ZFS Send/Receive: A Anatomia da Migração (Quase) Instantânea

Esqueça o rsync. Entenda como o ZFS serializa blocos para migrações de petabytes com janela de manutenção de segundos. O guia de engenharia para replicação.
Se você já tentou migrar 10 terabytes compostos por milhões de pequenos arquivos usando rsync, você conhece o desespero. Você observa o cursor piscar enquanto o sistema operacional luta para fazer stat() em cada inode, saturando os IOPS de leitura muito antes de transferir o primeiro byte de dados.
A maioria das ferramentas de sincronização opera na camada do sistema de arquivos (File-Level). Elas são "cegas" para a estrutura subjacente do disco e precisam perguntar ao kernel: "O que mudou?".
O ZFS opera de forma diferente. Ele não precisa perguntar o que mudou; ele é o registro do que mudou. Ao utilizar zfs send e zfs receive, não estamos copiando arquivos. Estamos serializando transações de blocos e transmitindo a estrutura da árvore de dados.
Este artigo disseca a mecânica dessa operação, como medir seus gargalos e como evitar que uma migração mal planejada derrube sua infraestrutura de produção.
O Abismo entre File-Walking e Block-Streaming
Para entender a performance, precisamos isolar o método de descoberta de dados.
No modelo tradicional (rsync, robocopy, tar), o custo da descoberta é O(n), onde n é o número de arquivos. O sistema precisa percorrer a árvore de diretórios, ler metadados e comparar timestamps ou checksums. Em storage de alta densidade, a latência de busca de metadados (metadata lookup latency) é o assassino silencioso da performance. O disco passa mais tempo buscando cabeçotes (em HDDs) ou processando filas de comandos aleatórios (em SSDs) do que movendo dados.
O ZFS transforma esse problema. Como um sistema de arquivos Copy-on-Write (CoW), o ZFS nunca sobrescreve dados "in-place". Novos dados são escritos em novos blocos, e o ponteiro do metadado é atualizado atomicamente.
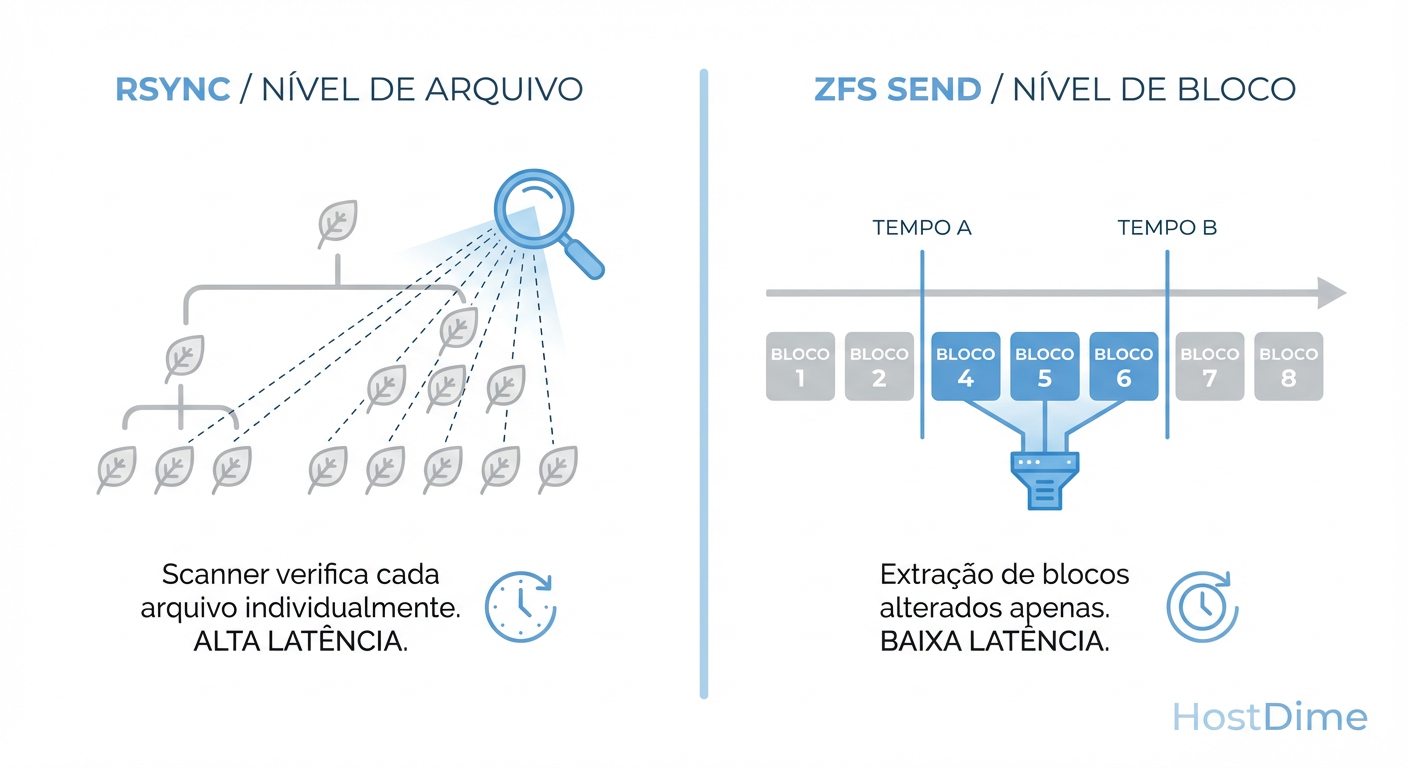 Figura: A diferença de O(n) para O(1): Enquanto ferramentas tradicionais 'perguntam' arquivo por arquivo o que mudou, o ZFS consulta a árvore de blocos baseada no tempo de nascimento (TXG).
Figura: A diferença de O(n) para O(1): Enquanto ferramentas tradicionais 'perguntam' arquivo por arquivo o que mudou, o ZFS consulta a árvore de blocos baseada no tempo de nascimento (TXG).
Isso significa que o ZFS possui um índice temporal intrínseco. Quando solicitamos um stream incremental entre o Snapshot A e o Snapshot B, o ZFS não varre o sistema de arquivos. Ele consulta a árvore de blocos e ignora qualquer bloco cujo "tempo de nascimento" (birth time) seja anterior à criação do Snapshot A.
O resultado é que o tempo de preparação para o envio de um diferencial é proporcional à quantidade de dados alterados, não ao tamanho total do dataset. É a diferença entre esperar 4 horas para o rsync começar a copiar e o zfs send começar a transmitir instantaneamente.
A Física do Stream: Transaction Groups (TXGs)
O que exatamente trafega pelo "cano" quando você executa um zfs send?
Não é um arquivo zip. É um fluxo serializado de registros de objetos (dnodes) e blocos de dados, organizados por Transaction Groups (TXGs).
Cada vez que o ZFS confirma escritas no disco (normalmente a cada 5 segundos por padrão), ele fecha um TXG. O stream de envio é, essencialmente, a reprodução desses TXGs no sistema de destino. Isso garante consistência transacional. O lado receptor (zfs receive) não vê um arquivo "pela metade". Ou a transação inteira é aplicada, ou nada é.
Isso elimina a necessidade de file locking. Você pode enviar um dataset de um banco de dados em produção (desde que tenha feito um snapshot atômico) sem parar o banco, e o destino receberá uma cópia consistente crash-consistent daquele exato milissegundo.
A Coreografia da Migração Live
Em cenários de produção, o objetivo é minimizar o RPO (Recovery Point Objective) e o RTO (Recovery Time Objective). A migração "quase" instantânea baseia-se em reduzir a janela de delta.
A metodologia correta segue este algoritmo:
Snapshot Inicial (Base): Criar
@migracao_inicio.Envio Full: Transferir todo o dataset. O sistema de origem continua operando e acumulando novos dados (divergência).
Snapshots Incrementais (Catch-up): Criar
@inc_1, enviar a diferença entre@migracao_inicioe@inc_1. Repetir conforme necessário para reduzir o delta.Janela de Corte (Cutover):
- Parar a aplicação/serviço na origem (quiesce).
- Criar Snapshot Final
@final. - Enviar o incremental (
-i @inc_N @final). Como o delta é pequeno (apenas os dados escritos desde o último sync), isso leva segundos. - Subir a aplicação no destino.
Este processo transforma uma janela de manutenção de horas (cópia total) em minutos ou segundos (cópia do último delta).
O Gargalo Invisível: TCP, SSH e Buffers
Aqui é onde a teoria encontra a realidade física da rede. Um erro comum de engenharia é assumir que zfs send | ssh host zfs receive utilizará toda a banda de um link de 10GbE. Raramente utiliza.
Existem dois culpados principais:
Overhead de Criptografia (CPU Bound): O SSH é single-threaded por conexão. Em redes rápidas, um único núcleo da CPU pode saturar tentando criptografar/descriptografar o stream (frequentemente limitando-se a ~150-300 MB/s dependendo do clock da CPU), deixando o link de 10GbE 80% ocioso.
Oscilação do TCP (Windowing): O
zfs sendproduz dados em rajadas (bursts). Ozfs receivegrava em rajadas (sync writes). Se o pipe TCP esvaziar ou encher demais, a transmissão para e espera (TCP window collapse).
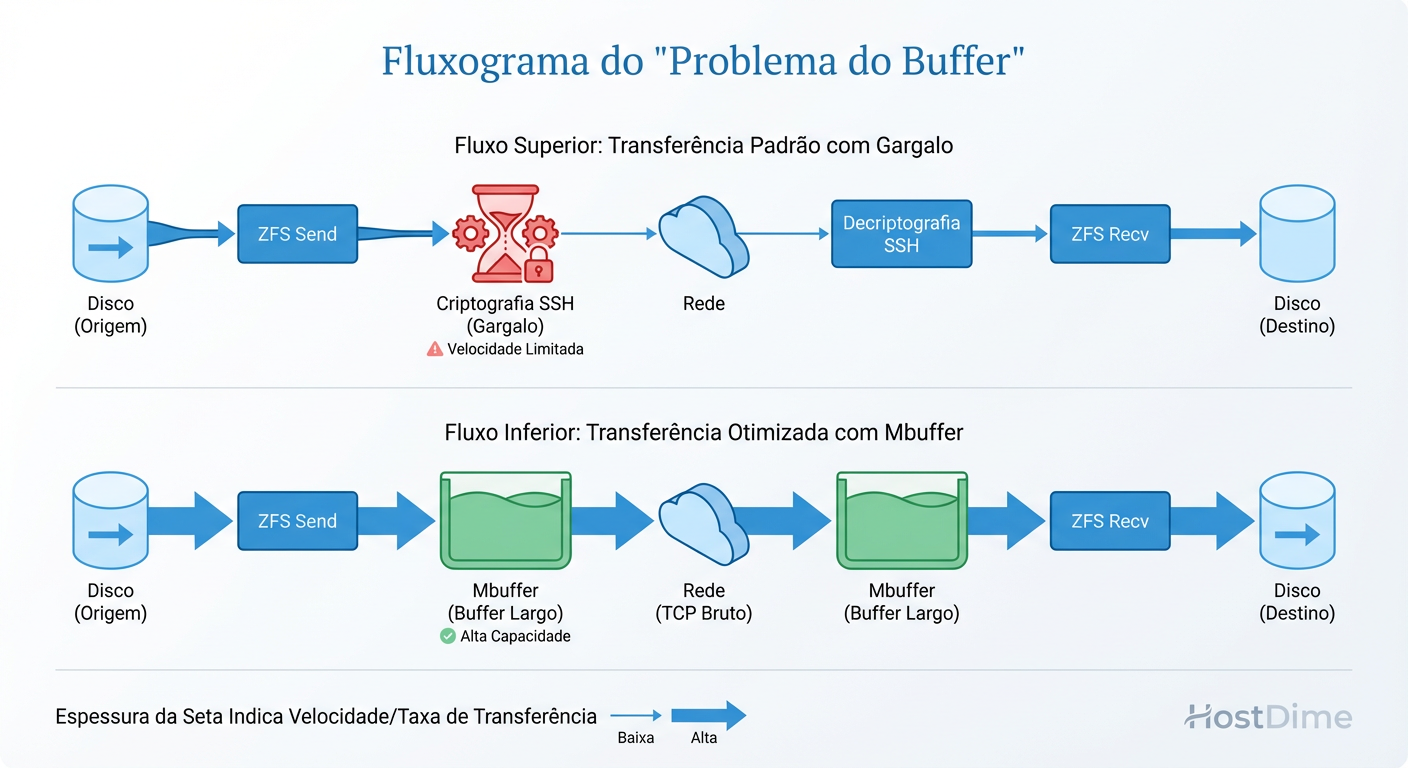 Figura: Otimização de Transporte: O SSH é frequentemente o gargalo da CPU em redes de 10GbE+. O uso de buffers intermediários (mbuffer) e transporte raw (netcat) desacopla a leitura da escrita.
Figura: Otimização de Transporte: O SSH é frequentemente o gargalo da CPU em redes de 10GbE+. O uso de buffers intermediários (mbuffer) e transporte raw (netcat) desacopla a leitura da escrita.
A Solução: mbuffer e Transporte Raw
Para resolver a oscilação, precisamos desacoplar a geração do stream da transmissão da rede. O mbuffer atua como um tanque de compensação, mantendo a rede saturada mesmo se o disco engasgar momentaneamente, e vice-versa.
Para resolver o gargalo da CPU do SSH, em redes confiáveis (como uma cross-connect de datacenter ou VPN segura), usar netcat (nc) é ordens de magnitude mais rápido. Se a segurança for mandatória, utilize cifras mais leves no SSH (como [email protected] ou chacha20-poly1305) ou, idealmente, use o recurso ZFS Raw Send (explicado abaixo) que torna a criptografia de transporte redundante.
Anatomia de um Comando Robusto
Evite comandos simplistas em produção. Um comando de engenharia robusto deve prever falhas de rede, preservar propriedades e otimizar o fluxo.
Flags Essenciais
-w(Raw Send): A "bala de prata". Se o seu dataset de origem é criptografado nativamente pelo ZFS, o-wenvia os blocos ainda criptografados.- Por que usar: O servidor de origem não gasta CPU descriptografando e o de destino não gasta CPU re-criptografando. O dado trafega seguro pela rede sem necessidade de SSH pesado. A chave de criptografia não precisa nem estar carregada no destino.
-R(Replication): Envia recursivamente todos os datasets filhos e, crucialmente, suas propriedades (compressão, quotas, pontos de montagem).-s(Resume Token): Se a conexão cair aos 95% de 10TB, o ZFS salva um token. Você pode retomar a transferência exatamente de onde parou, sem recomeçar do zero.
O Comando de Produção
Abaixo, um exemplo de pipeline otimizado para uma migração crítica via SSH, usando mbuffer para suavizar o fluxo e Resume Tokens para segurança:
# NA ORIGEM (PUSH)
# -w: raw send (mantém criptografia)
# -R: replicação recursiva
# -s: habilita resume token
# mbuffer: buffer de 1GB para absorver latência
zfs send -w -R -s pool/dataset@snap_final | \
mbuffer -s 128k -m 1G | \
ssh root@destino "mbuffer -s 128k -m 1G | zfs receive -F pool_destino/dataset"
Nota: O -F no receive força o rollback do sistema de destino para o estado inicial da transferência, útil se uma tentativa anterior falhou e deixou o dataset "sujo". Use com cautela.
Cenários de Risco: Onde a Migração Falha
Mesmo com a ferramenta certa, a física do storage impõe limites.
1. O Pesadelo da Deduplicação (Dedup)
Se o pool de destino tiver dedup=on, sua migração vai colidir com uma parede. Cada bloco recebido exigirá uma consulta na Tabela de Deduplicação (DDT). Se a DDT não couber na RAM (ARC), o disco fará leituras aleatórias para cada escrita sequencial do stream. A performance cairá de 500MB/s para 5MB/s.
Regra: Desligue o dedup no destino ou garanta RAM massiva.
2. Mismatch de Recordsize
Se você enviar um stream gerado com recordsize=128k (padrão) para um dataset que você gostaria que fosse recordsize=1M (banco de dados), o zfs receive respeitará o tamanho do bloco do stream original (a menos que seja forçado ou reescrito). O stream carrega a geometria dos dados. Para alterar o recordsize na migração, você não pode usar o stream raw; os dados devem ser reprocessados, o que aumenta a carga de CPU.
3. Fragmentação Oculta
Um stream de zfs send é linear. Quando o zfs receive escreve isso no disco, ele tenta fazer de forma sequencial. Isso geralmente resulta em um dataset menos fragmentado no destino do que na origem. No entanto, se o pool de destino estiver 90% cheio, o ZFS terá que lutar para encontrar blocos livres, transformando uma escrita sequencial (rápida) em aleatória (lenta).
Veredito Técnico
O zfs send/receive não é apenas uma ferramenta de cópia; é uma extensão da arquitetura transacional do ZFS. Ao entender que estamos movendo ponteiros e blocos baseados no tempo (TXGs), e não arquivos, podemos arquitetar migrações de petabytes com janelas de corte insignificantes.
O segredo não está no comando em si, mas em tratar o fluxo de dados como um problema de engenharia hidráulica: remova as constrições (SSH), adicione reservatórios (mbuffer) e garanta que o cano de destino suporte a pressão.

Marta G. Oliveira
DevOps Engineer & Storage Nerd
Automatiza provisionamento de storage com Terraform e Ansible. Defensora do 'Infrastructure as Code' para storage.