ZFS no Proxmox: O Duelo recordsize vs volblocksize (O Fim do Write Amplification)
Pare de matar seus SSDs. Entenda a matemática entre o bloco do ZFS e a sua VM, elimine o Read-Modify-Write e otimize databases no Proxmox.
Você investiu em NVMe Enterprise, configurou uma CPU robusta e memórias ECC. Ainda assim, seu banco de dados no Proxmox engasga sob carga e o espaço em disco está desaparecendo mais rápido do que a matemática sugere. O culpado raramente é o hardware; é a geometria.
No mundo do ZFS, especialmente sob virtualização (Proxmox), existe uma guerra silenciosa entre como a aplicação pensa que está gravando e como o disco realmente grava. Se esses dois mundos não estiverem alinhados, você cai no abismo do Write Amplification (Amplificação de Escrita).
Vamos dissecar a anatomia desse problema e, mais importante, como resolvê-lo arquitetando a solução correta, não seguindo tutoriais cegos.
O Conceito: Dataset vs. Zvol
Antes de ajustar qualquer botão, você precisa entender onde seus dados vivem. O Proxmox trata Containers (LXC) e Máquinas Virtuais (KVM/QEMU) de formas fundamentalmente diferentes no ZFS.
1. LXC usa Datasets (recordsize)
Um container LXC acessa o sistema de arquivos diretamente. Ele enxerga o ZFS. Aqui, o parâmetro rei é o recordsize.
- Natureza: Dinâmica. O
recordsizedefine o tamanho máximo do bloco. Se você gravar um arquivo de 4k e orecordsizefor 128k, o ZFS gravará apenas um setor de 4k (mais metadados). Ele se adapta.
2. VM usa Zvols (volblocksize)
Uma VM precisa de um dispositivo de bloco bruto para formatar com EXT4, XFS ou NTFS. O ZFS entrega isso via Zvol. Aqui, o parâmetro rei é o volblocksize.
- Natureza: Estática e Rígida. O
volblocksizeé a geometria física emulada. Se ele for definido como 8k, toda gravação será um múltiplo de 8k. Não há adaptação.
O Ponto Crítico: A maioria dos problemas de performance em Proxmox ocorre em VMs (Zvols) porque a rigidez do
volblocksizenão perdoa desalinhamentos.
O Ciclo da Morte: Read-Modify-Write (RMW)
O ZFS é um sistema de arquivos Copy-on-Write (CoW) e transacional. Ele nunca sobrescreve dados no lugar; ele grava novos dados e atualiza os ponteiros. Além disso, ele calcula checksums por bloco.
Imagine que você tem uma VM rodando um banco de dados.
Configuração: O
volblocksizedo Zvol no Proxmox é 16k.Ação: O banco de dados (dentro da VM) quer alterar apenas 4k de dados.
O ZFS não pode simplesmente "injetar" esses 4k no bloco de 16k, pois isso invalidaria o checksum do bloco inteiro. O que acontece nos bastidores é trágico:
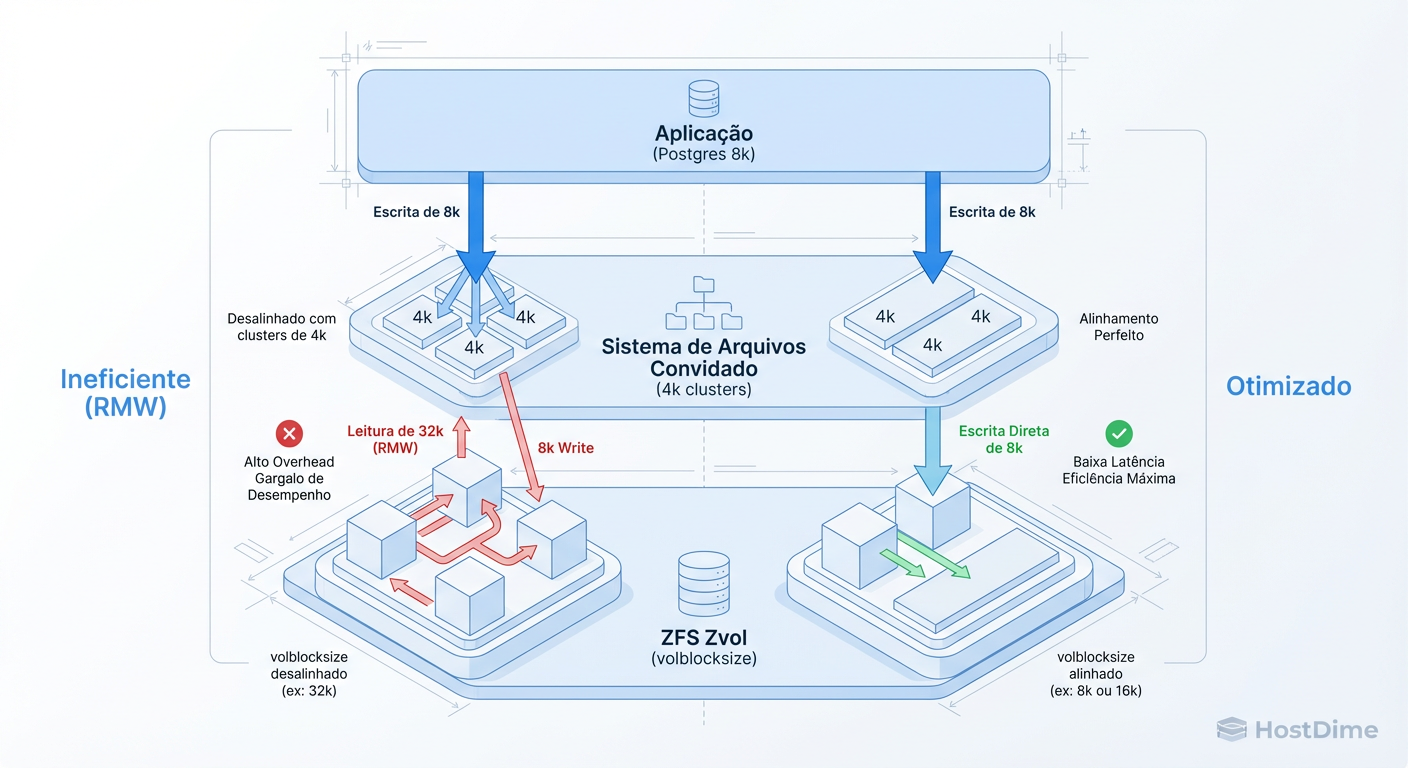 Figura: O Custo Invisível: Como o desalinhamento de blocos força o ZFS a ler antes de gravar (Read-Modify-Write).
Figura: O Custo Invisível: Como o desalinhamento de blocos força o ZFS a ler antes de gravar (Read-Modify-Write).
O ZFS é forçado a:
Ler o bloco inteiro de 16k do disco.
Modificar os 4k na memória.
Calcular o novo checksum.
Gravar o novo bloco de 16k.
Você queria fazer uma escrita pequena. O sistema fez uma leitura e uma escrita maior. Sua latência dobrou (ou triplicou) e seus IOPS efetivos caíram pela metade. Isso é o Read-Modify-Write.
A Matemática do Alinhamento
Para eliminar o RMW, precisamos alinhar a pilha inteira. O tamanho da escrita deve ser igual ou múltiplo do tamanho do bloco do ZFS.
A cadeia de comando é: Aplicação (Page Size) ➤ Guest OS (Cluster Size) ➤ Hypervisor (Volblocksize) ➤ Mídia Física (Ashift).
O Cenário Ideal
Se o PostgreSQL escreve páginas de 8k, o sistema de arquivos da VM (ex: EXT4) deve usar blocos de 4k (padrão), e o Zvol deve ter volblocksize=8k.
O Postgres envia 8k.
O ZFS recebe 8k.
O Zvol tem blocos de 8k.
Resultado: O ZFS simplesmente grava. Sem leitura prévia. Latência mínima.
O Cenário Comum (Desastre)
MySQL (InnoDB) escreve páginas de 16k.
Usuário configurou o Zvol com padrão antigo (8k).
Resultado: Cada escrita do MySQL gera duas operações de bloco no ZFS. Dobro de metadados, dobro de IOPS consumidos.
A Armadilha do RAID-Z: Padding e Espaço Perdido
Se você usa espelhamento (Mirrors/RAID-10), o desalinhamento custa performance. Se você usa RAID-Z (RAID-5/6), o desalinhamento custa espaço brutal e performance.
O RAID-Z não tem blocos de paridade fixos como o RAID-5 tradicional. Ele espalha dados e paridade dinamicamente. No entanto, ele precisa respeitar o ashift (tamanho do setor físico do disco, geralmente 4k) e o alinhamento das colunas.
Quando você usa um volblocksize pequeno (ex: 8k ou 16k) em um RAID-Z largo (ex: 6 discos em RAID-Z2), o ZFS precisa adicionar "padding" (espaço vazio) para alinhar matematicamente a paridade aos setores físicos.
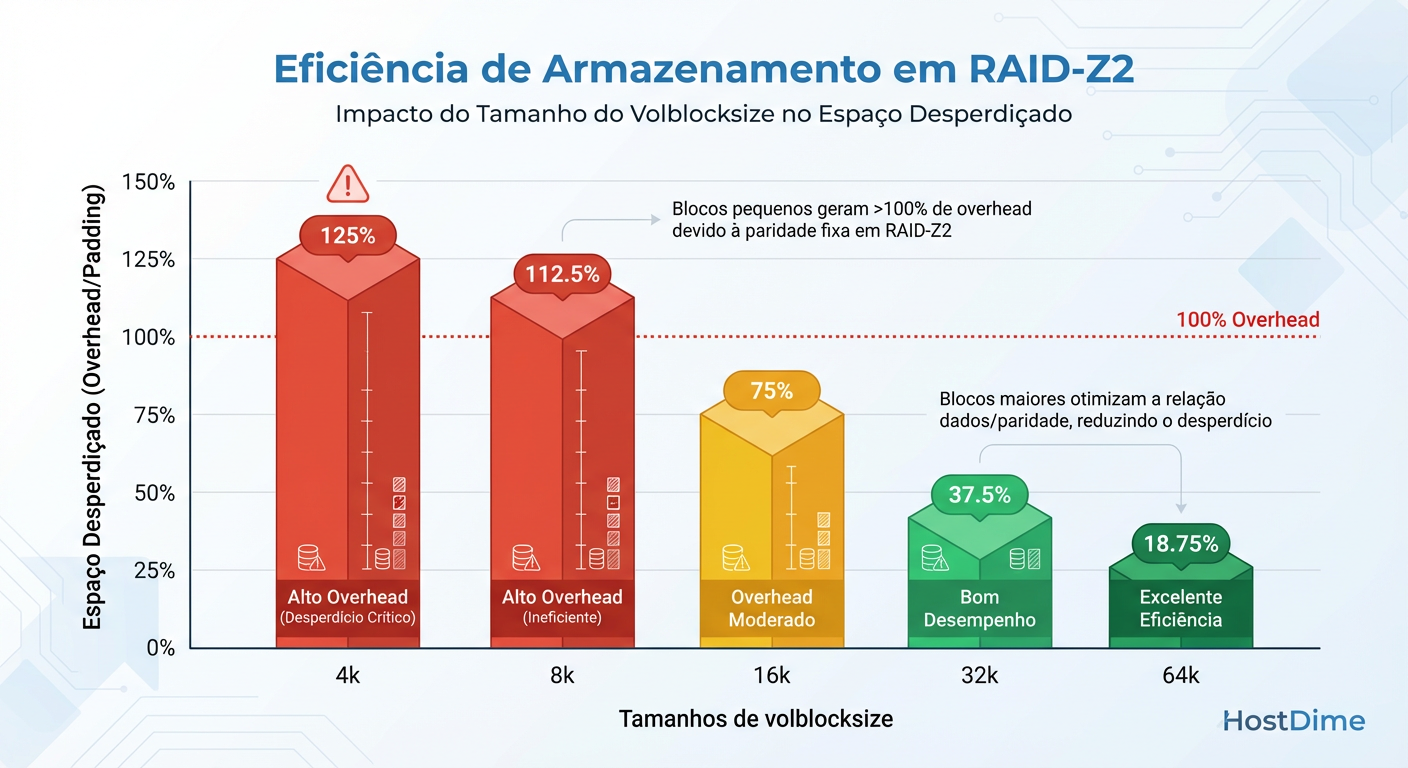 Figura: A Ilusão do Espaço: Por que usar volblocksize pequeno em RAID-Z destrói sua capacidade útil.
Figura: A Ilusão do Espaço: Por que usar volblocksize pequeno em RAID-Z destrói sua capacidade útil.
Tabela de Eficiência do Terror
Considere um RAID-Z2 (pense nisso como RAID-6) com discos de setor 4k (ashift=12).
| Volblocksize | Espaço Perdido (Padding + Paridade) | Eficiência Real |
|---|---|---|
| 8k | ~50% a 66% | Péssima |
| 16k | ~30% a 50% | Ruim |
| 64k | ~10% a 20% | Aceitável |
| 128k | < 5% | Ótima |
Trade-off Arquitetural: Para VMs em produção no Proxmox, evite RAID-Z se possível. Use Mirrors (RAID-10). Se você precisa usar RAID-Z para VMs (por custo), você deve aumentar o
volblocksizepara pelo menos 64k, aceitando que isso pode causar algum RMW em bancos de dados pequenos, mas salvará terabytes de espaço em disco.
Otimizando na Prática: PostgreSQL e MySQL
Não existe "melhor configuração". Existe a configuração que casa com sua carga de trabalho. Aqui está o guia de sobrevivência para bancos de dados em Zvols (VMs).
1. PostgreSQL
O Postgres usa uma página padrão de 8k.
Recomendação: Defina
volblocksize=8k.Por quê? Garante alinhamento 1:1.
Atenção: Se usar compressão (LZ4/ZSTD), o ZFS tentará comprimir esses 8k. Se o bloco comprimido não for menor que 8k (e alinhado ao ashift), ele não economiza espaço. Mas a performance será estelar.
2. MySQL / MariaDB (InnoDB)
O InnoDB usa uma página padrão de 16k.
Recomendação: Defina
volblocksize=16k.Por quê? Evita que uma escrita atômica do banco seja dividida em dois blocos de 8k (o que dobraria os IOPS de escrita).
3. Servidores de Arquivos (Windows/Samba em VM)
Arquivos gerais variam muito. O NTFS tem cluster de 4k.
Recomendação:
volblocksize=32ka64k.Por quê? Um meio-termo. Blocos muito pequenos (4k/8k) aumentam drasticamente a quantidade de metadados que o ZFS precisa gerenciar, consumindo RAM (ARC) e CPU. Blocos maiores favorecem a compressão e o throughput sequencial.
Como Medir: Evidência sobre Suposição
Não confie na minha palavra. Meça o seu sistema. O comando zpool iostat é seu melhor amigo, mas precisamos de flags específicas para ver a latência e o tamanho das requisições.
Verificando o Tamanho das Escritas
Execute este comando enquanto sua carga de trabalho roda. Ele mostra a distribuição do tamanho das requisições.
# Observe as colunas de tamanho (req_size)
zpool iostat -r 5
Se você vir muitas operações na coluna de 4k ou 8k (colunas da esquerda), mas seu volblocksize é 64k, você está sofrendo de RMW massivo.
Verificando Latência Real
Para ver se o disco está demorando para responder (sintoma de RMW ou saturação):
# -w mostra latência, -l mostra filas
zpool iostat -w -l 5
O Teste da Verdade (Dataset vs Zvol)
Se você tem dúvida se deve usar LXC ou VM para um banco de dados, faça este teste simples:
Crie um Dataset com
recordsize=8k(para Postgres).Crie um Zvol com
volblocksize=8k.Rode o
pgbenchem ambos.
Em 90% dos casos, o Dataset (LXC) vencerá por eliminar a camada de tradução do sistema de arquivos do Guest. Mas se você precisa de isolamento de VM, o Zvol alinhado é a única saída.
Veredito Técnico: A Regra de Ouro
O ZFS é uma ferramenta de precisão, não um martelo. No Proxmox:
Use Mirrors (RAID-10) para VMs sempre que o orçamento permitir. Isso elimina a complexidade do padding do RAID-Z.
Alinhe o
volblocksizeà aplicação mais crítica dentro da VM (8k para Postgres, 16k para MySQL).Use
recordsize=1Mpara Datasets de backup ou servidores de arquivos grandes (LXC) para maximizar compressão e throughput.
Performance de storage não é mágica; é evitar que o sistema trabalhe mais do que o necessário. Alinhe seus blocos e pare de desperdiçar IOPS.

Elena Kovacs
Arquiteta de Cloud Infrastructure
Focada em NVMe-oF e storage definido por software. Projeta clusters de petabytes para grandes provedores de nuvem.