ZFS Snapshots: O Poder do 'Undo' e a Armadilha da Fragmentação
Snapshots são instantâneos, mas não são grátis. Entenda a física do Copy-on-Write, o pesadelo do espaço retido e como evitar que seu pool sufoque.
Você chega na cena do crime. O servidor de arquivos está lento, arrastando-se como se estivesse rodando em hardware de 1998. O disco reporta 80% de ocupação, mas os usuários juram que apagaram terabytes de dados na semana passada. O administrador anterior configurou snapshots automáticos a cada 15 minutos e foi embora, achando que tinha criado a estratégia de backup perfeita.
Ele não criou um backup. Ele criou uma bomba-relógio de metadados.
Como investigador forense de sistemas, aprendi que "o que você vê" no ZFS raramente é o que o disco está realmente fazendo. Snapshots são vendidos como mágicos — "custo zero", "instantâneos", "infinitos". Mas na física do armazenamento, não existe almoço grátis. Existe apenas entropia adiada.
Vamos dissecar a anatomia de um snapshot, entender por que seu espaço em disco não volta e como essa funcionalidade incrível pode triturar a performance de leitura se você não respeitar as leis da física dos discos rotacionais (e até dos SSDs).
A Física do Copy-on-Write: Uma Meia-Verdade
A promessa de venda é sedutora: "Criar um snapshot não custa espaço". Isso é tecnicamente verdade no milissegundo em que o comando é executado, mas é uma mentira perigosa no longo prazo.
Para entender o crime, precisamos entender a arma: o Copy-on-Write (CoW).
Em sistemas de arquivos tradicionais (como EXT4 ou NTFS), quando você sobrescreve um arquivo, o sistema vai até o bloco físico no disco e muda os bits. No ZFS, isso é proibido. O ZFS nunca altera dados gravados. Se você precisa mudar um bloco, o ZFS aloca um novo bloco em outro lugar, grava os novos dados lá e depois atualiza o ponteiro de metadados para apontar para o novo local.
Quando você tira um snapshot, o ZFS simplesmente congela a árvore de ponteiros (Merkle Tree) naquele momento.
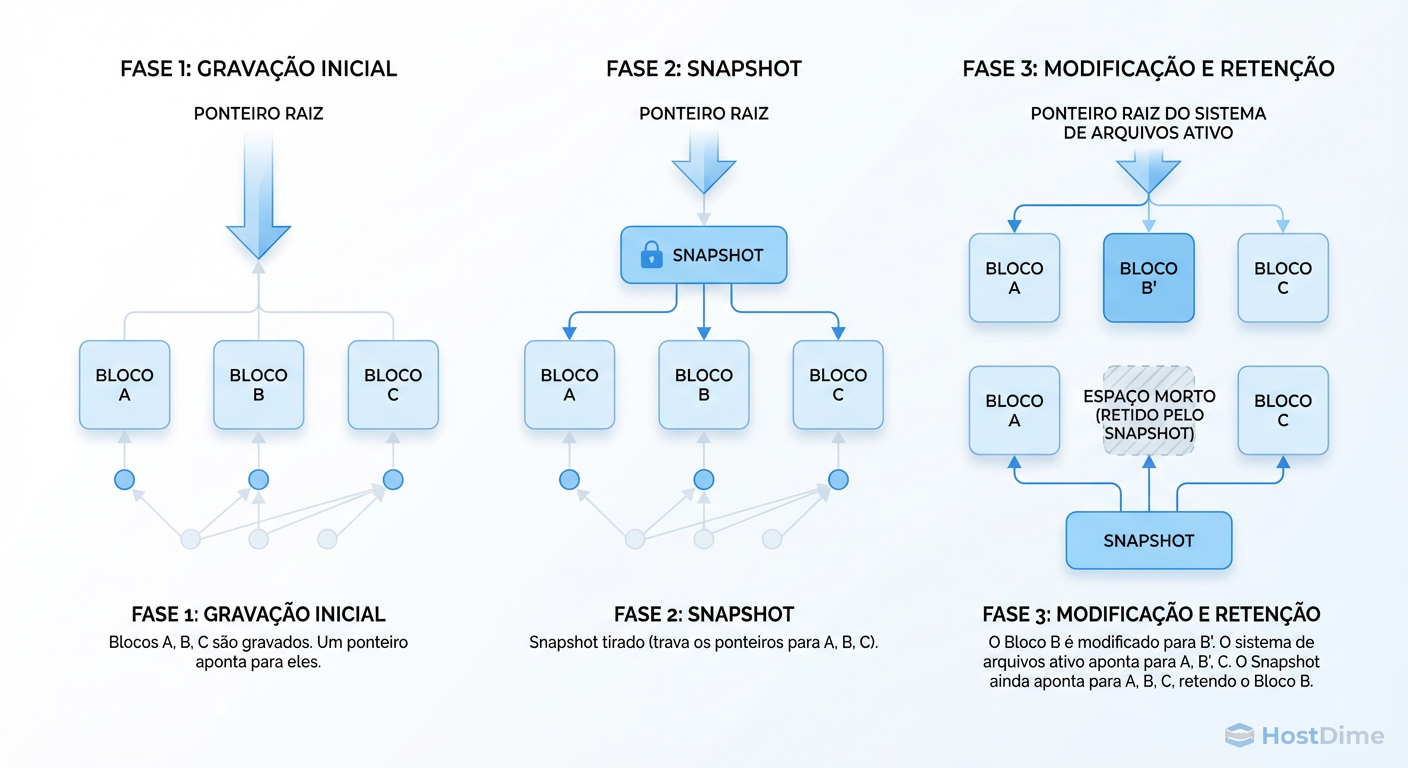 Figura: A Mecânica do CoW: O snapshot não copia dados, ele congela ponteiros. O espaço só é consumido quando os dados divergem.
Figura: A Mecânica do CoW: O snapshot não copia dados, ele congela ponteiros. O espaço só é consumido quando os dados divergem.
Se ninguém tocar nos dados, o snapshot ocupa, de fato, zero bytes adicionais (apenas alguns KB de metadados). Mas assim que o sistema de produção começa a gravar, a divergência começa.
O sistema de arquivos "vivo" aponta para os novos blocos (Bloco B'). O snapshot continua segurando o ponteiro para o bloco antigo (Bloco B). Agora, você tem dois blocos físicos ocupando espaço para representar um único arquivo lógico em dois momentos do tempo.
O "custo zero" é apenas um adiamento da cobrança. A conta chega quando os dados divergem.
O Triângulo das Bermudas do Espaço: Onde os GBs Somem
O sintoma mais comum que recebo em chamados de emergência é: "Apaguei 500GB de logs, mas o df -h continua mostrando o disco cheio. O ZFS está quebrado?"
O ZFS não está quebrado. Ele está sendo fiel à sua ordem de retenção.
Existe uma distinção crítica que muitos administradores ignoram até ser tarde demais: a diferença entre REFERENCED (Referenciado) e USED (Usado).
REFERENCED: É o tamanho dos arquivos que você consegue ver e acessar agora se montar aquele dataset.
USED: É o espaço que aquele dataset está consumindo do pool, que inclui os dados atuais mais os dados antigos segurados pelos snapshots.
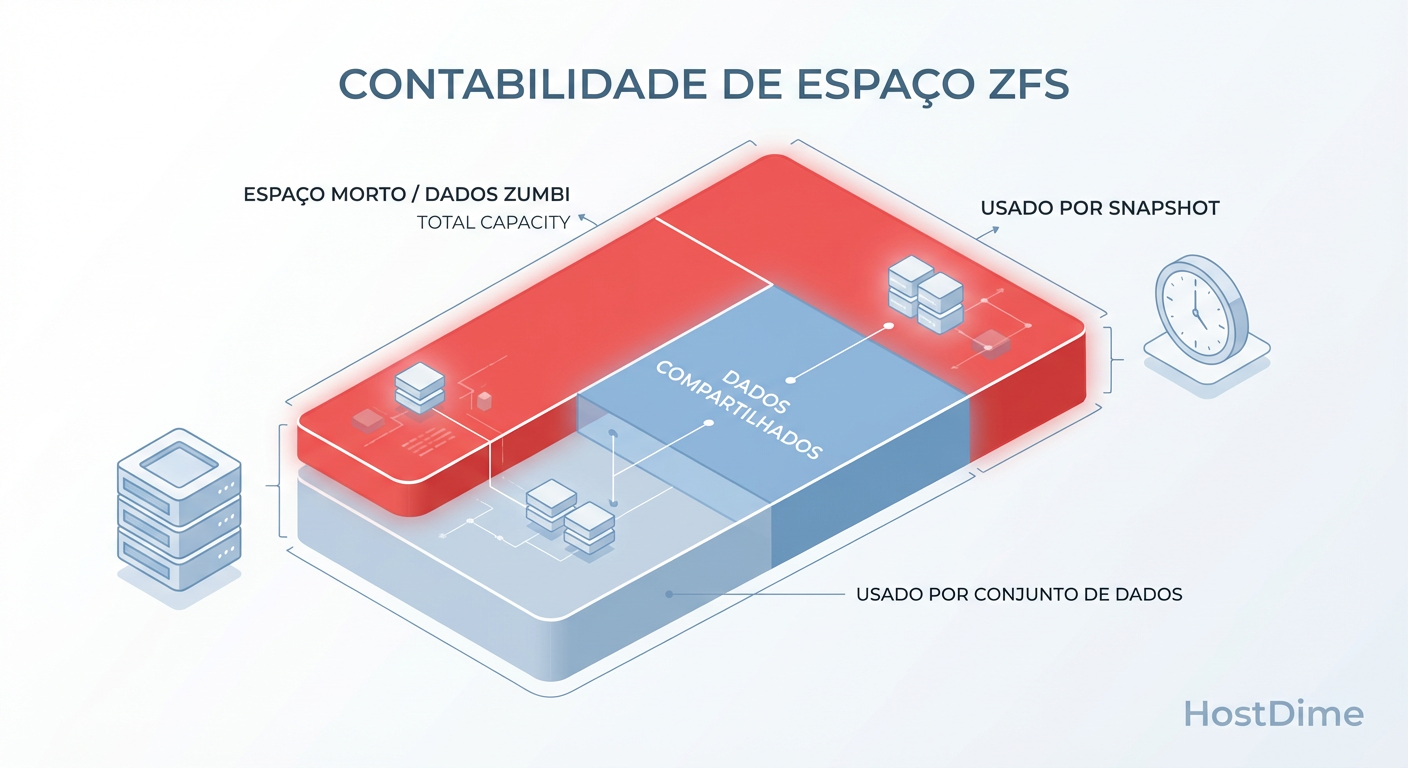 Figura: O Triângulo das Bermudas do df -h: Por que apagar arquivos no sistema de arquivos não libera espaço se um snapshot os segura.
Figura: O Triângulo das Bermudas do df -h: Por que apagar arquivos no sistema de arquivos não libera espaço se um snapshot os segura.
Quando você apaga um arquivo (rm arquivo.log), você está apenas removendo o ponteiro do sistema de arquivos atual. Se um snapshot feito há uma hora tem um ponteiro para os blocos desse arquivo, o ZFS não pode liberar o espaço físico. O bloco continua no disco, protegido pelo snapshot.
Para o sistema operacional (e para o df), o espaço continua ocupado. Para o usuário, o arquivo sumiu. É aqui que os gigabytes "desaparecem". Eles estão presos no limbo dos snapshots.
Investigação Rápida: Não confie no
df. Para ver quem está segurando o espaço, você precisa interrogar o ZFS diretamente.
# O comando que revela a verdade.
# Procure por snapshots com valor alto na coluna USED.
zfs list -t snapshot -o name,used,referenced -s used
Se você vir um snapshot antigo com 50GB em USED, significa que 50GB de dados mudaram ou foram deletados desde aquele momento, e esse snapshot é a única coisa impedindo o ZFS de liberar esse espaço.
A Bomba-Relógio da Fragmentação
Espaço em disco é barato. Performance de I/O não é. Aqui é onde o cenário fica feio.
Lembra do Copy-on-Write? Cada vez que você sobrescreve um pedaço de um arquivo, o novo dado é gravado em um bloco diferente. Em um disco vazio, o ZFS tenta gravar sequencialmente. Mas conforme o disco enche e você mantém snapshots antigos, o espaço livre se torna um "queijo suíço".
Imagine um banco de dados de 100GB. Originalmente, ele foi gravado sequencialmente.
Você tira um snapshot.
O banco de dados sofre updates aleatórios em 20% dos seus registros.
O ZFS grava esses 20% em novos blocos espalhados pelo disco (onde havia espaço livre).
O arquivo lógico agora é uma colcha de retalhos: parte dele está nos blocos originais (compartilhados com o snapshot), parte está em novos blocos distantes.
Se você usa discos rotacionais (HDD), você acabou de transformar leitura sequencial (rápida) em leitura aleatória (lenta). A cabeça de leitura do disco precisa pular freneticamente para ler um arquivo que, para o sistema operacional, parece contínuo.
O Sintoma: O throughput (MB/s) cai drasticamente, enquanto o IOPS dispara e a latência aumenta. O servidor parece "engasgado", mesmo sem pico de CPU.
Para verificar a fragmentação do pool:
zpool list -v
Olhe a coluna FRAG.
Abaixo de 30%: Aceitável.
Acima de 50%: Preocupante.
Acima de 80% em HDDs: O desempenho será sofrível para cargas de escrita/leitura aleatória.
Nota do Perito: Em SSDs, a fragmentação dói menos devido à ausência de latência de busca mecânica, mas ainda castiga a amplificação de escrita e sobrecarrega os metadados do ZFS. Não ignore isso só porque usa flash.
O Custo Invisível do Delete
Então você descobre que os snapshots estão matando seu espaço e performance. A reação instintiva? "Vou apagar todos os snapshots agora!"
Pare.
Apagar snapshots no ZFS não é uma operação gratuita. É uma transação complexa. Quando você emite um zfs destroy, o ZFS precisa percorrer a árvore de metadados para descobrir quais blocos eram exclusivos daquele snapshot e marcá-los como livres.
Se você apagar milhares de snapshots de uma vez, ou um snapshot que referenciava terabytes de dados únicos, você vai gerar uma tempestade de I/O de metadados. O ZFS faz isso em segundo plano (processo de freeing), mas isso compete com sua produção.
Já vi servidores de produção travarem (timeout em aplicações) porque o administrador rodou um script para limpar 50.000 snapshots antigos de uma vez. O sistema ficou tão ocupado limpando o lixo que não conseguia gravar novos dados.
Estratégia de Sobrevivência
Não deixe de usar snapshots. O poder de reverter um ransomware ou um DROP TABLE em segundos vale o risco. Mas você precisa operar com disciplina.
1. Política de Retenção "Fading Memory"
Não guarde snapshots de 15 em 15 minutos por um ano. Use uma política de decaimento exponencial:
4 snapshots por hora nas últimas 24h.
1 snapshot por dia nos últimos 7 dias.
1 snapshot por semana no último mês.
Destrua o resto.
2. Automatize com Ferramentas Maduras
Não escreva scripts em bash no cron. Use ferramentas que já resolveram os problemas de borda (como falhas de prune e monitoramento). A ferramenta padrão-ouro é o Sanoid.
# Exemplo de configuração do /etc/sanoid/sanoid.conf
# Simples, legível e evita o acúmulo tóxico.
[zpool/dados/producao]
use_template = production
recursive = yes
[template_production]
frequently = 0
hourly = 24
daily = 7
monthly = 3
yearly = 0
autosnap = yes
autoprune = yes
3. Monitoramento Ativo
Seu sistema de monitoramento (Zabbix, Prometheus, Nagios) deve alertar não apenas sobre "Espaço Livre", mas sobre:
Idade do snapshot mais antigo: Se for > 1 ano, questione a necessidade.
Porcentagem de
REFRESERV: Se você usa reservas, monitore se os snapshots estão comendo a reserva.IOPS de Delete: Se o sistema estiver lento, verifique se há um processo de
zfs destroyrodando em loop.
O ZFS lhe dá a arma mais poderosa de recuperação de dados existente. Cabe a você garantir que ela esteja apontada para o problema, e não para o seu próprio pé.

Alexei Volkov
Ceph Cluster Administrator
Escala clusters Ceph para o infinito. Mestre em CRUSH maps e recuperação de placement groups.