancos" acontece — quando todas as VMs decidem gravar dados simultaneamente — o cluster Ceph não apenas fica lento; ele para.
A seguir, vamos desmontar a mecânica do Thin Provisioning no Ceph RBD (RADOS Block Device), analisar onde a arquitetura quebra e como configurar o TRIM para não derrubar sua produção.
O que é Thin Provisioning no Ceph RBD?
Thin Provisioning no Ceph RBD é uma técnica de alocação de armazenamento onde a capacidade física (raw storage) no cluster RADOS é consumida apenas quando dados são efetivamente gravados, e não quando o volume é criado. Diferente do "Thick Provisioning", onde o espaço é reservado antecipadamente, o Ceph utiliza objetos esparsos (sparse objects): se um bloco de dados contém apenas zeros ou nunca foi escrito, ele não ocupa espaço nos OSDs, permitindo o overcommitment (vender mais espaço lógico do que a capacidade física disponível).
A Economia do Thin Provisioning no Ceph e o Preço da Eficiência
A decisão de usar Thin Provisioning raramente é técnica; é financeira. O custo do armazenamento cai com o tempo (Lei de Moore aplicada a densidade de área). Comprar 1 PB de discos hoje para usar apenas 200 TB no primeiro ano é jogar dinheiro fora. O Thin Provisioning permite adiar o CapEx, comprando discos "just-in-time".
No entanto, essa eficiência cobra um imposto operacional (OpEx). Você troca dinheiro por risco e ciclos de CPU.
No Ceph, o custo não é apenas o risco de encher o disco. É o custo de metadados. Um volume de 10 TB thick (preenchido) e um volume de 10 TB thin (com 1 TB de dados reais) comportam-se de forma muito diferente no backend. O sistema precisa rastrear quais objetos existem e quais são "buracos".
Arquitetura de Objetos Esparsos e Mapeamento RBD no RADOS
Para entender o risco, precisamos descer ao nível do objeto. O Ceph não sabe o que é um "disco virtual" ou um "sistema de arquivos ext4". Ele conhece objetos.
Quando você cria uma imagem RBD de 100 GB (rbd create vm-disk --size 100G), o Ceph divide essa imagem em objetos menores, geralmente de 4 MB (o padrão order 22).
Visão Lógica (VM): Um dispositivo de bloco contínuo de 0 a 100 GB.
Visão Física (Ceph): Uma coleção potencial de 25.600 objetos de 4 MB.
No momento da criação, zero objetos são criados. O Ceph apenas atualiza o cabeçalho da imagem dizendo "Eu existo e tenho tamanho lógico de 100 GB".
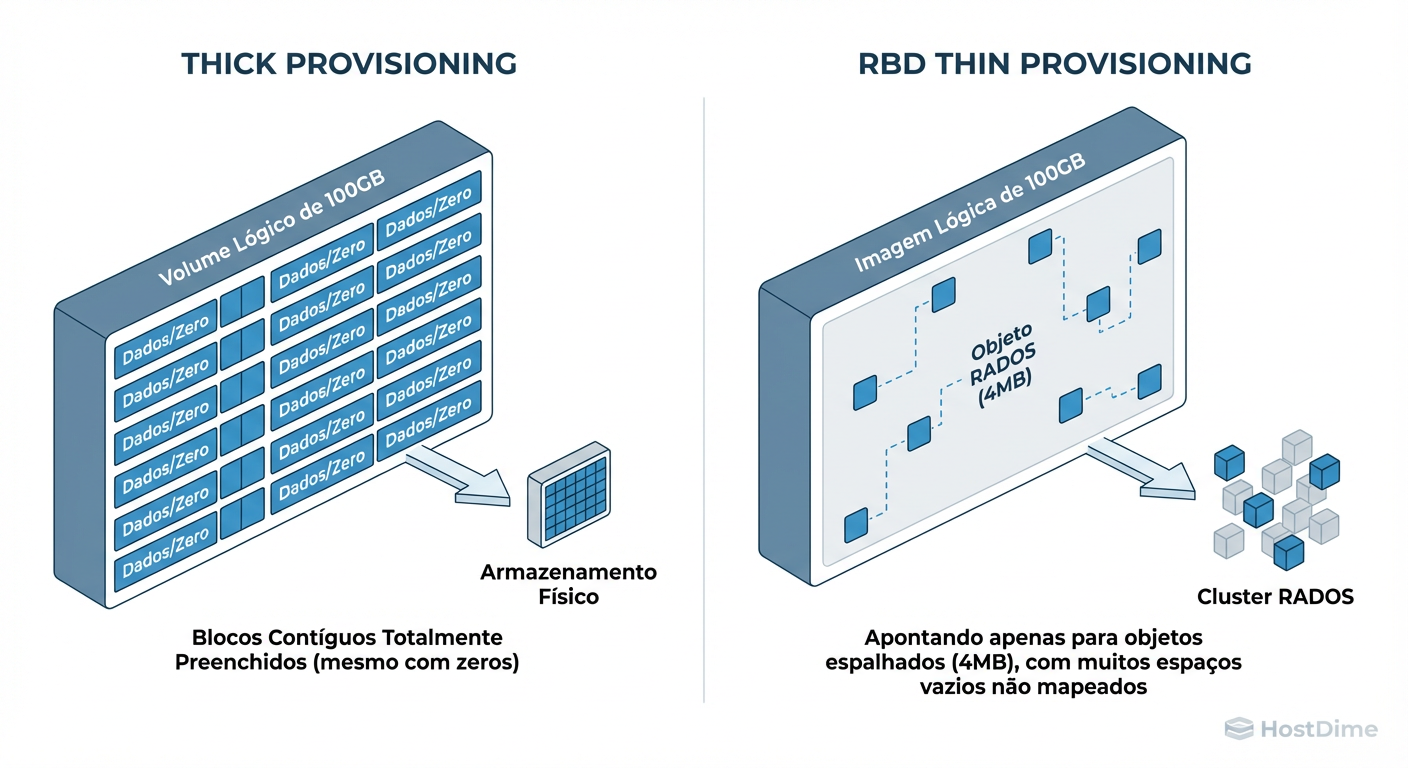 Figura: Mapeamento Lógico vs. Físico: No RBD, blocos vazios não existem no RADOS até serem escritos.
Figura: Mapeamento Lógico vs. Físico: No RBD, blocos vazios não existem no RADOS até serem escritos.
Conforme a VM grava dados, o cliente librbd calcula qual objeto de 4 MB corresponde àquele setor do disco e envia a escrita para o cluster RADOS. Se o objeto não existe, ele é instanciado. Se o objeto existe, ele é atualizado.
Se a VM grava 4 KB no meio de um bloco de 4 MB que ainda não existe, o Ceph cria o objeto inteiro (consumindo recursos de alocação), mas ele é "esparso". O problema surge quando temos milhões de pequenos objetos fragmentados.
Impacto na Latência de Escrita e Fragmentação no BlueStore
O Thin Provisioning não é gratuito em termos de IOPS e latência. Existe uma penalidade inerente, especialmente na primeira escrita.
1. Penalidade de Alocação
Quando uma VM escreve em um bloco novo, o backend de armazenamento (BlueStore) precisa:
Encontrar espaço livre no disco físico (usando o alocador, geralmente Bitmap ou Avl).
Atualizar os metadados no RocksDB para registrar a nova localização do objeto.
Gravar os dados.
Em um volume pre-allocated (thick), a alocação já ocorreu. No thin, cada nova escrita é uma transação de metadados + dados.
2. Fragmentação do Backend
O BlueStore melhorou muito a performance em relação ao antigo FileStore, mas ele ainda sofre com fragmentação em cenários de heavy thin provisioning. Se você enche e esvazia o cluster repetidamente, o espaço livre físico no disco se torna um "queijo suíço". O alocador precisa trabalhar mais para encontrar sequências contínuas de bytes para novos objetos, aumentando a latência de cauda (tail latency).
Riscos de Overcommitment e o Colapso por Falta de Espaço Físico
Aqui reside o pesadelo do arquiteto. O Overcommitment (sobrecompromisso) é a prática de provisionar, digamos, 200 TB de volumes lógicos em um cluster com 100 TB de capacidade física utilizável.
Funciona bem até o dia em que não funciona mais. Diferente de um storage tradicional que pode degradar a performance, o Ceph possui mecanismos de autoproteção draconianos.
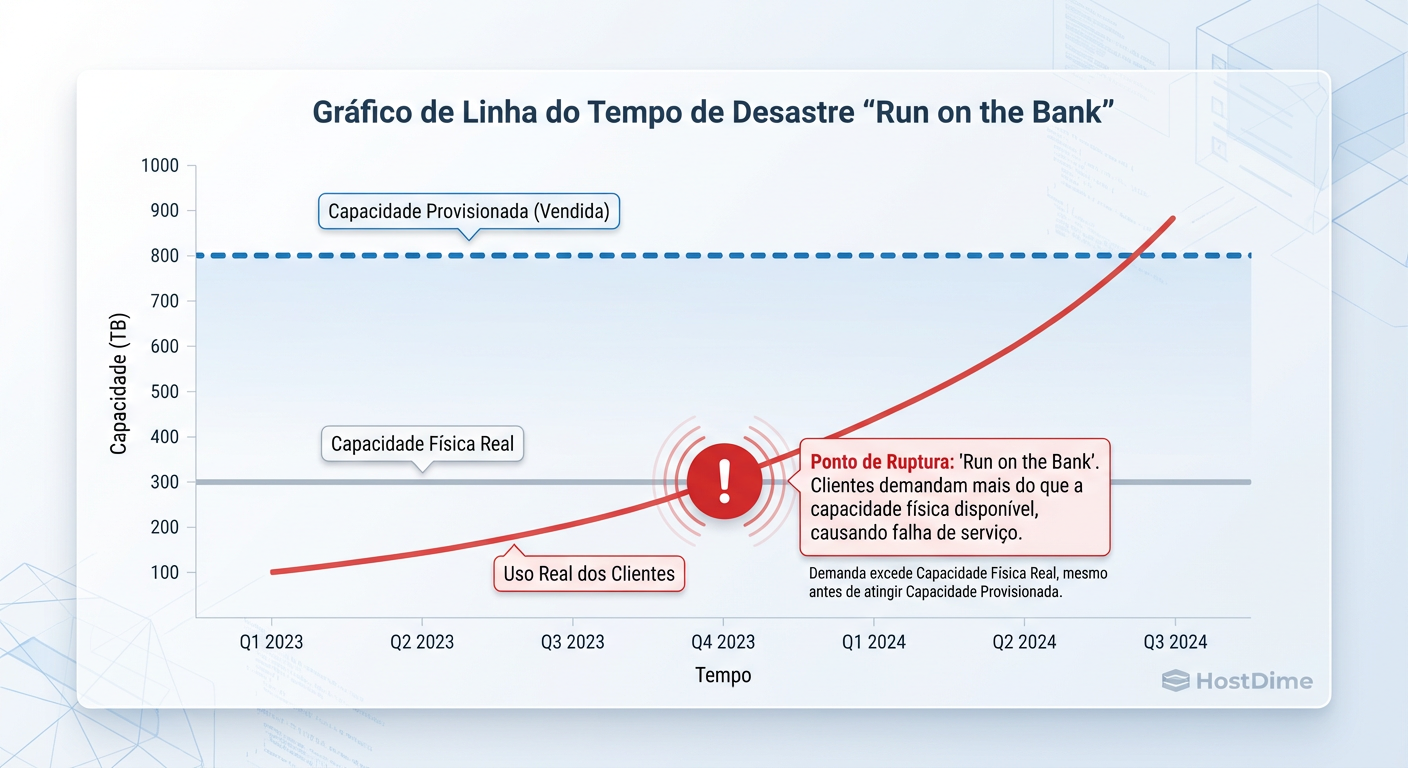 Figura: A Armadilha do Overcommitment: O cluster para de funcionar quando a linha vermelha cruza a capacidade física, muito antes de atingir o limite lógico vendido.
Figura: A Armadilha do Overcommitment: O cluster para de funcionar quando a linha vermelha cruza a capacidade física, muito antes de atingir o limite lógico vendido.
O Mecanismo de "Full Ratio"
O Ceph monitora o uso de cada OSD. Existem bandeiras críticas que você deve respeitar:
mon_osd_nearfull_ratio (padrão ~85%): O cluster entra em alerta (HEALTH_WARN). É o seu último aviso para adicionar discos ou deletar dados.
mon_osd_full_ratio (padrão ~95%): O cluster bloqueia todas as escritas. As VMs congelam. O banco de dados para.
O perigo real é que a distribuição de dados no CRUSH map é pseudo-aleatória, mas não perfeitamente uniforme. É possível que um OSD atinja 95% enquanto outros estão em 80%. Se um único OSD atinge o full_ratio, o cluster pode parar IO para proteger a integridade dos dados (evitando corrupção por falta de espaço para journals/WAL).
A Regra de Ouro: Nunca dimensione um cluster Thin Provisioned baseando-se na capacidade total. Dimensione baseando-se na capacidade de recuperação. Se um nó falhar e o Ceph precisar rebalancear (backfill) os dados para os nós restantes, haverá espaço físico para absorver esses dados? Se a resposta for "não", seu cluster é uma bomba relógio.
O Dilema do TRIM e Discard: Recuperação de Espaço vs. Performance
Em um ambiente Thin, quando você deleta um arquivo de 10 GB dentro da VM Linux (rm -rf arquivo.big), o sistema de arquivos da VM marca aqueles blocos como livres. Porém, o Ceph não sabe disso. Para o Ceph, aqueles objetos de 4 MB ainda contêm dados válidos e ocupam espaço físico.
Para recuperar esse espaço, precisamos do comando TRIM/Discard, que diz ao storage: "estes blocos não são mais necessários, pode liberar o espaço físico".
Existem duas abordagens principais para implementar isso, e a escolha errada pode destruir a performance da sua aplicação.
Tabela Comparativa: Estratégias de Discard
| Característica | Continuous Discard (mount -o discard) |
Periodic TRIM (fstrim via cron/systemd) |
|---|---|---|
| Mecanismo | Envia comando TRIM imediatamente após cada deleção de arquivo. | Executa uma varredura em lote (batch) em horários agendados. |
| Impacto no Host | Alto overhead de CPU/IO em tempo real. Cada rm vira uma transação no Ceph. |
Baixo impacto durante o dia, pico de IO durante a execução. |
| Interferência | Pode causar latência em outras operações de escrita concorrentes. | Pode ser agendado para janelas de manutenção ou baixa demanda. |
| Consistência | Espaço é liberado instantaneamente. | Espaço físico fica "sujo" até a próxima execução. |
| Recomendação | Evitar na maioria dos casos com Ceph RBD. | Recomendado (Diário ou Semanal). |
Por que evitar o mount -o discard?
O protocolo SCSI UNMAP (ou TRIM no ATA) é caro. No Ceph, liberar um intervalo dentro de um objeto requer manipulação de metadados e, em alguns casos, reescrita parcial. Se você tem uma VM com alto churn de arquivos temporários, usar discard contínuo pode reduzir o desempenho de escrita da VM em 30% a 50%.
A abordagem correta: Habilite o discard na camada do dispositivo de bloco (na definição XML do Libvirt/KVM, use discard='unmap') para que a VM possa emitir o comando. Dentro da VM, habilite e configure o fstrim.timer (systemd) para rodar fora do horário de pico.
Estratégias de Monitoramento: Diferenciando Capacidade Lógica de Uso Real
Gerenciar Thin Provisioning exige visibilidade. Você precisa saber a diferença entre o que você prometeu e o que você tem.
O comando rbd ls mostra o tamanho provisionado (a mentira).
O comando rbd du mostra o uso real (a verdade), mas cuidado: rbd du é uma operação pesada. Ele precisa iterar sobre os metadados de cada objeto da imagem. Não rode isso em loop a cada 5 minutos em um cluster com milhares de imagens.
Como medir corretamente
Para monitoramento operacional rápido (Grafana/Prometheus), confie nas métricas do pool e do OSD, não na imagem individual.
ceph df detail
# Verificação detalhada por IMAGEM (Lento, use esporadicamente)
# Mostra Provisioned vs Used
rbd du pool_name/image_name
Se o WRITTEN (usado) estiver se aproximando do PROVISIONED (tamanho total) em todas as imagens, seu benefício de Thin Provisioning acabou e você está operando como Thick, mas com a penalidade de fragmentação.
Callout: O Perigo dos Snapshots
Atenção: Snapshots em Ceph RBD são "Copy-on-Write". Eles congelam os objetos antigos. Se você tem uma imagem de 100 GB, usa 50 GB, tira um snapshot e depois sobrescreve os 50 GB, você agora ocupa 100 GB físicos (50 GB ativos + 50 GB no snapshot). O monitoramento de espaço deve incluir agressivamente a idade e o tamanho dos snapshots. Snapshots esquecidos são a causa #1 de clusters cheios inesperadamente.
Veredito Técnico
O Thin Provisioning no Ceph RBD é uma ferramenta poderosa para maximizar o ROI do armazenamento, mas transforma a gestão de capacidade de uma tarefa passiva para uma ativa. Não existe "configure e esqueça".
Para operar com segurança:
Monitore a capacidade física dos pools, não a lógica.
Use Periodic TRIM (
fstrim) em vez de discard contínuo.Mantenha o cluster abaixo de 75% de ocupação física para garantir performance e capacidade de rebalanceamento.
Entenda que o overcommitment é um empréstimo. Se você não planejar como pagá-lo (comprando mais discos antes do
full_ratio), o Ceph executará a dívida parando sua operação.
Referências & Leitura Complementar
Ceph Documentation: Block Device (RBD) Operations - Sparse Allocation. Detalhes sobre o tamanho de objetos e striping.
Virtio Specification: Virtio-SCSI and Discard/UNMAP Support. Como o hipervisor passa comandos de trim para o storage.
RocksDB Tuning Guide for Ceph: BlueStore Metadata Performance. Entendendo o impacto de alocações pequenas no banco de dados KV do OSD.
SAGE Weil et al. (2006): Ceph: A Scalable, High-Performance Distributed File System. O paper original que define a arquitetura CRUSH e a distribuição de objetos.

Daniel Siqueira
DevOps Engineer & Storage Nerd
Automatiza provisionamento de storage com Terraform e Ansible. Defensor do 'Infrastructure as Code' para storage.