ZFS ARC: O Mito da RAM Devorada e a Arte do Tuning Real

Seu servidor está sem RAM ou o ZFS está apenas fazendo o trabalho dele? Entenda o ARC, analise hit rates e saiba quando (e como) limitar a memória.
O chamado chega às 03:00 da manhã. O Grafana está sangrando vermelho. O alerta é claro e aterrorizante para quem não conhece a anatomia da vítima: RAM Usage > 95%.
O sysadmin júnior já está reiniciando serviços, convencido de que há um memory leak massivo na aplicação Java ou no banco de dados. Ele aponta para o comando free como prova do crime.
Mas, ao chegar na cena, a primeira regra da forense de sistemas se aplica: não confie no resumo, olhe os ponteiros.
A Ilusão Óptica do free
No Linux "vanilla" (com ext4 ou xfs), a memória não utilizada por aplicações é emprestada ao Page Cache. O kernel faz isso de forma transparente. Se a aplicação precisa da RAM de volta, o kernel descarta o cache instantaneamente. É um empréstimo sem burocracia.
Quando introduzimos o ZFS on Linux (ZoL), introduzimos um "corpo estranho" na gestão de memória. O ZFS tem seu próprio mecanismo de cache, o ARC (Adaptive Replacement Cache).
Veja a evidência que causou o pânico:
$ free -g
total used free shared buff/cache available
Mem: 64 60 1 0 3 2
Swap: 0 0 0
A interpretação errada: "Meu Deus, tenho 64GB e estou usando 60GB! Só tenho 1GB livre!"
A realidade forense: Você provavelmente tem 30GB ou 40GB de ARC que o free está contabilizando incorretamente como used (dependendo da versão do procps) ou que ele simplesmente não entende como "memória recuperável" da mesma forma que o Page Cache nativo.
Nota do Investigador: O ARC do ZFS não vive no Page Cache do Linux (LRU simples). Ele vive na memória alocada pelo kernel (via SPL - Solaris Porting Layer). Para o Linux, aquilo é memória em uso pelo kernel, não cache descartável.
O Modelo Mental: O Conflito de Inquilinos
Para entender o risco real, você precisa visualizar a briga por território.
O Page Cache (Nativo): É o cidadão de primeira classe. O Linux sabe exatamente quais páginas são "sujas" (precisam ser gravadas) e quais são "limpas" (podem ser descartadas agora). A liberação é na ordem de nanossegundos.
O ARC (O Inquilino): O ZFS aloca memória do kernel para armazenar metadados e dados. Ele segue a filosofia "Unused RAM is Wasted RAM". Ele vai crescer até atingir o
zfs_arc_max(geralmente 50% da RAM por padrão).
Onde mora o perigo (OOM Killer)
O mantra "RAM não usada é RAM desperdiçada" é lindo na teoria. Na prática, existe uma fricção física.
Quando sua aplicação pede 10GB de RAM subitamente:
O Linux vê que a memória livre é baixa.
O Linux emite um sinal de pressão de memória.
O ZFS recebe o sinal e começa a evictar (expulsar) dados do ARC para liberar espaço.
A Corrida da Morte: A velocidade com que o ZFS consegue liberar o ARC versus a velocidade com que a aplicação aloca memória.
Se a aplicação alocar mais rápido do que o ZFS consegue liberar, o Linux entra em pânico. Ele não vê o ARC diminuindo rápido o suficiente. Ele vê falta de memória iminente.
O resultado? O OOM Killer (Out of Memory Killer) acorda, saca a arma e atira no processo com maior pontuação (geralmente seu banco de dados ou o próprio processo que pediu memória).
Isolando a Variável: É ARC ou Leak?
Não adivinhe. Meça. Antes de culpar a aplicação, verifique o tamanho atual do ARC.
O arquivo da verdade não é o /proc/meminfo, é o arcstats.
# Verificando o tamanho real do ARC em Gigabytes
awk '/^size/ { print $3 / 1024 / 1024 / 1024 " GB" }' /proc/spl/kstat/zfs/arcstats
Se o comando acima retornar 32 GB e o seu free diz que você tem 60GB usados de 64GB, a matemática é simples:
Aplicação/Sistema: ~28 GB
ZFS ARC: 32 GB
Total: 60 GB
Veredito: Não há memory leak. O sistema está fazendo exatamente o que foi projetado para fazer: usar a RAM ociosa para acelerar leituras de disco.
Sinais Vitais vs. Sinais de Perigo
| Sinal | Interpretação Forense | Ação Necessária |
|---|---|---|
| RAM "Used" alta, ARC alto | Comportamento normal do ZFS. O sistema está saudável e rápido. | Nenhuma. Acalme a equipe. |
| Swap sendo usado | O Linux preferiu jogar páginas anônimas para o disco do que esperar o ARC encolher. | Perigo. O ARC pode estar configurado com um mínimo (zfs_arc_min) muito alto ou a pressão de memória é muito rápida. |
| OOM Killer nos logs | `dmesg | grep -i kill`. O kernel perdeu a paciência com o ZFS. |
Resumo da Investigação
O incidente reportado ("sem memória") é, na maioria das vezes, um falso positivo causado pela diferença de contabilidade entre o Linux e o ZFS.
O ARC deve ocupar a RAM livre. Isso é performance, não defeito.
O problema real não é o uso, é a latência de liberação.
Seu inimigo não é a barra vermelha no Grafana, é o OOM Killer disparando porque o ZFS não recuou rápido o suficiente.
Agora que sabemos que a "memória cheia" é (provavelmente) cache útil, precisamos validar se esse cache está realmente trabalhando para nós ou apenas ocupando espaço. É hora de olhar para a eficiência.
Modelo Mental: O Cérebro do ARC (Não é apenas um LRU)
Se você abrir o htop e vir 90% da sua RAM ocupada pelo ZFS, seu instinto de sysadmin "old school" grita: Vazamento de Memória.
Guarde o distintivo. Isso não é um crime; é uma estratégia de eficiência agressiva.
Para entender por que o ZFS se recusa a liberar RAM até o último milissegundo necessário, precisamos dissecar o algoritmo que o governa. A maioria dos sistemas de arquivos usa um LRU (Least Recently Used) simples: o que entrou por último fica no topo; quando enche, o que não foi tocado há mais tempo morre.
O LRU é "burro". Ele sofre de um problema fatal em armazenamento: Scan Thrashing.
Cenário do Crime: Você tem um banco de dados quente no cache. Às 03:00 AM, um backup via
rsyncoutarvarre o disco inteiro. Resultado no LRU: O backup lê terabytes de dados uma única vez. O LRU, cego, inunda o cache com esses dados inúteis e expulsa o banco de dados quente. O desempenho na manhã seguinte é catastrófico.
O ZFS usa o ARC (Adaptive Replacement Cache). Ele não olha apenas para quando você acessou um dado, mas com que frequência.
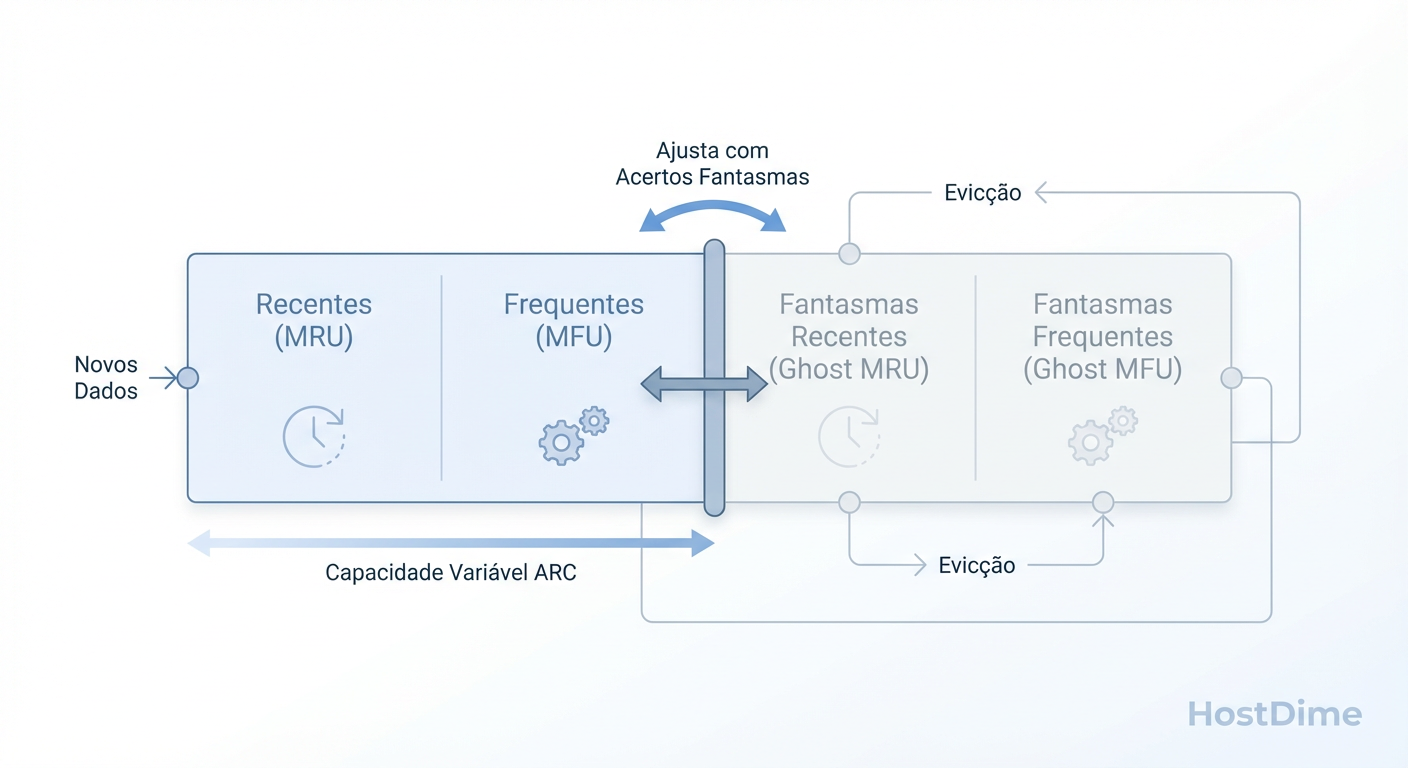
A Anatomia do ARC: Quatro Listas, Um Cérebro
Imagine o ARC como um bibliotecário com memória fotográfica e espaço limitado na mesa. Ele divide o cache em duas categorias principais, que competem por espaço em um cabo de guerra constante:
MRU (Most Recently Used): "Acabei de ver isso." Ótimo para dados novos e imediatos.
MFU (Most Frequently Used): "Vejo isso toda hora." A casa dos dados "quentes" e recorrentes.
Mas a genialidade do ARC (e onde a mágica forense acontece) não está no que ele guarda, mas no que ele lembra que expulsou. É aqui que entram as Ghost Lists (Listas Fantasmas).
O ARC mantém quatro listas lógicas:
T1 (Top 1 - MRU Real): Dados recentes que estão na RAM agora.
T2 (Top 2 - MFU Real): Dados frequentes que estão na RAM agora.
B1 (Bottom 1 - Ghost MRU): Metadados de dados recentes que foram expulsos da RAM. (O corpo sumiu, mas o fantasma ficou).
B2 (Bottom 2 - Ghost MFU): Metadados de dados frequentes que foram expulsos.
O Mecanismo de Aprendizado (O "Target P")
O ZFS possui um ponteiro móvel chamado p (target size). Ele dita quanto da RAM deve ser dedicada a dados Recentes (MRU) versus Frequentes (MFU).
Ele ajusta esse equilíbrio observando onde ocorrem os Phantom Hits (acertos nas listas fantasmas):
Hit na B1 (Ghost MRU):
- Significado: "O usuário pediu algo que eu acabei de jogar fora porque o cache de Recentes era pequeno demais."
- Ação: O ARC aumenta o tamanho alvo da lista MRU (empurra
ppara a esquerda). Ele aprende que precisa favorecer a novidade.
Hit na B2 (Ghost MFU):
- Significado: "O usuário pediu algo que é acessado sempre, mas eu joguei fora porque dei espaço demais para novidades passageiras."
- Ação: O ARC diminui o tamanho alvo da lista MRU (empurra
ppara a direita), preservando mais dados frequentes.
Isso torna o ZFS Scan Resistant. Quando aquele backup das 03:00 AM roda, ele enche a lista MRU. Os dados antigos do banco de dados (MFU) estão protegidos na lista T2. O backup passa, os dados do backup são descartados (porque foram lidos apenas uma vez e não migraram para MFU), e seu banco de dados continua quente na RAM.
O Mecanismo Adaptativo: O ARC ajusta dinamicamente o equilíbrio entre Recência (MRU) e Frequência (MFU) baseado em hits nas 'Ghost Lists'.
Evidência Forense: Vendo o Cérebro em Ação
Não confie na teoria. Verifique o comportamento. Se o seu servidor está lento, precisamos saber se o ARC está lutando para manter dados recentes ou frequentes.
No Linux, usamos o arcstat (parte do pacote ZFS) para ver essa batalha em tempo real. Não olhe apenas para o "hitrate"; olhe para a distribuição.
# Investigando a composição do cache e o movimento do fantasma
# Intervalo de 1 segundo. Focando em mru vs mfu.
arcstat -f time,c,p,mru,mfu,mru_ghost,mfu_ghost,hit% 1
O que analisar na saída:
c(Cache Size): O tamanho total atual do ARC.p(Target MRU): O tamanho alvo para a lista MRU.- Se
pestá próximo dec, seu workload é quase todo "dados novos/aleatórios". - Se
pestá baixo, o ZFS detectou que seus dados são repetitivos e está priorizando o MFU.
- Se
mru_ghostvsmfu_ghost: Se esses números estão explodindo, você tem "memory pressure". O sistema sabe o que deveria estar em cache, mas não tem RAM física para segurar os dados (apenas os metadados fantasmas).
[!NOTE] DICA DE PRODUÇÃO Se você vê um alto número de hits nas Ghost Lists (você pode inferir isso se o
pflutua agressivamente), isso é a prova definitiva de que adicionar mais RAM vai resolver o problema de I/O. O ZFS está literalmente lhe dizendo: "Eu sabia que precisava desse arquivo, mas não tive espaço".
Resumo do Modelo Mental
Não é apenas RAM usada: É RAM investida. O ZFS prefere expulsar páginas limpas de código de aplicação do que dados quentes do disco, porque ler do disco é ordens de magnitude mais lento.
Frequência vence Recência: Ao contrário do LRU, o ARC protege dados acessados repetidamente contra leituras sequenciais massivas (backups/scans).
Fantasmas guiam o caminho: O tamanho das listas não é fixo; ele respira conforme o padrão de acesso muda minuto a minuto.
Evidência: Diagnóstico Forense com arcstat
Chega de "achismo". Se o servidor está lento e o uso de RAM está alto, o administrador novato entra em pânico e limita o ARC. O investigador forense, porém, sabe que RAM livre é RAM desperdiçada. O crime não é o uso de memória; o crime é a latência de I/O.
Para absolver ou condenar o ZFS, precisamos interrogar o cache em tempo real. Nossa ferramenta principal é o arcstat (Python script nativo no ZFS on Linux/OpenZFS).
1. A Cena do Crime em Tempo Real
Não rode o comando sem argumentos. Precisamos de taxa de variação, não de acumulados desde o boot.
# Observe por 5 segundos, atualizando a cada 1 segundo
arcstat 1 5
A saída típica se parece com isso:
time read miss miss% dmis dm% pmis pm% mmis mm% sz c
10:00 12K 200 1 100 1 100 1 0 0 8G 8G
10:01 45K 12K 26 12K 26 0 0 0 0 8G 8G
...
2. Decodificando os Sinais Vitais
Aqui está como ler a matriz sem se perder no ruído:
read: O total de pedidos de leitura por segundo enviados ao ZFS.
miss% (Hit Rate Inverso): A métrica de vaidade. Todo mundo quer ver 0%, mas o contexto reina.
sz (Size): O tamanho atual do ARC.
c (Target Size): O tamanho alvo do ARC.
- Pista Forense: Se
sz<ce você tem RAM livre, o ARC está crescendo ("warming up"). Sesz>c, o kernel está pressionando o ZFS para liberar memória (memory pressure).
- Pista Forense: Se
A Falácia dos 90%: Um Hit Rate de 90% parece ótimo. Mas se você processa 100.000 IOPS, isso significa 10.000 IOPS vazando para o disco. Se seus discos são HDDs mecânicos (que suportam ~150 IOPS cada), seu sistema está morto, mesmo com "90% de sucesso".
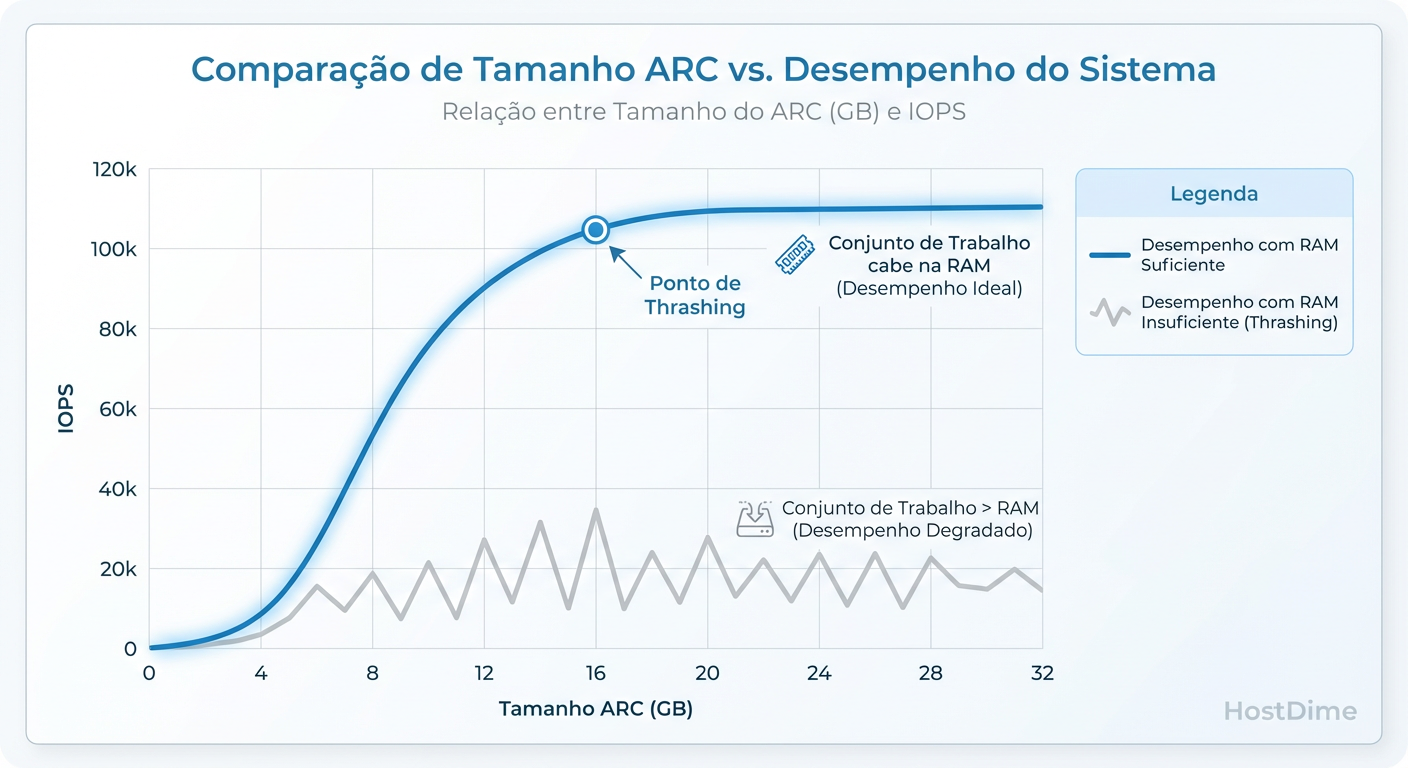
3. O Conceito de "Working Set"
O ARC tenta manter em RAM os dados mais usados (MFU) e mais recentes (MRU). O desempenho cai drasticamente quando o conjunto de dados ativos (Working Set) excede o tamanho físico do ARC disponível. É aqui que o tuning vira um jogo de física, não de configuração.
A Curva do Working Set: Se o seu ARC for menor que os dados 'quentes' (Working Set), a performance despenca. Limitar o ARC incorretamente força leituras de disco desnecessárias.
4. Metadata vs. Data: A Diferença Letal
O arcstat padrão mistura tudo. Mas nem todo miss é igual.
Data Miss: O arquivo não estava na RAM. O sistema vai buscar o bloco no disco. Lento, mas esperado em leituras sequenciais grandes.
Metadata Miss: O ZFS não sabe onde o arquivo está, ou não tem as permissões/atributos em cache. Isso é catastrófico. Operações como
ls -R,findou varreduras de banco de dados travam completamente porque cada leitura exige buscar a estrutura da árvore no disco.
Para diferenciar, usamos o arc_summary ou olhamos colunas específicas do arcstat (mmis = metadata miss).
Investigação Profunda com arc_summary
Se o arcstat mostra fumaça, o arc_summary mostra o fogo.
# Focando apenas na eficiência do ARC
arc_summary -s arc
Procure a seção "ARC Size Breakdown".
Se você vir Metadata size ocupando uma porcentagem minúscula e o Metadata miss alto, seu gargalo não é largura de banda, é IOPS de seek.
Regra de Bolso Forense: Em servidores de arquivos com milhões de arquivos pequenos (ex: e-mail, hospedagem web), o cache de metadados é mais valioso que o cache de dados. Force o ZFS a priorizar metadados (
zfs_arc_meta_limit).
5. O Fantasma do Cache (Ghost Lists)
O ZFS é brilhante porque ele lembra do que acabou de expulsar. Estas são as Ghost Lists (listas fantasmas).
mru_ghost: Dados recentes que foram despejados.
mfu_ghost: Dados frequentes que foram despejados.
Se você tiver muitos "hits" nas listas fantasmas (visíveis via /proc/spl/kstat/zfs/arcstats ou arc_summary), a evidência é clara: Sua carga de trabalho se beneficiaria linearmente de mais RAM ou de um L2ARC (cache em SSD). O ZFS está dizendo: "Eu tinha esse dado agora pouco, mas tive que jogá-lo fora por falta de espaço".
Veredito: Diagnóstico Diferencial
Use esta tabela para determinar a causa raiz antes de tocar em qualquer configuração:
| Sintoma (arcstat) | Contexto | Causa Provável | Ação Recomendada |
|---|---|---|---|
| Hit% > 99%, mas lento | Latência alta no app | Gargalo não é leitura. Provavelmente escritas síncronas (ZIL) ou CPU. | Verifique iostat -x (escrita) e latência de rede. |
| Hit% < 80% | Backup ou Full Scan | Comportamento normal. Dados são lidos uma vez e descartados. | Ignorar. O ARC está fazendo seu trabalho ao não cachear lixo. |
| Hit% < 80% | Banco de Dados / VM | Working Set > RAM. O cache está thrashing. | Adicionar RAM, adicionar L2ARC ou tunar primarycache=metadata. |
| Metadata Miss Alto | ls lento, navegação lenta |
Cache de metadados insuficiente. | Aumentar zfs_arc_meta_limit_percent (padrão costuma ser 75%). |
| Ghost Hits Altos | Performance instável | O cache está despejando dados úteis prematuramente. | Evidência irrefutável para compra de hardware (RAM/SSD L2ARC). |
O Stack: A Guerra de Pressão de Memória (ZFS vs Kernel)
A Cena do Crime: Seu servidor tem 64GB de RAM. O monitoramento diz que 60GB estão "em uso". De repente, uma aplicação Java pede 2GB, o sistema engasga (stall) por 4 segundos e, no final, o kernel invoca o OOM Killer e assassina seu banco de dados.
O culpado imediato parece ser o ZFS "devorando" a RAM. O veredito real: Foi um problema de latência de comunicação entre o kernel do Linux e o ZFS.
Vamos dissecar o cadáver desse incidente.
O Alienígena no Kernel
Para entender a falha, você precisa entender o modelo mental correto: O ZFS não é nativo do ecossistema de memória do Linux.
O kernel do Linux gerencia sua própria cache de disco (Page Cache) de forma agressiva e integrada. Ele sabe exatamente quais páginas pode descartar instantaneamente quando uma aplicação pede memória. É uma conversa interna, fluida.
O ZFS, vindo do Solaris, traz seu próprio gerenciador de memória: o ARC (Adaptive Replacement Cache). No Linux (ZoL), o ARC não vive dentro do Page Cache; ele vive na memória alocada pelo kernel (slab/spl).
Quando a memória acaba, acontece uma negociação hostil:
Kernel: "Estou sem páginas livres. Preciso de RAM agora."
Kernel (Shrinker): Cutuca o ZFS pedindo para liberar memória.
ZFS: Precisa travar estruturas, decidir o que evictar (LRU/LFU), atualizar metadados, liberar o buffer e devolver a página ao kernel.
O "Gap" Mortal: A Velocidade de Evicção
O problema não é o tamanho do ARC. O problema é a derivada (taxa de variação).
Se a sua aplicação aloca memória mais rápido do que o ZFS consegue evictar dados do ARC, o kernel entra em pânico.
O Ciclo da Morte:
- App pede memória.
- Kernel vê RAM cheia -> Aciona Direct Reclaim.
- Kernel bloqueia a App enquanto espera o ZFS liberar RAM.
- ZFS começa a evicção (Isso custa CPU e I/O se houver dirty data).
- O Lag: Se o ZFS demorar milissegundos a mais do que a tolerância do kernel, o kernel assume que não há memória recuperável.
- OOM Killer: O kernel escolhe o processo mais gordo (geralmente o DB ou a App) e o mata para salvar o sistema.
Não foi falta de RAM. Foi falta de tempo de reação.
Evidência Forense: Como provar a culpa
Não adivinhe. Interrogue o sistema. Se você suspeita que o ARC não está reagindo rápido o suficiente à pressão de memória, procure por estes sinais.
1. O Tamanho vs. O Alvo
O ARC tem um tamanho atual (size) e um tamanho alvo (c). Se size > c, o ZFS sabe que precisa encolher, mas ainda não conseguiu.
# Verifique o estado instantâneo do ARC
grep -E '^c |^size ' /proc/spl/kstat/zfs/arcstats
Se você monitorar isso em loop durante um incidente e vir o size se recusando a baixar enquanto o c despenca, você encontrou o gargalo de evicção.
2. O Assassino de Memória (memory_throttle)
O ZFS possui contadores internos que indicam quantas vezes ele teve que frear operações para gerenciar memória.
# Procure por incrementos neste contador
awk '/memory_throttle_count/ {print $3}' /proc/spl/kstat/zfs/arcstats
Se este número estiver subindo, o ZFS está admitindo: "Estou segurando operações de disco porque não tenho memória livre para processá-las".
Tuning Real: Definindo as Fronteiras
No Solaris, deixar o ZFS gerenciar toda a RAM funcionava. No Linux, confiar na retração automática do ARC sob pressão é jogar roleta russa com seus processos.
Você deve impor limites rígidos.
A Regra de Ouro do zfs_arc_max
Nunca deixe o ARC crescer até competir com suas aplicações. Defina um teto seguro.
Cenário: Servidor de Banco de Dados.
Cálculo: RAM Total - (RAM da App + RAM do OS + Margem de Segurança 10%).
Se você tem 64GB e o MySQL precisa de 32GB:
# Defina o máximo do ARC para 24GB (exemplo)
# Valor em bytes: 24 * 1024^3 = 25769803776
echo 25769803776 > /sys/module/zfs/parameters/zfs_arc_max
Nota: Persista isso no /etc/modprobe.d/zfs.conf.
Isso elimina o "Gap Mortal". O ARC nunca crescerá a ponto de o kernel precisar pedir desesperadamente por RAM, pois a RAM livre para a aplicação já estará garantida fora do escopo do ZFS.
A Trincheira do zfs_arc_min
O inverso também é perigoso. Se o kernel estiver sob pressão (talvez por dentry cache ou buffers de rede), ele pode intimidar o ZFS a encolher o ARC até quase zero. Resultado: Performance de disco horrível porque seu cache sumiu.
Proteja seu cache mínimo:
# Garanta que o ARC nunca caia abaixo de 4GB, por exemplo
echo 4294967296 > /sys/module/zfs/parameters/zfs_arc_min
Resumo da Autópsia
Sintoma: OOM Kills intermitentes em cargas de pico.
Causa: O kernel pede memória mais rápido do que o ZFS consegue limpar o ARC (Latência de Shrink).
Solução: Não confie na negociação dinâmica. Use
zfs_arc_maxpara forçar o ZFS a deixar um "pulmão" de RAM livre para o sistema operacional e aplicações, evitando que a guerra de pressão sequer comece.
Produção: Tuning e a Armadilha do L2ARC
Você chega na cena do crime: um servidor de arquivos engasgando. O administrador jura que fez o "upgrade": instalou um SSD NVMe de 1TB para cache e limitou a RAM do ZFS para "sobrar memória para o sistema". O resultado? Latência alta e IOPS instáveis.
Aqui jaz o erro clássico: tratar o ZFS como um sistema de arquivos tradicional. O ZFS não "usa" RAM; ele é a RAM. O disco é apenas onde os dados vão para morrer (persistência).
Vamos dissecar a anatomia desse erro e como consertar.
1. O Modelo Mental: Working Set e Evicção
Antes de tocar em qualquer arquivo de configuração, você precisa entender o Working Set. O Working Set é a quantidade de dados "quentes" (acessados frequentemente) que sua aplicação precisa num intervalo de tempo relevante.
Cenário Ideal: Todo o Working Set cabe na ARC (RAM). Leituras são instantâneas.
Cenário Real: O Working Set é maior que a RAM. O ZFS precisa evictar (expulsar) dados da RAM para ler novos do disco.
O objetivo do tuning não é "economizar RAM", é garantir que o Working Set caiba no cache mais rápido disponível.
2. A Regra de Ouro do zfs_arc_max
Esqueça a regra preguiçosa de "50% da RAM para o ZFS". Isso é superstição, não engenharia. O ZFS é projetado para devolver memória ao sistema quando solicitado, mas em cargas extremas, essa devolução pode ser lenta, causando OOM (Out of Memory) em aplicações.
A Abordagem Forense para Dimensionamento:
Em vez de uma porcentagem arbitrária, calcule de trás para frente:
Quanto o SO precisa para não travar? (Geralmente 2GB-4GB para um Linux moderno headless).
Quanto suas aplicações realmente consomem? (Banco de dados, VMs, Containers). Meça o pico, não a média.
O resto é do ZFS.
Regra de Bolso (Pragmatismo MWL): Se é um Storage Server dedicado (NAS/SAN), defina
zfs_arc_maxparaTotal RAM - 2GB. Deixe o ZFS respirar. Se é um Hypervisor (Proxmox/Sistemas Mistos), definazfs_arc_maxrigidamente para evitar que o ZFS devore a RAM das VMs durante uma scrub.
Como aplicar (sem reiniciar):
# Exemplo: Limitando a 64GB (em bytes)
echo 68719476736 > /sys/module/zfs/parameters/zfs_arc_max
Nota: Para persistir, adicione em /etc/modprobe.d/zfs.conf.
3. A Armadilha do L2ARC (O "Cache" que Piora Tudo)
Aqui é onde a maioria cai. O raciocínio linear é: "Minha RAM está cheia. Vou adicionar um SSD rápido como L2ARC (Level 2 Cache) para expandir a memória."
O Problema Físico: O L2ARC precisa ser indexado. Para saber o que está no SSD, o ZFS precisa manter uma tabela de endereçamento na RAM (ARC).
A Matemática do Desastre
Cada bloco de dados no L2ARC consome cerca de 70 bytes de RAM na ARC para o cabeçalho (header).
Parece pouco? Vamos escalar:
Você tem 64GB de RAM.
Você adiciona um SSD de 2TB como L2ARC.
Você enche o L2ARC com blocos pequenos (ex: 4K ou 8K volblocksize).
Resultado: O ZFS pode precisar de 10GB a 20GB de RAM apenas para mapear o L2ARC.
A Consequência: Para acomodar os headers do L2ARC, o ZFS expulsa dados reais da ARC. Você trocou dados cacheados na RAM (nanosegundos) por dados cacheados no SSD (microsegundos), e ainda pagou uma multa de RAM por isso. Seu "upgrade" acabou de tornar o sistema mais lento.
Sinal de Perigo: Se o seu
arc_summarymostra uma taxa de acerto (Hit Rate) da ARC caindo após adicionar um L2ARC, remova o SSD imediatamente.
4. O Veredito: Quando usar L2ARC?
Não adicione L2ARC por "instinto". Adicione apenas se passar neste checklist:
| Variável | Condição | Ação |
|---|---|---|
| RAM Atual | < 64GB | NÃO USE L2ARC. Compre mais RAM. A taxa de indexação vai matar sua performance. |
| ARC Hit Rate | > 90% | NÃO USE L2ARC. Seu cache atual já resolve. O L2ARC ficará ocioso. |
| Workload | Escrita Sequencial Pura | NÃO USE L2ARC. L2ARC é apenas para leitura. |
| Workload | Leitura Randômica Massiva | SIM. Se o Working Set for 5x maior que a RAM máx possível. |
5. Investigando a Eficiência (Métricas Reais)
Não adivinhe. Pergunte ao kernel. Use o arc_summary ou olhe direto no /proc.
O que procurar no relatório:
ARC Size: Está batendo no
c_max(limite máximo)? Se sim, há pressão de memória.Hit Ratio:
> 95%: Excelente. Não toque em nada.< 80%: Problema. O Working Set não cabe.
L2ARC Breakdown (Se instalado):
- Olhe para
L2ARC HitsvsL2ARC Misses. Se você tem milhões de misses no L2ARC e poucos hits, o SSD está apenas gastando eletricidade e RAM de indexação.
- Olhe para
Comando Rápido para Diagnóstico
Se você não tem arc_summary, extraia a verdade crua:
# Verifique a eficiência do ARC (Hits vs Misses)
grep -E 'hits|misses' /proc/spl/kstat/zfs/arcstats
# Verifique o tamanho atual vs o alvo (c) e máximo (c_max)
grep -E 'c_max|size' /proc/spl/kstat/zfs/arcstats
Resumo da Operação
RAM é Rei: Maximize a RAM física antes de pensar em cache em disco.
Ajuste o Teto: Defina
zfs_arc_maxbaseando-se no que o resto do sistema precisa, não numa % cega.Cuidado com o L2ARC: Adicionar cache SSD em sistemas com pouca RAM (<64GB) é geralmente contraproducente devido ao custo dos headers na memória.
Meça o Working Set: Se o seu ARC Hit Rate é 99%, você não tem um problema de cache, você tem um problema de ansiedade.

Kenji Tanaka
Especialista em Performance de I/O
Obscecado por latência zero. Analisa traces de kernel e otimiza drivers de storage para bancos de dados de alta frequência.