Timeout E Retries Parametros Criticos Em San

Você recebe o alerta às 03:00 da manhã. O banco de dados principal parou de responder. O dashboard de monitoramento está vermelho, mas estranhamente, o servidor...
Timeout E Retries Parametros Criticos Em San
Você recebe o alerta às 03:00 da manhã. O banco de dados principal parou de responder. O dashboard de monitoramento está vermelho, mas estranhamente, o servidor não crashou. Ele está pingando. O load average está subindo para 50, 60, 100. Você loga na máquina e roda um top. A CPU está ociosa, mas o Wait I/O (wa) está colado no teto. Seus processos do banco de dados estão em estado D (Uninterruptible Sleep). Você tenta dar um kill -9 em um processo filho e... nada acontece. O processo é um zumbi imortal.
Cinco minutos depois, o sistema "descongela", uma enxurrada de logs de erro de I/O aparece no dmesg, e o cluster manager decide rebootar o nó porque ele estourou o timeout de heartbeat.
O que aconteceu aqui? O storage não caiu completamente. Um switch de fibra óptica oscilou ou uma porta HBA falhou. O sistema tem redundância (Multipath), tem dois switches, quatro caminhos. Deveria ter sido transparente. Mas não foi. O sistema congelou por tempo suficiente para causar uma interrupção de serviço completa.
O culpado quase sempre reside nos valores padrão (defaults) da stack SCSI e do driver de Multipath. Eles são configurados para serem "educados" e "pacientes" em uma era onde cabos soltos eram comuns. Hoje, em ambientes de alta performance, essa paciência é o que mata sua disponibilidade. Vamos dissecar a anatomia desse congelamento.
O A Lógica por Trás: O Entregador Teimoso
Para entender por que o failover demora, precisamos mudar como visualizamos o I/O. Não pense em um fluxo contínuo de água. Pense em uma empresa de logística.
Imagine que o Kernel do Linux é o gerente da loja e o HBA (Host Bus Adapter) é o entregador. O Kernel entrega um pacote (um bloco de dados para escrita) ao entregador e diz: "Leve isso ao Armazém A (o LUN no Storage)".
O entregador sai de moto. Ele chega na ponte (o switch SAN) e vê que ela caiu. No modelo ideal de SRE, o entregador olharia, veria a ponte quebrada, e imediatamente ligaria para o gerente: "Chefe, ponte quebrada. Vou pela rota B (o outro caminho do Multipath)". Tempo total: milissegundos.
Mas a stack SCSI padrão não age assim. O entregador padrão é teimoso e burocrático.
- Ele chega na ponte quebrada. Ele não liga para o gerente. Ele espera. (Isso é o
transport_tmoou timeout de transporte da HBA). - Depois de esperar 30 ou 60 segundos, ele volta para a loja e diz "Não consegui".
- O gerente (a camada SCSI, não o Multipath ainda) diz: "Você deve ter se enganado. Tente de novo". (Isso são os
retries). - O entregador volta para a ponte quebrada. Espera mais 60 segundos. Volta.
- Isso se repete 5 vezes (default em muitas distros).
Só depois de minutos tentando passar pela mesma ponte quebrada é que o gerente SCSI admite a derrota e passa o erro para o supervisor de logística (o driver Multipath). Só agora o Multipath diz: "Ah, a rota A está ruim? Usem a rota B".
Durante todo esse tempo, a aplicação (o cliente que comprou o produto) está esperando no balcão, congelada. O banco de dados não pode comitar a transação porque o Kernel prometeu que a escrita seria feita e colocou o processo em espera (D state) aguardando a confirmação do entregador.
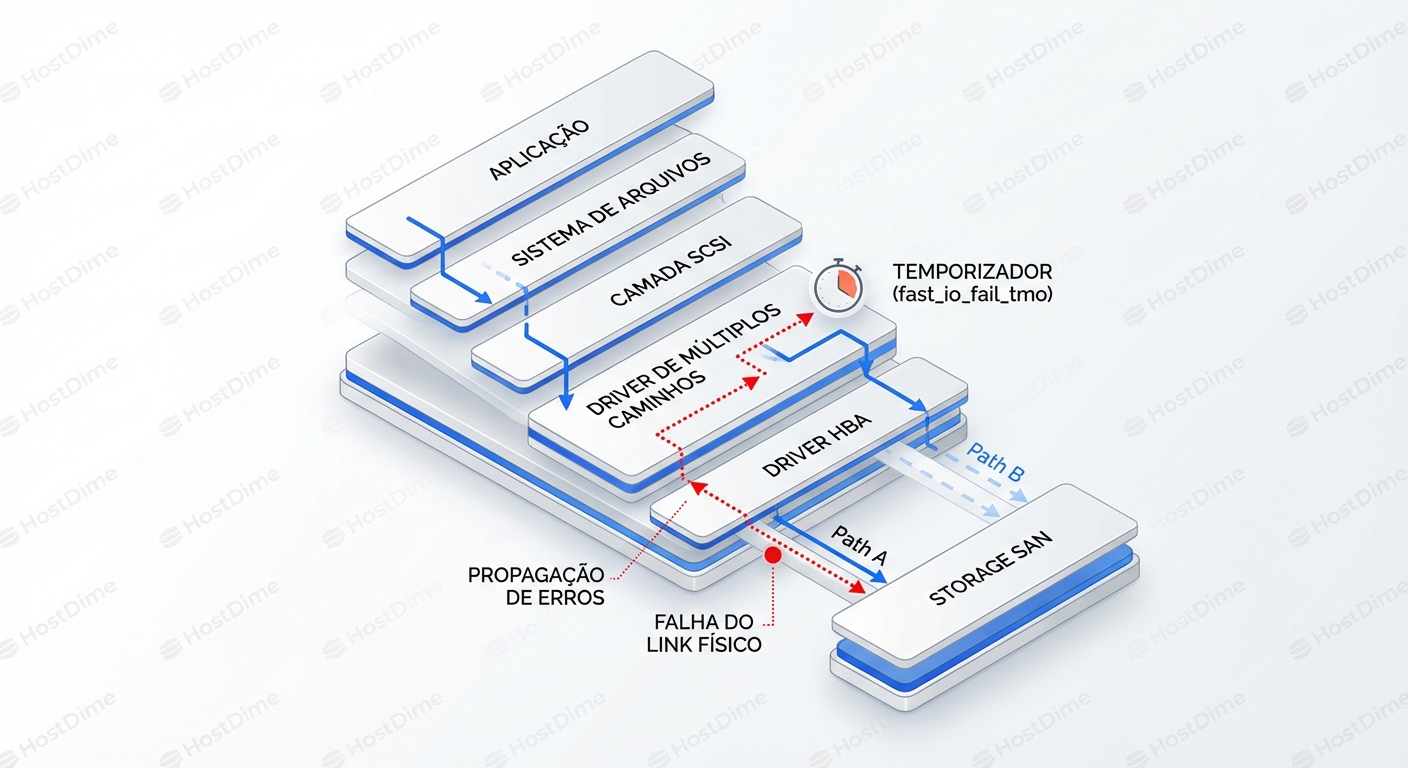
Esse diagrama acima ilustra o "Gap da Morte". O tempo entre a falha física (cabo cortado) e a decisão lógica (troca de caminho) é onde sua aplicação morre. Nosso trabalho é reduzir esse gap de minutos para milissegundos.
A Matemática do Desastre: Calculando o Tempo de Congelamento
A maioria dos administradores subestima o impacto multiplicativo dos timeouts. Vamos olhar para a stack Linux padrão (RHEL/CentOS/Debian sem tuning).
A fórmula básica para o tempo que o sistema leva para declarar um caminho como "morto" (e parar de enviar I/O para ele) é, grosseiramente:
$$ \text{Tempo de Falha} = (\text{SCSI Timeout}) \times (\text{SCSI Retries} + 1) $$
Parece simples, mas há camadas.
1. A Camada HBA (Fibre Channel)
Antes mesmo do SCSI, a placa de fibra tem seus próprios timers.
dev_loss_tmo: Define quantos segundos a camada FC espera após perder o sinal na fibra antes de remover o dispositivo do sistema operacional. O padrão muitas vezes é 30 a 60 segundos.- Se o link piscar e voltar em 29 segundos, o I/O fica represado, a aplicação congela, mas nenhum erro é gerado. A fila apenas para.
2. A Camada SCSI (Mid-layer)
Aqui é onde o perigo mora. O kernel Linux tem um parâmetro SD_TIMEOUT (geralmente 30s ou 60s) e um número de retries (retries, geralmente 5).
Se um comando SCSI é enviado e não recebe resposta (o switch morreu silenciosamente, black hole), o timer conta até 30s. Estoura. O mid-layer tenta de novo. E de novo.
Se você tem 5 retries de 30 segundos: $30s \times (5 + 1) = 180s$ (3 minutos).
Isso é por comando. Se sua aplicação tem 50 threads tentando escrever, todas elas vão entrar nessa fila de espera.
3. A Camada Multipath
O Multipath só entra em ação quando a camada SCSI abaixo dele retorna um erro definitivo de I/O. Se a camada SCSI está em loop de retry, o Multipath não sabe que há um problema. Ele acha que o disco está apenas lento.
Portanto, o failover do Multipath não acontece até que a camada SCSI desista.
Cenário Real: Você tem 4 caminhos para o storage. 2 passam pelo Switch A (que falhou) e 2 pelo Switch B. O driver tenta o Caminho 1. Falha após 3 minutos. O driver tenta o Caminho 2 (que também está no Switch A). Falha após 3 minutos. Total de congelamento: 6 minutos. Só então ele tenta o Caminho 3 e o I/O flui.
Para um cluster Oracle RAC ou um cluster VMware HA, 6 minutos é uma eternidade. O nó já foi evitado (fenced), as VMs reiniciaram em outro lugar, e você tem um incidente de Sev-1 nas mãos por causa de uma configuração padrão.
O Arsenal de Tuning: Parâmetros Críticos
Agora que entendemos o problema, vamos às ferramentas para resolvê-lo. Não estamos falando de "melhores práticas" genéricas, mas de alavancas específicas que controlam o comportamento de erro.
fast_io_fail_tmo: O Salvador
Este é, sem dúvida, o parâmetro mais importante em ambientes SAN modernos no Linux.
Ele instrui a camada Fibre Channel a "mentir" para a camada SCSI. Se a HBA detectar que o link caiu, ela espera o tempo definido em fast_io_fail_tmo (ex: 5 segundos). Se o link não voltar, ela imediatamente falha todos os I/Os pendentes naquele caminho com um erro de transporte, bypassando os retries da camada SCSI padrão.
Isso força o erro a subir para o Multipath quase instantaneamente.
- Sem
fast_io_fail_tmo: Esperadev_loss_tmo(ex: 30s-infinity) ou os retries SCSI (minutos). - Com
fast_io_fail_tmo = 5: Em 5 segundos, o Multipath percebe a falha e troca para o caminho saudável.
dev_loss_tmo: O Limite da Esperança
Este parâmetro define quando o sistema desiste completamente do dispositivo. Se o link cair e não voltar após esse tempo, o device /dev/sdX é removido da tabela de dispositivos.
- Cuidado: Se você definir isso muito baixo (ex: igual ao
fast_io_fail_tmo), uma oscilação rápida no switch pode fazer seus discos "desaparecerem" do sistema, exigindo um rescan manual ou reboot para trazê-los de volta. - Recomendação: Mantenha
dev_loss_tmoalto (ex: infinity ou 2147483647 em alguns storages) para evitar que discos sumam, mas usefast_io_fail_tmobaixo para garantir failover rápido.
no_path_retry e queue_if_no_path: A Armadilha da Fila
O que acontece se todos os caminhos falharem? O storage inteiro caiu. O padrão de muitas configurações é "queue" (enfileirar). O sistema operacional segura o I/O na memória, esperando que o storage volte.
- Vantagem: Se o storage voltar em 10 minutos, o banco de dados retoma de onde parou sem perder dados ou crashar processos.
- Desvantagem: O sistema fica em
Dstate (Load 100+). Você não consegue desmontar partições, não consegue matar processos, e muitas vezes o sistema operacional trava completamente (OOM Killer pode entrar em ação se a fila de I/O encher a RAM).
Para aplicações de cluster (como Oracle RAC), você geralmente quer que o I/O falhe rápido se todos os caminhos sumirem, para que o software de cluster possa tomar uma ação (failover para outro site/nó). Nesse caso, no_path_retry deve ser configurado para um número finito (ex: 12 ou 'fail').
Diagnóstico: Como ver o invisível
Você não pode tunar o que não vê. Durante um evento de latência ou failover, ferramentas padrão como top mentem. Elas mostram CPU, não a saúde da fila de I/O.
1. Observando a fila de Multipath em tempo real
O comando multipath -ll é seu amigo, mas você precisa saber ler os estados.
# multipath -ll
mpatha (360060e80104dac0000334e4400000001) dm-0 HITACHI,OPEN-V
size=100G features='1 queue_if_no_path' hwhandler='0' wp=rw
`-+- policy='service-time 0' prio=1 status=active
|- 1:0:0:1 sdb 8:16 active ready running
|- 2:0:0:1 sdc 8:32 active ready running
|- 1:0:1:1 sdd 8:48 failed faulty running <-- Caminho morto
`- 2:0:1:1 sde 8:64 active ready running
failed faulty: O caminho foi marcado como ruim. O Multipath não enviará I/O para cá.shaky: (Em algumas versões) O caminho está oscilando. O Multipath parou de usá-lo temporariamente.active ghostouactive ready: Depende do array (ALUA). Ghost geralmente significa um caminho passivo (standby) que funciona mas não é otimizado.
2. A verdade sobre a latência: iostat estendido
Use iostat -xkz 1. Ignore a coluna %util por um momento. Foque em:
avgqu-sz: Tamanho médio da fila. Se isso está alto (ex: > 32 ou 64) e o throughput está baixo, você tem um gargalo de processamento no storage ou timeout.awaitvsr_await/w_await:await: Tempo total (fila + serviço).- Se
awaité 500ms mas o tempo de serviço (svctm - obsoleto mas útil como conceito) seria baixo, o disco não está respondendo.
3. O Detetive Forense: sar
Se o problema já passou, sar -d é sua caixa preta.
Procure por picos repentinos de await que coincidem com quedas de tps (transações por segundo). Isso é a assinatura clássica de um timeout. O sistema tenta enviar (fila sobe), o disco não responde (tps cai), a latência explode.
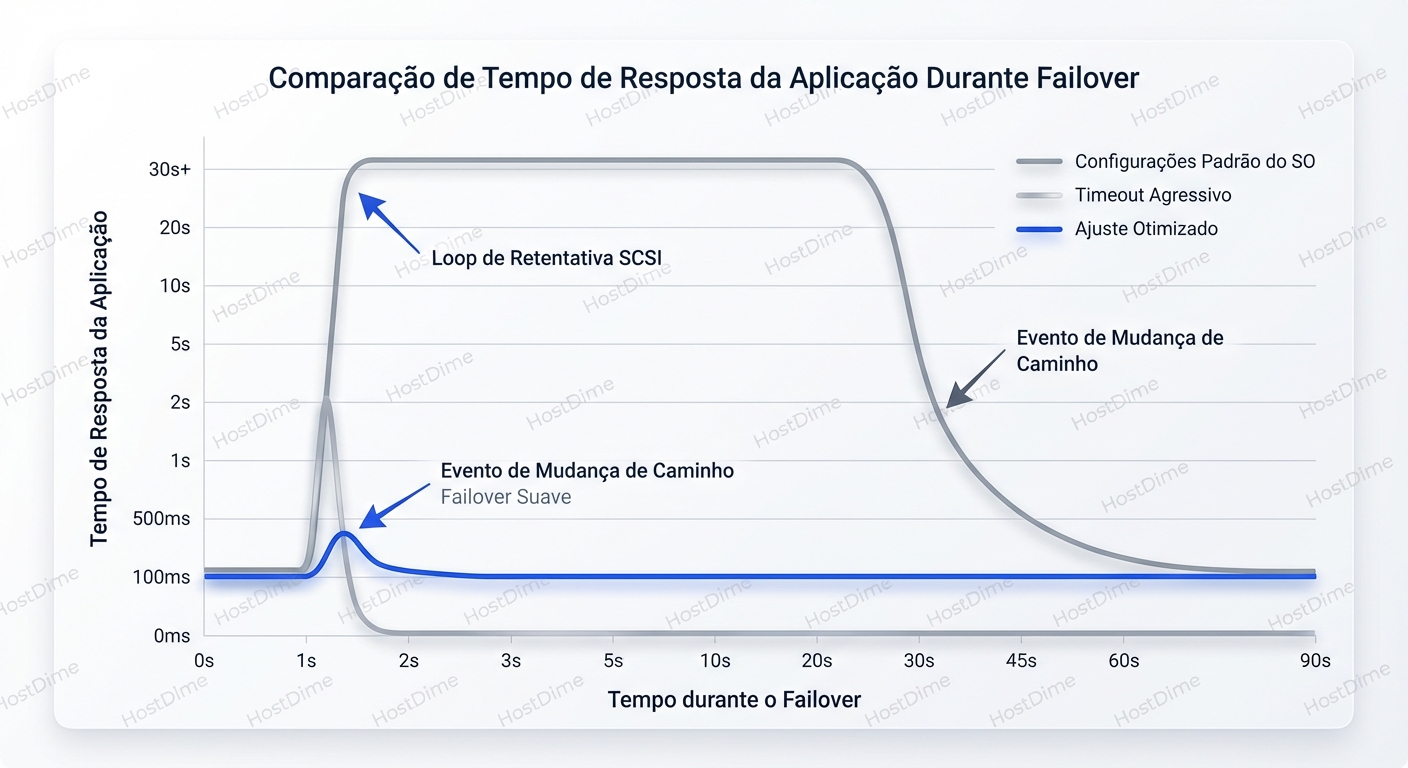
O gráfico acima (placeholder) demonstraria exatamente isso: a linha de "Default Settings" mostra um platô longo de latência alta (o freeze), enquanto "Optimized" mostra um pico curto seguido de estabilidade (o failover).
Cenários de Batalha: Configurações Recomendadas
Não existe "bala de prata". A configuração depende da tolerância da sua aplicação. Vamos comparar três perfis.
Tabela de Comparação de Estratégias
| Parâmetro | Perfil "Conservador" (Default) | Perfil "Agressivo" (DB/Cluster) | Perfil "Virtualização" (ESXi Guest) |
|---|---|---|---|
| Objetivo | Evitar erros de I/O a todo custo. Prioriza estabilidade do link. | Failover rápido. Prioriza disponibilidade da App. | Delegar o controle para o Hypervisor. |
fast_io_fail_tmo |
off ou não setado |
5 segundos |
5 ou off (depende se VMware Tools está controlando) |
dev_loss_tmo |
infinity (ou 600s+) |
infinity |
infinity |
no_path_retry |
queue |
12 (ou fail) |
queue |
checker_timeout |
Default (geralmente alto) | 10 a 30 |
Default |
| Resultado em Falha | Freeze de 2-5 minutos. App em D-State. | Soluço de 5s. App retoma ou Cluster faz fencing. | VM congela brevemente, Hypervisor trata o caminho. |
Configuração Exemplo (multipath.conf para Banco de Dados)
Aqui está um trecho de como isso se traduz no /etc/multipath.conf para um backend de storage enterprise (ex: 3PAR, Pure, EMC VMAX) focado em performance:
defaults {
polling_interval 10
path_selector "service-time 0" # Melhor que round-robin para latências desiguais
path_grouping_policy multibus
getuid_callout "/lib/udev/scsi_id --whitelisted --device=/dev/%n"
prio const
path_checker tur
rr_min_io 100
flush_on_last_del yes
max_fds 8192
rr_weight priorities
failback immediate
no_path_retry fail # Falhe logo se tudo cair!
user_friendly_names yes
}
devices {
device {
vendor "3PARdata"
product "VV"
path_grouping_policy group_by_prio
path_selector "service-time 0"
path_checker tur
features "0"
hardware_handler "1 alua"
prio alua
failback immediate
rr_weight uniform
no_path_retry 18 # Tenta por um tempo curto, depois falha
fast_io_fail_tmo 5 # O segredo do sucesso
dev_loss_tmo infinity
}
}
Nota: Sempre consulte o "Host Connectivity Guide" do seu vendor de storage. Eles testam esses parâmetros exaustivamente. Mas entenda o PORQUÊ deles.
O Lado Sombrio do Tuning Agressivo
Você pode pensar: "Por que não colocar fast_io_fail_tmo em 1 segundo e retries em 0?"
Porque o mundo físico é sujo. Fibras ópticas têm micro-oscilações. Switches fazem updates de firmware que pausam portas por milissegundos. Se sua configuração for paranoica demais, você criará um cenário de "Link Flapping".
- Um erro CRC ocorre no cabo (poeira no conector).
- O sistema imediatamente marca o caminho como falho.
- O Multipath joga tudo para o caminho B.
- O caminho A volta 2 segundos depois.
- O Multipath joga dados de volta para o A (failback).
Esse "ping-pong" de caminhos pode degradar a performance mais do que um caminho estável levemente mais lento. Além disso, o processo de failover consome CPU e gera overhead de locking no kernel.
A regra de ouro: O timeout deve ser maior que a latência máxima esperada durante um pico de carga normal, mais uma margem de segurança. Se seu storage às vezes demora 2 segundos para responder sob carga pesada, um timeout de 1 segundo vai destruir seu cluster sem motivo físico.
Under the Hood: O Código de Retorno SCSI
Para os verdadeiros debuggers, saber ler o dmesg é essencial. Quando você vê mensagens como:
sd 2:0:0:1: [sdb] Result: hostbyte=DID_OK driverbyte=DRIVER_SENSE
Isso conta uma história.
- DID_OK: O comando chegou ao dispositivo. O transporte está ok.
- DID_NO_CONNECT ou DID_TRANSPORT_DISRUPTED: O cabo/switch morreu.
- DID_TIME_OUT: O comando foi enviado, mas o relógio estourou antes da resposta.
Se você vê muitos DID_TIME_OUT, mas o link está Up, seu storage está sobrecarregado ("afogado") ou há um problema de buffer credit no switch SAN (congestionamento silencioso). Nesse caso, diminuir o timeout só vai gerar mais erros. A solução é QoS ou mais hardware.
Veredito: Escolha seu Veneno
Configurar timeouts de SAN é um exercício de gerenciamento de risco. Você está escolhendo entre dois tipos de falha:
- O Congelamento (Alta Tolerância): O sistema segura o I/O, a aplicação trava, usuários reclamam, mas nenhuma transação falha com erro. O sistema volta sozinho se o storage voltar.
- O Erro Rápido (Baixa Tolerância): O sistema mata o I/O, a aplicação recebe um
EIO(Input/Output Error), transações sofrem rollback, o cluster failover dispara.
Para ambientes modernos, cloud-native ou bancos de dados clusterizados, a opção 2 é quase sempre preferível. Um erro limpo e rápido permite recuperação automatizada. Um estado zumbi indefinido requer intervenção humana.
Ação Recomendada:
Não confie em mim. Não confie no default.
Agende uma janela de manutenção. Inicie um dd ou fio gravando no disco. Vá até o datacenter (ou console do switch) e puxe o cabo.
Cronometre com um relógio quanto tempo leva para o I/O fluir pelo segundo caminho.
Se demorar mais de 10 segundos, você tem trabalho a fazer no multipath.conf.
A estabilidade não vem da ausência de falhas, mas da velocidade com que nos recuperamos delas.
Aprofundamento Sugerido
- ALUA (Asymmetric Logical Unit Access): Como o storage diz ao host qual caminho é "rápido" e qual é "lento", e como isso interage com seus timeouts.
- FC Buffer Credits: O assassino silencioso de performance em SANs de longa distância ou congestionadas.
- NVMe-oF (NVMe over Fabrics): Como o novo protocolo muda completamente esse jogo (dica: ele elimina a fila SCSI e seus timeouts legados, trazendo novos desafios de gerenciamento de fila).

Dr. Marcus 'Bitrot' Silva
Engenheiro Sênior de Armazenamento
20 anos recuperando RAIDs quebrados. Especialista em ZFS e sistemas de arquivos distribuídos. Já viu mais falhas de disco do que gostaria.