VMware vSphere 9: Guia de Performance de Storage e Otimização VMFS/vVols

Domine o subsistema de storage do vSphere 9. Entenda as diferenças reais entre VMFS-6 e vVols, configure NVMe-oF e elimine gargalos de I/O com métricas, não suposições.
Performance de storage em ambientes de virtualização não é magia, é física aplicada a filas. Se você não consegue explicar onde o I/O está esperando, você não está fazendo engenharia, está fazendo adivinhação.
No VMware vSphere 9, a camada de abstração ficou mais fina com a consolidação do NVMe-oF, mas a complexidade lógica aumentou. O administrador que apenas "clica em Next" na criação do datastore está deixando de 20% a 40% de performance na mesa. Este guia ignora as "melhores práticas" genéricas para focar na mecânica do fluxo de dados e como provar, com números, onde está o gargalo.
Otimização de Performance de Storage no vSphere 9
A otimização de storage no vSphere 9 consiste na redução sistemática da latência em três camadas críticas: a pilha de driver do Guest OS (PVSCSI/NVMe), a gestão de filas do VMkernel (HPP vs NMP) e a resposta do array físico. O objetivo não é apenas aumentar o IOPS bruto, mas garantir que o tempo de serviço (DAVG) e o tempo de espera no kernel (KAVG) permaneçam estáveis sob carga, utilizando protocolos modernos como NVMe-oF para eliminar o overhead de tradução SCSI.
O Caminho do I/O: Do Guest OS ao Array Físico
Para diagnosticar lentidão, você precisa visualizar o pacote de dados descendo pelo stack. A maioria dos administradores culpa o Storage Array (o hardware final) quando a latência sobe, mas em 60% dos casos, o problema é "in-host" (dentro do ESXi).
O vSphere não processa I/O instantaneamente; ele gerencia filas. Quando uma VM envia uma gravação:
Guest OS: O driver (ex: PVSCSI) coloca o comando no anel de transmissão.
vSCSI: O hypervisor pega esse comando.
PSA (Pluggable Storage Architecture): O kernel decide por qual caminho físico enviar (Multipathing).
HBA Driver: O comando é enviado ao hardware.
Fabric: O cabo (Fibre Channel, Ethernet) transporta o dado.
Storage Controller: O array recebe, processa e grava na mídia (Flash/HDD).
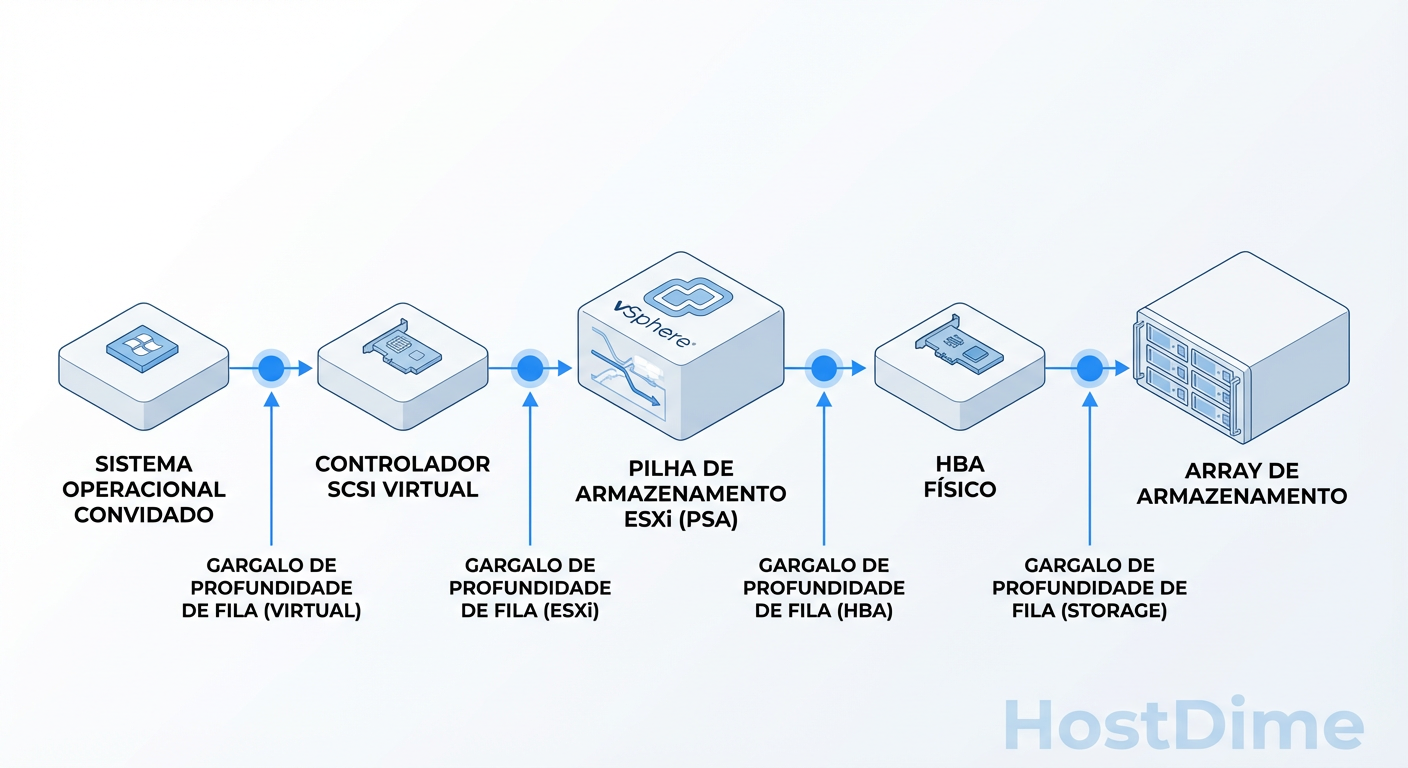 Figura: O funil de I/O: Onde a latência realmente acontece no stack do vSphere.
Figura: O funil de I/O: Onde a latência realmente acontece no stack do vSphere.
Se você observar latência alta no vCenter, ela é a soma de todas essas etapas. O segredo da performance no vSphere 9 é saber isolar se a espera está na etapa 3 (CPU do Host saturada/Locking) ou na etapa 6 (Disco lento).
Otimização VMFS-6: Alinhamento, Locking e UNMAP no vSphere 9
O VMFS-6 é o sistema de arquivos padrão, mas ele não é "configure e esqueça" para cargas de alta performance. O vSphere 9 traz refinamentos no tratamento de metadados que exigem atenção.
Locking Atômico (ATS) vs. Reservas SCSI
Antigamente, para atualizar metadados (ex: expandir um arquivo VMDK), o host precisava "travar" o LUN inteiro (SCSI Reservation). Isso matava a performance de todos os vizinhos. O VMFS-6 usa exclusivamente ATS (Atomic Test & Set). O ATS permite travar apenas o setor do disco necessário para a atualização de metadados.
O Risco: Se o seu Storage Array tiver uma implementação de firmware ATS com bugs ou lenta, o VMFS pode tentar reverter para reservas SCSI antigas, causando "congelamentos" aleatórios.
- Ação: Verifique se o VAAI (vStorage APIs for Array Integration) está ativo e se o status do ATS é "Supported".
O Dilema do UNMAP Automático
O VMFS-6 recupera espaço livre automaticamente (UNMAP/TRIM). Isso é ótimo para economizar espaço no array, mas tem um custo de I/O. O processo de UNMAP gera comandos SCSI extras. Em arrays All-Flash antigos ou sobrecarregados, o UNMAP agressivo pode elevar a latência de gravação das VMs de produção.
- Diagnóstico: Se a latência sobe em horários de baixa demanda (quando o UNMAP costuma rodar), considere alterar a prioridade do UNMAP via CLI:
esxcli storage vmfs reclaim config get -l "NomeDatastore"
vVols: A Promessa vs. A Realidade Operacional
Virtual Volumes (vVols) prometem eliminar o LUN management, transformando cada disco virtual em um objeto nativo no storage. No papel, é perfeito: controle de QoS por disco, snapshots offloaded instantâneos.
A Realidade Operacional: A performance do vVol depende inteiramente do VASA Provider (o software que roda no storage e fala com o vCenter). Se o VASA Provider for lento ou cair, o Data Plane (o I/O das VMs) continua funcionando, mas o Control Plane (ligar VM, snapshot, vMotion) morre.
Quando não usar vVols:
Se o seu array tem um histórico de VASA Providers instáveis (consulte fóruns, não o vendedor).
Se você precisa de performance bruta máxima sem overhead de chamadas de API externas para cada operação de gerenciamento.
Para ambientes de altíssima densidade no vSphere 9, um datastore VMFS-6 bem configurado ainda é mais robusto e previsível que vVols em arrays de gama média.
A Revolução NVMe-oF: Abandonando o SCSI para Baixa Latência
Aqui reside a maior mudança de performance do vSphere 9. O protocolo SCSI foi desenhado nos anos 80 para fitas e discos giratórios. Ele é serial e limitado. O NVMe over Fabrics (NVMe-oF) não é apenas "mais rápido"; ele é arquiteturalmente diferente. Ele permite que o vSphere fale com o storage usando o paralelismo nativo das CPUs modernas.
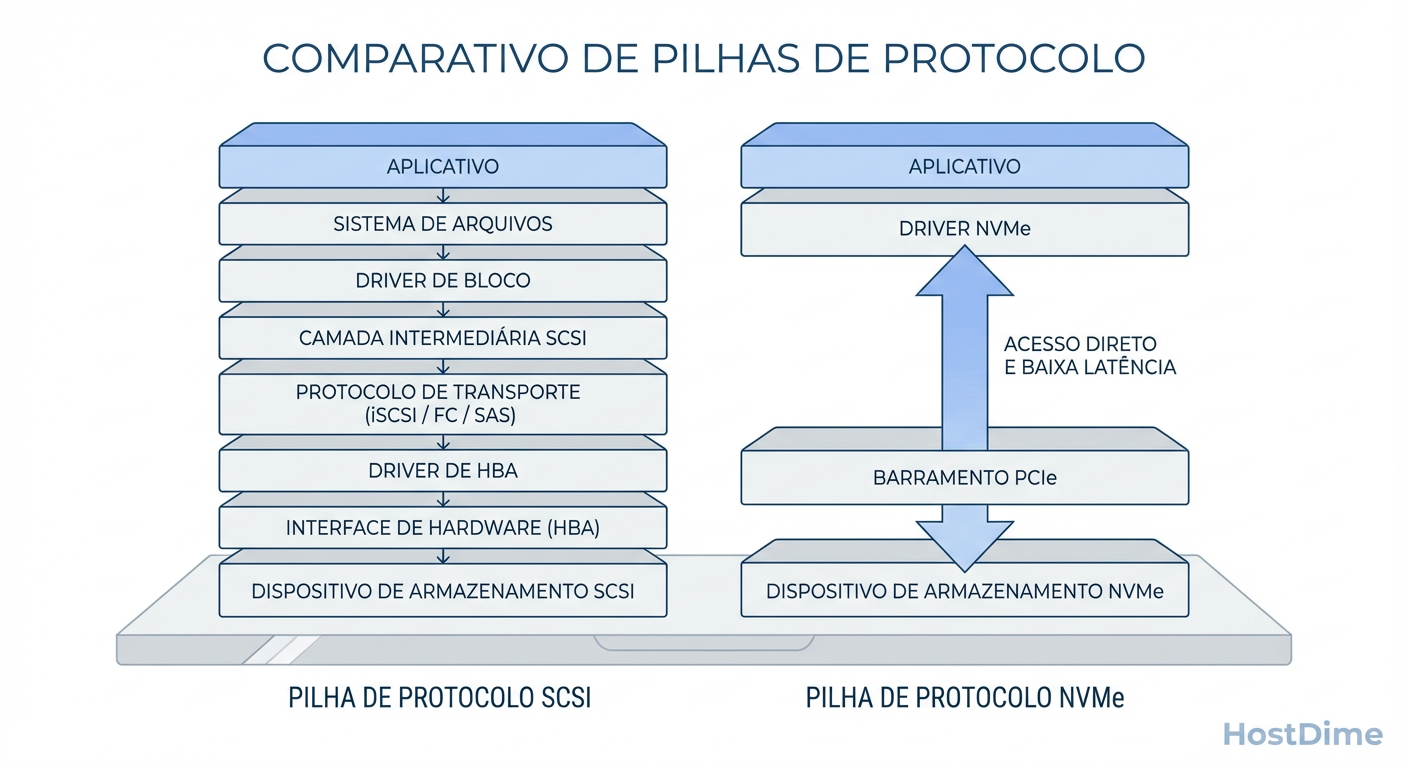 Figura: SCSI vs. NVMe: Por que o NVMe-oF reduz o uso de CPU no vSphere 9.
Figura: SCSI vs. NVMe: Por que o NVMe-oF reduz o uso de CPU no vSphere 9.
Comparativo Técnico: SCSI vs NVMe-oF
Enquanto o SCSI encapsula comandos e exige ciclos de CPU para tradução, o NVMe-oF reduz drasticamente o caminho do código.
| Característica | SCSI (Fibre Channel / iSCSI) | NVMe-oF (FC / TCP / RDMA) | Impacto na Performance |
|---|---|---|---|
| Filas (Queues) | 1 fila por LUN | 64.000 filas (paralelismo real) | Elimina gargalos de serialização. |
| Profundidade da Fila | Típico: 32 ou 64 comandos | 64.000 comandos por fila | Permite saturação total de Flash Arrays. |
| Overhead de CPU | Alto (Tradução SCSI necessária) | Baixo (Direct Memory Access) | Mais CPU livre para rodar VMs. |
| Latência | Média (Overhead de protocolo) | Baixa (Perto da velocidade do wire) | Resposta mais rápida para DBs transacionais. |
Veredito: Para novos deployments no vSphere 9 com arrays All-Flash ou NVMe, usar SCSI (iSCSI/FC tradicional) é um erro de arquitetura. Use NVMe-oF.
Multipathing Moderno: Quando usar NMP vs. HPP
O vSphere possui plugins para decidir qual caminho físico usar. A escolha errada aqui pode limitar o throughput de um array de milhões de dólares à velocidade de um único cabo.
NMP (Native Multipathing Plugin)
É o padrão para dispositivos SCSI (SAS, SATA, FC, iSCSI).
Problema: O padrão geralmente é "Fixed" ou "Most Recently Used". Isso usa apenas UM caminho ativo.
Otimização: Mude sempre para Round Robin (PSP_RR) e altere o parâmetro
iops=1. Isso força o ESXi a trocar de caminho a cada 1 I/O, balanceando a carga perfeitamente entre todos os cabos.
HPP (High Performance Plugin)
Introduzido para NVMe. O NMP é lento demais para NVMe. O HPP foi reescrito para lidar com as múltiplas filas do NVMe.
Regra: Se você usa NVMe-oF no vSphere 9, você deve usar HPP.
Diferencial: O HPP tem mecanismos inteligentes de "Path Selection" que detectam latência no caminho e evitam automaticamente rotas congestionadas, algo que o NMP faz de forma muito rudimentar.
Diagnóstico de Gargalos: Usando esxtop para medir DAVG e KAVG
Gráficos do vCenter fazem médias de 20 segundos (tempo real) ou 5 minutos (histórico). Isso esconde picos de latência que travam bancos de dados. Para engenharia de performance, usamos o esxtop via SSH.
Execute esxtop, pressione u (para visão de disco) e f para selecionar os campos. Garanta que você está vendo as colunas DAVG, KAVG e GAVG.
A Fórmula da Latência
GAVG (Guest Average) = KAVG (Kernel Average) + DAVG (Device Average)
A interpretação desses valores é binária. Não existe "talvez":
DAVG alto (> 10-15ms constante):
- Significado: O dispositivo (Device) está lento. O comando saiu do ESXi e o array demorou para responder.
- Culpado: Storage Array saturado, Fabric congestionado ou disco com defeito.
- Ação: Verifique o array. O vSphere é inocente.
KAVG alto (> 1-2ms):
- Significado: O comando ficou preso no Kernel do ESXi antes de sair para o cabo.
- Culpado: CPU do Host saturada (Ready Time alto), filas de driver mal configuradas (Queue Depth baixo) ou excesso de comandos (buffer overflow).
- Ação: Aumente o Queue Depth do HBA, verifique se há oversubscription de CPU no host ou mude de NMP para HPP se aplicável.
ABORTS/s > 0:
- Significado: O storage demorou tanto que o ESXi desistiu e mandou cancelar o comando.
- Culpado: Falha grave de hardware ou timeout.
- Ação: Risco iminente de corrupção ou queda. Investigue imediatamente.
Otimização de Queue Depth
Se o seu array é rápido (Flash) mas o throughput está limitado e a latência (DAVG) é baixa, você pode ter uma fila pequena demais. Aumentar o Queue Depth (ex: de 64 para 128 ou 256) permite mais I/O em voo.
- Cuidado: Aumentar a fila aumenta a latência se o array não aguentar. É um trade-off entre Throughput e Latência.
Referências & Leitura Complementar
VMware vSphere 9 Storage Performance Technical Reference - Documentação oficial sobre limites de configuração e HPP.
NVM Express Base Specification (Revision 2.0) - Para entender a arquitetura de filas paralelas e namespaces.
RFC 3720 (iSCSI) vs RFC 9300 (NVMe over Fabrics) - Comparativo técnico dos protocolos de transporte.
Gregg, Brendan. "Systems Performance: Enterprise and the Cloud" - Capítulo sobre Disk I/O e metodologias de USE (Utilization, Saturation, Errors).

Dr. Marcus 'Bitrot' Silva
Engenheiro Sênior de Armazenamento
20 anos recuperando RAIDs quebrados. Especialista em ZFS e sistemas de arquivos distribuídos. Já viu mais falhas de disco do que gostaria.