ZFS Compression em RAID-Z: Análise Forense de Performance e Trade-offs
A compressão inline no ZFS não serve apenas para economizar espaço. Descubra como algoritmos como LZ4 e ZSTD podem acelerar o throughput em vdevs RAID-Z e entenda o impacto do 'padding' na eficiência.
Você chega na cena do crime: um servidor de arquivos "se arrastando". O administrador jura que os discos são novos, a rede é 10GbE, mas a latência de gravação está estourando o teto. A primeira suspeita recai sobre a CPU — "deve estar sobrecarregada calculando paridade ou compressão", dizem.
Como investigador forense de sistemas, minha regra número um é: não confie na intuição, confie na telemetria.
Na grande maioria dos casos envolvendo ZFS, a intuição sobre compressão está invertida. O medo de "gastar CPU" leva administradores a desativarem a compressão, transformando um sistema que poderia ser ágil em um dinossauro mecânico preso à velocidade de rotação dos discos. Mas, em configurações específicas de RAID-Z, existe uma armadilha matemática oculta — o padding — que pode anular seus ganhos. Vamos dissecar esse sistema, isolar as variáveis e entender o que realmente acontece quando você ativa compression=on.
ZFS Compression em RAID-Z é o processo de reduzir o tamanho lógico dos dados antes que eles sejam escritos nos discos físicos, trocando ciclos de CPU (que são abundantes e ociosos) por menor tempo de I/O (que é escasso e lento). Em configurações RAID-Z, no entanto, essa eficiência depende do alinhamento entre o tamanho do bloco comprimido e a geometria física dos setores (ashift), podendo gerar desperdício de espaço se não monitorado.
O Paradoxo da Compressão ZFS: Trocando CPU por Latência
Para entender o ganho de performance, precisamos olhar para o "orçamento de tempo" de uma operação de escrita.
Em um HDD moderno, o tempo de busca (seek time) e a latência rotacional são medidos em milissegundos (ms). A CPU opera em nanossegundos (ns). A diferença é de várias ordens de magnitude.
O modelo mental correto aqui não é "Compressão custa trabalho". É "Compressão compra tempo".
Se o algoritmo de compressão (digamos, LZ4) consegue reduzir um bloco de 128KB para 64KB gastando 20 microssegundos de CPU, você acabou de evitar escrever 64KB no disco. O tempo que o disco levaria para escrever esses 64KB extras é infinitamente maior do que o tempo que a CPU levou para comprimi-los.
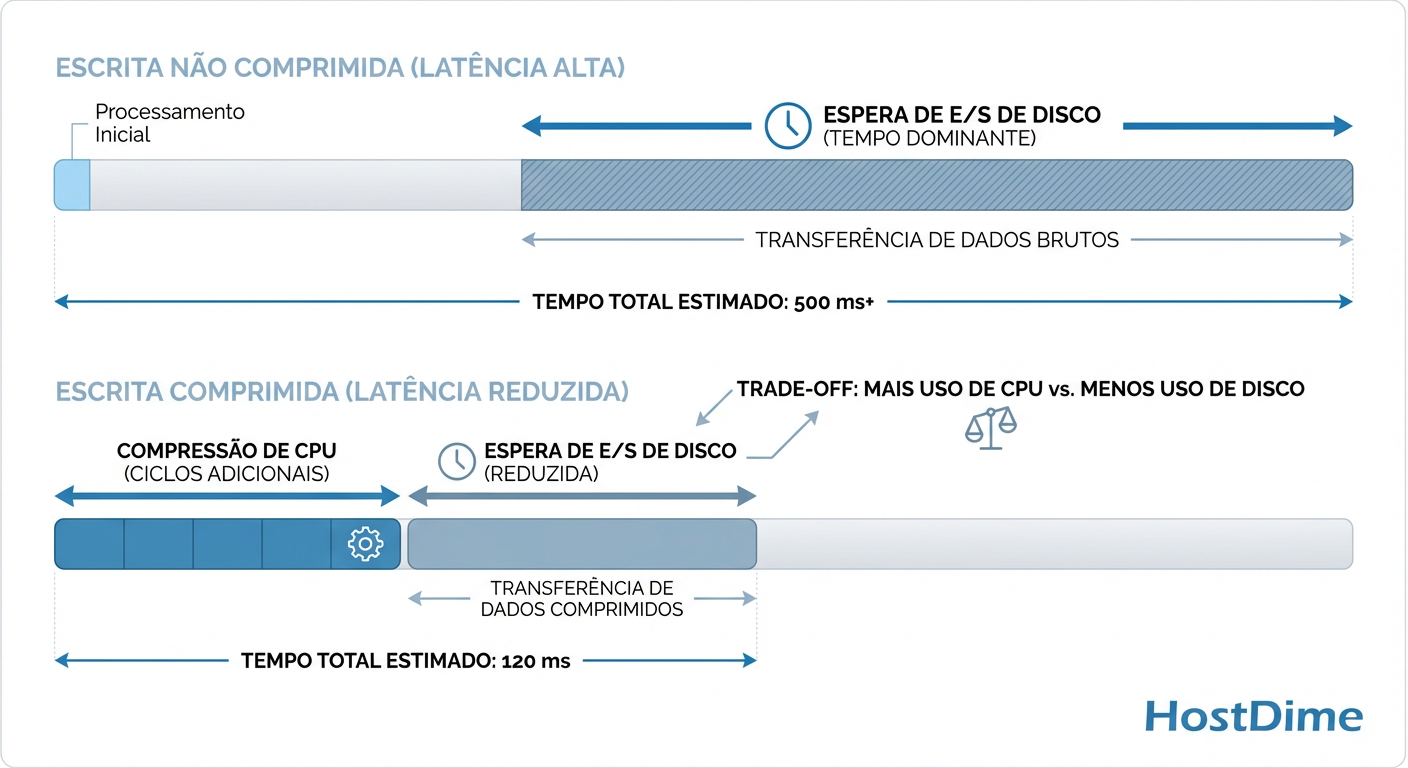 Figura: Trade-off de Latência: Como o custo marginal de CPU reduz o gargalo mecânico do disco.
Figura: Trade-off de Latência: Como o custo marginal de CPU reduz o gargalo mecânico do disco.
Isso resulta em:
Aumento de Throughput: O disco continua escrevendo na mesma velocidade física, mas você está enviando dados mais densos. Se a taxa de compressão for 2x, seu throughput efetivo dobra.
Redução de Latência: Menos dados físicos para escrever significam que a operação de I/O completa retorna mais rápido para a aplicação.
No entanto, essa lógica linear funciona perfeitamente em mirrors (espelhamentos). Quando entramos no território do RAID-Z, a matemática forense fica mais complicada.
Mecânica da Compressão Inline no Pipeline TXG
Diferente de sistemas que comprimem dados "frios" durante a noite, a compressão do ZFS é inline. Ela ocorre no momento em que os dados estão transitando da memória (ARC) para o disco, dentro do contexto de um TXG (Transaction Group).
Quando uma aplicação solicita uma gravação:
O dado entra na RAM (Adaptive Replacement Cache - ARC). O ZFS diz "ok, recebi" (write ack), a menos que seja um sync write (que vai para o ZIL).
O ZFS agrupa essas gravações em um TXG.
O TXG é "fechado" e começa o processo de commit para o disco.
Aqui ocorre a compressão: O ZFS pega o bloco lógico (ex:
recordsize=128k), tenta comprimi-lo.Se a compressão falhar (não economizar pelo menos 12,5% ou 1 setor, dependendo da versão), ele desiste e grava o original. Isso evita gastar CPU em dados incompressíveis (como arquivos .zip ou vídeos criptografados).
O dado comprimido é alocado e escrito.
O ponto crítico aqui é que o ZFS aloca espaço baseado no tamanho comprimido. Isso reduz a fragmentação a longo prazo, mas cria o cenário para o nosso principal suspeito: o problema do alinhamento.
O Problema do Padding no RAID-Z e o Impacto do Ashift
Aqui é onde muitos projetos de storage falham silenciosamente.
O RAID-Z (seja Z1, Z2 ou Z3) não funciona com blocos de tamanho fixo como o RAID 5 tradicional de hardware. Ele usa stripes de largura variável. Cada bloco lógico do ZFS (recordsize) é dividido em colunas de dados e colunas de paridade e espalhado pelos discos.
O problema surge na interação entre três variáveis:
Ashift (Tamanho do Setor Físico): Geralmente 4KB (
ashift=12) em discos modernos.Tamanho do Bloco Comprimido: O tamanho final do dado após passar pelo LZ4.
Número de Discos no VDEV: A geometria do array.
O ZFS precisa alocar dados em múltiplos do ashift. Se um bloco comprimido resulta em 5KB, mas seus setores são de 4KB, o ZFS precisa alocar 8KB (dois setores). Esses 3KB extras são padding (enchimento/lixo).
Em um RAID-Z, isso é agravado. O bloco precisa ser dividido entre os discos de dados + paridade. Se o tamanho comprimido não se alinhar perfeitamente com a geometria do RAID-Z, o sistema insere padding para completar a stripe.
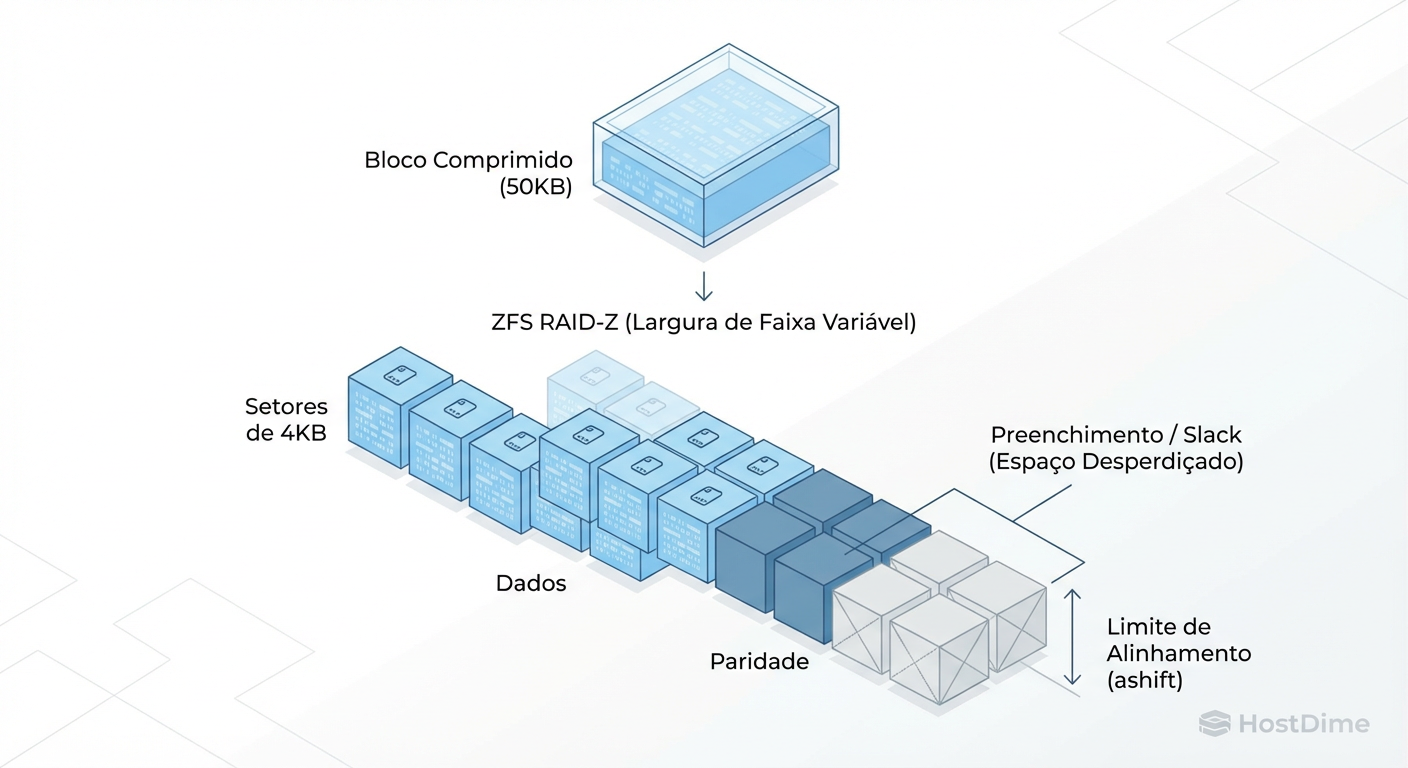 Figura: O Efeito Padding no RAID-Z: Onde a compressão pode perder eficiência devido ao alinhamento de setores (ashift).
Figura: O Efeito Padding no RAID-Z: Onde a compressão pode perder eficiência devido ao alinhamento de setores (ashift).
O Cenário de Risco:
Se você tem um banco de dados com recordsize=8k ou 16k e usa RAID-Z2 ou RAID-Z3 com discos de 4k (ashift=12), a compressão pode reduzir o dado, mas o padding necessário para alinhar a paridade pode fazer com que o espaço físico ocupado seja igual ou até maior do que se não houvesse compressão, desperdiçando ciclos de CPU sem ganho de espaço.
Regra de Ouro Forense: Em VDEVs RAID-Z, evite recordsize pequeno (abaixo de 64k ou 128k). Se precisar de IOPS de bloco pequeno (bancos de dados, VMs), prefira VDEVs do tipo Mirror ou aceite que a compressão pode ser ineficaz no RAID-Z.
Batalha de Algoritmos de Compressão: LZ4 vs ZSTD
A escolha do algoritmo define o equilíbrio entre a carga na CPU e a economia no disco. Não existe "o melhor", existe o adequado para a carga de trabalho.
Tabela Comparativa de Algoritmos ZFS
| Algoritmo | Carga de CPU | Taxa de Compressão | Latência de Descompressão | Cenário Ideal | Risco |
|---|---|---|---|---|---|
| LZ4 | Muito Baixa | Média | Instantânea | Padrão Geral. Use sempre, a menos que tenha um motivo para não usar. | Nenhum. O recurso "early abort" cancela a compressão se não houver ganho. |
| ZSTD (Zstandard) | Média/Alta | Alta | Baixa | Dados "mornos", backups, logs, documentos de texto. | Configurável (zstd-1 a zstd-19). Níveis altos podem saturar a CPU em gravações rápidas. |
| GZIP | Alta | Alta | Média | Legado. Evite. | Lento. Frequentemente se torna o gargalo do sistema. |
| OFF | Nula | Nula | Nula | Dados já comprimidos (H.264, JPEGs, Encrypted Volumes). | Perda de IOPS efetivo (throughput) e cache ARC menos eficiente. |
Análise do ZSTD: O ZSTD (introduzido no OpenZFS 2.0) é o novo concorrente. Ele oferece taxas próximas ao GZIP com velocidade muito superior. No entanto, para cargas de trabalho interativas (VMs, DBs), o LZ4 ainda é rei devido à sua latência de descompressão quase inexistente.
Metodologia de Teste para Validar Ganhos de Throughput
Não adivinhe. Meça. Para validar se a compressão está ajudando ou atrapalhando seu RAID-Z, você precisa isolar o subsistema de disco.
1. Verificando a Eficiência Atual
O primeiro passo é verificar o compressratio. Lembre-se: 1.00x significa zero compressão.
zfs get compressratio,compression tank/dataset
2. Testando Performance Real (IOPS vs Bandwidth)
Não use dd. O dd é single-threaded e enganoso. Use fio.
Abaixo, um teste para simular carga sequencial (onde a compressão brilha no throughput) e aleatória.
Cenário A: Escrita Sequencial Compressível Se a compressão funciona, você verá velocidades de escrita maiores que a velocidade física dos discos.
fio --name=teste_compressao --filename=/tank/dataset/teste.file \
--rw=write --bs=128k --size=10G --numjobs=1 \
--buffer_compress_percentage=50 --buffer_compress_chunk=4k
Nota: O parâmetro --buffer_compress_percentage=50 gera dados que são 50% compressíveis, simulando um cenário real melhor que zeros (100%) ou aleatório puro (0%).
3. Monitoramento em Tempo Real
Enquanto o teste roda, observe o comportamento do pool. O comando zpool iostat é seu estetoscópio.
zpool iostat -r 2
Sinais de Sucesso:
A taxa de escrita lógica (vista pelo
fio) é maior que a taxa de escrita física (vista nozpool iostat).A latência não aumentou desproporcionalmente.
Sinais de Fracasso (O Efeito Padding):
O
compressratioé > 1.20x, mas o espaço ocupado no disco (propriedadeused) não reflete essa economia proporcionalmente.Alta utilização de CPU (sys time) correlacionada com latência de disco, indicando que o algoritmo (talvez um GZIP-9 ou ZSTD alto) está bloqueando o pipeline TXG.
Veredito Forense
A compressão no ZFS não é mágica, é engenharia de trade-offs.
Padrão Seguro: Ative
compression=lz4em quase tudo. O custo de CPU é trivial para CPUs modernas e o ganho de throughput em discos mecânicos é real.O Risco do RAID-Z: Se você usa RAID-Z com
ashift=12, tenha cuidado extremo comrecordsizepequenos (vol-block-size em zvols). O padding vai comer sua economia e performance. Mantenha orecordsizeem 128k ou maior para datasets em RAID-Z.Use ZSTD com Propósito: Use
zstdpara datasets de arquivamento ou diretórios de logs onde a leitura é rara e o espaço é crítico. Não o use para o disco raiz de uma VM de alta performance.
Pense no alinhamento dos blocos. Meça a taxa de compressão. Se os números não baterem, a culpa provavelmente não é do algoritmo, é da geometria do seu array.
Referências & Leitura Complementar
OpenZFS Documentation: Compression Algorithms and Performance Tuning.
Matt Ahrens (ZFS Co-founder): RAID-Z Stripe Width and Padding Overhead Analysis.
RFC 1950/1951/1952: ZLIB Compressed Data Format Specification (Base para entender algoritmos deflate).
Facebook Engineering Blog: Zstandard: A new compression algorithm for real-time scenarios.
FreeBSD Man Pages:
man zfs(Seção sobrerecordsizee interação comashift).

David Ross
Linux Sysadmin Veterano
Vive no terminal. Mantenedor de diversos módulos kernel de storage. Acredita que GUI é bloatware.