ZFS ARC: O Fim da Regra '1GB por TB' e a Ciência do Cache Real

Esqueça os mitos de dimensionamento do ZFS. Aprenda a analisar o Working Set, interpretar o arcstat e ajustar a memória baseada em evidências, não em regras de 2010.
Se você entrar em qualquer fórum de entusiastas ou sysadmins juniores perguntando sobre dimensionamento de servidor ZFS, a resposta virá como um reflexo pavloviano: "Você precisa de 1GB de RAM para cada 1TB de disco."
Isso não é apenas uma simplificação grosseira. É um mito zumbi que recusa a morrer e está custando dinheiro à sua empresa.
Seguir essa regra cegamente leva a dois cenários desastrosos: ou você superdimensiona o servidor, gastando milhares de dólares em RAM que ficará ociosa, ou subdimensiona a performance porque focou na capacidade total do disco em vez de entender como seus dados são acessados.
Vamos dissecar o ARC (Adaptive Replacement Cache), abandonar a magia negra e focar na única coisa que importa em engenharia de sistemas: comportamento observável e métricas.
O Mito Zumbi e a Origem do "1GB por TB"
Vamos matar isso agora. Essa regra de ouro nasceu em uma época específica, para um caso de uso específico: Deduplicação.
Se você ativar a deduplicação no ZFS, o sistema precisa manter uma Tabela de Deduplicação (DDT) na memória para saber, em tempo real, se o bloco que está sendo gravado já existe no disco. Se essa tabela não couber na RAM e transbordar para o disco, cada gravação vira uma busca aleatória lenta. O desempenho cai de um penhasco. Para esse cenário, a regra do 1GB/1TB (ou até mais) faz sentido.
Mas para 99% dos casos de uso (file server, VM storage, backups) sem deduplicação, essa regra é lixo.
O ZFS não precisa de RAM proporcional ao tamanho do disco para funcionar. Ele precisa de RAM proporcional ao seu Working Set (conjunto de trabalho) e aos metadados que você acessa.
Anatomia do ARC: Mais Esperto que o LRU
A maioria dos sistemas de arquivos usa um cache simples do tipo LRU (Least Recently Used). A lógica é básica: "Se a RAM encher, jogue fora o que não é acessado há mais tempo".
O problema do LRU é que ele é burro. Imagine que você tem um banco de dados rodando perfeitamente no cache. Às 3 da manhã, um script de backup roda e lê todos os arquivos do disco sequencialmente. Um cache LRU simples descartaria os dados vitais do banco de dados para armazenar os dados do backup (que só foram lidos uma vez). Resultado: na manhã seguinte, o banco de dados está lento porque precisa ler tudo do disco novamente.
O ZFS ARC resolve isso dividindo o cérebro em dois:
MRU (Most Recently Used): O que você acabou de tocar.
MFU (Most Frequently Used): O que você toca sempre.
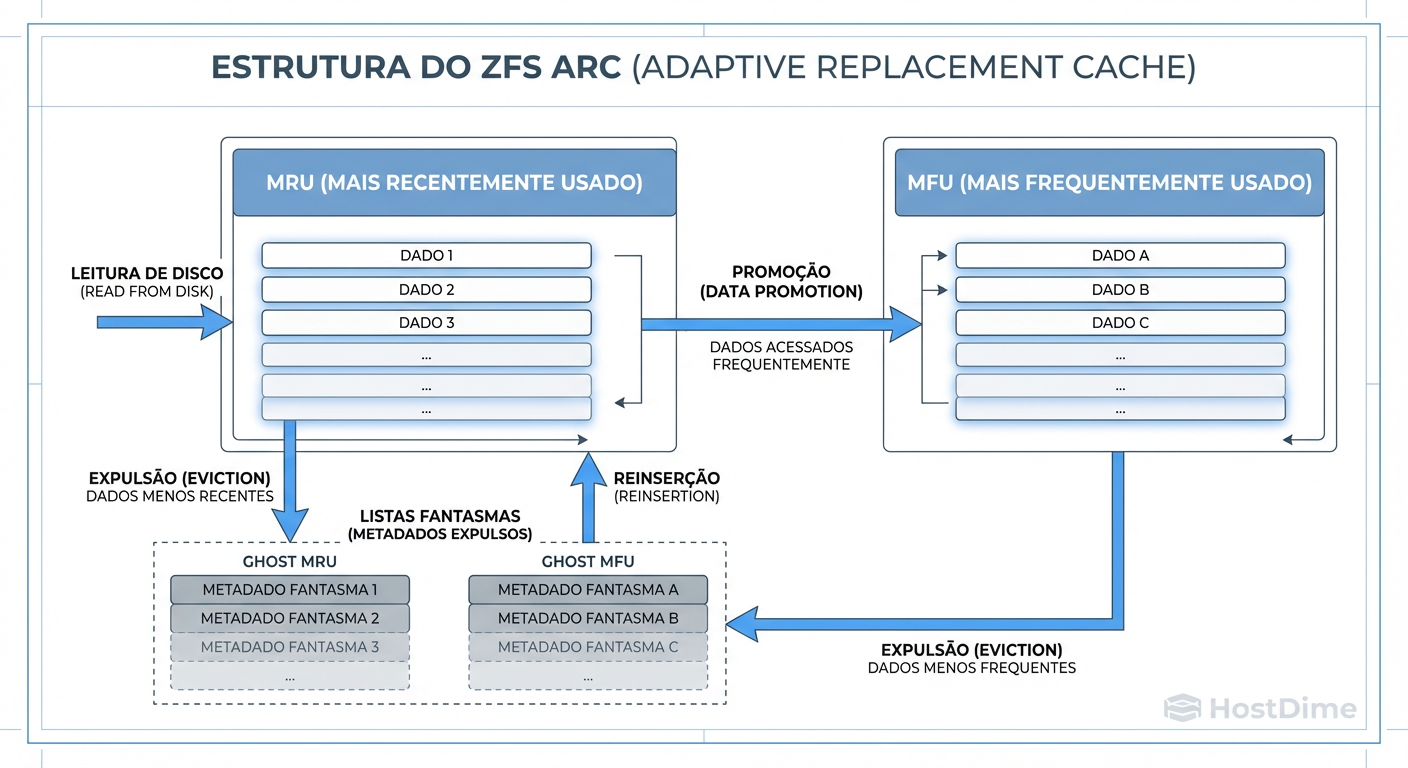 Figura: O Cérebro do ARC: Ele não apenas armazena o que você usou por último (MRU), mas protege agressivamente o que você usa sempre (MFU). As 'Ghost Lists' são o segredo para o ZFS saber se precisa de mais RAM.
Figura: O Cérebro do ARC: Ele não apenas armazena o que você usou por último (MRU), mas protege agressivamente o que você usa sempre (MFU). As 'Ghost Lists' são o segredo para o ZFS saber se precisa de mais RAM.
O ARC equilibra dinamicamente essas duas listas. Se o backup varre o disco, o ZFS percebe que esses dados são recentes (MRU) mas não frequentes, e protege o cache MFU.
Mais impressionante são as Ghost Lists. Quando o ZFS é forçado a expulsar dados da RAM para liberar espaço, ele não esquece totalmente deles. Ele mantém uma referência (um "fantasma") de que aquele dado existia. Se você solicitar um dado que está na Ghost List, o ZFS pensa: "Aha! Se eu tivesse um cache um pouco maior, isso teria sido um Hit. Preciso aumentar a área de MFU/MRU." É assim que ele se adapta à sua carga de trabalho.
O Conceito de Working Set
Aqui está a verdade que dói: A capacidade total do seu pool não importa.
Imagine dois servidores:
Servidor A: 100TB de capacidade. Armazena arquivos mortos (Cold Storage) acessados uma vez por ano.
Servidor B: 1TB de capacidade. Hospeda 50 máquinas virtuais de alta performance acessadas 24/7.
Pela regra estúpida do "1GB/1TB", o Servidor A precisaria de 100GB de RAM e o Servidor B de 1GB. Na prática, o Servidor A roda feliz com 4GB de RAM, enquanto o Servidor B vai travar e chorar por 64GB ou mais.
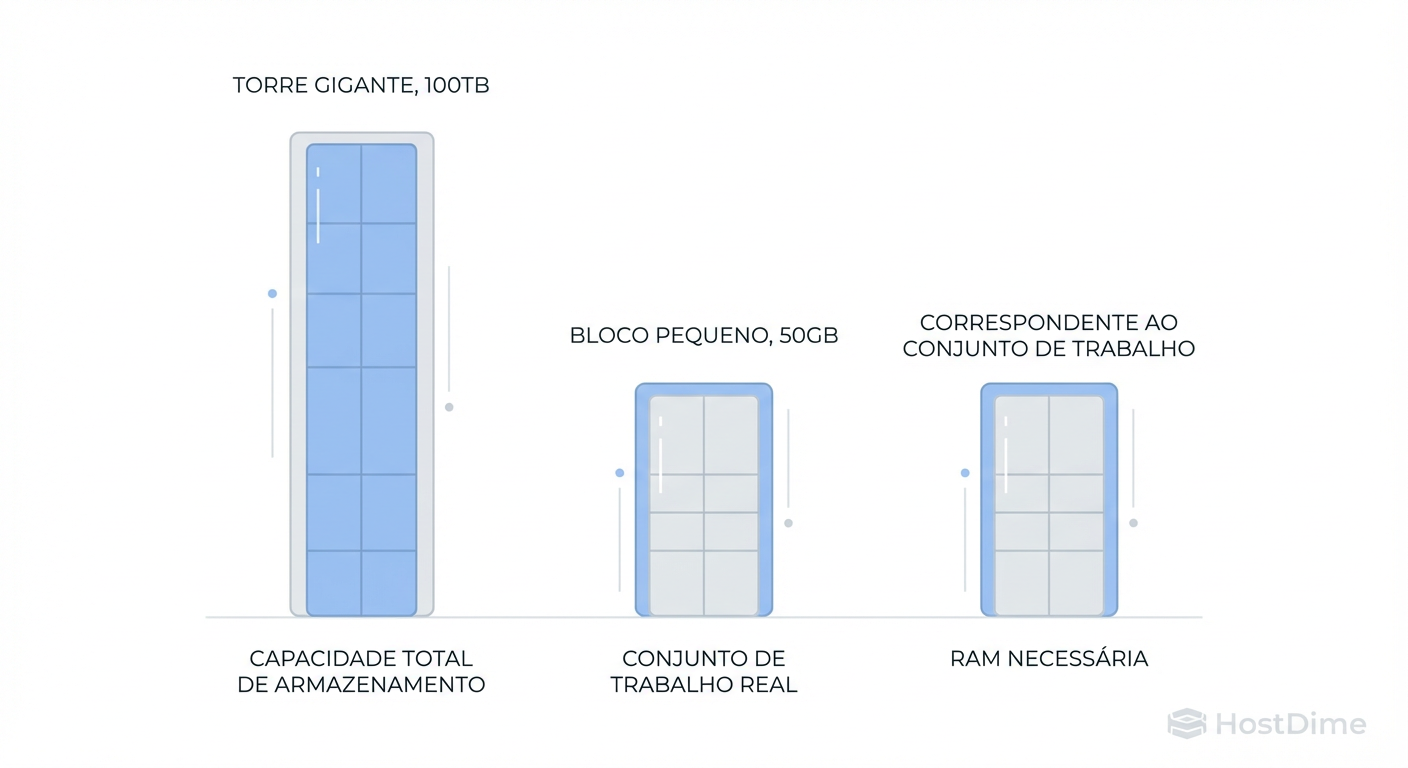 Figura: Capacidade vs. Working Set: Se você tem 100TB de dados frios (arquivos mortos) e apenas 50GB de dados acessados diariamente, você precisa de RAM para cobrir os 50GB, não os 100TB.
Figura: Capacidade vs. Working Set: Se você tem 100TB de dados frios (arquivos mortos) e apenas 50GB de dados acessados diariamente, você precisa de RAM para cobrir os 50GB, não os 100TB.
Você deve dimensionar a RAM para cobrir o Working Set Ativo.
Se seus usuários acessam repetidamente os mesmos 50GB de planilhas e PDFs todos os dias, você quer 64GB de RAM para garantir que 100% dessas leituras venham da memória (microssegundos), e não dos discos (milissegundos).
O restante dos 100TB pode ficar no disco girando. Se alguém acessar um arquivo de 2015, eles esperarão 100ms. Ninguém vai morrer por isso.
Evidência sobre Suposição: Medindo a Eficiência
Como você sabe se tem RAM suficiente? Não adivinhe. Pergunte ao arcstat.
No Linux ou BSD, execute:
# Monitora o ARC a cada 1 segundo
arcstat 1
Você verá uma saída como esta:
time read miss miss% dmis dm% pmis pm% mmis mm% size c
...
10:00:01 40K 10K 25 10K 25 0 0 10K 25 30G 30G
O que olhar:
size vs c:
sizeé o uso atual do ARC.cé o alvo (target) máximo. Sesize<c, seu cache ainda está crescendo ou você tem RAM sobrando.miss%: Esta é a métrica de ouro.
- miss% perto de 0: Você está servindo tudo da RAM. Ótimo. Talvez você tenha RAM demais (desperdício de $$).
- miss% alto (>10-20%) CONSTANTE: Você tem um problema. O Working Set é maior que a RAM. O disco está sendo martelado.
Nota Pragmática: Um miss% alto durante um backup ou uma cópia de arquivos novos é normal. O que preocupa é miss% alto durante a operação rotineira de leitura.
Para uma visão detalhada de como o MFU e MRU estão se comportando, use:
arc_summary
Procure a seção "ARC Breakdown". Se o seu MFU Hit Rate for alto (90%+), o ZFS identificou corretamente seus dados quentes e os está protegendo.
A Armadilha do L2ARC (Cache em SSD)
Sysadmins adoram adicionar SSDs como cache de leitura (L2ARC) achando que é "RAM barata". Cuidado.
O L2ARC não é memória mágica. Para saber o que está no SSD (L2ARC), o ZFS precisa manter uma tabela de apontadores na RAM principal (ARC).
O Custo Oculto: Cada bloco de dados no L2ARC consome cerca de 70 bytes de RAM na tabela de cabeçalho.
- Parece pouco? Se você adicionar um SSD de 1TB como L2ARC cheio de pequenos blocos (recordsize 4K), você vai consumir ~16GB de RAM apenas para mapear o SSD.
Se o seu servidor tem apenas 32GB de RAM, adicionar esse SSD vai roubar metade da sua RAM disponível para o ARC rápido. Você está expulsando metadados ultra-rápidos da RAM para indexar dados moderadamente rápidos no SSD. O resultado final é um servidor mais lento.
Regra de Bolso: Só use L2ARC se:
Sua RAM já está maximizada (slots cheios).
Seu
arcstatmostra miss rates altos.Você tem RAM suficiente para "pagar" o custo do índice do L2ARC.
Ajuste Fino no Linux: A Batalha do OOM Killer
O ZFS nasceu no Solaris. No Linux, ele é um cidadão de segunda classe (por motivos de licença). Isso cria uma tensão. O Kernel do Linux vê a memória do ARC como "memória usada", não como "cache de sistema de arquivos livre para ser descartado".
Se uma aplicação precisar de RAM súbita e o ARC estiver ocupando 80% da memória, o Linux pode não esperar o ARC encolher e acionar o OOM Killer (Out of Memory Killer), matando seu banco de dados ou o processo SSH.
Para servidores de produção Linux, nunca deixe o ZFS gerenciar o máximo por padrão (que geralmente é 50% da RAM do host). Defina limites rígidos.
Configuração Recomendada (Exemplo para servidor de 64GB dedicado a Storage):
Você quer garantir RAM para o sistema base + margem de segurança. Digamos que deixaremos 48GB para o ZFS.
Crie/edite /etc/modprobe.d/zfs.conf:
# zfs_arc_max em bytes (48GB * 1024^3) = 51539607552
options zfs zfs_arc_max=51539607552
# zfs_arc_min (Evita que o cache encolha demais, garantindo performance mínima)
# Digamos 4GB
options zfs zfs_arc_min=4294967296
Após aplicar, monitore. Se o servidor começar a usar Swap, seu zfs_arc_max está alto demais.
Resumo Operacional
Esqueça o 1GB/1TB a menos que use deduplicação (e tente não usar deduplicação).
Dimensione pela Carga: RAM = Tamanho do Working Set (dados quentes) + Metadados.
Monitore o
miss%: Se os hits do ARC são altos, você não precisa de mais RAM, não importa o tamanho do disco.Cuidado com L2ARC: Adicionar cache SSD em máquinas com pouca RAM (<64GB) geralmente piora a performance.
No Linux, limite o ARC: Defina
zfs_arc_maxpara evitar que o OOM Killer assassine processos vitais.
Storage não é sobre acumular terabytes. É sobre entregar os bits certos, na velocidade certa, sem falir a empresa. Meça, ajuste, repita.

Marta G. Oliveira
DevOps Engineer & Storage Nerd
Automatiza provisionamento de storage com Terraform e Ansible. Defensora do 'Infrastructure as Code' para storage.