ZFS Dedup: A Armadilha da Economia de Espaço (Análise Técnica)

Antes de rodar 'zfs set dedup=on', leia isto. Entenda a Tabela de Deduplicação (DDT), o custo brutal de RAM e por que compressão ZSTD é quase sempre a melhor escolha.
Se existe um recurso no ZFS que já causou mais demissões, noites em claro e migrações de emergência do que qualquer outro, é a Deduplicação.
A promessa de venda é sedutora: "Armazene petabytes de dados usando apenas terabytes de disco físico". O marketing mostra gráficos lindos de economia de espaço. O que eles "esquecem" de colocar no slide é o custo brutal de latência e a exigência de memória RAM que escala de forma impiedosa.
Como veterano de storage, minha postura padrão sobre zfs set dedup=on é simples: Não faça. A menos que você tenha uma planilha de cálculo de IOPS, hardware específico e um orçamento de RAM ilimitado, a deduplicação é um suicídio operacional esperando para acontecer.
Vamos dissecar o porquê, não com medo, mas com a frieza da arquitetura de sistemas.
O Canto da Sereia: Espaço Infinito vs. Latência Real
A deduplicação no ZFS é "in-line". Isso significa que ela acontece em tempo real, no momento em que os dados estão trafegando da memória para o disco. O sistema não grava o dado imediatamente; ele para e pergunta: "Eu já vi esse bloco antes?"
Se a resposta for sim, ele descarta o novo dado e apenas cria um ponteiro para o bloco antigo. Se a resposta for não, ele grava o dado e registra sua "assinatura" (checksum) em uma tabela gigante.
Parece eficiente. Mas em storage, não existe almoço grátis. Você está trocando capacidade de disco (que é barata) por ciclos de CPU e, crucialmente, latência de busca em RAM (que são caros).
A maioria dos administradores ativa o dedup olhando apenas para a economia de espaço. O que você deveria estar olhando é para a latência de gravação.
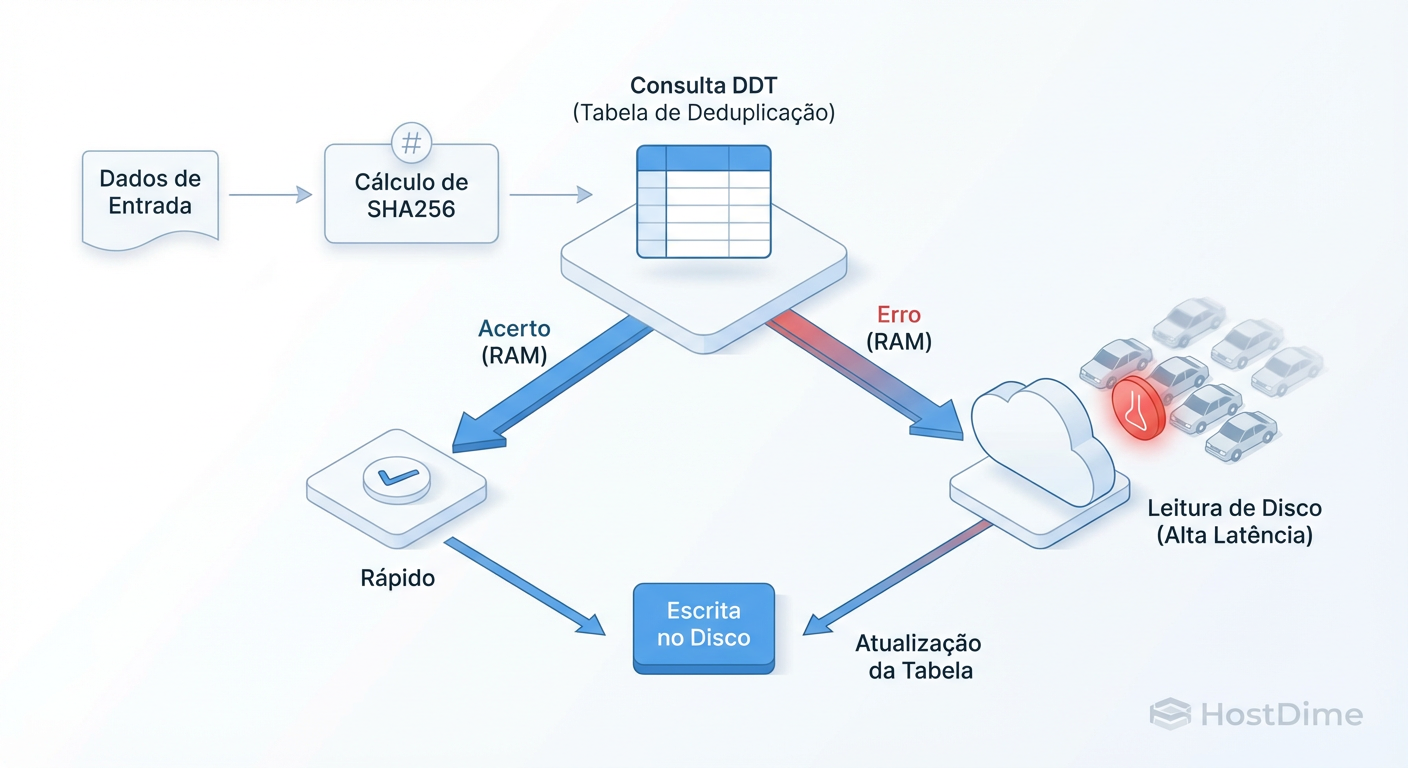 Figura: O Ciclo de Escrita com Dedup: Cada gravação exige uma verificação de existência. Se o DDT não estiver na RAM (ARC), sua latência de escrita dispara porque você precisa ler do disco antes de gravar.
Figura: O Ciclo de Escrita com Dedup: Cada gravação exige uma verificação de existência. Se o DDT não estiver na RAM (ARC), sua latência de escrita dispara porque você precisa ler do disco antes de gravar.
Como ilustrado acima, você transformou uma operação simples de gravação (Write) em uma operação complexa de leitura-verificação-gravação. Se essa verificação for rápida, ótimo. Se não for... bem-vindo ao inferno dos IOPS.
A Tabela de Deduplicação (DDT): O Monstro na RAM
O coração do problema reside na DDT (Deduplication Table). É um hash table global que mapeia o checksum de cada bloco (geralmente SHA-256) para sua localização física no disco.
Para que a deduplicação seja performática, a DDT inteira precisa caber na memória RAM (ARC).
Aqui está a matemática que mata projetos: Cada entrada na DDT consome cerca de 320 a 400 bytes de RAM (dependendo da versão do ZFS e metadados). Isso parece pouco? Vamos escalar.
Se você usa o recordsize padrão de 128K, um 1TB de dados únicos gera cerca de 8 milhões de blocos.
8.000.000 * 400 bytes ≈ 3.2 GB de RAM apenas para a tabela.
Agora, imagine que você configurou um servidor de arquivos com blocos pequenos (4K ou 8K) para bancos de dados ou VMs, e você tem 10TB de dados.
10TB em blocos de 8K = ~1.3 bilhão de blocos.
1.300.000.000 * 400 bytes ≈ 520 GB de RAM.
Você tem meio terabyte de RAM livre apenas para manter o índice dos seus dados? Provavelmente não. E lembre-se: isso compete com o cache de leitura normal (ARC) e com o sistema operacional.
O "Performance Cliff": Quando a DDT vai para o Disco
O momento em que a DDT não cabe mais na RAM é chamado de "Performance Cliff" (O Abismo de Performance). Não é uma degradação gradual; é uma parede de tijolos.
Quando o ZFS precisa verificar se um bloco existe e a DDT não está na memória, ele precisa ler a DDT do disco.
O ZFS calcula o hash do dado que chega.
Ele busca esse hash na DDT.
Cache Miss: A parte da DDT necessária está no disco.
O ZFS emite uma leitura aleatória (Random Read) para buscar o índice.
Só depois ele decide se grava ou não.
Se você estiver usando discos mecânicos (HDDs), cada disco entrega cerca de 100-150 IOPS. Uma única gravação com dedup ativado pode gerar 1 a 3 leituras aleatórias de metadados.
Resultado: Um pool capaz de gravar a 500 MB/s cai repentinamente para 5 MB/s. O load average do servidor dispara, o iowait bate no teto e as aplicações travam por timeout. O sistema entra em thrashing, gastando mais tempo buscando metadados do que movendo dados reais.
O Custo Oculto da Deleção
Muitos administradores pensam: "Ok, ativei o dedup, o servidor ficou lento. Vou apagar alguns dados para aliviar."
Surpresa: Apagar dados deduplicados é excruciantemente lento.
Quando você deleta um arquivo normal, o ZFS apenas marca os blocos como livres. Com dedup, para cada bloco "deletado", o ZFS precisa:
Ir na DDT.
Verificar a contagem de referências (refcount).
Decrementar a contagem.
Se (e somente se) a contagem chegar a zero, liberar o bloco.
Se a sua DDT estiver no disco (o cenário de lentidão que fez você querer apagar dados), cada bloco a ser removido exige leituras aleatórias para atualizar a tabela.
Eu já vi processos de rm -rf em datasets deduplicados de 20TB levarem semanas para concluir, mantendo o pool 100% ocupado durante todo o processo. É uma armadilha onde a porta de saída é tão estreita quanto a entrada.
Compressão (ZSTD) vs. Dedup: Pragmatismo Vence
Antes de sequer cogitar a deduplicação, você deve exaurir as possibilidades da compressão transparente.
Diferente do dedup, a compressão moderna (especialmente LZ4 e o mais recente ZSTD) é extremamente barata. CPUs modernas ficam ociosas esperando o disco; a compressão utiliza esses ciclos ociosos para aumentar a performance efetiva (escrevendo menos dados físicos no disco).
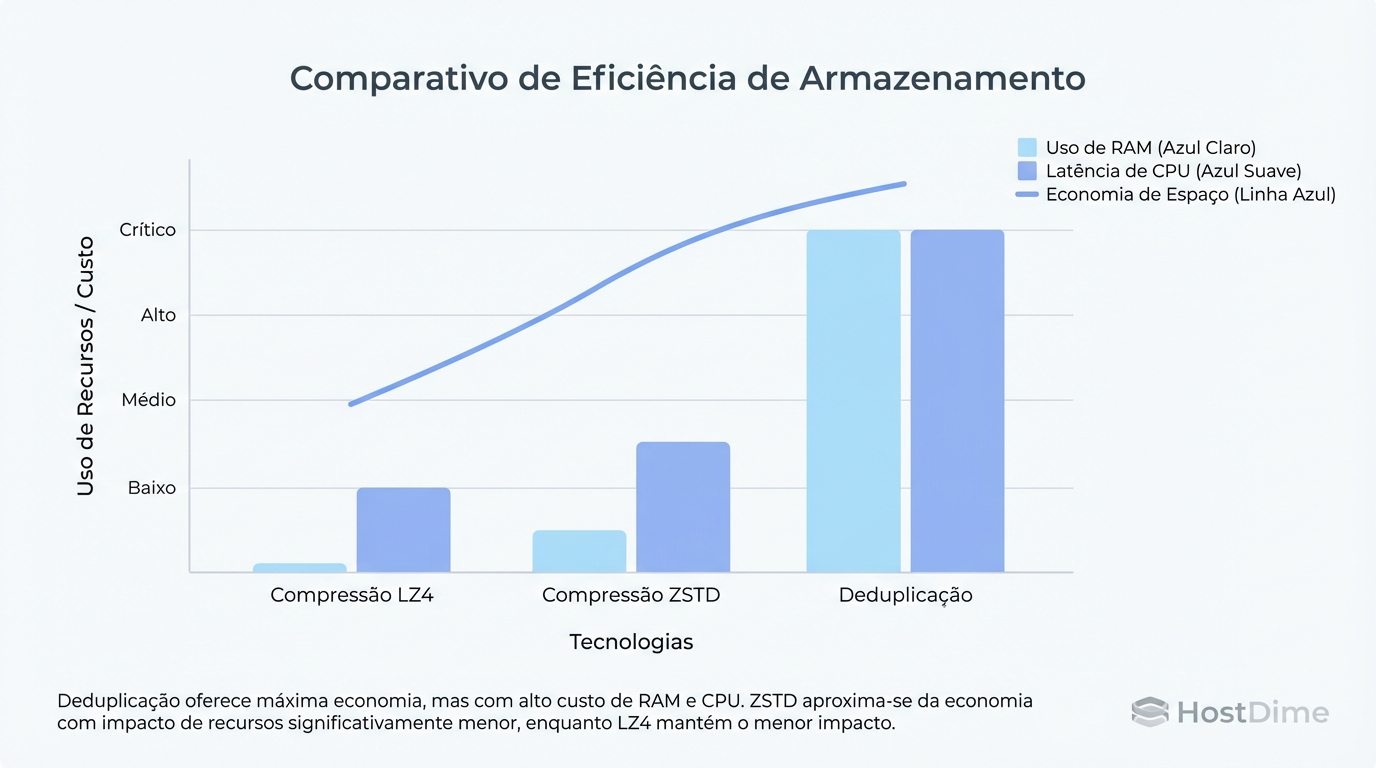 Figura: Custo vs. Benefício: Enquanto a compressão moderna (ZSTD) oferece ganhos de espaço significativos com custo computacional linear, a deduplicação impõe uma 'taxa de RAM' exponencial.
Figura: Custo vs. Benefício: Enquanto a compressão moderna (ZSTD) oferece ganhos de espaço significativos com custo computacional linear, a deduplicação impõe uma 'taxa de RAM' exponencial.
A regra de ouro do Sysadmin Pragmático:
LZ4: Padrão para tudo. Custo de CPU quase nulo.
ZSTD (nível 3 a 9): Para dados altamente compressíveis (logs, texto, dumps de banco). Oferece taxas de compressão que muitas vezes rivalizam com a deduplicação, sem o custo de RAM da DDT.
Se o ZSTD-3 reduzir seus dados em 2:1 e o Dedup reduzir em 3:1, a vitória é do ZSTD. A economia extra de espaço do dedup não paga o custo do hardware necessário para mantê-lo rodando.
O Cenário de Exceção: Onde o Dedup Funciona
Eu disse para não usar. Mas existem exceções, desde que você projete o hardware para isso. O Dedup pode funcionar se você garantir que a DDT nunca toque em discos lentos.
O Checklist da Exceção:
All-Flash: O pool inteiro é SSD/NVMe. A latência de busca aleatória é baixa o suficiente para mascarar misses na DDT.
Special VDEVs (Allocation Classes): Esta é a "bala de prata" moderna do ZFS (OpenZFS 2.0+). Você pode adicionar espelhos de NVMe dedicados exclusivamente para metadados e DDT.
# Exemplo conceitual (não execute sem planejar) zpool add tank special mirror /dev/nvme0n1 /dev/nvme1n1Isso força a tabela de deduplicação a viver no armazenamento mais rápido, segregada dos dados brutos.
Carga de Trabalho VDI: O único caso de uso onde a economia é astronômica (10:1 ou mais). Se você hospeda 500 clones da mesma imagem do Windows, o dedup é justificável.
Para verificar se o seu sofrimento atual vale a pena, use o comando abaixo e olhe a coluna dedup:
zpool list
# NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
# tank 10T 5.00T 5.00T - - 5% 50% 1.02x ONLINE -
Se o seu ratio for 1.02x (como acima), você está queimando RAM e CPU por 2% de espaço. Desligue imediatamente. Se for 10.5x, talvez o custo se justifique.
Plano de Fuga: Você ativou e se arrependeu. E agora?
Aqui está a dura verdade operacional: Desativar a deduplicação não "re-hidrata" os dados.
Ao rodar:
zfs set dedup=off tank/dataset
Você apenas diz ao ZFS: "Pare de tentar deduplicar novas gravações". Os dados antigos continuam deduplicados, a DDT continua existindo e ocupando espaço na RAM ou disco, e as deleções continuam lentas.
A única maneira de se livrar de uma DDT existente é reescrever os dados.
Você precisará:
Criar um novo dataset (ou ter outro pool).
Garantir que o destino tenha
dedup=off.Mover os dados usando
zfs send | zfs recvou ferramentas comorsync.Destruir o dataset original amaldiçoado.
Isso exige espaço livre temporário igual ao tamanho real (não deduplicado) dos seus dados. Se você ativou o dedup porque estava sem espaço... bem, você está em uma situação delicada (um "deadlock" físico).
Conclusão: O ZFS Dedup é uma ferramenta de precisão para cenários de nicho, não um botão mágico de "ganhar espaço". Na dúvida, compre mais discos. É mais barato que a RAM necessária para o dedup e infinitamente mais barato que o seu tempo gasto resolvendo problemas de performance.

Julia M. Santos
Enterprise Storage Consultant
Consultora para Fortune 500. Traduz 'economês' para 'técniquês' e ajuda empresas a não gastarem milhões em SANs desnecessárias.